NOTE TO USERS
Page(s) not included in the original manuscript and are unavailable from the author or university. The manuscript
was scanned as received.
35
This reproduction is the best copy available.
Acquisition de la lecture en langue seconde : profil des
stratégies utilisées par les apprentis lecteurs
Andréanne GAGNÉ
Department of Integrated Study in Education Second Language Education
McGill University, Montreal
August, 2003
A thesis submitted to McGill University in partial fuI filment of the requirements of the degree ofM.A.
1+1
Library and Archives Canada Bibliothèque et Archives Canada Published Heritage Branch Direction du Patrimoine de l'édition 395 Wellington Street Ottawa ON K1A ON4 Canada395, rue Wellington Ottawa ON K1A ON4 Canada
NOTICE:
The author has granted a non-exclusive license allowing Library and Archives Canada to reproduce, publish, archive, preserve, conserve, communicate to the public by
telecommunication or on the Internet, loan, distribute and sell th es es
worldwide, for commercial or non-commercial purposes, in microform, paper, electronic and/or any other formats.
The author retains copyright ownership and moral rights in this thesis. Neither the thesis nor substantial extracts from it may be printed or otherwise reproduced without the author's permission.
ln compliance with the Canadian Privacy Act some supporting forms may have been removed from this thesis.
While these forms may be included in the document page count,
their removal does not represent any loss of content from the
AVIS:
Your file Votre référence ISBN: 0-612-98440-0 Our file Notre référence ISBN: 0-612-98440-0
L'auteur a accordé une licence non exclusive permettant
à
la Bibliothèque et Archives Canada de reproduire, publier, archiver,sauvegarder, conserver, transmettre au public par télécommunication ou par l'Internet, prêter, distribuer et vendre des thèses partout dans le monde, à des fins commerciales ou autres, sur support microforme, papier, électronique et/ou autres formats.
L'auteur conserve la propriété du droit d'auteur et des droits moraux qui protège cette thèse. Ni la thèse ni des extraits substantiels de celle-ci ne doivent être imprimés ou autrement reproduits sans son autorisation.
Conformément
à
la loi canadienne sur la protection de la vie privée, quelques formulaires secondaires ont été enlevés de cette thèse.Bien que ces formulaires aient inclus dans la pagination, il n'y aura aucun contenu manquant.
Abstract:
As a result of migratory movements in recent decades, an increasing number of children are educated in a language which is not their mother tongue. For these children, leaming to read takes place in their second language. This leaming context is
made unique by two challenges. First, the leaming of the written code occurs
simultaneously with the leaming of the oral language. Second, no reference to the written code of the maternaI language is made available to these children.
This particular leaming context can lead to inequity between the second language leamer and ms or her unilingual pcers in tenns of phonetic encoding and decoding. Furthennore, the limited vocabulary of a beginning language learner can impede the direct lexical access used when leaming to read.
Fourteen students were evaluated for their metalinguistical abilities, lexical and
phonie knowledge. Following these tests, an analysis was conducted of student reading errors made in a real reading context.
This descriptive study explores the interaction between reading strategies used
by second language leamers: bottom-up ( word comprehension derived from the
context of the text) and top-down (text comprehension derived from word recognition).
In addition, this study seeks to describe the linguistic and metalinguistic abilities of these second language students in the process of learning to read.
Résumé:
Suite aux mouvements migratoires des dernières décennies, de plus en plus d'enfants sont scolarisés dans une langue qui leur est seconde. Pour ces enfants allophones, l'apprentissage de la lecture se fait en langue seconde. Deux défis rendent ce contexte d'apprentissage de la lecture unique. D'une part, l'apprentissage du code écrit est simultané à l'apprentissage de la langue orale. D'autre part, aucune référence au code écrit en langue maternelle n'est disponible pour ces enfants.
Ce contexte particulier peut amener l'apprenant lecteur en langue seconde à se distinguer de ses pairs unilingues en encodage et décodage phonétique. De plus, compte tenu du vocabulaire limité des apprenants novices d'une nouvelle langue, l'accès lexical direct peut être moins efficace chez l'apprenant lecteur en langue seconde.
Les connaissances lexicales, les habiletés métaphonologiquse et les connaissances du son des graphèmes ont été mesurées chez quatorze participants. Une analyse des méprises en situation réelle de lecture a ensuite été effectuée.
Cette étude descriptive veut dépeindre l'interaction des stratégies utilisées: ascendante (de la reconnaissance du mot, au sens du texte) et descendante (du sens du texte à la reconnaissance du mot) par les apprenants lecteurs en langue seconde. Elle veut aussi cerner la dynamique, chez cette population, des habiletés linguistiques et métalinguistiques dans l'acte de lecture.
Remerciements
Ma reconnaissance à Mela Sarkar pour son enthousiasme, sa disponibilité et ses précieux conseils.
Merci au Fond FRSC pour leur contribution financière durant toute la durée de mes études.
Merci à Pierre Bernard, Doris L'Heureux et à la Commission Scolaire de
Montréal pour leur collaboration essentielle. Merci à Marielle Chagnon pour son assistance et sa complicité. Merci à tous les enfants qui ont participé à cette étude, que l'anonymat m'empêche de nommer, mais à qui je souhaite la meilleure des chances dans leur vie future.
Remerciements à Andrea Sterzuk pour son aide dans l'édition et la traduction de certaines parties de ce texte.
Toute ma gratitude à Robert Bracewell, Patrick DeRoy, Claudia Gagné, Randall Halter et plus particulièrement à Jacques Gagné pour l'aide apportée dans le traitement et l'interprétation des données statistiques.
Merci à PC Parc pour avoir réussi le double exploit de sauver mon disque dur d'un état amnésique permanent et d'avoir gérer la crise de panique qui accompagnait la demande. Merci à Elizabeth pour son aide technique durant cette période.
Merci à Nicole Laroche pour son imagination et à Jacques Gagné pour sa rationalité. Finalement, merci à ma famille et mes amis pour leur contribution spirituelle, artistique, informatique, littéraire, humoristique, gastronomique et j'en passe ...
Table des matières
Liste des tableaux Liste des figures Introduction Cadre théorique
Modèles cognitivistes et développementaux de la lectilre Les modèles à deux voies
Le modèle développemental de Frith Le modèle de Seymour
Limites des applications des modèles cognitivistes et développementaux en lecture langue seconde
Conséquences d'une vocabulaire limité Conséquences d'une phonologie limitée L'apprentissage de la lecture en langue seconde
Comparaisons entre les apprentis lecteurs en langue maternelle et en langue seconde
Les différences intrinsèques à un groupe de lecteurs en langue seconde Question de recherche
Méthodologie
Participants
Instruments de mesure
Échelle de vocabulaire en image Peabody
Batterie d'évaluation du langage écrit et de ses troubles Épreuve de lecture
Analyse des méprises
Résultats
Les erreurs contextuelles Les erreurs graphiques Les erreurs doubles
Les erreurs inexpliquées et les mots non lus
Introduction
Profildu groupe d'apprentis lecteurs Les erreurs graphiques Les erreurs contextuelles
m
iv 1 3 3 3 6 6 7 7 8 8 10 16 18 19 19 20 20 22 24 29 30 3\ 3\ 32 33 33 37 38 39Analyse statistique du rôle des habiletés linguistiques et métalinguistiques Relations entre méta et erreurs/87
Relations entre son et erreurs/87 Relations entre voca et erreurs/87
Analyse de la dynamique des variables explicatives Prédire une performance en lecture
Faits saillants
Discussion
Les différences intrinsèques au groupe d'apprentis lecteurs aHophones Les habiletés métaphonologiques et la performance en lecture
La connaissance du son des graphèmes et les habiletés métaphonologiques La connaissance du son des graphèmes et la performance en lecture Les connaissances linguistiques et la performance en lecture
Le vocabulaire réceptif La sémantique et la syntaxe
Modèles cognitivistes et développementaux de la lecture Les modèles à deux voies
Conclusion
Le modèle développemental de Frith Le modèle de Seymour Limites Implications futures Faits Saillants Bibliographie Annexes
Batterie d'évaluation du langage écrit et de ses troubles Extrait de « Mais où sont les grenouilles»
Certificate of Ethical Acceptability
Autorisation de la Commission scolaire de Montréal Demande d'autorisation des parents
41 41 43 44 45 50 52 54 54 56 57 59 59 59 61 61 62 63 65 66 67 54 65 69 A B C D E
Tableau 1
Tableau 2
Liste des tableaux
Études comparatives entre le comportement des apprentis lecteurs en langue maternelle et en langue seconde
15
Études sur les différences intrinsèques d'un groupe d'apprentis lecteurs bilingues 17 Tableau 3 Liste de mots à décoder pour« Mais où sont les grenouilles» 27
Tableau 4 Liste de mots à décoder pour« Léon dit vrai» 28
Tableau 5 Vue d'ensemble des données recueillies 36
Tableau 6 Analyse statistique descriptive pour le nombre d'erreurs 37
Tableau 7 Tableau des corrélations entre les variables 41
Tableau 8 Analyse de régression et de variance entre méta et erreurs/87 42 Tableau 9 Analyse de régression et de variance entre son et erreurs/87 44 Tableau 10 Analyse de régression et de variance entre voca et erreurs/87 45
Tableau II Analyse multivariables de type pas-à-pas 46-47
Tableau 12 Analyse de régression et de variance entre son et méta 49-50
Tableau 13 Test d'égalité des espérances: deux observations de variances différentes pour 51 voca
Tableau 14 Test d'égalité des espérances: deux observations de variances différentes pour 51 méta
Tableau 13 Test d'égalité des espérances: deux observations de variances différentes pour 52 son
Liste des figures
Figure 1 Modèle à deux voies du traitement d'un stimulus écrit 5
Figure 2 Graphique du nombre d'erreurs par individu 38
Figure 3 Ratios des types d'erreurs pour le groupe 40
Figure 4 Ratios des types d'erreurs par participants 40
Figure 5 Nuage de points d' erreurs/87 en fonction de méta 40
Figure 6 Nuage de points d'erreurs/87 en fonction de son 43
Figure 7 Nuage de points d'erreurs/87 en fonction de voca 45
Figure 8 Compariason des rapports détaillés de la régression simple et de la 48 régression multiple
Introduction
Depuis les dernières décennies, Montréal est devenue une véritable métropole urbaine et une ville d'accueil pour plusieurs immigrants. En conséquence de ces changements démographiques, les enfants scolarisés dans une autre langue que leur langue maternelle représentent une proportion de plus en plus grande de la clientèle scolaire montréalaise. Chez ces enfants, issus de diverses communautés culturelles, le premier contact avec la langue d'enseignement se fait souvent à la maternelle. Cette nouvelle réalité impose de nouvelles solutions. Le Ministère de l'Éducation a dernièrement mis sur pied un programme d'aide à l'école montréalaise qui vise, entre autre, la prévention des difficultés d'apprentissage dans les écoles pluriethniques. Cependant, très peu de recherches ont été effectuées sur l'interaction entre la diversité culturelle et les difficultés d'apprentissage. Ceci est particulièrement vrai pour les pratiques éducationnelles relatives à la 'prévention des difficultés et aux interventions appropriées (Ortiz, 1991; Ganschow, 1991). L'intégration réussie de la clientèle aUophone dans les programmes réguliers du système d'éducation est un défi de taille. En particulier, la maîtrise de la lecture en langue seconde, qui représente un préalable nécessaire à la poursuite des études dans les différentes matières, constitue pour certains élèves allophones un obstacle important (Ministère de l'Éducation du Québec, 1996).
