Overlapping Waves in Tool Use Development: a Curiosity-Driven Computational Model
Texte intégral
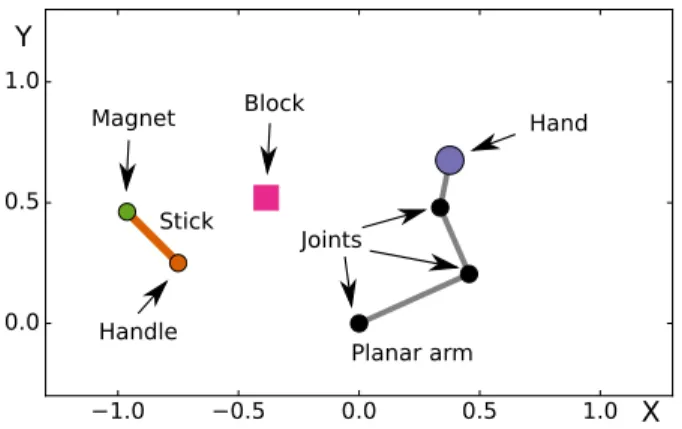
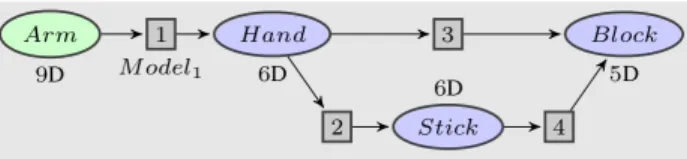
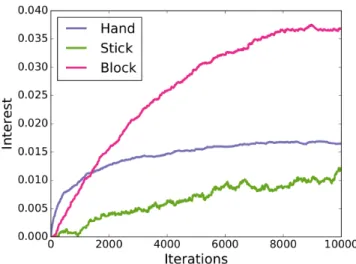
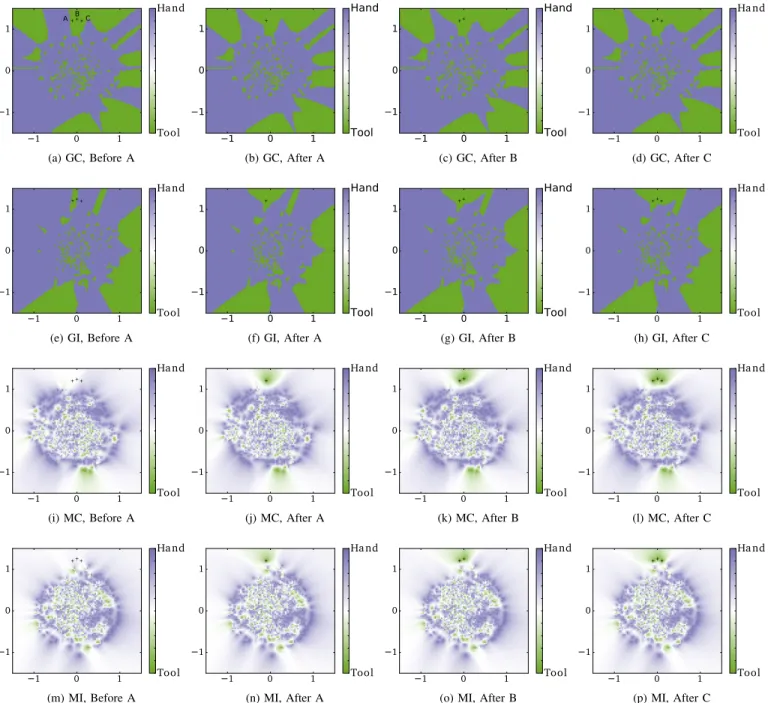
Figure
Documents relatifs
Focusing on the environment of firms, meta-organizations – organizations which members are themselves organizations (Ahrne and Brunsson, 2008 ; Gulati et al., 2012) –
• Right to effective remedy (47 CFR) • …also for negative
Along these lines, this paper describes an innovative home- based hand rehabilitation system device that exploits sensory substitution of median sensory deficits
We conducted a one-semester university course focusing on pre-service teachers’ learning to analyse the use of multiple representations in mathematics classroom situations
3.1, are the following: (1) The proposed algorithm converges for a class of games broader than the one of the RLA; (2) It allows a transmitter to learn its distributed strategy but
In a first approximation, the size of the cavity defines the range of the resonance frequency; the electron density profile, up to the upper atmospheric boundary, controls the
For instance, a cell complex model of a three-dimensional multicellular organism models not only the three-dimensional cells, but the two- dimensional cell walls connecting
—► Positive: Introduction of fish farming —► Negative: Decline in fish sizes, numbers and types caught, increase of water weeds (water hyacinth). R e c o m m e n d a tio
