Aide intelligente pour la surveillance d'examens
108
0
0
Texte intégral
Figure

+7



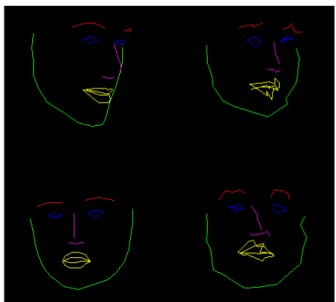
Outline
Documents relatifs