Deux défis rendent ce contexte d'apprentissage de la lecture unique. D'une part, l'apprentissage du code écrit est simultané à l'apprentissage de la langue orale.
D'autre part, aucune référence au code écrit en langue maternelle n'est disponible pour ces enfants.
Ce contexte particulier peut amener l'apprenti lecteur en langue seconde à se distinguer de ses pairs unilingues en encodage et décodage phonétique. De plus, compte tenu du vocabulaire limité des apprenants novices d'une nouvelle langue, l'accès lexical direct peut être moins efficace que chez l'apprenant lecteur en langue maternelle.
Ce mémoire veut dépeindre le comportement d'enfants scolarisés en langue seconde ou troisième devant une tâche de lecture à haute voix. Deux analyses seront effectuées. Une première analyse dressera le portrait général du groupe d'apprentis lecteurs allophones ainsi que les particularités présentées par certains de ses individus. Une deuxième analyse aura pour but d'établir une relation entre une performance en lecture à haute voix et les habiletés lexicales, les habiletés métaphonologiques et les connaissances graphémiques du lecteur allophone.
Cadre théorique
Modèles cognitivistes et développementaux de la lecture
Les processus de lecture ont fait l'objet de plusieurs études desquels des modèles explicatifs ont été inspirés. Certains modèles de traitement du stimulus écrit, de l'évolution de l'apprentissage de la lecture ainsi que des balises d'un comportement fonctionnel en lecture seront exposés ici, de façon simplifié, afin de cerner tous les aspects que revêt l'acte de lecture chez les enfants âgés entre six et huit ans.
Les modèles à deux voies
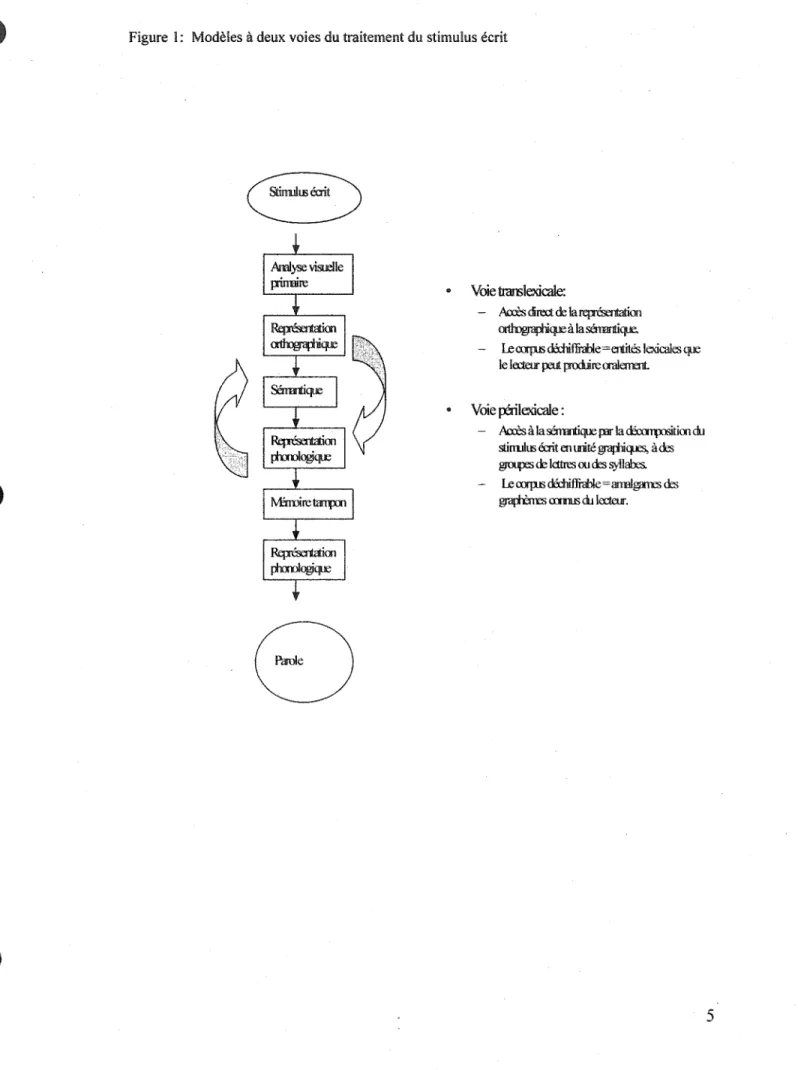
Le modèle d'Ellis (1985) présente les caractéristiques principales des modèles à deux voies (Figure 1). Ces modèles stipulent que le traitement d'un stimulus écrit peut prendre deux voies différentes: la voie translexicale (aussi appelée voie directe) et la voie périlexicale (aussi appelée voie indirecte). La voie translexicale se définit comme étant la voie d'accès direct à la représentation abstraite par le traitement du mot ou du morphème. Le corpus littéraire déchiffrable correspond alors aux entités lexicales connues de l'enfant. La voie périlexicale, quant à elle, est la voie d'accès par la décomposition du stimulus écrit en unités graphiques, à des groupes de lettres ou à des syllabes. Le corpus littéraire déchiffrable correspond alors aux différents amalgames possibles des graphèmes ou phonèmes connus du lecteur. Dans la plupart des modèles à deux voies, le
traitement d'un stimulus écrit donné se fait exclusivement par l'une des deux voies (Laplante, 1999), à l'exception de Goldsmith-Phillips (1989), Lecours (1996) et Rumelhart (1985) qui ne rejettent pas la possibilité d'un traitement interactif ou simultané. Le modèle de Rumelhart complète le modèle d'Ellis en qualifiant le processus impliquant l'interprétation de données graphiques comme étant le processus ascendant et le processus impliquant l'utilisation de connaissances lexicales ou factuelles déjà présentes comme étant un processus descendant. L'interaction entre les deux processus peut être présent lorsque les informations de haut nIveau (comme l'utilisation d'informations contextuelles et environnementales) et les informations de bas niveau (comme la perception graphiques des lettres et des mots) sont utilisées en concomitance. Les relations entre le type d'information utilisé et le niveau des élèves a fait l'objet de controverses. Alors que certains comme Goodman (1982 [ 1965]) affirme que l'utilisation d'informations de haut niveau caractérise les lecteurs avancés, Stanovich (1980) maintient que l'utilisation d'information de hau,t niveau est une stratégie de compensation chez les lecteurs faibles incapables de décoder des graphèmes efficacement. Un troisième point de vue a été exposé par Walczyk (1995). Ce dernier stipule que les bons lecteurs peuvent utiliser différentes stratégies traitant tous les types d'informations disponibles, alors que les mauvais lecteurs ne peuvent utiliser qu'une seule stratégie.
