Gestion de droits d’accès dans des réseaux
informatiques
Mémoire
MEMEL EMMANUEL LATHE
Maîtrise en informatique Maître ès sciences (M.Sc.)
Québec, Canada
Résumé
La sécurité informatique est plus que jamais une préoccupation majeure de toute entreprise privée comme publique. Le contrôle d’accès, qui représente une composante importante de la sécurité des systèmes d’information, consiste à vérifier si un sujet possède les droits nécessaires pour accéder à un objet [43]. Il est régi par des règles qui peuvent être exprimées en différents langages. La validation de contrôle d’accès, également appelée analyse de conformité, consiste à vérifier, à intervalles réguliers, si ces règles de contrôle d’accès mises en œuvre sont cohérentes et complètes par rapport à une politique de sécurité donnée. Plusieurs outils de contrôle d’accès sont applicables à cette fin. AVTAC (Automatic Validation Tool of Access Control) est un outil sur lequel nous avons apporté notre contribution.
Abstract
Computer security is more than ever a major concern for any private or public company. Access control which is an important component of security of information systems consists on verifying whether a subject has the rights to access to an object. It is governed by rules that can be expressed in different languages. Validation of access control also called compliance is to check at regular intervals if the access control implemented rules are consistent and complete with respect to a given security policy or not. Several access control tools are applicable to this end. AVTAC (Automatic Validation Tool of Access Control) is the tool on which we made our contribution.
Table des matières
Résumé iii
Abstract v
Table des matières vi
Liste des tableaux ix
Liste des figures xi
Remerciements xiii
Introduction 1
1 État de l’art des outils de contrôle d’accès 3
1.1 Introduction. . . 3
1.2 Authentification pour un système IAM . . . 4
1.3 Modèle d’habilitation pour un système IAM . . . 8
1.4 Implémentation et contrôle pour un système IAM . . . 11
1.5 Outils de gestion des droits d’accès . . . 14
1.6 Normes et référentiels de sécurité . . . 18
1.7 Conclusion . . . 25
2 Représentation des droits d’accès sous Windows et Linux 27 2.1 Introduction. . . 27
2.2 Contrôle d’accès : définitions et politiques . . . 28
2.3 Contrôle d’accès sous Linux . . . 30
2.4 Contrôle d’accès sous Windows . . . 42
2.5 Représentation graphique du contrôle d’accès . . . 46
2.6 Conclusion . . . 50
3 Contribution 51 3.1 Introduction. . . 51
3.2 Architecture et vue d’ensemble . . . 51
3.3 Outils d’approvisionnement . . . 54
3.4 Processus de validation de droit d’accès . . . 57
3.5 Traduction des droits d’accès . . . 59
3.6 Récupération automatique des droits d’accès à partir de différentes machines 63 3.7 Conclusion . . . 65
Conclusion générale 67
A Scripts et documents XACML 69
A.1 Script d’extraction des droits d’accès Windows . . . 69
A.2 Traduction des droits d’accès Linux vers XACML . . . 75
A.3 Grammaire BNF pour un sous-ensemble de XACML 3.0 . . . 77
Liste des tableaux
2.1 Types d’entrées ACL [36]. . . 33
2.2 Masquage des autorisations d’accès. . . 34
3.1 SDDL Syntax [43]. . . 61
Liste des figures
1.1 Processus de synchronisation [60].. . . 12
1.2 midPoint[31]. . . 15
1.3 Architecture OpenIDM [31]. . . 16
1.4 ITIL version 3 [65]. . . 25
2.1 Concepts de base pour le contrôle d’accès dans Linux . . . 30
2.2 Droit d’accès Linux : Exemple. . . 30
2.3 ACL minimale. . . 34
2.4 ACL étendue. . . 34
2.5 ACE de type accès accordé [13].. . . 43
2.6 ACE de type accès refusé [13]. . . 44
2.7 Structure d’un descripteur de sécurité [13].. . . 45
2.8 Language SDDL. . . 45
2.9 Architecture Linux [53]. . . 47
2.10 GMC gestion des droits d’accès [21]. . . 48
2.11 Console de gestion Microsoft. . . 49
2.12 Utilisateurs et groupes locaux. . . 49
2.13 Gestionnaire de sécurité Windows. . . 49
2.14 Fenêtre d’édition des ACE. . . 50
3.1 Architecture du cadriciel AVTAC [43]. . . 52
3.2 Architecture de l’outil de validation [54] . . . 54
3.3 Capture 1 d’écran de l’outil de validation. . . 63
3.4 Capture 2 d’écran de l’outil de validation. . . 64
Remerciements
À mon Dieu
Que toute la gloire te revienne pour cette étape, je te dis merci pour ton choix et ta fidélité sur ma vie.
À mon épouse et mes enfants
Vous qui m’avez toujours soutenu, merci de me faire confiance et d’être pour moi une source de motivation.
À mon père spirituel
Merci prophète de Dieu pour la source de bénédiction que tu es pour moi, l’Université Laval est aujourd’hui une réalité grâce à toi.
À mes parents
Reconnaissance et amour familial, plus particulièrement à mon père qui a accepté de financer mes études, merci de croire en moi papa.
À mon directeur de recherche, Dr Mohamed Mejri
Je tiens à vous dire merci pour votre motivation et votre patience dans l’élaboration de ce projet de maîtrise. Je vous suis très reconnaissant d’avoir accepté de superviser ce travail. À mes collègues
Merci pour votre soutien, particulièrement à Etienne Sadio qui a été pour moi un appui ines-timable.
À mes frères et sœurs
Je dis merci à tous ceux qui m’ont soutenu durant mes études, plus particulièrement à la famille Gandonou, la famille Angora, la famille Yao et la famille Lasme. Que Dieu vous bénisse !
Introduction
Motivation
La sécurité informatique est plus que jamais une préoccupation majeure de toute organisation. Le contrôle d’accès, qui représente une composante importante de la sécurité des systèmes d’information, consiste à vérifier si un sujet demandant l’accès à un objet possède les droits nécessaires pour le faire. Il est régi par des règles qui peuvent être exprimées dans un langage tel que XACML [1].
Pour mieux protéger nos données et les équipements de nos systèmes informatiques, nos insti-tutions définissent des politiques de sécurité et utilisent différentes techniques et outils pour les implémenter. L’attribution et le contrôle de droits d’accès est souvent la principale technique. Cependant, la conformité entre ce qui est demandé par la politique de sécurité et ce qui est réellement implanté dans le système n’est pas toujours respectée. Par ailleurs, la complexité de cette tâche d’analyse de conformité augmente considérablement quand nos systèmes (incluant les équipements et les données qu’on protège, les personnes qui donnent les droits d’accès et les personnes à qui l’on donne les droits d’accès) ou nos politiques de sécurité changent constamment.
Par exemple, il arrive assez souvent que des personnes qui ont complètement quitté une organi-sation bénéficient, par erreur, de leurs anciens accès. Il arrive souvent aussi que des personnes qui ont changé de poste ou de grade bénéficient, toujours par erreur, de leurs anciens accès. Pire encore, des données sensibles peuvent se trouver mal protégées.
Pour rendre l’analyse de conformité faisable et à coût raisonnable, il faut automatiser ce processus. En d’autres termes, il faut développer des outils qui sont capables d’aller chercher régulièrement et automatiquement les droits d’accès attribués aux différents utilisateurs pour les différentes ressources et de les comparer avec la politique de sécurité actuelle.
C’est dans cet axe de recherche que se situe ce travail. En effet, nous proposons le développe-ment des outils permettant de récupérer automatiquedéveloppe-ment des droits d’accès et des techniques permettant de les analyser.
Buts
L’objectif de ce travail de recherche est d’une part de faire une synthèse de l’état de l’art des différents outils et techniques permettant la gestion des droits d’accès dans les réseaux infor-matiques et d’autre part de développer des outils permettant de récupérer automatiquement une partie de ces droits d’accès et de les analyser.
Organisation
Ce mémoire est structuré comme suit : le chapitre 1 est consacré à l’état de l’art des ou-tils de gestion de contrôle d’accès . Ensuite, le chapitre 2 décrit la représentation des droits d’accès sous Windows et Linux . Dans le chapitre 3, nous présentons notre contribution dans l’élaboration de l’outil AVTAC. Finalement au chapitre 4, nous terminons par une conclusion générale.
