Metaelliptical copulas and their use in frequency analysis of multivariate hydrological data.
Texte intégral
Figure
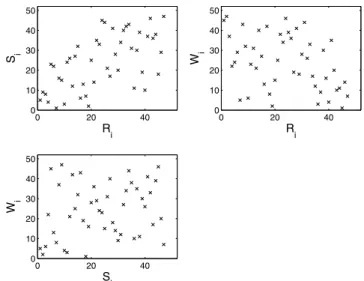


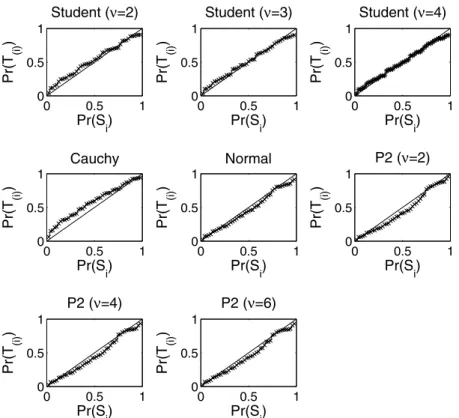
Documents relatifs
Figure 1. Location of the study area, location of the simulated catchments and slope map of the region. The catchment numbers are those of Table 1. Scheme of the MARINE
In this case, standard homogeneous or inhomogeneous Poisson processes cannot be used and models based on univariate or multivariate Hawkes processes or variations of them are
If we consider that a higher error ratio implies a simulation of higher quality, then we notice that for all the proposed datasets the quality of the simulated data seems to be
This part is not exactly an illustration of the theoretical part since it does not focus on the separating rate between the alternative and the null hypothesis, but it is devoted to
D´ eterminez la question que chaque droite gradu´ ee d´
In order to check that a parametric model provides acceptable tail approx- imations, we present a test which compares the parametric estimate of an extreme upper quantile with
Both plots are using monthly maximum of precipitation in Moscow and Kostroma to evaluate upper tail dependence coefficient using
The probability of the type II error is not considered (the probability of accepting the false hypothesis) 3). Selection of the statistic of a GoF test is determined by the