Figure 1: Modèles à deux voies du traitement du stimulus écrit
• Voie trarslexicale:
- Accès dm de larep-é;entatiœ OItIng,rajnqJe à la sémlntique.
- LeOlXpll5 dWliffrable=entÏté> lexicales qJe le lecteur peut prodire OOÙemenl
Voie p&ilexicale :
- Accès à IasémJrtiqJe rar la~itiœdu
stinulœ écrit en unité graJllcp.lfS, àdes
gJOOpes de Icttres ou des syllal:x.s - LeOlXpll5dWliffrable=armIg;nx:sdes
Le modèle développemental de Frith
Le modèle de Frith (1985) nous pennet d'énoncer les prmcIpes qm gouvernent l'apprentissage de la lecture. Ce modèle propose la succession de trois phases d'acquisition se déroulant de façon stricte et universelle. Il y a d'abord la phase logographique (où l'unité du mot traité en lecture est le mot); la phase alphabétique (où l'unité traitée est le graphème) et la phase orthographique (où l'unité traitée est le morphème). Le passage d'une modalité à une autre se manifese par la disparition d'une ancienne modalité au profit de la nouvelle. De plus, cette nouvelle modalité s'appuie sur le développement de la précédente, elle y est ainsi
conditionnelle. Ce modèle se caractérise par l'absence des facteurs
environnementaux dans l'évolution de l'apprentissage de la lecture, ce qui lui a valu de nombreuses critiques (Laplante, 1999) .
Le modèle d'un comportement fonctionnel
Le modèle de Seymour (1986) nous pennet d'expliquer les balises d'un comportement fonctionnel en lecture. Selon ce modèle, la lecture est un processus interactif entre trois processeurs: phonologique, sémantique et visuel dont la perfonnance est influencée par différentes variables: la longueur des mots, la régularité de l'orthographe, le fonnat, l'homophonie, la parenté, la concrétude ... Le processeur phonologique fait intervenir le système de production de la parole. Ce
système est présent avant même l'apprentissage de la lecture. Le processeur
l'établissement de liens entre un symbole (ou un code abstrait) et un signifié. Le processeur visuel est responsable de la reconnaissance des graphèmes familiers fréquents d'après le lexique logo graphique ou le lexique alphabétique.
Limites des applications des modèles cognitivistes et développementaux en lecture
langue seconde
Les conséquences d'un vocabulaire limité
Les différents modèles explicatifs en lecture, conçus d'après différentes observations effectuées auprès de lecteurs en langue maternelle, soulèvent quelques interrogations lorsque appliqués aux lecteurs aUophones. En effet, les lecteurs allophones se caractérisent par un vocabulaire limité (Koda, 1994). Par conséquent, on peut prédire 'du modèle à deux voies, que la voie translexicale sera fortement défavorisée. Quant au modèle de Frith, le stade logographique utilise le mot comme unité d'analyse. Des lacunes en connaissances lexicales pourraient fortement compromettre l'acquisition du tout premier stade et, conséquemment, la totalité du développement de la lecture. Lorsqu'on tente d'appliquer le modèle de Seymour, on est en droit de se demander si une organisation lexicale différente en langue maternelle et en langue seconde influence l'efficacité du processeur sémantique.
Les conséquences d'une phonologie limitée
Une autre caractéristique du lecteur en langue seconde est qu'il peut être moins conscient des règles phonétiques qui régissent la langue en voie d'apprentissage (Verhoeven 1990). Ainsi, si l'on tente appliquer le modèle à deux voies, on peut prédire que la décomposition en unités grapho-phonétiques pourraient être inappropriées et la voie périlexicale difficilement accessible. D'après le modèle de Frith, les lecteurs en langue seconde seraient susceptibles de plafonner au deuxième stade où l'unité traitée est le graphème. Dans le même ordre d'idées, Seymour mentionne que le processeur phonologique est présent avant même l'acquisition de la lecture. Ce qui n'est pas forcément le cas pour les lecteurs en langue seconde. Quelles sont les conséquences sur l'efficacité et l'importance relative du processeur phonologique en lecture chez les allophones? Qui plus est, certains auteurs (Papagno et al, 1991) ont établi une relation entre la mémoire phonologique à court terme et l'acquisition de vocabulaire en langue seconde. Ainsi, une lacune en phonologie pourrait avoir non seulement des conséquences directes sur la voie périlexicale, le processeur phonologique ou le deuxième stade d'acquisition de la lecture, mais affecterait, par ricochet, l'accès lexical direct du lecteur avec les conséquences exposées ci-dessus.
L'apprentissage de la lecture en langue seconde
Comme le rapporte Fitzgerald (1995), la recherche portant sur la lecture en langue seconde a surtout été effectuée par le domaine des langues secondes et très
peu par les chercheurs en acquisition de la lecture; chercheurs provenant généralement des départements de neuropsychologie, psychologie, psychoéducation et psychopédagogie. Cet état de fait semble avoir influencé l'angle traité de la problématique et la clientèle étudiée. Ainsi Armand (2000) constate qu'un plus grand intérêt a porté sur le processus descendant (et l'utilisation des informations de haut niveau) que sur le processus ascendant (et l'utilisation des informations de bas niveau). De plus, les recensions des écrits de Fitzgerald (1995) et Koda (1994) relèvent qu'une grande majorité des études ont été effectuées avec une clientèle adulte lettrée en langue maternelle lorsque l'apprentissage de la lecture en langue seconde débute. Les principales questions traitées sont l'existence d'un seuil de compétence langagière orale en langue seconde (Cummins, 2001), le transfert des habiletés en lecture de la langue maternelle à la langue seconde (Bernhard & Kamil, 1995; Genesee, 1979) et la description de l'effet de l'interlangue (Koda, 1994).
Ainsi, peu d'informations sont disponibles sur les processus cognitifs inhérents à l'apprentissage de la lecture en langue seconde chez les personnes qui, en l'absence de scolarisation en langue maternelle dans le pays d'origine ou dans le pays d'accueil, commencent l'apprentissage de la lecture dans une langue seconde (Armand, 2000). Et ce, tout particulièrement pour la clientèle jeune apprentis
lecteurs du préscolaire à la deuxième année du primaire (Fitzgerald, 1995).
Chez cette clientèle de jeunes apprentis lecteurs en langue seconde, quelques écrits existent sur les connaissances de haut niveau: par exemple, le transfert des pratiques de littératie du milieu familial et du pays d'accueil (Ortiz, 1997; Gregory,
1996); l'influence du contexte socio-économique (Silver & Hagin, 2002), la perception sociolinguistique (Cummins, 2001) et les effets possibles des capacités métalinguistiques (Armand, 2000). Toutefois, l'étude des connaissances de bas niveau chez les apprentis lecteurs allophones est restée relativement négligée à l'exception de Comeau et al (1999), qui s'intéresse aux transferts des processus phonologiques entre deux langues alphabétique : le français et l'anglais.
Comparaison entre les apprentis lecteurs en Li et L2
Koda (1994) relève que les bases théoriques des écrits portant sur l'acquisition de la lecture en langue seconde proviennent des théories en acquisition de la lecture en langue maternelle. Conséquemment, des études comparatives entre les apprentis lecteurs en langue maternelle, et les apprentis lecteurs en langue seconde ont fait l'objet d'une majorité de publications. Les articles dont il sera
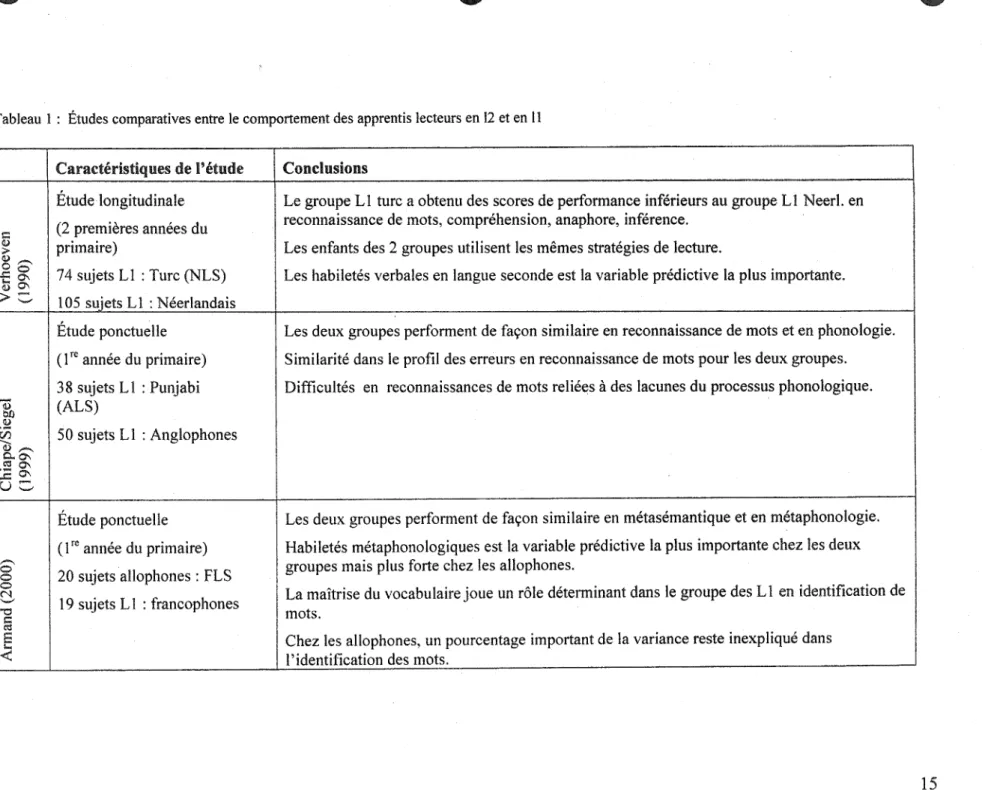
question ici ont été résumé dans le tableau 1.
