Column generation algorithms for the wafer-to-wafer integration problem
Texte intégral
Figure
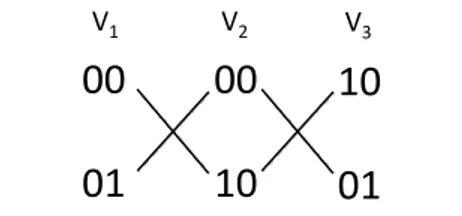

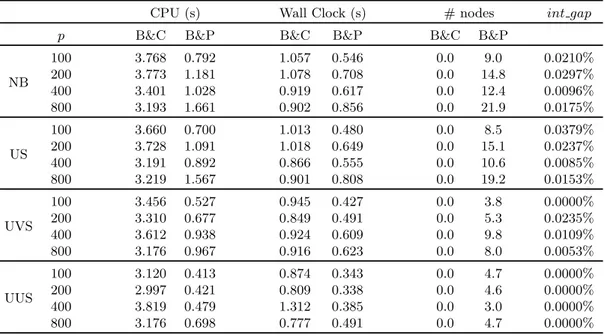
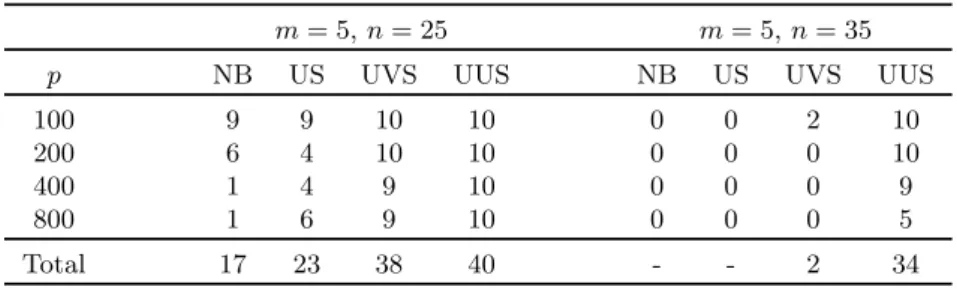
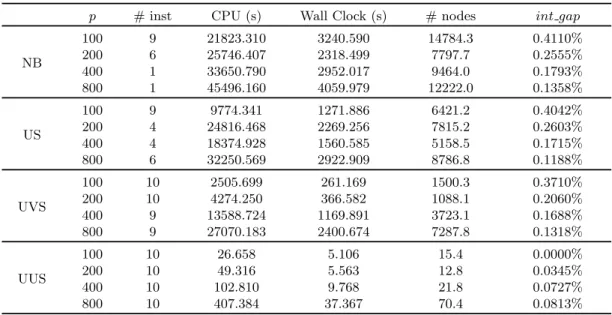
Documents relatifs
For example, many recent works deal with F I -modules (functors from the category of finite sets with injec- tions to abelian groups, see [1]); finitely generated F I -modules
The Team Orienteering Problem (TOP) [4] is a widely studied Vehicle Routing Problem (VRP) which can be described as follows: a fleet of vehicles is avail- able to visit customers from
Without a specific and expensive n-port vector network analyzer (VNA), the full characterization of the n-port device is usually performed from several partial measurements
In this paper, the dual feasible functions will be applied to the knapsack poly- topes associated to different constraints of (8)–(11), namely the demand con- straints (9),
In this case, the vehicle can possibly load the supplied object and carry it to a vertex requiring that object type, and it may also leave the vertex with a deadheading (see Lemmas
Therefore, there exists an optimal solution in which the original depot is visited at most twice, where the two visits case corresponds to an additional pair of deadheadings
Time preproc., time spent on preprocessing, this includes the time spent tightening time windows (see Section 6.4) and calculating the sets A + i and A − i needed for the
For our experimentations, the compromise between the cost of treatment of the accelerating procedure (the computation of complementary columns for CGDR and the construction of