Chapitre 1
État de l’art des outils de contrôle
d’accès
1.1
Introduction
L’IAM (Identity and Access Management) a évolué en devenant un élément capital du sys-tème informatique dans les grandes et moyennes entreprises. Ses atouts en termes de création et de mise en œuvre de politiques de contrôle d’accès sont avérés ; cependant cette solution informatique a été auparavant considérée comme très difficile à mettre en œuvre. Aussi, la né-cessité métier d’une bonne interaction entre les systèmes d’information et les différentes entités organisationnelles (acteurs externes) devient de plus en plus primordiale. Qu’il s’agisse d’uti-lisateurs internes ou externes à l’entreprise, ces identités peuvent exposer celle-ci à de grandes menaces, si elles ne sont pas gérées et maintenues par des systèmes fiables et performants. La gouvernance d’un système IAM, qui est très souvent intégrée à la gestion de la politique de sécurité de l’organisation, spécifie les attendus pour les quatre thèmes principaux de la gestion d’identités et d’accès :
— l’Authentification de l’accès utilisateur ;
— l’Habilitation aux ressources du système d’information ; — L’Implémentation de processus ;
— Le Contrôle des procédures de gestion et de validation.
Ce chapitre sera un bon repère dans la connaissance de l’IAM, car il nous permettra de nous acclimater avec les notions et la modélisation utilisées dans un processus de gestion des identités et des droits d’accès. Il a aussi pour objectif de nous orienter à faire de bon choix afin de réaliser parfaitement un projet IAM.
1.2
Authentification pour un système IAM
L’objectif de l’authentification est d’assurer la légitimité d’un accès à une ressource. Cette justification est faite par un moyen d’authentification qui se base sur des composants de différents types :
— "Ce que je sais".
Il s’agit d’une information confidentielle qu’un utilisateur indique pour prouver son iden-tité : un mot de passe, un NIP1, etc.
— "Ce dont je dispose".
Il s’agit d’un équipement de sécurité tenu par l’utilisateur qui donne lieu à un authen-tifiant permettant de prouver son identité : certificat numérique, token, badge d’accès, etc.
— "Ce que je suis".
Il s’agit d’une marque propre à l’utilisateur : la signature, l’empreinte digitale, l’iris de l’œil, etc.
Plusieurs services peuvent être mis en place pour faciliter l’authentification, mais celui qui attirera notre attention et qui est le service d’authentification le plus mis en œuvre pour un projet IAM est : l’authentification unique ou SSO2.
1.2.1 Authentification unique (SSO)
De nos jours, les entreprises ont à assurer la gestion d’un ensemble délicat d’applications ré-seau et d’applications Web qui fonctionnent sur des systèmes hétérogènes. Les utilisateurs sont dans l’obligation d’accéder à plusieurs applications pour l’envoi de leurs courriels, la gestion du support informatique, la gestion des fichiers de tout type.
À cause des exigences toujours plus rigoureuses en matière de sécurité, les utilisateurs doivent entrer leur paramètre de connexion (identifiant / mot de passe) propre à chacune de ces ap-plications, ce qui peut avoir comme conséquence, et ce de façon courante, l’utilisation de n (nombre d’applications) combinaisons différentes.
Dans le contexte de la gouvernance des systèmes et de l’application des mesures de sécurité d’informations (paramètres de stratégie de mot de passe), des dispositions ont été prises afin d’assurer la sécurité du réseau, par exemple par l’utilisation de mots de passe forts, la durée de vie maximale du mot de passe, durée de vie minimale du mot de passe et conservation d’historique de mot de passe. Avec tout cela, des problèmes liés à la réinitialisation des mots
1. NIP : Numéro d’identification Personnel. 2. SSO : Single Sign On.
de passe (coup de fil important de la part des utilisateurs pour réinitialiser leur mot de passe) et à "l’inconfortabilité" des utilisateurs (trop de mot de passe à gérer) se sont accentués. C’est dans ce cadre qu’ont été élaborées les solutions d’authentification unique pour les entre-prises. Cette façon de s’authentifier permet aux utilisateurs de se loguer une seule fois, sachant que les processus de connexion aux applications dans la suite, sont gérés automatiquement. Ainsi, la solution de SSO logue automatiquement les utilisateurs à diverses applications sur la base des paramètres de connexion authentifiés.
Avantages de l’authentification unique
Les fonctions de l’authentification unique offrent plusieurs avantages aux entreprises parmi lesquels :
• Une évolution dans le confort et dans le rendement des utilisateurs.
Les employés disposent d’un accès simplifié et prompt à toutes les applications requises, ce qui augmente leur rendement.
• La restriction des risques au niveau de la sécurité.
Les employés n’ont plus besoin d’écrire leurs accès secrets sur une feuille qui est suscep-tible d’être facilement interceptée vu qu’ils les laissent souvent sur le bureau.
• Une sécurité optimale du réseau d’entreprise.
L’authentification unique empêche les utilisateurs non autorisés d’avoir accès au réseau de l’entreprise. En effet elle donne lieu à une bonne gestion des droits accès, seuls les utilisateurs autorisés peuvent accéder aux applications pour lesquelles ils ont un accès. • Le centre d’assistance technique est moins sollicité en ce qui concerne les
demandes de réinitialisation.
Les employés risquent moins d’omettre leurs accès secrets, car ils n’en ont qu’un seul à retenir, ce qui logiquement aide à réduire le nombre d’interventions du centre d’assistance technique à ce sujet.
• Une optimisation du niveau de service
Attendu que le centre d’assistance technique est moins sollicité pour ce qui concerne la gestion de réinitialisation, ses collaborateurs peuvent donc se focaliser sur le soutien des usagers qui ont des problèmes plus critiques et ainsi développer leur niveau de service. • Compatibilité aux exigences de conformité (PCI, HIPAA, SOx, etc.)
Les fonctionnalités de l’authentification unique offrent plusieurs options de compatibi-lité :
— La gestion des authentifications prend en compte l’authentification forte (concaté-nation d’au moins deux facteurs d’authentification) sans entraver au confort des employés.
— En une seule demande, l’authentification unique permet, et ce en une seul fois, l’interdiction de l’accès des employés à l’ensemble du réseau, à défaut de devoir reproduire cette action pour chacune des applications.
— L’authentification unique permet de produire un rapport sur le temps exact (date et heure) auquel les comptes des utilisateurs ont reçu une autorisation d’accès. — L’authentification unique donne lieu également à plusieurs vérifications
supplémen-taires avant la connexion effective des employés, par exemple, il est possible de doter les applications sensibles de l’entreprise d’une couche additionnelle de sécu-rité afin de vérifier que l’employé qui tente d’accéder au système y est bien autorisé. L’utilisation d’un badge ou d’un NIP est requise.
Inconvénients de l’authentification unique
Nonobstant les avantages que proposent les fonctions SSO, il est de même notable de signaler quelques inconvénients :
— Au niveau de la compatibilité, l’authentification unique a bien souvent des limites avec plusieurs applications (clients lourds) . Pour pallier ce problème, il faut implémenter, pour les applications non supportées, une interface qui permet au SSO d’authentifier de façon automatique l’utilisateur.
— L’authentification unique peut aussi attenter à la sécurité, en effet elle permet d’accéder à plusieurs ressources une fois l’utilisateur logué. Pour pallier ce problème, il faut associer les solutions de l’authentification unique à d’autres facteurs d’authentification comme les certificats ou carte à puce.
— Le concept même de l’authentification unique peut également être considéré comme étant un risque, en effet si le module (serveur SSO) qui gère l’authentification a un problème (indisponibilité, dysfonctionnement, etc.) celui-ci empêche alors tout le système d’information de fonctionner. Pour pallier ce problème, le recours a des serveurs secours peut être envisagé.
Les composants du SSO
Un système d’authentification unique est composé d’au moins trois « segments », ces segments spécifient des fonctionnalités qui donnent lieu à la mise en place de l’authentification. Ces trois segments sont :
• Le serveur SSO : c’est le composant central de l’authentification unique, il gère : — l’authentification des employés.
— la propagation d’identité3 entre les applications.
• Les applications : Les applications sont utilisées par les utilisateurs finaux, elles doivent être compatibles avec le système d’authentification unique, c’est à dire être capable d’échanger avec l’agent d’authentification.
• L’agent d’authentification :
L’agent d’authentification est la jonction entre les applications et le serveur SSO. Sa fonction est de vérifier que l’employé est authentifié. En cas d’échec de ce processus de vérification, l’utilisateur est redirigé vers le serveur SSO.