Verhoeven (1990) a fait une étude longitudinale durant les deux premières années du primaire visant à comparer 74 enfants turcophones scolarisés en néerlandais et 105 enfants néerlandophones scolarisés en langue maternelle. La tâche présentait neuf listes de 20 mots. Les listes de distinguaient par la fréquence des mots et la complexité de l'orthographe. Trois degrés de complexité étaient contrôlés. Le premier degré comportait des mots monosyllabiques de construction consonne-voyelle-consonne. Le deuxième degré contenait des mots monosyllabiques ayant une construction consonne-consonne-voyelle et finalement,
le dernier degré comprenait des mots bisyllabiques. Comme le néerlandais a une orthographie transparente, la complexité orthographique d'un mot augmente de façon linéaire en fonction de la longueur du mot.
L'analyse quantitative a permis d'établir que le groupe turco phone avait des scores de performances inférieures au groupe néerlandophone en reconnaissance de mots, compréhension, anaphore et inférence. Cette différence de performance perdure durant les deux années d'expérimentation. L'analyse qualitative conclut que les deux groupes linguistiques utilisent les mêmes stratégies de lecture et que les habiletés verbales en langue seconde (mesurées en néerlandais en terme de: fonction des mots, terminaison des mots, vocabulaire réceptif, et vocabulaire expressif) étaient les variables prédictives les plus fiables.
Chiappe & Siegel (1999) ont effectué une étude ponctuelle chez deux groupes d'enfants de première année du primaire. Un premier groupe comprenait 38 participants qui avaient le punjabi comme langue maternelle et qui étaient scolarisés en anglais. L'autre groupe était constitué de 50 anglophones scolarisés en langue maternelle. Les enfants présentant des troubles spécifiques de la lecture avaient été exclus de l'étude. Deux séries de mots étaient présentaient aux enfants. Une première série comportait 40 mots: 9 à graphie régulière et consistante; 14 à
graphie régulière et inconsistante et 17 à graphie exceptionnelle. Une deuxième
série présentait 69 mots à haute fréquence, variant en terme de nombre de syllabe. De plus, le type d'erreur lors de la lecture à haute voix fut l'objet d'analyse. Quantitativement, les deux groupes ne se distinguaient pas l'un de l'autre en
reconnaissance de mots et en phonologie. Le même profil d'erreurs a été établi pour les deux groupes. Par contre, des différences intrinsèques à chacun des groupes linguistiques entre bons et mauvais lecteurs furent démontrées. Une relation entre un processeur phonologique déficitaire et des difficultés en lecture a pu être établie pour les deux groupes linguistiques.
Armand (2000) compare, quant à elle, un groupe de 20 sujets allophones scolarisés en français et un groupe de 19 sujets francophones dans une étude ponctuelle visant à analyser le rôle des habiletés langagières orales et des capacités métalinguistiques sur les performances en lecture en première ,année du primaire. La définition des capacités métalinguistiques, servant à cette étude est traduite de la définition de Bialystok (1993) à savoir qu'elles sont des réalisations dont la manifestation est le produit conjoint du développement de représentations langagières de plus en plus abstraites, d'une capacité d'explication de plus en plus précise et enfin de capacités de contrôle des ressources attentionnelles de traitement langagier (Bialystok dans Armand, 2000). La tâche métasémantique proposait deux images au participant (ex train et coccinelle) et lui demandait d'identifier le mot le plus long. Le but de la tâche était d'identifier si le sujet était capable de différencier le signifié du signifiant. Les capacités métaphonologiques ont été mesurées par des épreuves de répétition, de jugement et de correction de phrases sémantiques grammaticales ou agrammaticales selon l'ordre des mots ou l'accord morphologiques. Une mesure de compétence langagière en vocabulaire et en syntaxe (réceptifs et productifs) fut aussi prélevée. Les similarités entre les deux
groupes concernent la performance en métasémantique, en métaphonologie, en compréhension de texte et en reconnaissance de mot. De plus, les habiletés métaphonologiques ont été la variable prédictive la plus importante de la performance au test d'identification des mots chez les deux groupes linguistiques. La variance explicative de ce prédicteur s'est avérée excessivement plus élevée chez le groupe francophone, laissant une grande partie de la variance de la performance en identification de mots des allophones inexpliquée. Certaines différences entre les deux groupes ont aussi été relevées en métasyntaxe, en vocabulaire et en syntaxe (à noter que chez les aHophones, la performance en métasyntaxe et en syntaxe est fortement corrélée). Dans ces épreuves les élèves allophones ont sous-performé par rapport au groupe francophone. Des observations similaires sur les différences de performance en syntaxe avait aussi établit par DaFontura & Siegel (1995) ainsi que par Paradis & Crago (2000). Dans cette dernière étude, non seulement le groupe bilingue se démarquait-il négativement du groupe unilingue mais leur comportement à une tâche morphosyntaxique était similaire à cene d'un groupe d'enfants atteints de trouble du langage. Une dernière différence intergroupe importante à relever de l'étude d'Armand (2000) est la corrélation entre le vocabulaire et la reconnaissance de mots chez les francophones. Aucune corrélation du même type n'a pu être démontrée chez le groupe d'allophones. Ce dernier résultat semble contredire les conclusions de Verhoeven (1990).
Les trois études citées tendent à prouver que des différences existent entre les lecteurs en langue maternelle et les lecteurs en langue seconde. Par contre, la nature des différences fait l'objet de débats. Les différences sont-elles de nature qualitative? En d'autres mots, est-ce que les différences entre les deux groupes ont trait au choix même de la voie de traitement de l'information écrite, au choix de l'unité' lexicale traitée (à savoir, le mot, le graphème, le morphème) ou encore au
processeur (phonologique, visuel, sémantique) privilégié? Est-ce que ces
différences sont plutôt d'ordre quantitative? C'est-à-dire que le choix de la voie de traitement de l'information écrite, l'unité lexicale traitée et les processeurs impliqués sont les mêmes chez les lecteurs en langue maternelle et en langue seconde; mais que les performances des lecteurs en langue seconde restent inférieures. aux performances des lecteurs unilingues dans les premières années d'acquisition.
En faisant une analyse comparative entre des lecteurs en langue maternelle et en langue seconde, les trois auteurs ont considéré le groupe de lecteurs bilingues comme étant homogène. Et ce, malgré que certains d'entre eux soulignent que les écarts-types calculés pour le groupe bilingue sont notablement plus élevés que les écarts-types calculés pour le groupe unilingue, ce qui pourrait laisser présager une plus grande disparité des sujets dans le groupe bilingue.
Tableau 1 : Études comparatives entre le comportement des apprentis lecteurs en 12 et en Il
Caractéristiques de l'étude Conclusions
-~-
--1
Étude longitudinale Le groupe LI turc a obtenu des scores de performance inférieurs au groupe LI Neerl. en (2 premières années du reconnaissance de mots, compréhension, anaphore, inférence.
:=:
Q)
primaire) Les enfants des 2 groupes utilisent les mêmes stratégies de lecture.
;;.-Q),.-...,
° 0
74 sujets LI : Turc (NLS) Les habiletés verbales en langue seconde est la variable prédictive la plus importante.
-1:0'\
Q)OI
>c
105 sujets LI: NéerlandaisÉtude ponctuelle Les deux groupes performent de façon similaire en reconnaissance de mots et en phonologie.
(1 re année du primaire) Similarité dans le profil des erreurs en reconnaissance de mots pour les deux groupes.
38 sujets LI : Punjabi Difficultés en reconnaissances de mots reliées à des lacunes du processus phonologique.
