Spatial coding-based informed source separation
Texte intégral
Figure
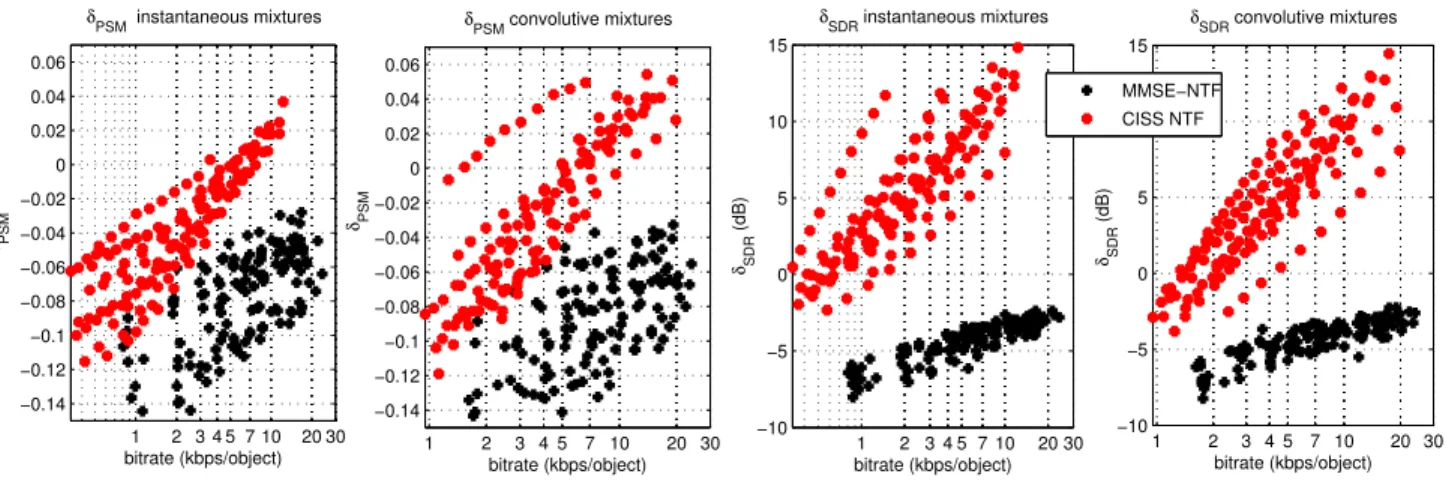
Documents relatifs
Firstly, we characterize the nature of the time series using the DVV method with WiAAFT sur- rogates and then employ complex Morlet wavelet to discover the cycles or hidden
To deal with the overwhelming number of the concepts produced by formal concept analysis, we used fuzzy membership functions based on the features of email, including
A similar enrichment of DSBs in the neighbourhood of the TSS and along the gene body of highly expressed genes was also recapitulated in low-input samples of primary mouse
This paper proposes a new step-wise integrated approach that could potentially assist municipal professionals in developing optimized renewal plans that would identify the most
L’accès à ce site Web et l’utilisation de son contenu sont assujettis aux conditions présentées dans le site LISEZ CES CONDITIONS ATTENTIVEMENT AVANT D’UTILISER CE SITE WEB.
A Cerenkov-electrooptical diagnostic of intense, relativistic electron beams, giving two- dimensional images with subnanosecond resolution is described...
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