Architectures de SSO
On dénombre plusieurs types d’architecture pour l’authentification unique, en plus des tech-niques utilisées. L’architecture d’un système d’authentification unique est révélatrice, ce choix doit être fonction d’une bonne vue d’ensemble du système d’information visé. En effet ce choix est très conditionné par les normes de confiance établies entre plusieurs entités à fédérer au sein du système d’authentification unique. Les architectures se subdivisent en deux modèles que voici :
• Le modèle centralisé
La règle fondamentale ici est d’avoir soit un système de stockage de données (BD4) de
tous les utilisateurs ou un annuaire. Cela donne lieu aussi à la centralisation de la gestion de la politique de sécurité et des droits d’accès. On compte parmi les logiciels qui illustre ce procédé, LemonLDAP.
Ce modèle est particulièrement désigné à des services qui appartiennent tous à une même entité. Par exemple au sein d’une entreprise, la gestion des intergiciels est fondée sur le modèle centralisé. En effet chaque entité (service) interdépendante a confiance dans l’authentification approuvée par le centre d’authentification (serveur SSO). On peut citer le compte Apple pour illustrer ce modèle. En effet il permet d’accéder à une multitude de modules tels qu’ App store (Plateforme de téléchargement d’application), iTunes store (service de vente en ligne de musique, films, séries, etc.), iCloud (service de nuage), etc., avec un seul compte et une seule authentification.
• Le modèle fédératif
Dans ce modèle, le système Liberty Alliance5 est le principal exemplaire, chaque entité
3. L’objectif de la propagation d’identités est double : déléguer l’authentification à l’établissement d’origine de l’utilisateur et obtenir certains attributs de l’utilisateur (pour gérer le contrôle d’accès ou personnaliser les contenus).[61]
4. BD = Base de données.
5. Liberty Alliance, aussi connu sous le nom de Project Liberty, est un projet qui réunit des acteurs des mondes industriel, informatique, bancaire et gouvernemental sous la forme d’un consortium. L’objectif est de définir des ensembles de spécifications de protocoles de fédération d’identité et de communication entre services
administre une partie des données d’un utilisateur A en partageant les informations dont il dispose sur l’utilisateur A avec les entités partenaires.
Cette approche a été mise en œuvre pour faire face à la nécessité d’une gestion décen-tralisée des utilisateurs, où chacune des entités partenaires souhaite garder le contrôle de leur propre politique de sécurité.
À titre d’exemple, considérons un partenariat commercial qui met en œuvre deux sites web. L’utilisateur a un même compte pour les deux sites, mais il doit pour chacun spé-cifier quelques informations importantes, telles que son adresse de livraison. Mais par contre, des informations telles que son login et son courriel sont partagées dans le but de cibler les goûts de l’utilisateur.
1.3
Modèle d’habilitation pour un système IAM
Il existe plusieurs modèles de contrôle d’accès bien documentés dans la littérature de la sécurité informatique et de nombreux articles en décrivent un grand nombre d’extensions. On distingue deux catégories de modèle d’habilitation principal que sont :
— les modèles classiques (Modèles discrétionnaires ou DAC6 et Modèles mandataires ou
MAC7)
— Les Modèles à rôles (RBAC)
Dans un système IAM et dans la majorité des entreprises, le principal modèle d’habilitation utilisé est RBAC8. Ce modèle repose sur la définition de rôles (ou profils) qui établissent le lien
en matière d’habilitation entre les utilisateurs et les ressources du SI. Nous nous intéresserons donc dans cette section du modèle RBAC et de ses dérivées.
1.3.1 Modèle RBAC
RBAC est présenté dans [28]. Dans ce modèle, la notion de rôle est le concept fondamental, les droits d’accès sont attribués à un rôle et si ce rôle est joint à un utilisateur ou à des groupes d’utilisateurs, alors ceux-ci obtiennent implicitement les droits d’accès à travers le rôle. Un rôle définit un ensemble de droits d’accès et est attribué à un ou plusieurs utilisateurs. Ainsi dans la gestion de RBAC, deux types de relations sont à considérer :
- La relation entre les rôles et les utilisateurs. - La relation entre les rôles et les permissions.
web. Ces protocoles sont conçus pour être mis en œuvre aussi bien dans le cadre de déploiements intra-entreprise qu’inter-entreprise.[62]
6. Discretionary Access Control. 7. Mandatory Access Control. 8. Role-Based Access Control.
1.3.2 Extensions du modèle RBAC
Le modèle RBAC connaît quelques limites dès lors que l’employé a des fonctions différentes qui dépendent du lieu géographique où il exerce (Ex. : un conseiller qui travaille dans plusieurs agences avec des fonctions différentes).
Des modèles d’habilitations proches du modèle RBAC existent pour pallier ce genre de spéci-ficité :
— ORBAC9 permet en plus des autorisations, de spécifier des interdictions et des
obliga-tions tout en s’appuyant sur des noobliga-tions de contexte.
— Risk-RBAC qui introduit la notion de risque et de délégation. Modèle ORBAC
Le modèle OrBAC (Organization-based Access Control) [56] est une évolution de RBAC. Le concept principal de ce modèle est d’exprimer la politique de sécurité avec des notions abstraites, et aussi de pouvoir distinguer la représentation d’une politique de sécurité de son implémentation en utilisant différents processus de contrôle d’accès. OrBAC définit la notion d’ « organisation » et spécifie les sujets, les objets et les actions respectivement en rôle (comme dans RBAC). OrBAC utilise aussi la notion de vue (View-based Access Control "VBAC" [57]), et aussi la notion d’activités (Task-based Authorization Controls "TBAC" [58]). Un rôle est attribué à un groupe d’utilisateurs, aussi une activité est attribuée à une ou plusieurs actions, et une vue est attribuée à un ou plusieurs objets. OrBAC introduit également la notion aussi de contexte et la définit comme étant une situation particulière qui détermine si une règle est valide ou pas.
Dans OrBAC, la définition des autorisations se fait comme suit : — Autorisation accordée ou Permission.
— Autorisation refusée ou Interdiction. — Des règles d’obligations de la forme
P ermission|P rohibition|Obligation(org; r; v; a; c), où org est une organisation, r un rôle, v une vue, a une activité et c un contexte.
On identifie deux paliers dans OrBAC : un palier abstrait dans lequel l’administrateur décrit la politique de sécurité en utilisant des règles sur les notions abstraites (rôles, activités, vues), et un palier concret où des utilisateurs exécutent des actions sur des objets dépendamment des règles spécifiées dans la politique. Pour illustrer formellement l’instanciation des règles de sécurité, considérons l’expression suivante :
∀org ∈ Org, ∀s ∈ S, ∀α ∈ A, ∀o ∈ O, ∀r ∈ R, ∀a ∈ A, ∀v ∈ V, ∀c ∈ C, P ermission(Org, r, v, a, c) ∧ Empower(org, s, r) ∧ Consider(org, α, a)∧ U se(org, o, v) ∧ Hold(org, s, α, o, c)
→ Ispermitted(s, α, o)
L’interprétation donnée à cette expression est la suivante :
si « dans l’organisation ‘org’, le rôle ‘r’ est autorisé à faire l’activité ‘a’ sur la vue ‘v’ quand le contexte ‘c’ est vrai », et si « dans l’organisation ‘org’, le rôle ‘r’ est attribué au sujet ‘s’ », et si « dans l’organisation ‘org’, l’action ‘’ est incluse dans l’activité ‘a’», et si « dans l’organisation ‘org’, l’objet ‘o’ est inclus dans ‘v’ » et si « le contexte ‘c’ est vrai pour le quadruplet (org, s, , o) », alors le sujet ‘s’ peut exécuter l’action ‘’ sur l’objet ‘o’.
Modèle Risk-RBAC
Il est capital d’introduire une relation d’ordre dépendamment de la valeur des objets et aussi de définir des actions délimiter afin de sécuriser ces objets.
Le présent modèle d’accès de contrôle dans cette sous-section introduit la notion de risque et de délégation, il s’agit du Risk-RBAC [59], qui est une évolution du modèle RBAC.
Le modèle RBACR est défini comme RBAC en y ajoutant une fonction de sécurité RF
(fonction d’analyse de risque) et un ensemble de niveaux de confiance C.
On affecte un niveau de confiance C à un utilisateur u ∈ U et on note CNF (u) : U → C et pour tous les rôles on calcule le niveau minimum de confiance noté MLC(R) : R → C. La valeur du risque attribué à un utilisateur u qui a un rôle R, noté rv(u, R), est compris entre 0 et 1.