~ l:lJ) (ALS) Q)
i:i5 50 sujets LI : Anglophones
---
Q),.-...,0.0'1 .~ 0'1
, . c O I
uc
Étude ponctuelle Les deux groupes performent de façon similaire en métasémantique et en métaphonologie. ( 1 re année du primaire) Habiletés métaphonologiques est la variable prédictive la plus importante chez les deux ,.-...,
groupes mais plus forte chez les allophones.
0
20 sujets allophones : FLS
0 0
La maîtrise du vocabulaire joue un rôle déterminant dans le groupe des LIen identification de (".l
19 sujets LI: francophones
'--'
'"0 mots.
:=:
~
ê
Chez les allophones, un pourcentage important de la variance reste inexpliqué dansLes différences intrinsèques à un groupe de lecteurs en langue seconde
Quelques rares études ont analysé les différences intrinsèques qui existent à l'intérieur d'un même groupe de lecteurs en langue seconde. Les faits saillants des études présentées ici sont résumé au tableau 2.
Chiappel & Siegel (1999) mentionnent que les lecteurs moyens utilisent de façon plus importante la correspondance graphème-phonème lors de la lecture de mots moins familiers. Les auteurs ont observé, chez les lecteurs faibles, une présence plus importante d'erreurs sémantiques et d'erreurs inexplicables qui résulteraient d'une approche non phonologique.
Miramontes (1990), d'une analyse d'erreurs en lecture à haute voix, a voulu décrire les stratégies utilisées par des lecteurs bilingues (espagnol-anglais). Deux groupes ont été formés, soit: un groupe de dix bons lecteurs en langue seconde, et un groupe de vingt mauvais lecteurs en langue seconde. Tous les participants étaient en fin du cours de primaire (entre la quatrième et la sixième année). Elle conclut que le groupe de lecteurs bilingues faibles se distinguent de leurs pairs bilingues bons lecteurs dans leur utilisation de stratégies ainsi que dans la sous-utilisation de certaines habiletés, ce qui entraînent des différences importantes dans la fluidité de la lecture à haute voix. Les lecteurs bilingues faibles décodant deux fois moins de mots que les bons lecteurs. Ces deux études démontrent bien que les différences intrinsèques à un groupe d'apprentis lecteurs en langue seconde ne sont pas négligeables et mériteraient une plus grande attention.
Tableau 2 : Études sur les différences intrinsèques d'un groupe d'apprentis lecteurs allophones
Caractéristiques de l'étude Conclusions
Chiape/Siegel
Étude ponctuelle Différences dans le profil des erreurs en reconnaissance de mots entre les bons (1999)
(1 re année du primaire) et les mauvais lecteurs du groupe L2. 38 sujets LI : Punjabi
(ALS)
50 sujets LI : Anglophones
Miramontes (2000)
Étude ponctuelle Différences claires entre les bons lecteurs et les mauvais lecteurs dans la reconnaissance de mots à haute voix.
(4e,5e,6e année du primaire)
10 sujets: bons lecteurs hispanophones ESL
Questions de recherche
Des écrits comparant les apprentis lecteurs en langue maternelle et en langue seconde relèvent que des différences existent entre les deux groupes. Ces différences se sont traduites en terme de performance en lecture de textes ou en reconnaissances de mots isolés. Les auteurs ont établi des relations entre certaines habiletés linguistiques ou métalinguistiques des lecteurs et leur performance en lecture. Les conclusions des différents articles restent cependant contradictoires quant à la variable prédictive la plus importante. Cette étude tentera de répondre à
la question soulevée par ces résultats contradictoires. QueUe est l'importance relative des habiletés en vocabulaire, en correspondance graphophonémique et en métaphonologie dans une performance de lecture à haute voix chez un groupe d'apprentis lecteurs aUophones? Est-ce que l'une de ces habiletés, ou l'interaction de deux ou trois habiletés peuvent prédire une performance en lecture?
La nécessité d'analyser l'homogénéité d'un groupe d'apprentis lecteurs allophones a été relevée des deux études portant sur les différences intrinsèques. Ce mémoire questionnera l'homogénéité d'un groupe d'apprentis lecteurs en langue seconde et la nature des différences qui .peuvent être observées dans le choix des stratégies et dans le types d'erreurs commises entre les bons lecteurs et les lecteurs en difficultés.
Méthodologie
Participants
Une étude ponctuelle auprès de quinze élèves aUophones (neuf garçons et six filles) de première année fut entreprise. Les âges des participants variaient entre 6 ans Il mois et 7 ans 5 mois à l'exception d'un élève doubleur âgé de 8 ans 8 mOlS. Un profil langagier de chaque élève fut dessiné à partir d'une liste administrative sur les langues parlées par les enfants. Cette liste, à l'usage du personnel enseignant, a été établie d'après les fiches d'inscriptions remplies par les parents lors de l'admission de l'enfant à l'école. Un participant fut exclu car le français était à la fois la langue d'usage et la langue scolaire. La répartition des langues maternelles des autres enfants se lit:
Anglais (deux participants) Arabe (deux participants) Chinois (un participant) Créole Haïtien (un participant) Gujarati (un participant) Espagnol (quatre participants) Ourdou (un participant) Portugais (un participant)
Anglais et espagnol (un participant)
Toujours d'après les dossiers scolaires, aucun participant ne présentait une limite intellectuelle. Un seul enfant était en processus de diagnostic pour un déficit de
l'attention avec hyperactivité. Trois enfants bénéficiaient d'un service d'orthopédagogie en dénombrement flottant. Treize élèves provenaient d'une école qualifiée d'une école en milieu défavorisé. En effet, l'école prend part au programme de soutien à l'école Montréalaise du Ministère de l'Éducation du Québec qui a pour objectif de soutenir les écoles les plus défavorisées de l'île de Montréal afin d'assurer la réussite scolaire et éducative du plus grand nombre d'élèves. Le quatorzième élève provenait d;une école à curriculum alternatif où la pédagogie Freisnet était utilisée.
Instruments de mesure
Échelle de vocabulaire en images Peabody (Évip)
Une première épreuve, l'Évip (Dunn & Thériault-Whalen, 1993), adaptation française du Peabody Picture Vocabulary Test-Revised, voulait mesurer le vocabulaire réceptif. Une épreuve de vocabulaire réceptif fut préférée à une épreuve de vocabulaire expressif. Dans un premier temps, le vocabulaire réceptif et expressif corrélait fortement dans l'étude de Verhoeven (1990). Nous pouvions donc prétendre que la mesure de l'une seule des deux variables était scientifiquement valable pour présumer de la performance de l'autre variable. La mesure du vocabulaire réceptif fut préférée afin d'éviter que la présence d'un accent étranger pouvant modifier la production orale ait une influence sur la mesure prise (Fitzgerald, 1995). Compte tenu de la macédoine des langues maternelles que contenait l'échantillon, il eut été complexe de bien définir, pour chacune des
langues, les productions déviantes dues à une méconnaissance réelle du mot exprimé des productions déviantes dues à l'interférence de la langue maternelle. Pour la passation de l'Évip, la tâche de l'élève était de pointer une image représentant le mot prononcé par l'expérimentatrice parmi quatre images proposées. Le participant était soumis à une pré-série de quatre items au tout début de l'expérimentation afin de vérifier la compréhension de la consigne. Durant cette pré-série une rétroaction corrective était donnée. La formulation de la question posée (ex« Montre-moi pomme») ne divulguait aucun indice sur la nature, la fonction ou le genre du mot. L'item plancher correspondait au premier item d'une série de huit items réussis. L'épreuve était suspendue après six échecs sur huit réponses données. L'item plafond correspondait au dernier item de cette série de huit. Aucune rétroaction corrective n'était donnée à l'élève lors de la passation de l'épreuve. Des commentaires neutres tels: « Tu as bien répondu »,« c'est bien» étaient donnés.
L'Évip est un test normalisé auprès d'un bassin de population nord-américain francophone. Malgré l'existence d'une norme, l'utilisation du score brut fut préférée. Ce score brut correspond aux nombres de mots reconnus par l'enfant entre l'item plancher et l'item plafond. Cette décision fut prise principalement parce que la norme de l'Évip avait été établie en fonction de l'âge. Chez la population normalisée, soit la population francophone, l'âge correspond au temps d'exposition à la langue testée, ce qui n'est pas le cas de la population allophone étudiée ici. Chez l'ensemble des participants, le temps d'exposition à la langue testée est en
général deux ans (soit le nombre d'années de scolarisation). De plus, l'objectif de cette étude n'était pas de comparer le niveau de vocabulaire des élèves allophones par rapport aux élèves francophones du même âge, mais bien de mesurer l'influence de leur corpus lexical sur leur performance en lecture.
