Snooze: A Scalable and Autonomic Virtual Machine Management Framework for Private Clouds
Texte intégral
Figure
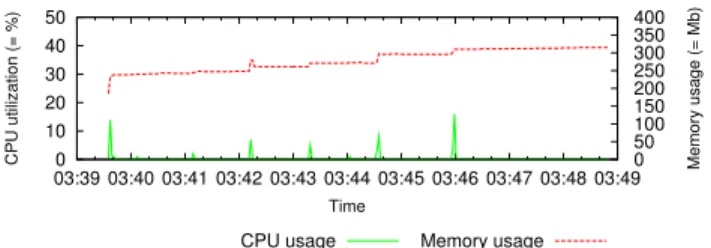
Documents relatifs
We considered the set of 500 random permutations with n = 15 and d = 12 and, for each permutation P, we calcu- lated the ratios (number of enumerated traces with height H / total
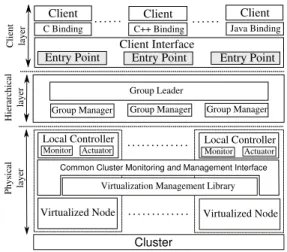
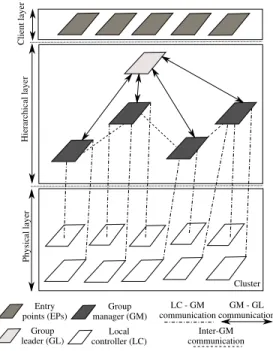
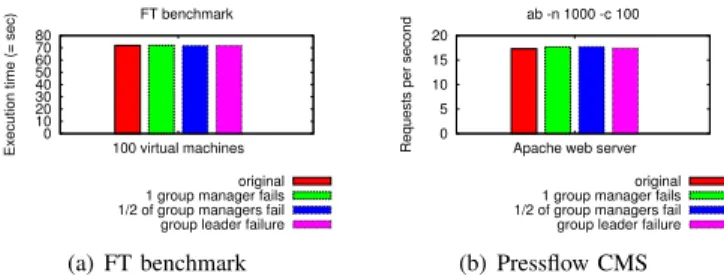
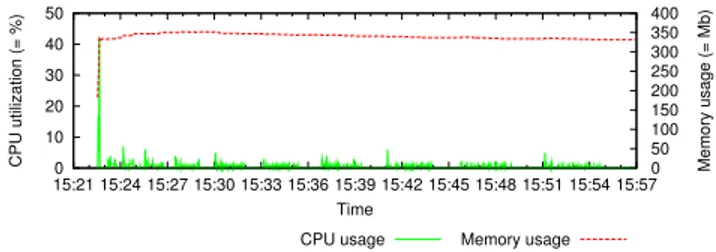
Snooze is an open-source scalable, autonomic, and energy- efficient virtual machine (VM) management framework for private clouds.. It allows users to build compute infrastructures
On the third step, the planner generates the deployment graph plan based on received RFCs. It plans the deployment of the event brokers of the home gateway and the smart
Dans un pays où beaucoup d’efforts restent à consentir pour un développement durable ; Le marché de l’environnement en Algérie est porteur, et invite à des ententes et accords
Résumé de l’atelier : Par diverses mises en situation, nous voudrions mettre en évidence certaines difficultés auxquelles sont confrontés les élèves lorsque des
We provide the comparison between different methods, and show, that on both the real data of Porto network and synthetic ones, the method based on zone-based RL and using the
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
Consequently, it is crucial to provide scalable and efficient VM and container images management to ease and enable fast service provisioning in distributed clouds and Edge