Ce calcul s’effectue de la façon suivante :
rv(u, R) = (
0, si CN F (u) ≥ M LC(R) 1 −M LC(R)CN F (u), sinon
Comme spécifié plus haut, il est question également dans cet article de notion de délégation et du risque correspondant à cette délégation.
Il est noté del_rv(u1, u2) et traduit le risque produit sur les objets de u1 si u1 délègue son
rôle à u2.
Ce calcul s’effectue de la façon suivante : del_rv(u, R) = ( 0, si CN F (u1) ≥ CN F (u2) 1 −CN F (u1) CN F (u2), sinon .
1.4
Implémentation et contrôle pour un système IAM
La bonne gestion des processus d’entrée, sortie et mobilité des employés dans l’entreprise est importante afin de garantir la validité des identités, des habilitations et des accès. Une surcharge d’habilitation, l’utilisation de comptes utilisateurs désuets, la non-résiliation des droits dans les systèmes de gestion d’accès sont une partie des risques traités par la gestion du cycle de vie des identités. La mise en œuvre des processus métiers, et leur automatisation assure à l’entreprise un bon contrôle des identités et une meilleure gestion des accès au sein de l’entreprise. Pour ce faire nous allons définir les différents processus et techniques utilisés par un système IAM afin de garantir une bonne gestion des identités, des habilitations et des accès au sein de l’organisation.
1.4.1 Approvisionnement
Dans l’intention d’automatiser les tâches d’administration du SI et de repérer les incohésions et les écarts avec le modèle d’habilitations, la gestion des identités et des droits d’accès doit se baser sur des processus d’approvisionnement automatique.
Alimenter chaque référentiel de façon manuelle et indépendamment est source d’erreurs, et rend complexe la mise en place d’une politique de sécurité. Ce procédé représente également une perte de temps et de productivité pour une entreprise.
L’approvisionnement automatique, lorsque bien utilisé, garantira une bonne mise en œuvre des politiques d’habilitation sur le SI.
Selon [42], l’objectif de l’approvisionnement dans un système IAM est d’interagir avec les ressources externes en se connectant aux serveurs d’annuaire, aux systèmes d’application mé-tiers (RH, Administration...), et d’autres types de systèmes. Il récupère les informations des ressources et les modifie également si nécessaire.
Les responsabilités qui incombent au système d’approvisionnement sont en résumé :
— La gestion des objets sur les ressources (système cible / source). Les objets désignent toutes les entités liées à la gestion de l’identité, en particulier les comptes, les groupes, les rôles, les droits, les attributs de compte, etc. et on entend par gestion, l’exécution d’opé-rations telles que la récupération, création, modification et la suppression des objets. (CRUD)
— Fournir la possibilité de rechercher des objets de ressources. — Détecter des changements sur la ressource (système cible / source) — Masquer si nécessaire les informations obtenues à partir des ressources.
1.4.2 Réconciliation et synchronisation
L’un des grands challenges qui déterminent la gestion des identités et le contrôle des accès consiste dans l’interaction de plusieurs applications. Pour relever ce défi dans le monde des IAM, deux techniques sont souvent utilisés et demeurent incontournables de nos jours. Ce sont : la réconciliation et la synchronisation.
Réconciliation
La réconciliation est le processus de synchronisation bidirectionnelle des objets entre différents base de données et référentiels (LDAP, BD relationnelle) [33]. Elle s’applique principalement aux objets utilisateurs, aux groupes et aux rôles. Pour effectuer la réconciliation, un outil IAM analyse à la fois les systèmes sources et cibles afin de découvrir les différences qu’il faut concilier. La réconciliation ne peut donc être considérée comme un processus lourd et sert éga-lement de base pour l’analyse de conformité et peut être aussi utilisée dans les fonctionnalités de rapports (reporting) .
Synchronisation
Pour expliquer le processus de synchronisation, nous allons utiliser la figure1.1 comme illus-tration.
Des connecteurs placés sur des référentiels fournissent des événements ou des données au moteur de synchronisation. Le moteur de synchronisation interprète les événements en entrée, éventuellement les modifie, puis achemine aux référentiels cibles les événements ou données à intégrer. Ce fonctionnement de répartition de données est automatisé et régi par des règles statiques.
1.4.3 Attribution de privilège d’accès
La méthode d’attribution des identités numériques constitue un aspect important de la gestion des identités et des accès. Le processus d’octroi de privilèges d’accès fournit un outil puissant qui se sert des informations utilisateur existantes dans l’infrastructure d’annuaire de l’organi-sation, afin d’accroître le processus d’attribution et de révocation des comptes utilisateur aux ressources d’informations. Au nombre des ressources, on peut citer :
La messagerie électronique, le téléphone, les applications TI, les applications métiers et fonc-tionnelles, etc.
Les avantages liés à l’automatisation des processus sont nombreux, on peut citer entre autres : Une diminution des coûts et un accroissement de la productivité de façon radicale.
1.4.4 Workflow de validation
Bon nombre d’outils IAM de nos jours intègrent des moteurs de workflow10à leur architecture.
L’implémentation de cette solution consiste à mettre en œuvre une application de workflow simple, en général par une interface Web qui permet d’effectuer des étapes manuelles à l’in-térieur du processus d’attribution de privilèges d’accès automatique. Par exemple, considé-rons que l’embauche d’un employé exige l’approbation du gestionnaire, mais dans lequel le gestionnaire peut seulement approuver ses nouveaux employés. Lorsque le personnel des res-sources humaines crée un compte employé, il saisit les informations relatives au gestionnaire afin d’envoyer une notification par courrier électronique au gestionnaire approprié. Lorsque le gestionnaire se connecte au site Web, il peut parcourir la liste des nouveaux employés à approuver.
10. Le moteur de workflow est l’outil permettant de modéliser et d’automatiser les processus métiers de l’entreprise.
1.5
Outils de gestion des droits d’accès
Il existe diverses applications pour la gestion des droits d’accès dans le monde IAM. Bon nombre d’entre elles sont assignées à un environnement spécifique, et n’ont pas toujours les mêmes niveaux de tâche dépendamment de la fonction majeure que ces outils sont appelés à exercer. Ci-dessous, nous citons quelques outils de contrôle d’accès.
1.5.1 CA IdentityMinder
CA IdentityMinder [30] est un outil de gestion d’identité et de droit d’accès mise en œuvre par la compagnie CA Technologies. Il fournit la capacité de gérer et de gouverner les identités des utilisateurs et comme tout bon outil de gestion de droits d’accès répond à la question "Qui a accès à quoi ?". D’une façon aisée et productive, CA IdentityMinder permet également de gérer et de gouverner les outils nécessaires afin de prendre le contrôle des utilisateurs privilégiés dans les plateformes physiques, virtuels et de cloud computing. Élaborer pour être pratique à exploiter et productive, la gestion de CA IdentityMinder peut concourir à accroître l’efficacité, la sécurité et la conformité dans toute l’organisation. La compagnie CA a augmenté au fil du temps son offre de gestion IAM, en rachetant la compagnie ID Focus en octobre 2008 et Eurikify quelque temps après.
1.5.2 SetACL Studio
SetACL Studio est un outil de gestion pour des autorisations Windows. Cet outil administre les droits d’accès des utilisateurs et donne lieu à la mise en œuvre d’audits. Il possède une interface utilisateur très intuitive pour une bonne gestion des autorisations, sans oublier sa fonctionnalité qui se met en œuvre aussi bien sur le réseau qu’en local. Il est possible d’utiliser des scripts afin de construire certaines automatisations dans l’élaboration et l’administration de droits d’accès.
1.5.3 midPoint
midPoint [31] est un système d’approvisionnement d’identités . Le provisionning d’identités est un sous champ de l’identité et de gestion des accès (IAM). Un logiciel de provisionnig prend en charge les tâches techniques (IT) qui se produisent quand un nouvel employé se joint à une entreprise, lorsque ses responsabilités changent, quand il quitte l’entreprise, quand un nouvel entrepreneur est inscrit et ainsi de suite. Ceci est appelé cycle de vie d’une identité : l’ensemble des événements et des tâches qui font en sorte que chaque «identité» a ce qu’il faut. midPoint est un outil complet qui permet de synchroniser plusieurs référentiels d’identités et des bases de données, les gère et les rend disponibles sous une forme unifiée. Il appartient à la catégorie Identity Provisioning du champ Enterprise Identity Management, cependant midPoint lui-même ne se limite pas à l’entreprise. Il peut tout aussi bien fonctionner pour les
services de cloud computing, les portails Internet, les opérateurs télécom et les fournisseurs de services et ainsi de suite.