Batterie d'évaluation du langage écrit et de ses troubles (Bélec)
Trois épreuves de la Bélec (Mousty et Leybaert, 1999) ont été utilisées et
sont présentées en annexe 1 :
1. La connaissance du son des graphèmes,
2. Les habiletés de perception de la parole et de la mémoire phonologique de travail
3. Les habiletés métaphonologiques constituées de quatre sous épreuves: a. inversion de syllabes
b. inversion de phonèmes c. soustraction syllabique
d. soustraction phonémique: incluant la soustraction de la consonne initiale dans une construction consonne-voyelle-consonne et la soustraction de la consonne initiale dans une construction consonne-consonne-voyelle.
Avant chaque épreuve, deux exemples et trois items pilotes étaient donnés à l'élève pour s'assurer de la compréhension des consignes. Pour ces items pilotes
ainsi que pour les épreuves 3a, 3b, 3c, 3d, un feedback correctif était donné à
l'élève après chaque mauvaise réponse.
Les scores pour l'épreuve de la mémoire de travail phonologique n'ont pas été retenus pour l'analyse. Cette mesure voulait être une mesure contrôle pour éviter qu'un trouble au niveau de la perception phonologique affecte la performance sur les épreuves d'habiletés métaphonologiques. Tous les participants ont réussi l'épreuve, les performances les plus faibles étant des empans de quatre phonèmes pour la mémoire phonologique de construction consonne-voyelle et de trois phonèmes pour les constructions consonne-consonne-voyelle.
Comme pour l'Évip, les scores bruts de la Bélec furent préférés aux scores normalisés. Les scores correspondant aux habiletés métalinguistiques correspond à la somme des quatre sous-épreuves rapportée sur 12,4 points. Le score en connaissance des graphèmes a été calculé sur 37, la reconnaissance de chaque graphème correspondant à un point. Dans le cas de la Bélec les normes sont des normes européennes en fonction des degrés scolaires du système scolaire normal en Communauté française de Belgique. L'échantillon ayant servi à établir la norme était unilingue francophone. L'application de cette norme aurait pu avoir pour conséquence de pénaliser les enfants allophones et de se retrouver face à un phénomène de plancher. Ici encore, l'objectif de cette prise de mesure n'était pas de comparer les performances des enfants aUophones à celles des enfants francophones, mais d'observer la relation entre les habiletés linguistiques et
métalinguistiques mesurées et la performance en lecture chez une population allophone.
Épreuve de lecture
La lecture d'un livre eut préséance sur la lecture d'une suite de mots ou de non mots isolés. Contrairement à ces deux dernières options, la lecture d'un livre offrait la possibilité d'observer les différents types d'informations utilisés par les élèves. . L'utilisation d'informations de haut niveau pouvait être observée par l'influence de l'utilisation d'indices sémantiques: images, connaIssances antérieures de l'enfant sur le thème; ou syntaxique : structure de la phrase, passage rimé. L'information de bas niveau pouvait être, quant à elle, détectée par l'influence des symboles graphiques sur la production orale de la lecture par l'élève. La lecture à haute voix fut préférée à la lecture silencieuse. Principalement parce que la lecture à haute voix permet une observation directe des processus de lecture. En effet, il eut été possible de faire faire une épreuve de lecture silencieuse et, suite à cette lecture, faire passer un questionnaire introspectif sur les stratégies mises en place. Cette technique représentait quelques risques. Dans un premier temps, les participants étaient relativement jeunes et une telle introspection pu avoir été difficile pour eux. D'autre part, les élèves auraient eu à exprimer leur réponse en langue seconde. Des difficultés reliées à l'expression orale en langue seconde auraient pu appauvrir ou fausser les données recueillies. De plus, en début d'apprentissage de la lecture, une verbalisation est très fréquemment observée chez
les jeunes lecteurs; et ce, même en situation de lecture personnelle et silencieuse. Finalement, la lecture à haute voix est un contexte de lecture plus fréquent que la lecture à voix basse en classe. Une épreuve à haute voix s'imposait donc comme contexte naturel d'expérimentation.
Le livre sélectionné pour l'épreuve de lecture fut «Mais où sont les grenouilles» des éditions Modulo. Ce livre appartenait à une collection connue des participants puisqu'elle était utilisée en classe. Dans le cas où le livre avait déjà été lu par l'enfant, un deuxième livre: « Léon dit vrai» du même éditeur était utilisé. Deux participants utilisèrent ce livre. Il n'est pas surprenant de constater que les deux élèves ayant déjà lu le livre Mais où sont les grenouilles était les deux meilleurs lecteurs du groupe. En effet, les deux lecteurs étaient avancées dans la lecture des livres de la collection et c'est pourquoi un livre d'une autre collection du même éditeur a dû être utilisé. Les deux livres présentaient les mêmes caractéristiques: une image par page, des images intimement reliées à la narration, des passages rimés et des redondances dans les structures de phrase. L'extrait suivant (cet extrait est accompagné des illustrations en annexe 2) illustre bien les caractéristiques narratives du texte:
« À la ferme de monsieur Paquin, il y a un âne très têtu ... han ... hi-han ... hi-hi-han ... et des lapins aux longues oreilles
pointus ... tssst ... tssst ... tssst. À la ferme de monsieur Paquin, il y a des
belles grosses dindes et des dindons ... glou ... glou ... glou. » (extrait, Mais
où sont les grenouilles, p.9 à 12).
L~ thème traité par les deux livres était le même soit: les animaux de la ferme. Ce thème fut choisi car il avait été traité préalablement en classe. Chaque livre contenait 88 mots différents à décoder, desquels un nom propre a été retiré dans chaque livre, pour un total de 87 mots par livre. Les tableaux 1 et 2 font état de la liste de mots à décoder. La lecture de chaque participant fut enregistrée sur cassette audio et transcrit selon la méthode proposées par M. Clay dans le Sondage d'observation (2003).
Tableau 3: Liste de mots à décoder pour « Mais où sont les grenouilles»
A moutons âne sont
a petits tsst elles
chevaux gros plus donc
cocorico maman glou Oh
cot deux n'y toutes
de bêe lapins entrées
des avec dindes maison
des bien canetons
et d'être grosses
ferme blancs hi-han
grenouilles ouah rron
iiiii sérieux quenouilles
il tachetées oreilles
iun coq vaux cnards
juments bœufs dans
la noirs têtu
les miaou queue
Mais trois cochons
monsieur belles aux
où chats une
paquin vaches longues
poulains très mare
poules contents coin-coin
poussins leur dindons
sont chien drôle
y meuh pointues
Tableau 4 : Liste de de mots à décoder pour « Léon dit vrai»
je cochons grenouilles propres
dis roses des coqs
toujours ils chèvres mangent
la ont mais du
vérité une je grain est queue n'ai aussi
ce en pas si
que tire de mensonges Léon bouchon moutons vais
dit épouvantail cheval avoir Vrai qui dindons boutons
j'ai fait mes oh
deux peur cinq poules aux lapins blanches pigeons longues et mon oreilles quatre canard vaches noirs Flonflon sont elles a pareils pondent sept mon œufs canetons chat bien mare court ronds il après trois y chien petits six animaux
Analyse des méprises
L'analyse des méprises fut utilisée à plusieurs reprises dans la littérature comme outil de délation des stratégies de lecture mises en place par les lecteurs (Biemiller, 1970; Clay 1968; Danielsson 2001; Sears, 2001; Weber, 1970). Dans le cadre de l'étude ici présentée, une attention particulière a due être portée sur la
prononciation. Aucune déviance dans la prononciation des mots a mené à
l'exclusion du mot. La seule déviance notée fut la prononciation de certaines lettres muettes finales chez un lecteur hispanophone. Les mots ainsi décodés ont été cotés comme mots lus et ont été analysé de la même façon que les mots pour lesquels aucune déviance dans la prononciation n'avait été notée. Les informations suivantes ont été recueillies des transcriptions des lectures faites par les participants :
- Nombre de mots lus
- Nombre de mots ayant fait l'objet d'autocorrection
-Méprises où l'utilisation d'informations de haut mveau (sémantiques et syntaxiques) est observable
-Méprises où les informations de bas niveau (graphiques) sont utilisées.
Dans cè mémoire, les erreurs dites contextuelles feront référence aux erreurs où l'information de haut niveau a été utilisée alors que l'appellation erreur graphique fera référence aux erreurs où l'information de bas niveau a été utilisée. La procédure de classification du types d'erreurs a été établie d'après la procédure de BiemiHer (1970) ainsi que d'un document sur l'analyse qualitative des erreurs de Laplante
Les erreurs contextuelles
Pour être qualifiée d'erreur contextuelle, une erreur devait être possible sur le plan sémantique et syntaxique d'après le texte précédent l'erreur. Une erreur possible sur le plan' sémantique peut s'observer par :
-Une substitution lexicale (par exemple: la lecture de bébés canards pour le mot
canetons)
-Une omission lexicale (par exemple: la lecture de les moutons pour les moutons
noirs)
-Un déplacement lexical (par exemple: la lecture les noirs moutons pour les
moutons noirs)
-Un ajout lexical ( par exemple: la lecture de les vieux moutons noirs pour les
moutons noirs).
