Growing hierarchical self-organizing map for alarm filtering in network intrusion detection systems
Texte intégral
Figure
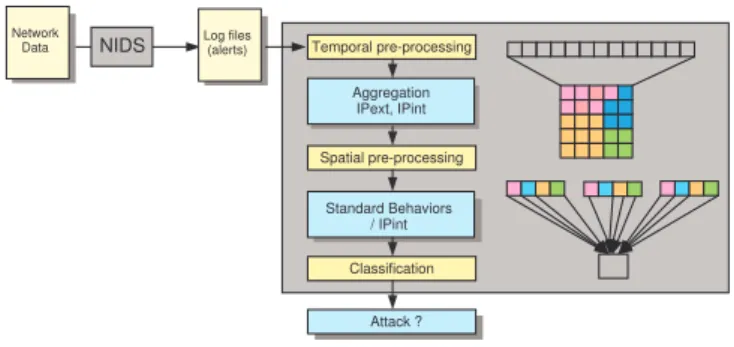
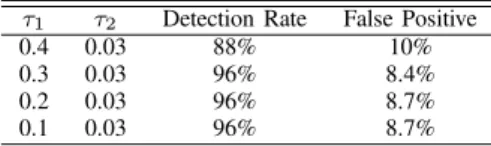
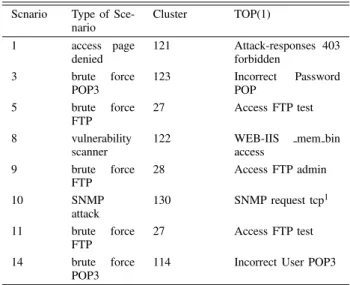

Documents relatifs
The second layer in the hierarchy consists of another SOM which clusters the activity tra- jectories of the first-layer SOM and thus it learns to represent action prototypes
Using prob- abilistic topological algorithms in a rst stage allow to summarize the initial data set into a smaller set of codebook vectors which can be clustered us- ing a
Current state of the art in robotic assistance for surgical procedures [1,2] has a considerable potential for augmenting the precision and capability of physicians,
“SOMbrero: an r package for numeric and non-numeric self- organizing maps,” in Advances in Self-Organizing Maps and Learning Vector Quantization (Proceedings of WSOM 2014),
To process such kind of data unsupervised learning algorithms, such as Self Organizing Maps (SOM) or Growing Neural Gas (GNG), are usually used.. Various aspects of
Parallel modification, Growing Neural Gas with pre-processing by Self Organizing Maps, and its implementation on the HPC cluster is presented in the paper.. Some experimental
This paper deals with the reclamation of industrial land in the context of the current brownfield initiatives supporLed by the Environmental Protection
CONCLUSION—A changing waist affected cardio-metabolic risk factors, and this was most clearly seen for the metabolic syndrome, which accumulates the effects of