Figure 1.2 – midPoint[31].
1.5.4 IBM Security Identity and Access Assurance
Le logiciel IBM Security Identity and Access Assurance présente une solution pour la gouver-nance d’un système IAM. La solution IBM est composée de cinq progiciels dont :
- IBM Security Identity Manager qui est une solution qui aide au niveau de la gestion d’iden-tité, elle donne lieu à la gestion de comptes utilisateur, de rôles, etc. dans tout le système informatique.
- IBM Security Access Manager for Enterprise Single Sign-On quant à elle utilise les fonctions SSO couplées avec d’autres facteurs d’authentification dans le but de renforcer l’accès utilisa-teurs à différentes applications.
- IBM Security Access Manager for Web définit une plateforme pour la gestion d’autorisation des applications web. Il aide également à déployer plusieurs applications sécurisées .
- IBM Tivoli Federated Identity Manager utilise le modèle fédératif (vu dans la sous-section 1.2.1) dans le but de partager les données de façon sécuritaire entre plusieurs organisations. - IBM Security QRadar Log Manager permet de faire la gestion et l’analyse de journaux (fi-chier log), ces dits fi(fi-chiers pourront être utilisés afin de réduire le risque de menace de sécurité. Il est à noter que IBM a racheté Access360 en 2002 et Encentuate en mars 2008, ces rachats on permis à IBM de développer sa suite IAM en intégrant l’Entreprise Single Sign On (eSSO).
1.5.5 LinID
LinID est la seule suite logicielle de gestion d’identité "Open Source", qui permet de gagner en efficacité et en sécurité dans la gestion des données d’identité, d’accès et d’habilitation. Cette suite est développée par l’entreprise Linagora, une entreprise française qui oeuvre dans le monde de l’open source. LinID est principalement utilisé dans l’environnement Windows où est déployé un domaine active directory.
1.5.6 OpenIDM
OpenIDM, édité par ForgeRock, est un système de gestion d’identité open source écrit en Java. OpenIDM exploite JavaScript comme langage de script par défaut pour définir les règles d’affaires pendant l’approvisionnement. Il est basé sur un outil d’approvisionnement nommé OpenICF qui est un framework que l’on peut utiliser avec java et .NET. OpenIDM permet aux organisations d’automatiser la gestion du cycle de vie de l’identité de l’utilisateur en temps réel, y compris la gestion des comptes utilisateurs et des droits d’accès dans les applications. Léger et agile, OpenIDM a été conçu pour aider les organisations à assurer la conformité avec les politiques et les exigences réglementaires à travers l’entreprise, cloud, les environnements sociaux et mobiles.
1.5.7 Quest One Identity
Membre de la suite de Quest Software de l’entreprise DELL, Quest One Identity assure le contrôle des accès et l’administration des identités et améliore, en plus, la vérification de conformité en consolidant l’automatisation et la génération de rapports.
Quest One vous permet de trouver rapidement et facilement les comptes et les utilisateurs qui possèdent des droits d’accès inadaptés. Quest One Identity permet d’effectuer une découverte approfondie des environnements Active Directory et accéder à la gouvernance de toute l’en-treprise.
Il fonctionne sous Windows et est optimisé pour une architecture basée sur Active directory de Windows.
1.5.8 Varonis Datadvantage
Varonis donne lieu à la gestion de permissions de fichier Windows, toutefois sa spécificité se situe au niveau des alertes. En effet, Varonis permet de recevoir des alertes en temps réel sur toute modification faite aux fichiers ou aux dossiers contenus dans les systèmes de fichiers Windows et périphériques NAS11. Les administrateurs sont prévenus de tous changements
apportés aux fichiers de configuration importants, les accès aux données sensibles, les événe-ments de refus d’accès et plus encore. Ils reçoivent ces alertes par courrier électronique, SNMP, journal des événements, syslog ou directement dans le système de gestion des informations et événements de sécurité.
1.5.9 Étude comparative
Plusieurs outils IAM existent sur le marché du contrôle d’accès, ils ont plusieurs fonctions communes cependant, chacun d’eux se démarque par une spécificité propre à chaque outil. Ce tableau est une illustration de certains critères que nous avons établis pour les outils cités plus haut.
Contrôle d’accès
SSO Gestion des mots de passe
SNMP Audits Script Gestion d’alertes OpenIDM • • • • • CA Identity-Minder • • • • SetACL studio • • • • • • midPoint • • • • • IBM Security Identity and Access Assu-rance • • • • • Varonis Datad-vantage • • • • • • Quest One Identity • • • • • LinID • • • • •
Tous les outils IAM mentionnés ci-dessus ont en commun des politiques de sécurité statique. En outre, les procédés de validation de droits d’accès ainsi que l’audit sont mis en œuvre par les gestionnaires de sécurité qui, alerté par un processus de sécurité (alerte, scan, plainte utilisateur), s’appuie en général sur les résultats des fichiers logs. Vu cette façon de gérer l’environnement de sécurité, il est indispensable de mettre en oeuvre des outils "Ontologiques", ayant une base formelle qui aideront à établir une analyse des droits d’accès afin de vérifier le respect ou non d’une politique de sécurité donnée, et ce de façon automatique.
1.6
Normes et référentiels de sécurité
De nos jours, la gestion et la sécurité d’un Système d’Information sont difficiles à mettre en œuvre sans l’utilisation de normes et de référentiels de sécurité. En effet, ces référentiels garantissent une bonne cohérence des processus ainsi que de bonnes pratiques au sein de l’organisation. Plusieurs référentiels et normes existent, mais nous allons nous contenter d’en
présenter quelques-uns.
1.6.1 Norme ISO 27002
La norme ISO/CEI 27002 est une norme internationale concernant la sécurité de l’informa-tion, publiée en 2005 par l’ISO, dont le titre en français est "Code de bonnes pratiques pour le contrôle de la sécurité de l’information" . Elle fait partie de la suite ISO/CEI 27000.[66] ISO 27002 définit un ensemble de bonnes pratiques de la sécurité de l’information adaptée aux entreprises. Cette norme propose plusieurs mesures de sécurité sur le plan organisationnel et technique.
En 2005, deux normes sont éditées :
la norme ISO/CEI 17799, qui modifie les domaines et objectifs, et la norme ISO/CEI 27001 qui introduit la notion de Système de Management de la Sécurité de l’Information (SMSI). La norme ISO 17799 se voit remplacer en 2007 par la norme ISO 27002, qui a été mise à jour en 2013, cette mise à jour spécifie 18 chapitres, 35 objectifs de sécurité et 113 mesures de sécurité. On peut dès lors, définir un objectif comme étant le projet à réaliser par l’implémentation de procédures de contrôle à l’intérieur d’une pratique TI et une mesure de sécurité quant à elle, l’ensemble de pratiques qui garantit que les objectifs seront accomplis [67].
Voici le contenu (chapitres) de la norme ISO 27002 : — Chapitre 1 : Champ d’application.
— Chapitre 2 : Termes et définitions.
— Chapitre 3 : Structure de la présente norme.
— Chapitre 4 : Évaluation des risques et de traitement. — Chapitre 5 : Politiques de sécurité de l’information. — Chapitre 6 : Organisation de la sécurité de l’information. — Chapitre 7 : Sécurité des ressources humaines.
— Chapitre 8 : Gestion des actifs. — Chapitre 9 : Contrôle d’accès. — Chapitre 10 : Cryptographie.
— Chapitre 11 : Sécurité physique et environnementale. — Chapitre 12 : Sécurité liée à l’exploitation.
— Chapitre 13 : Sécurité des communications.
— Chapitre 14 : Acquisition, développement et maintenance des systèmes d’information. — Chapitre 15 : Relations avec les fournisseurs.
— Chapitre 17 : Aspects de la sécurité de l’information dans la gestion de la continuité d’activité.
— Chapitre 18 : Conformité.
Nous allons maintenant voir selon [67], les chapitres qui sont en rapport avec l’analyse de conformité :
— Politiques de sécurité de l’information (chapitre 5) — Contrôle d’accès (Chapitre 9)
— Conformité (chapitre 18)
Politiques de sécurité de l’information
L’objectif concernant ce chapitre est d’apporter à la sécurité de l’information une orientation et un soutien de la part de la direction, conformément aux exigences métier et aux lois et règlements en vigueur. Pour ce faire une mesure et des préconisations de mise en œuvre sont définies dans cette norme pour chaque chapitre.