Les erreurs syntaxiques inacceptables s'observent par:
-Un changement dans la nature d'un mot (par exemple: l'adjectif tachetées est lu
tache- nom commun)
-Un changement non grammatical dans l'ordre des mots ( par exemple: Où
sont-elles donc? lu Donc où sont-sont-elles?).
Deux expressions non grammaticales ont été considérées syntaxiquement acceptables: les chevals pour/es chevaux et Ouss 'qui sont pour Où sont. En effet, ces deux expressions sont d'usage courant en français parlé au Québec. Par conséquent, la capacité pour les jeunes élèves allophones de juger de l'acceptabilité syntaxique de ces formulations n'a pas été prétendue.
Les erreurs graphiques
Pour qu'une erreur soit qualifiée d'erreur graphique, l'erreur produite devait être une approximation valable du mot écrit. Une approximation valable se traduit par la production d'un non-mot ou d'un mot où l'on observe:
-Une substitution phonémique (par exemple: la lecture de binbes pour
dindes)
-Une omission phonémique ou syllabique (par exemple: la production de
séri pour sérieux)
-Un déplacement phonémique (par exemple: la lecture de sinépou pour le
mot poussin)
-Un ajout phonémique: (par exemple: la lecture de dinodon pour dindon).
Les erreurs doubles
Les erreurs contextuelles et graphiques ne sont pas mutuellement exclusives. Une troisième catégorie, les erreurs doubles, a donc été créée pour regrouper les erreurs où les deux types d'informations ont été utilisés. Par exemple l'erreur
« poulets» dans le passage: Il y a des chevaux, des juments et des poulains lu Il y a des chevaux, des juments et des poulets a été cotées erreur double, puisque le mot est
une approximation valable du mot écrit (substitution phonémique de la dernière syllabe) et qu'il est sémantiquement et syntaxiquement acceptable.
Les erreurs inexpliquées et les mots non lus
Dans le cas où aucune information contextuèlle ou graphique n'est observée, l'appellation erreur inexpliquée est utilisée (par exemple: la lecture de aux longues pour le mot saute).
Finalement, une dernière catégorie: mots non lus, a été créée. Ces erreurs correspondent aux mots qui ont été lus au participant par l'expérimentatrice lorsque celui-ci en faisait la demande: soit après une suite d'essais infructueux ou après un blocage important.
Le nombre total d'erreurs équivaut à la somme des erreurs graphiques, erreurs contextuelles, erreurs doubles, erreurs inexpliquées et mots non lus. Les erreurs ayant fait l'objet d'une autocorrection ont été colligées à part, et n'ont pas été inclues dans le nombre total d'erreurs.
Résultats
Introduction
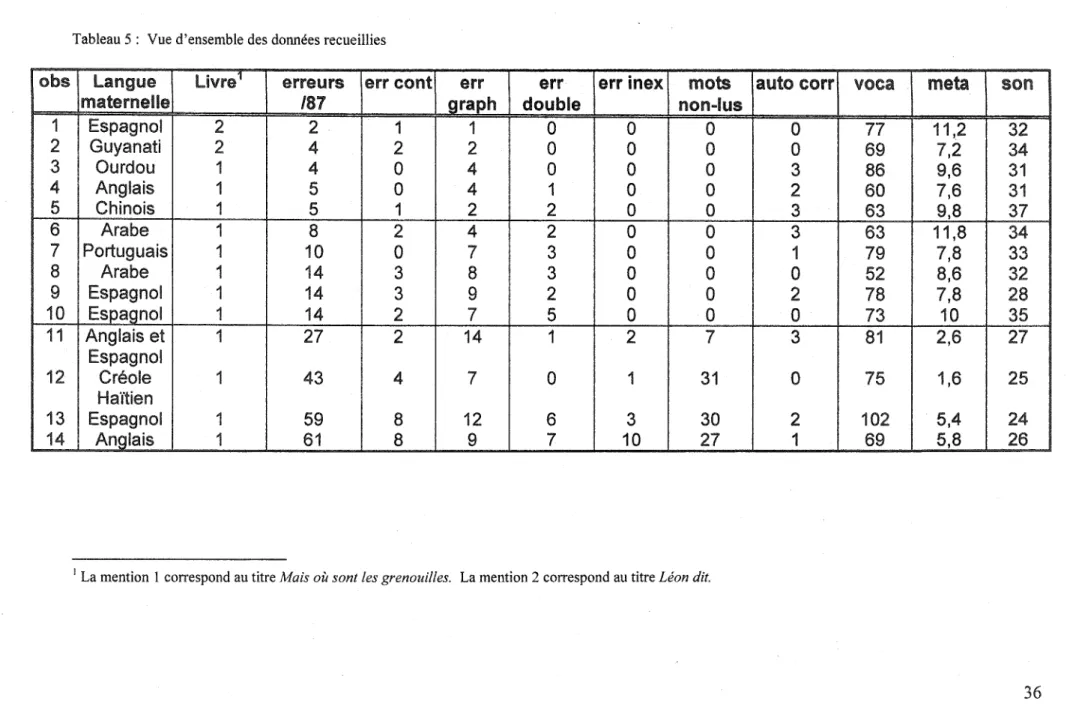
Une vue d'ensemble des données recueillies est exposée dans le tableau 5. La première colonne fournit une identification pour chacun des 14 participants observés. La deuxième colonne fait état de la performance en lecture. Cette performance est mesurée en terme de nombre d'erreurs observées sur une possibilité de 87 erreurs. L'abréviation erreurs/87 sera dorénavant utilisée pour exprimer cette mesure. Les cinq colonnes qui succèdent erreurs/87 font la description du total de ces erreurs observées. :
- erreurs contextuelles (err cont) : erreurs pour lesquelles l'observation d'une utilisation d'informations relatives à la sémantique et à la syntaxe a pu être observée.
- erreurs graphiques (err graph): erreurs desquelles l'utilisation d'indices visuels a été repérée.
- erreurs doubles (err double): erreurs où l'observation des deux types d'informations fut possible.
- erreurs inexpliquées (err inex) : erreurs pour lesquelles aucune référence à un type d'information n'a pu être détectée.
- mots non-lus: mots qui n'ont pu être décodés de façon autonome par le participant.
corrigées sans aide. Cette donnée est publiée à titre indicatif seulement et n'a fait l'objet d'aucune analyse dans cette étude.
Les trois dernières colonnes représentent les résultats obtenus aux tests d'habiletés linguistiques et métalinguistiques, comme suit:
-Les résultats au test de vocabulaire réceptif (voca) : il n'y avait pas de score plafond pour ce test.
-Les résultats aux tests d'habiletés métaphonologiques (méta) :sur un maximum
possible de 12,4.
-Les résultats au test de connaissance du son des graphèmes (son) : pour un maximum possible de 37.
Tableau 5: Vue d'ensemble des données recueillies
obs Langue Livre1
erreurs err cont err err err inex mots auto carl' voca meta son
maternelle 187 graph double non-lus
1
Espagnol2
2
1
1
0
0
0
0
77
11,2
32
2
Guyanati2
4
2
2
0
0
0
0
69
7,2
34
3
Ourdou1
4
0
4
0
0
0
3
86
9,6
31
4
Anglais1
5
0
4
1
0
0
2
60
7,6
31
5
Chinois1
5
1
2
2
0
0
3
63
9,8
37
6
Arabe1
8
2
4
2
0
0
3
63
11,8
34
7
Portuguais1
10
0
7
3
0
0
1
79
7,8
33
8
Arabe1
14
3
8
3
0
0
0
52
8,6
32
9
Espagnol1
14
3
9
2
0
0
2
78
7,8
28
10
Espagnol 114
2
7
5
0
0
0
73
10
35
11
Anglais et1
27
2
14
1
2
7
3
81
2,6
27
Espagnol12
Créole1
43
4
7
0
1
31
0
75
1,6
25
Haïtien13
Espagnol1
59
8
12
6
3
30
2
102
5,4
24
14
Anglais1
61
8
9
7
10
27
1
69
5,8
26
Profil du groupe d'apprentis lecteurs
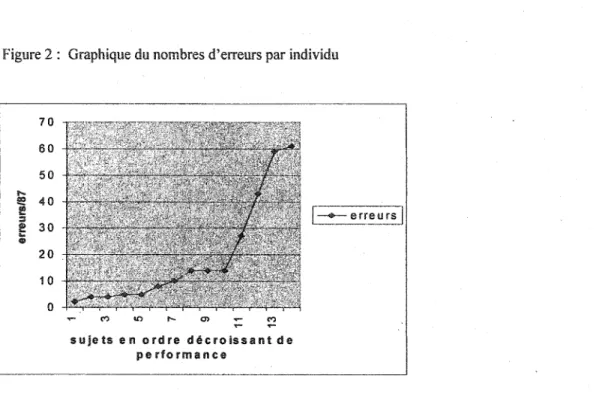
Afin de dresser un profil général du groupe d'apprentis lecteurs observé, l'analyse statistique descriptive de la performance en lecture, telle que mesurée par erreurs/87 fut effectuée (Tableau 6). Une moyenne de 19,28 erreurs a été observée, moyenne de beaucoup supérieure à la médiane, qui eUe est égale à 12. Conséquemment, la courbe de distribution est asymétrique, déformée positivement. De plus, l'écart-type est relativement grand (20,4) laissant présager que le groupe est disparate. La performance en lecture calculée en terme d'erreurs pour chaque participant est illustrée par la figure 2. On remarque que l'augmentation du nombre d'erreurs est beaucoup plus prononcée entre chez les quatre plus mauvais lecteurs que chez les dix autres (participants 1 à 10) ..
