On the amount of regularization for super-resolution reconstruction
Texte intégral
Figure



Documents relatifs
It is expected that the result is not true with = 0 as soon as the degree of α is ≥ 3, which means that it is expected no real algebraic number of degree at least 3 is
First introduced by Faddeev and Kashaev [7, 9], the quantum dilogarithm G b (x) and its variants S b (x) and g b (x) play a crucial role in the study of positive representations
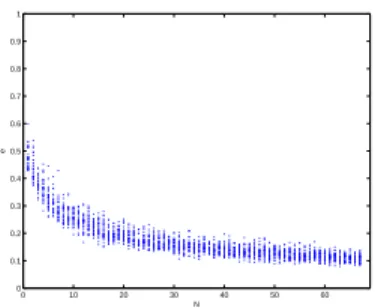
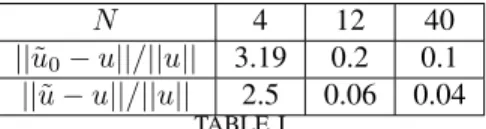
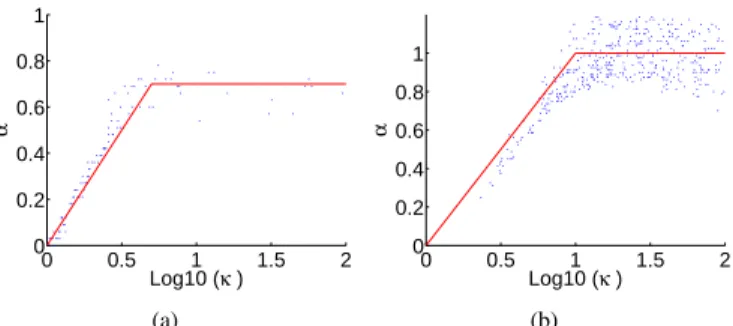
On the other hand, for reconstructing the frequency spectrum or the time signal of prelocalized sources, the regularization term has to reflect prior information on the nature of
The underlying idea behind this regularization strategy was to combine the advantages of the iterated Tikhonov regularization, which can be thought as an iterative refinement of
In particular, the practical interest of updating the regularization parameter during the identification process has been pointed out, as well as the relative performances of
A distribution-wise GP model is a model with improved interpolation properties at redundant points: the trajectories pass through data points that are uniquely defined
[r]
It can be seen as an extension to the space-time domain of the Proper Generalized Decomposition (PGD) method previously proposed in DIC [6] where the dimensions of space were