La mesure dans ce chapitre, recommande de définir un ensemble de politiques en matière de sécurité de l’information qui soit approuvé par la direction diffusé et communiqué aux salariés et aux tiers concernés.
La mise en œuvre préconisée des politiques de sécurité de l’information, traitent des exigences créées par la stratégie d’entreprise sans oublier les réglementations, la législation et les contrats. Cette politique de sécurité comporte des précisions concernant :
— Une définition de la sécurité de l’information, ses objectifs et ses principes pour orienter toutes les activités relatives à la sécurité de l’information ;
— Des processus de traitement des dérogations et des exceptions. Contrôle d’accès
L’un des objectifs concernant ce chapitre est de limiter l’accès à l’information et aux moyens de traitement de l’information.
La mesure dans ce chapitre, recommande d’établir, de documenter et de revoir une politique du contrôle d’accès sur la base des exigences métier et de sécurité de l’information.
La mise en œuvre préconise que les propriétaires des actifs déterminent des règles de contrôle d’accès, des droits d’accès et des restrictions d’accès appropriés aux fonctions spécifiques de l’utilisateur des actifs, avec la quantité de détails et la rigueur des mesures correspondant aux risques associés en matière de sécurité de l’information.
Selon la norme, il convient que la politique du contrôle d’accès tienne compte des exigences de sécurité suivantes :
— cohérence entre la politique des droits d’accès et la politique de classification de l’infor-mation des différents systèmes et réseaux ;
— gestion des droits d’accès dans un environnement décentralisé mis en réseau qui reconnaît tous les types de connexions disponibles ;
— cloisonnement des rôles pour le contrôle d’accès, par exemple la demande d’accès, l’au-torisation d’accès et l’administration des accès ;
— annulation de droits d’accès. Conformité
L’objectif de ce chapitre est de garantir que la sécurité de l’information est mise en œuvre et appliquée conformément aux politiques et procédures organisationnelles.
La mesure dans ce chapitre, recommande d’une part, de procéder à des revues régulières et indépendantes de l’approche retenue par l’organisation pour gérer et mettre en œuvre la sécu-rité de l’information (à savoir le suivi des objectifs, les mesures, les politiques, les procédures et les processus relatifs à la sécurité de l’information) à intervalles définis ou lorsque des chan-gements importants sont intervenus.
D’une autre part, elle recommande que les responsables revoient régulièrement la conformité du traitement de l’information et des procédures dont ils sont chargés au regard des politiques, des normes de sécurité applicables et autres exigences de sécurité.
La mise en œuvre préconise que la direction instaure une revue indépendante. Des revues indépendantes sont nécessaires pour veiller à la pérennité de l’efficacité de l’approche de l’or-ganisation en matière de management de la sécurité de l’information. Elle préconise aussi dans un premier temps, que les responsables déterminent la manière de vérifier que les exigences de sécurité de l’information définies dans les politiques, les normes et autres règlementations applicables, sont respectées. Et dans un deuxième temps, elle recommande d’envisager l’utili-sation d’outils de mesure et d’enregistrement automatisés pour procéder à des revues régulières efficaces.
Si la revue détecte une non-conformité, il convient que les responsables : — déterminent les causes de la non-conformité ;
— évaluent la nécessité d’engager des actions pour établir la conformité ; — mettent en oeuvre l’action corrective appropriée ;
— revoient l’action corrective entreprise pour vérifier son efficacité et identifier toute insuf-fisance ou faille.
1.6.2 Norme ISO 27001
L’ISO/CEI 27001 est une norme internationale de système de gestion de la sécurité de l’infor-mation de l’ISO et la CEI. Publiée en octobre 2005 et révisée en 2013, son titre est
"Technolo-gies de l’information - Techniques de sécurité - Systèmes de gestion de sécurité de l’information - Exigences". Elle fait partie de la suite ISO/CEI 27000.[63]
La norme ISO 27001 enseigne le personnel responsable de la sécurité dans les entreprises sur la manière de construire, procéder, entretenir et optimiser un Système de Management de la Sécurité de l’Information (SMSI) dans l’intention de maintenir la sécurité de l’information au sein de l’entreprise. Pour ce faire, la norme ISO 27001 utilise une approche d’amélioration continue connue sous le nom de PDCA (Plan-Do-Check-Act).
— PLAN : Dans cette phase, il s’agit de définir le périmètre, c’est à dire le domaine d’appli-cation du SMSI et spécifier les besoins en sécurité. À ce stade, une politique de sécurité est élaborée, la réalisation de l’analyse des risques, le traitement des risques et le choix des mesures de sécurité à mettre en place.
— DO : Ce stade permet d’établir un plan de traitement des risques afin que les objectifs du SMSI défini soient opérationnels. Il consiste également à déployer les mesures de sécurité sans oublier la formation du personnel.
— CHECK : La phase check comme son l’indique, consiste à détecter les erreurs. C’est également dans cette phase que se déroulent les audits et les contrôles internes.
— ACT : Le SMSI est optimisé au regard des résultats de la phase CHECK, des actions correctives et préventives sont ainsi élaborées.
Nous allons maintenant voir selon [71], les sections qui sont en rapport avec l’analyse de conformité dans l’approche de l’amélioration continue (PDCA).
Phase Do
C’est dans cette phase que les objectifs de sécurité sont définis ainsi que les plans pour les atteindre.
Dans la norme iso 27001 :2013, il est dit que l’organisation doit établir, aux fonctions et niveaux concernés, des objectifs de sécurité de l’information. Ces objectifs à leur tour doivent à leur tour :
— être cohérents avec la politique de sécurité ; — être mesurables (si possible)
— tenir compte des exigences applicables à la sécurité de l’information, et des résultats de l’appréciation et du traitement des risques ;
— être communiqués et aussi mis à jour quand cela est approprié. Phase Check
Cette phase est l’une des plus importantes dans le processus d’analyse de conformité, car elle consiste à détecter les incidents et les non-conformités.
Pour cette sous-section, l’organisation doit réaliser des audits internes à des intervalles planifiés afin de recueillir des informations permettant de déterminer si le système de management de la sécurité de l’information est conforme aux exigences propres de l’organisation et aux exigences de la présente norme.
Pour ce faire l’organisation doit :
— Planifier, établir, mettre en œuvre et tenir à jour un ou plusieurs programmes d’audit ; — définir des critères d’audit et le périmètre de chaque audit ;
— sélectionner des auditeurs et réaliser des audits qui assurent l’objectivité et l’impartialité du processus d’audit ;
— conserver des informations documentées comme preuves de la mise en œuvre des pro-grammes d’audit et des résultats d’audit.
Phase Act
Comme mentionné plus haut, cette phase donne lieu principalement à la mise en place d’ac-tions corrective. À cet effet, la norme recommande lorsqu’une non-conformité se produit, l’organisation doit :
— réagir à celle-ci et le cas échéant, traiter les conséquences ;
— évaluer s’il est nécessaire de mener une action pour éliminer les causes de la non-conformité, de sorte qu’elle ne se reproduise plus ;
— mettre en œuvre toutes les actions requises ;
— réviser l’efficacité de toute action corrective mise en œuvre. 1.6.3 COBIT
COBIT (Control Objectives for Business Related Technology) [64] est une approche pour les gestionnaires, auditeurs et utilisateurs qui aide à évaluer les risques et à déterminer le niveau de contrôle afin de mieux protéger l’organisation. En effet, COBIT est un référentiel pour la gouvernance et l’audit des Systèmes d’Information développé par l’ISACA12. COBIT adopte
une approche orientée processus qui consiste à décomposer tout Système d’Information en 34 processus regroupés en 4 domaines. Ces domaines sont entre autres :
— Planification et Organisation : l’objectif principal définit un plan stratégique pour le Système d’Information basé sur l’efficacité, l’architecture et la stratégie technologique tout en tenant compte de la gestion de son investissement. Ce domaine comprend ce qui concerne l’organisation du Système d’Information et ses relations avec la direction quant à sa stratégie et le métier de l’entreprise. De plus, tout principe d’organisation implique de traiter d’une part la gestion des ressources humaines et d’autre part, des 12. ISACA : Information System Audit Control Association
projets avec les critères de qualité et les risques associés tout en assurant la conformité avec les besoins externes.