Tableau 6· Analyse statistique descriptive pour le nombre d'erreurs
obs erreurs 187 err cont err graph err double err inex mots non- auto corr lus 1 2 1 1 0 0 0 0 2 4 2 2 0 0 0 0 3 4 0 4 0 0 0 3 4 5 0 4 1 0 0 2 5 5 1 2 2 0 0 3 6 8 2 4 2 0 0 3 7 10 0 7 3 0 0 1 8 14 3 8 3 0 0 0 9 14 3 9 2 0 0 2 10 14 2 7 5 0 0 0 11 27 2 14 1 2 7 3 12 43 4 7 0 1 31 0 13 59 8 12 6 3 30 2 14 61 8 9 7 10 27 1 somme: 270 36 90 32 16 95 moy: 19,2857143 ecart type 20,4014651 médiane 12
Figure 2: Graphique du nombres d'erreurs par individu
sujets en ordre décroissant de performance
I-erreurs 1
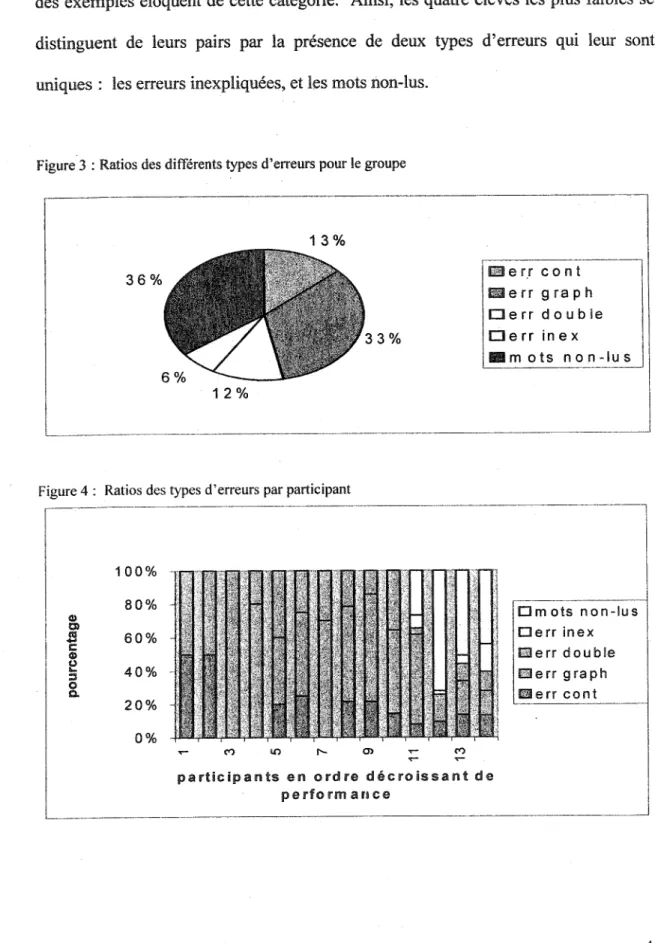
Les ratios des cinq types d'erreurs (erreurs basées sur les indices contextuels, erreurs basées sur les indices graphiques, erreurs doubles, erreurs inexpliquées et mots non-lus) sont illustrés par la figure 3.
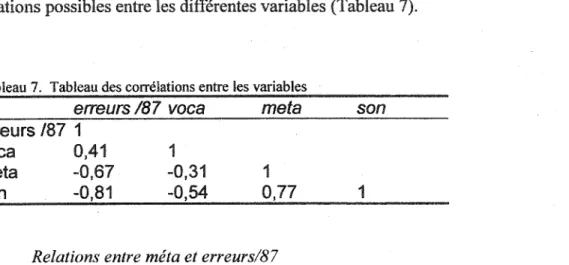
Erreurs graphiques
On remarque que l'utilisation exclusive d'informations de type graphique a été observée dans 33% des erreurs commises. En se référant à la figure 4, on remarque que chez tous les participants sans exception, l'utilisation unique d'indices graphiques dans les méprises a été observée. L'observation de l'utilisation de ce type d'indice s'est fait via des erreurs produites comme: la lecture de trois pour le mot tomate, la lecture de deux pour dans ou encore la lecture de va pour avec. Quatre-vingt dix erreurs de ce genre ont ainsi été commises.
Erreurs contextuelles
L'utilisation exclusive d'informations contextuelles, quant à elle, fut observée dans 13% des méprises (figure 3). Chez 11 des 14 participants, l'usage unique d'indices contextuels a pu être observé. Les trois lecteurs chez qui les indices contextuels n'ont pas été observés sont trois des sept lecteurs ayant produit le moins d'erreurs; soit les sujets numéro 3, 4 et 7 (figure 4). L'observation de l'utilisation d'indices contextuels s'est faite par le biais d'analyse d'erreurs telles que la lecture du mot jument pour le mot poulain, du mot veaux pour le mot grenouille ou encore la production du mot nénuphars pour le mot quenouilles. Trente-six erreurs de ce genre ont été observées.
Erreurs doubles
L'utilisation combinée des deux types d'informations fut observée dans 12% des erreurs (figure 3). Quelques exemples comme la lecture de chatons pour chats, de jumeaux pour juments ou encore de leur pour lui illustre bien que les mots produits sont graphiquement près du mot réel et qu'ils sont possibles sémantiquement et syntaxiquement. Trente-deux erreurs de ce type ont été dénombrées.
Erreurs inexpliquées et mots non lus
Le haut taux de mots non-lus mérite attention. Ce type d'erreurs compte pour 36% du total (figure 3) mais a seulement été produit par les quatre élèves les plus faibles (Figure 4). Il en va de même pour les erreurs inexpliquées qui représentent 16% des erreurs effectuées (figure 3). La lecture du nom oreille pour le verbe
conjugué sautent ou encore de l'onomatopé cocorico pour le nom grenouilles sont
des exemples éloquent de cette catégorie. Ainsi, les quatre élèves les plus faibles se distinguent de leurs pairs par la présence de deux types d'erreurs qui leur sont uniques: les erreurs inexpliquées, et les mots non-lus.
Figure 3 : Ratios des différents types d'erreurs pour le groupe
13%
12 %
Figure 4: Ratios des types d'erreurs par participant
100% 80% CI) tI) ca 60%
....
i: CI) ~ 40% ::1 0 0. 20% 0% lil!J e r.r con t Berr graph Derr double Derr inexam
ots non-lus Dm ots non-lus Derr inex Iillerr double Berr graph lIiiIerr contparticipants en ordre décroissant de p e rfo rm a ri ce
Analyse statistique du rôle des habiletés linguistiques et métalinguistiques
Afin d'expliquer les résultats observés dans la section précédente, une analyse statistique du rôle des habiletés linguistiques et métalinguistiques dans la performance est nécessaire. Un tableau des corrélations a été produit pour faire ressortir les relations possibles entre les différentes variables (Tableau 7).
Tableau 7. Tableau des corrélations entre les variables
erreurs
/87
voca meta sonerreurs /87 1
voca 0,41 1
meta -0,67 -0,31 1
son -0,81 -0,54 0,77 1
Relations entre méta et erreurs/87
En consultant le tableau 7, on constate une corrélation négative (-0,67) entre
erreurs/87 et méta. La figure 5 représente le nombre d'erreurs en fonction des
résultats obtenus aux épreuves d'habiletés métaphonologiques en fonction du nombre d'erreurs. À partir de la fonction linéaire dessinée, on remarque que les performances réelles de trois des quatre plus mauvais lecteurs se démarquent des performances prédites par la fonction linéaire établie. Néanmoins, pour l'ensemble du groupe, l'analyse de variance entre méta et erreurs/87 (tableau 8) révèle que le modèle utilisant méta comme variable indépendante, a une valeur explicative significative de la performance en lecture, F(9,51)=p:5 0,009. De plus, la variable méta,
lorsqu'analysée isolément des autres variables, explique 44,2% (R2) de la variance observée dans la performance en lecture.
Figure 5 : Nuage de points de erreurs/87 en fonction de méta 70 60 50
...
40 ~ ::s e 30 lb 20 1 0 0 0 5 1 0 m êtaTableau 8: Analyse de régression et de variance entre méta et erreurs/87 RAPPORT DÉTAILLÉ Régression R 0,67 RI\2 0,44 RI\2 adj 0,40 Erreur-type 15,83 Observations