Predicting Volatility: Getting the Most out of Return Data Sampled at Different Frequencies
Texte intégral
Figure
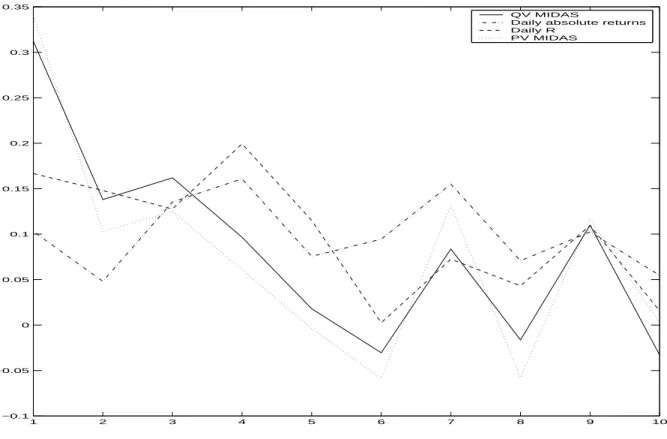
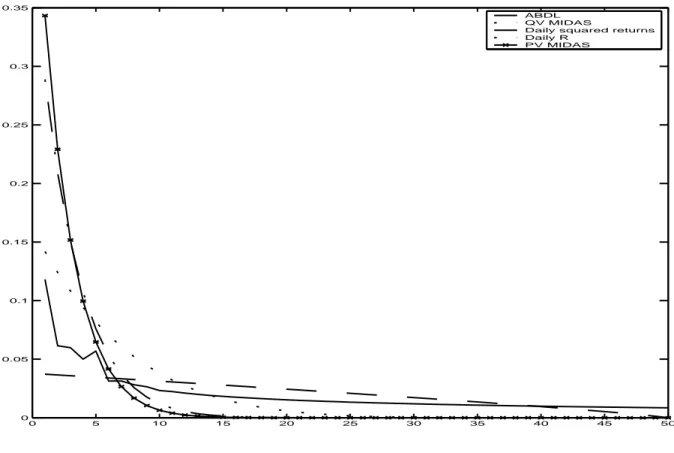
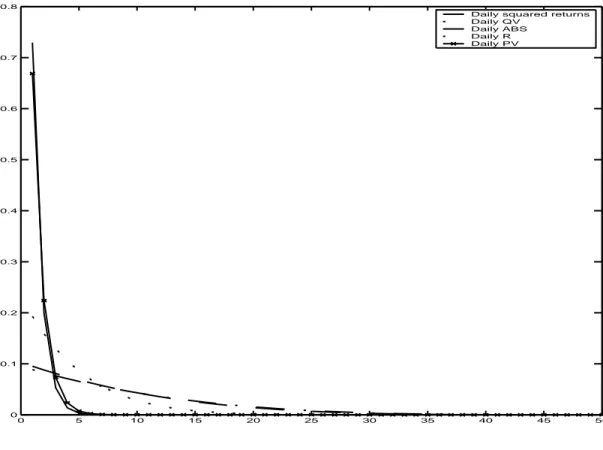
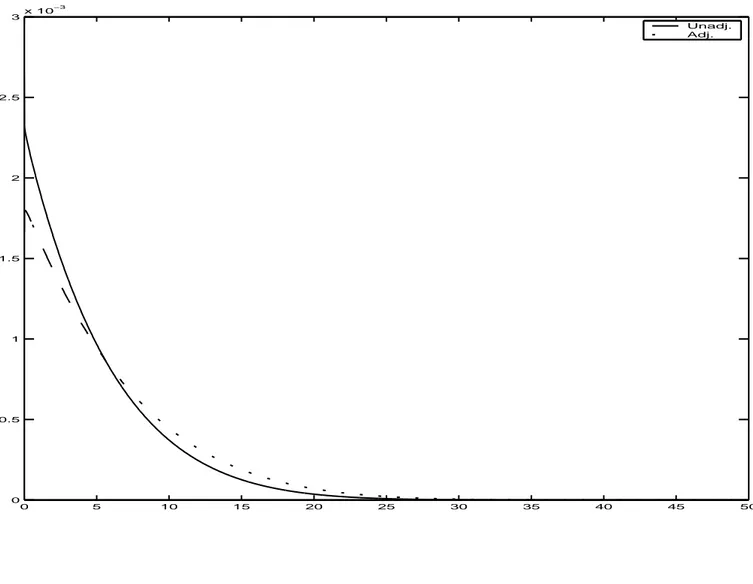
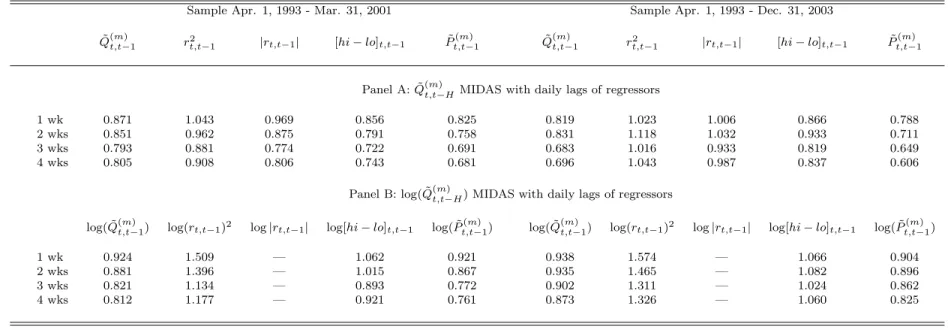
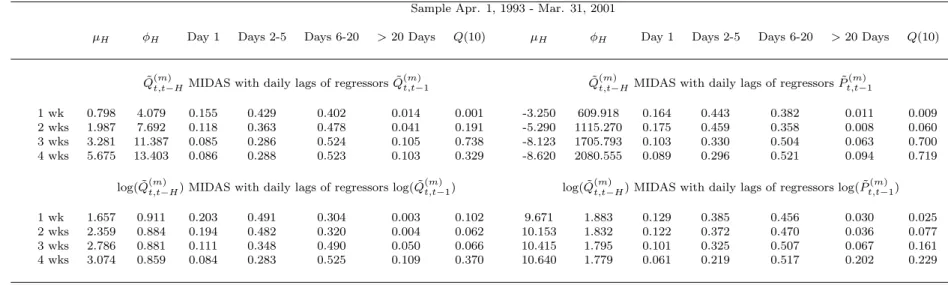


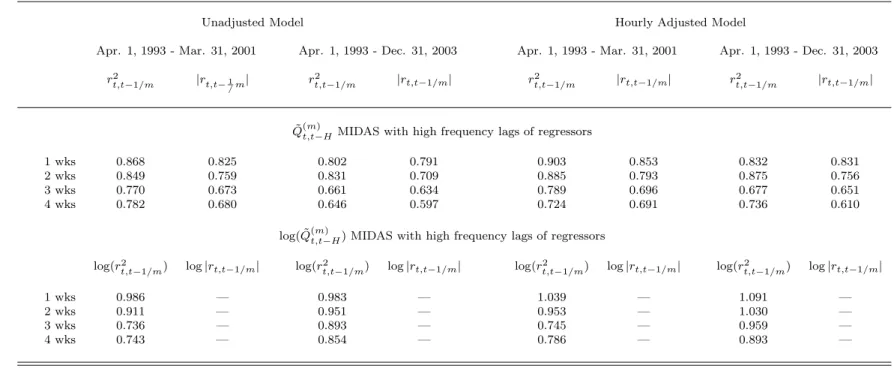

Documents relatifs
Utiliser une attache parisienne comme axe.. Utiliser une attache parisienne
ln the U.S.A.: Postmaster: send address changes to NEWSWEEKINTERNATiONAL,251 West 57th Street, New York, NY 10019; periodical postage paid at New York, NY., and at additional
ln the U.S.A.: Postmaster: send address changes to NEWSWEEK INTERNATIONAL, 251 West 57th Street, NewYork, NY10019;perlodical postage paid at New York, N.Y.,and at addltlonal
With 'The KiteRunner'opening this week,the principals talk about the chal- lenges of fllmingthe real Mghanistan with a truly global cast and crew.Page62. THE ISSUE World Affoirs 22
ln the U.S.A.:Postmaster: send address changes to NEWSWEEK INTERNATIONAL, 251 West 57th Street, New York, NY10019; periodical postage paid at NewYork, N.Y.,and at add~ional
Copyright under the InternationalCopyrightConvention.Copyrightreserved underthe PanAmericanConvention.Registeredinthe PhilippinesPatent Office.lnthe U.S.A.: Postmaster: send
ln the U.S.A.:Postrnaster: send address changes to NEWSWEEK INTERNATIONAL, 251 West57thStreet,NewYork,NY10019: periodicalpostagepaidat NewYork,N.Y., andat
57th Street, New York, NY 10019; periodical postage paid at New York, N.Y., and at additional mailing offices. NEWSWEEK INTERNATIONAL is written and edited for a worldwide audience