— Acquisition et mise en œuvre : ce domaine décrit dans une première partie les processus d’identification des solutions automatisées, d’acquisition, de la gestion d’actifs (infra-structure technologique, logiciels applicatifs) et leur adéquation avec les besoins métiers. Ensuite viennent lors de la mise en œuvre, le développement et la maintenance de pro-cédures, l’installation et l’accréditation des systèmes. Enfin, tout système étant évolutif, la gestion des changements est prise en compte.
— Livraison et Support : ce domaine comporte des processus équivalents à ceux décrits dans ITIL. Ce qui permet de retrouver :
- la définition et la gestion des niveaux de service, l’assistance aux clients et utilisateurs ; - la gestion de la performance et de la capacité ;
- la gestion de la configuration ;
- la gestion des incidents et des problèmes.
— Monitoring : ce dernier domaine s’occupe de la partie supervision des processus et de l’aspect audit sous forme d’évaluation de l’adéquation du contrôle interne, souvent à partir d’apports externes et indépendants.
En résumé, COBIT est un référentiel pour auditer l’activité du Système d’Information dans l’environnement d’une grande organisation.
1.6.4 ITIL
ITIL (Information Technology Infrastructure Library) est une mise en œuvre de bonnes pra-tiques pour le management des processus informapra-tiques [65]. Présentement en version 3 (Figure
1.4), ITIL est une bibliothèque qui dénombre, résume et expose les meilleures pratiques pour un service informatique.
Au nombre de ces pratiques, on peut citer :
— La stratégie des services (service strategy) qui définit les processus comme la gestion financière, la gestion du portefeuille des services, la gestion des demandes, etc. .
— La conception des services (service design), qui permet mettre en relation des processus, assurer la sécurité des informations, maintenir un niveau de stock permettant de répondre à la demande, etc. .
— La transition des services (service transition) qui est composé de processus donnant lieu à la gestion des changements, à la gestion des mises en production, sans oublier le service de test et validation.
— L’exploitation des services (service operation) qui prend en charge les processus comme la gestion des accès, la gestion des incidents, la gestion des problèmes, etc. .
Figure 1.4 – ITIL version 3 [65].
1.7
Conclusion
Dans ce chapitre, nous avons présenté les principes fondamentaux et les pratiques liées à une bonne gestion des identités et des droits d’accès. Nous avons également défini les différents processus et techniques utilisés par un système IAM afin de garantir une bonne gestion des identités, des habilitations et des accès au sein d’un système d’information. Finalement, une ébauche de quelques outils de contrôle d’accès et norme de sécurité ont été définies afin d’aider les administrateurs à choisir la technologie adaptée à leur besoin.
Cette mise en œuvre des concepts et pratiques autour du contrôle d’accès vient nous confor-ter dans l’élaboration de nos travaux et nous permet d’aborder la partie suivante, où il est question de la représentation des droits d’accès sous Windows et Linux.
Chapitre 2
Représentation des droits d’accès sous
Windows et Linux
2.1
Introduction
La sécurisation des systèmes informatiques est un domaine ouvert uniquement à un certain nombre de personnes regroupant des compétences et un savoir-faire avéré. En effet, la sé-curité informatique fait ressortir plusieurs notions telles que l’intégrité, la disponibilité, la confidentialité, la non-répudiation et l’authentification des données circulant au sein d’un sys-tème d’information. Ainsi, l’un des axes principaux de la sécurité informatique est le contrôle d’accès.
Le contrôle d’accès est la mise en œuvre de procédures permettant de vérifier qu’une entité voulant avoir accès à une ressource bénéficie des droits ou habilitations nécessaires pour le faire. Il se fait de façon générale en se basant sur une politique de sécurité.
En effet, cette méthode de contrôle d’accès peut être remarquée aussi bien dans le domaine des infrastructures informatique, que dans la vie de tous les jours. Prenons le cas d’une personne qui veut retirer de l’argent au guichet automatique, le contrôle d’accès se définit ici par le faite de vérifier que la personne dispose de sa carte bancaire et du bon NIP.
Afin de sécuriser les ressources, plusieurs systèmes d’information mettent en œuvre un système de contrôle d’accès en s’appuyant sur des modèles comme le MAC1, DAC2, RBAC3 , etc. Un
modèle de contrôle d’accès est la mise en œuvre d’une méthode définissant des règles pour la répartition des droits d’accès.
Dans ce chapitre, nous allons définir les notions qui environnent le contrôle d’accès dans la 1. MAC : contrôle d’accès obligatoire.
2. DAC : contrôle d’accès discrétionnaire. 3. RBAC : contrôle d’accès à base de rôles.
section 1 ; dans la section 2 et 3, il s’agira de montrer les représentations du contrôle d’accès sous Linux et Windows, et finalement dans la section 4 nous représenterons quelques interfaces utilisateurs de gestion de contrôle d’accès.
2.2
Contrôle d’accès : définitions et politiques
Faisant référence au livre "Un cadre sémantique pour le contrôle d’accès" [2], on y découvre une représentation particulière en ce qui concerne la traduction des modèles d’accès.
Définition et notation : -Entités
Les entités du système sont subdivisées en deux ensembles :
— l’ensemble S des sujets, aussi appelé "entités actives", qui représente les entités qui exécutent les actions dans le système.
— l’ensemble O des objets, aussi appelé "entités passives", qui supporte les actions. Les sujets et les objets sont en général jugés aussi bien que des entités atomiques. Parmi plusieurs modèles, on fait allusion au terme utilisateur plutôt qu’ objet. Ces deux termes ne sont pas forcément distincts : par exemple, un processus peut parallèlement être un utilisateur parce qu’il exécute des opérations et un objet, dans l’option où un deuxième processus essaie de le stopper.
-Accès
L’ensemble des accès noté A, représentent les multiples modes d’accès exécutés par les sujets sur les objets. Cet ensemble inclut de façon générale les accès de type "read, write, execute, etc.". De façon formelle on peut décrire un accès A par un triplet (s, o, x) traduisant que le sujet s a accès à l’objet o selon le mode d’accès x.
-Paramètres de sécurité
Quelques informations liées aux entités sont utiles et essentielles afin d’être à même de mieux exprimer une politique de sécurité dans un système d’information donné. Ces informations émanent de ce que nous dénommerons les paramètres de sécurité et sa notation est ρ.
-État
Un état correspond à un instant donné du système et comprend toujours un descriptif de l’ensemble des accès, à savoir tous les accès admis, mais dont le processus reste inachevé. On note cet ensemble Σ.
-Fonction de sécurité
paramètres de sécurité. Puisque ces fonctions de sécurité sont définies par les états, elles sont modifiables lors des phases de transitions, à l’encontre des paramètres de sécurité, qui sont définitifs pour une politique donnée.
On définit Υ(σ), σ dans Σ, exprime le groupe des fonctions de sécurité de l’état σ. Υ : Σ → SF 4.
-Accès courant
Un accès courant traduit un accès qui a été admis, mais dont le processus reste inachevé. L’ensemble des accès courants est noté Λ. De même on à :
Λ : Σ → ℘(A)
Où ℘(A) désigne l’ensemble des parties de A. Compte tenu un état σ, Λ(σ) traduit l’ensemble des accès courants du système dans l’état σ.
-Prédicat de sécurité
Une politique de sécurité décrit les états sûrs d’un système. Ces états sûrs sont déterminés par un prédicat de sécurité et sa notation est Ω.
-Politique de sécurité
Une politique de contrôle d’accès se base sur des paramètres de sécurité. Les paramètres de sécurité étant notés ρ, une politique de sécurité d’accès P[ρ] est traduite par un quintuple :
P[ρ] = (S, O, A, Σ, Ω)
où S est un ensemble de sujets, O un ensemble d’objets, A un ensemble de modes d’accès, Σ l’ensemble des états du système et Ω un prédicat de sécurité caractérisant les états sûrs.
