Unsupervised Classifier Selection Approach for Hyperspectral Image Classification
Texte intégral
Figure

Documents relatifs
In order to emphasise the central role of the characteristic Boolean algebra, let us recall that classical realizability gives rise to surpris- ing models of set theory (such as
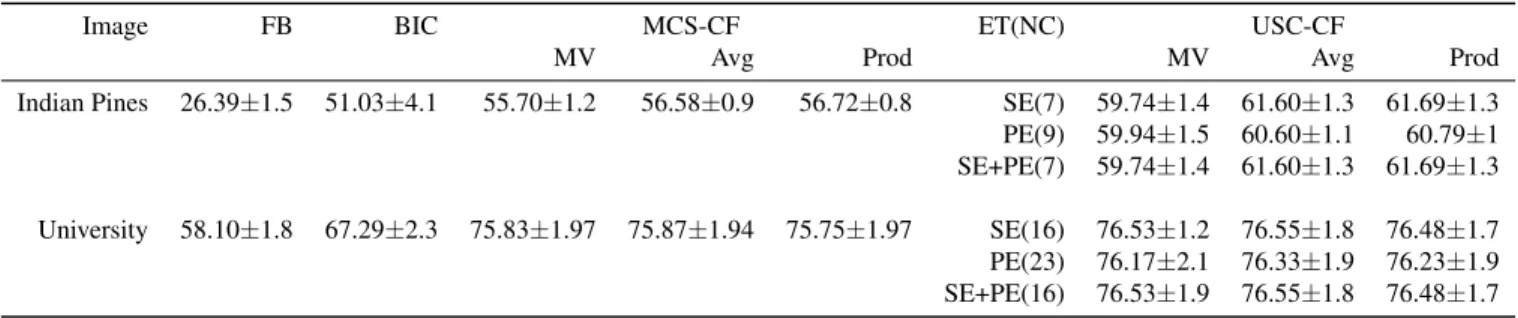
The proposed method is composed of a feature selection procedure and a two-step classification strategy, both based on a specific mass function construction method inspired by
Using the complementary erf function with the templates obtained from the training phase, the algorithm computes the probabilities to belong to each of the 3 states
the obtained segmentation maps is combined with the pixel- wise classification map using the majority voting principle: For every region in the segmentation map, all the pixels
In the 1-SVM classification task with Gaussian RBF kernel, the kernel width must be adapted by a scaling process, in some way, to the distribution of the data in H and to adapt
And then realization methods of rule reduction and rule set minimum are relatively systematically studied by using attribute-value block technique, and as a
Keywords: Symbol recognition, data analysis, probabilistic graphical models, Bayesian networks, variable selection..
We also show that the use of belief functions allows us to combine the information contained into different input data derived from the whole spectrum data, and that it is an