Figure 2.1 – Concepts de base pour le contrôle d’accès dans Linux
2.3
Contrôle d’accès sous Linux
2.3.1 Concepts de base pour le contrôle d’accès dans Linux
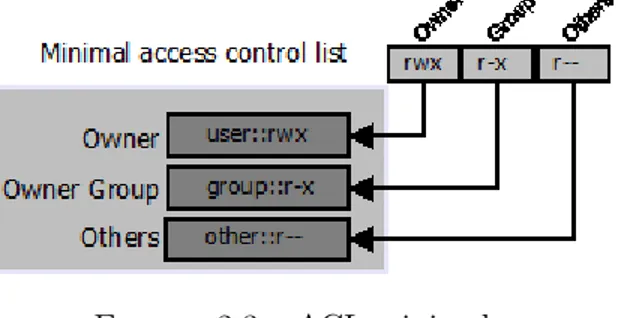
Sur Linux, le contrôle d’accès s’élabore conformément au modèle DAC. Effectivement, dans les systèmes d’exploitation Linux, un objet, qui peut être un fichier ou un processus, se rapporte à un propriétaire appelé Owner et est aussi combiné à un groupe appelé Owner Group. Le restant des utilisateurs appelés Others sont considérés dans la définition des droits d’accès sur un objet.
Excepté l’utilisateur suprême (root) qui administre totalement tous les objets du système, uniquement le Owner peut accéder et modifier ses objets ; sans compter qu’il est également le seul à pouvoir déléguer des droits d’accès au Owner Group et aux Others.[9]
Les droits d’accès donnés à un objet sont traduits par trois entités de trois caractères qui appartiennent à l’ensemble : {r, w, x, −}.
La première entité de trois caractères indique le droit d’accès du Owner, la deuxième de trois caractères traduit les droits d’accès du Owner Group et la troisième entité de caractères indique les droits donnés au Others . (Voir Figure 2.1). Dès lors on parvient à trois entités de trois caractères. Le premier caractère de chacune des entités accorde le droit de lecture s’il retourne "r", autrement il retourne "−" et le droit de lecture n’est pas accordé.
Le deuxième caractère de chacune des entités accorde le droit d’accès en écriture sur un objet s’il retourne "w" sinon il retourne "−" et le droit d’écriture n’est pas accordé.
Le troisième caractère d’une entité accorde l’autorisation d’exécuter un objet s’il retourne "x" sinon il retourne "−" et le droit d’exécuter n’est pas accordé".
En exécutant la commande ls -l , on a les droits d’accès des différents fichiers ainsi que le présente la figure 2.2.
Figure 2.2 – Droit d’accès Linux : Exemple.
Selon l’exemple, le premier caractère révèle la nature de l’objet. Le caractère d nous indique que la nature du fichier est un dossier, tandis que le caractère − quant à lui nous indique que la nature de l’objet est un fichier. Les caractères ci-après traduisent les droits d’accès
pour respectivement le Owner, Owner Group et Others. La valeur drwxr − xr − x signifie que le Owner a les droits de lecture, d’écriture et de "traversée"(c’est-à-dire qu’on peut voir les sous-dossiers que le dossier contient) ; le Owner Group et le Others ont le droit de lecture et de "traversée". Sous Linux, les droits d’accès sont modifiables le Owner où le root en utilisant la commande chmod.
Le bit setuid
Quand un utilisateur lance un programme, celui-ci s’exécute avec les droits de cet utilisateur. Mais souvent, on veut lancer une commande spéciale (en général réservé au super utilisateur) en tant que simple utilisateur. L’exemple le plus manifeste étant la commande passwd dont le chemin d’accès est /usr/bin/passwd qui est une commande root.
$ ls -l /usr/bin/passwd
-rwsr-xr-x 1 root root 25036 2013-10-02 11:08 /usr/bin/passwd
En regardant les droits sur passwd, on s’aperçoit que ce fichier est affecté par le bit setuid : c’est-à-dire que lorsqu’un utilisateur lance la commande passwd, elle est lancée avec les droits du root, ainsi l’écriture pourra se faire dans le fichier /etc/passwd et l’utilisateur aura changé son mot de passe sans être root. Sans le setuid5, l’utilisateur n’aurait pas pu écrire dans le
fichier /etc/passwd.
setuid est un attribut de fichier spécial qui indique au système d’exécuter certains programmes sous un ID utilisateur spécifique.[36]
Il est à noter que la notion de setuid n’existe pas pour les répertoires. Le bit setgid
La théorie du setgid6 est le même que le setuid pour un fichier, mais assurément au niveau
des droits du groupe. Un exécutable affecté par le bit setgid peut donc être déclenché avec les droits du groupe auquel il se rapporte.
En revanche, le comportement change lorsqu’il s’agit d’un répertoire. Quand il s’agit d’un répertoire, tous les fichiers créés dans ce répertoire appartiennent au même groupe que le répertoire. Exemple : prenons le cas d’un répertoire contenant plusieurs utilisateurs qui tra-vaillent sur celui-ci pour un même projet, il est bon d’affecter le bit setgid au dossier, de cette manière, les fichiers mis en œuvre appartiendront tous au même groupe.
drwxrws--- 2 tux projet1 48 Jan 19 10:12 backup 5. setuid = Set User ID.
le s signifie que le bit setuid est défini pour l’autorisation du groupe. Le propriétaire du dossier backup et les membres du groupe projet1 peuvent accéder au dit dossier.
Le sticky bit
L’utilisation du bit collant (sticky bit) est différente dépendamment de s’il appartient à un fichier ou à un répertoire. S’il est assigné à un fichier, alors le fichier en question est chargé dans la mémoire vive pour éviter d’avoir à le recueillir du disque dur à chacune de ces utilisations . Si ce bit appartient à un répertoire, alors son but est d’empêcher les utilisateurs de supprimer leurs fichiers respectifs. Les exemples spécifiques sont entre autres les répertoires /tmp et /var/tmp.
drwxrwxrwt 2 root root 1160 2002-11-19 17:15 /tmp
le t indique que le sticky bit est attribué au répertoire /tmp, dont l’accès en écriture demeure possible par tous les utilisateurs, sans que ceux-ci se suppriment leurs fichiers.
2.3.2 Gestion des listes de contrôles d’accès sous Linux
La majorité de plusieurs développements du modèle de sécurité Linux demeurait des fonction-nalités du modèle d’accès discrétionnaire. Les groupes de recherche Unix, ont mis au point chacun leurs propres améliorations, souvent très semblables les unes aux autres, des travaux laborieux ont été consentis pour essayer de les standardiser.
Les ACL (listes de contrôle d’accès) POSIX pour Linux sont fondées sur la proposition première du standard POSIX [35]. Elles sont employées comme une avancée de la notion traditionnelle d’autorisation pour les objets système de fichiers. Les ACL donnent lieu à la mise en œuvre des autorisations plus aisément que le concept d’autorisation traditionnel.
Avantage des ACL
En général, trois entités d’autorisations sont spécifiées pour chacun des objets (fichier) sous Linux. Ces entités englobent les autorisations lire (r), écrire (w) et exécuter (x) pour chacun des trois types d’utilisateurs : le Owner, le group et les others. Par ailleurs, il est possible de définir les bits set user id et set group id comme nous l’avons vu plus haut.
Cette notion élémentaire est absolument adaptée dans une grande partie des cas pratiques. Toutefois, pour les scénarios plus délicats ou les applications avancées, les administrateurs système jadis étaient obligés d’adopter plusieurs moyens pour contourner les limitations du concept d’autorisation traditionnel.
![Figure 1.1 – Processus de synchronisation [60].](https://thumb-eu.123doks.com/thumbv2/123doknet/5804644.139889/26.918.268.609.621.1019/figure-processus-de-synchronisation.webp)
![Figure 1.2 – midPoint[31].](https://thumb-eu.123doks.com/thumbv2/123doknet/5804644.139889/29.918.154.811.160.446/figure-midpoint.webp)
![Figure 1.3 – Architecture OpenIDM [31].](https://thumb-eu.123doks.com/thumbv2/123doknet/5804644.139889/30.918.125.752.573.1015/figure-architecture-openidm.webp)
![Figure 1.4 – ITIL version 3 [65].](https://thumb-eu.123doks.com/thumbv2/123doknet/5804644.139889/39.918.183.779.100.700/figure-itil-version.webp)

![Table 2.1 – Types d’entrées ACL [36].](https://thumb-eu.123doks.com/thumbv2/123doknet/5804644.139889/47.918.329.631.644.811/table-types-d-entrées-acl.webp)
![Figure 2.5 – ACE de type accès accordé [13].](https://thumb-eu.123doks.com/thumbv2/123doknet/5804644.139889/57.918.143.879.111.526/figure-ace-type-accès-accordé.webp)
![Figure 2.6 – ACE de type accès refusé [13].](https://thumb-eu.123doks.com/thumbv2/123doknet/5804644.139889/58.918.110.859.109.507/figure-ace-type-accès-refusé.webp)

