Rabat
N° d’ordre : 2868
THÈSE DE DOCTORAT
Présentée par
Siham LAMZABI
Discipline : Physique Informatique
Spécialité : Physique Informatique
Modélisation et simulation des protocoles de routage et de
propagation des virus dans les réseaux Internet
Soutenue le : 30-04-2016
Devant le jury :
Président :
Mohammed LOULIDI PES, Faculté des Sciences, Rabat Examinateurs :
Abdelilah BENYOUSSEF Professeur, membre résident de l'Académie Hassan II des Sciences et Techniques, Rabat
Youssef EL AMRAOUI PES, Faculté des Sciences, Rabat
Ismail ESSAOUDI PH, Faculté des Sciences, Université Moulay Ismail, Meknès
Hamid EZ-ZAHRAOUY PES, Faculté des Sciences, Rabat Redouane MERROUCH PES, École Mohammadia d'Ingénieurs
Invité :
Abdeljalil RACHADI PA, Faculté des Sciences, Rabat
Faculté des Sciences, 4 Avenue Ibn Battouta B.P. 1014 RP, Rabat-Maroc Tel +212 (0) 37 77 18 34/35/38, Fax: +212 (0) 37 77 42 61, http:/www.fsr.ac.ma
2
Table des matières
Remerciement--- 5
Abstract --- 6
Résumé --- 7
Introduction générale --- 8
Chapitre 1 : État de l’art --- 14
I. Théorie des graphes --- 14
I.1. Bref historique sur la théorie des graphes. --- 14
I.2. Qu’est-ce qu’un graphe ? --- 15
I.2.1. Définition --- 15
I.2.2. Graphes non orientés --- 15
I.2.3. Graphes orientés --- 16
I.2.4. Graphes pondérés --- 17
I.3. Graphe et Chaîne de Markov --- 18
I.3.1. Chaîne de Markov --- 18
I.3.2. Lien entre chaîne de Markov et théorie des graphes --- 19
I.4. Outils mathématiques et physiques --- 20
II. Types de réseaux --- 21
III. Routage --- 23
III.1. Modes de routage --- 24
III.1.1. Routage statique --- 24
III.1.2. Routage dynamique --- 25
III.2. Algorithme de routage --- 27
III.2.1. Routage fixe et routage adaptatif --- 27
III.2.2. Sélection de la route --- 29
III.2.3. Calcul d'une route --- 34
III.2.4. Congestion dans les réseaux --- 36
IV. Propagation des virus sur réseau--- 37
IV.1. Définition et structure d'un virus --- 37
IV.1.1. Qu'est-ce qu'un virus informatique ? --- 37
IV.1.2. Cycle de vie d'un virus --- 38
IV.1.3. Structure d’un virus --- 39
IV.1.4. Différents types de virus --- 40
IV.2. Méthodes de détection (anti-virus) --- 45
IV.2.1. Types d'anti-virus --- 45
IV.2.2. Fonctionnement.--- 46
IV.3. Modélisation de propagation et réparation de virus --- 49
V. Conclusion --- 50
Chapitre 2 : Réseaux complexes --- 51
I. Introduction --- 51
3
III. Réseau aléatoire --- 53
IV. Réseau petit-monde --- 54
V. Réseaux sans échelle --- 55
V.1. Réseau de Barabasi Albert (BA) --- 57
V.2. Propriétés de vérifications du réseau (BA) --- 60
VI. Conclusion --- 61
Chapitre 3 : Algorithmes de routage dans un réseau Sans échelle--- 63
I. Introduction --- 63
II. Model de trafic minimal --- 64
III. Rapprochement analytique à la réduction de la congestion--- 66
IV. Adaptation myope --- 69
IV.1. Modèle A --- 70
IV.2. Modèle B --- 70
V. Adaptation empathique --- 72
VI. Conclusion --- 75
Chapitre 4 : Taux de rejet au niveau des paires de nœuds et son impact sur les flux du trafic dans un réseau sans échelle --- 78
I. Introduction --- 78
II. Protocole de rejet statique --- 80
II.1. Protocole de rejet symétrique --- 81
II.2. Protocole de rejet asymétrique --- 83
II.3. Application du protocole asymétrique sur un réseau carré --- 85
III. Protocole de rejet dynamique --- 86
IV. Conclusion --- 88
Chapitre 5 : Modèles de propagation de virus au niveau des ordinateurs --- 89
I. Introduction --- 89
II. Propagation des virus --- 90
III. Modèles de propagation de virus --- 90
III.1. Modèle SI --- 90
III.2. Modèle SIR --- 92
IV. Conclusion --- 93
Chapitre 6 : Modélisation de la propagation des virus dans les paquets d'informations dans un réseau sans échelle --- 96
I. Introduction --- 96
II. Modèles de propagation --- 97
III. Modèle SI --- 98
4 V. CONCLUSION --- 105 Conclusion générale --- 106 Références --- 108 Publications --- 116
5
Remerciement
Cette thèse a été réalisée au sein du Laboratoire du Magnétisme et Physique des Hautes Energies (LMPHE), de la Faculté des Sciences de l’Université Mohammed V-Rabat sous la direction du professeur Monsieur EZ-ZAHRAOUY Hamid.
J'adresse tous mes remerciements à toutes les personnes qui m'ont aidé dans la réalisation de cette thèse. En premier lieu, je tiens à remercier le directeur de cette thèse, le professeur Hamid EZ-ZAHRAOUY pour l’aide qu'il m’a apporté, sa disponibilité permanente et le partage de ses grandes connaissances, sa passion pour la recherche, ainsi que pour ses orientations et ses encouragements le long de l’élaboration de cette thèse.
Je tiens à exprimer mes sincères remerciements à Monsieur Mohammed LOULIDI, Professeur d’enseignement supérieur de la Faculté des Sciences Rabat, d’avoir accepté de présider le jury de cette thèse.
Je tiens à remercier également le professeur Abdelilah BENYOUSSEF, membre résident de l'Académie Hassan II des Sciences et Techniques, pour ses fructueuses explications, ses précieux conseils et ses qualités professionnelles et humaines.
Je tiens à remercier, Monsieur le professeur Youssef EL AMRAOUI, Professeur d’enseignement supérieur de la Faculté des Sciences Rabat, d’avoir accepté de participer à ce jury, en tant que rapporteur et examinateur.
Je tiens à exprimer mes sincères remerciements à Monsieur Ismail ESSAOUDI, Professeur habilité à la Faculté Moulay Ismail de Meknès, pour avoir accepté de participer à ce jury, en tant que rapporteur et examinateur.
Je tiens à exprimer mes sincères remerciements à Monsieur Redouane MERROUCH, Professeur d’enseignement supérieur à l'Ecole Mohammadia d'Ingénieurs, pour avoir accepté de participer à ce jury, en tant qu’examinateur.
Je tiens à remercier également Monsieur Abdeljalil RACHADI, Professeur Assistant à la Faculté des Sciences de Rabat, pour sa disponibilité, son aide soutenu dans le déroulement des recherches de cette thèse et d’avoir accepté de participer à ce jury.
Je voudrais aussi remercier tout particulièrement mes collègues du laboratoire LMPHE. Enfin, une pensée particulière et pleine de gratitude à mes parents et à toute ma famille.
6
Abstract
This thesis focuses on modeling and simulation of routing protocols to reduce congestion and on the problem of the virus propagation in networks.
First, we propose a pair-dependent rejection rate of packet information between routers in the framework of the minimal traffic model applied to scale-free networks. We have shown that the behavior of the transition point from the phase where the system balances the inflow of new information packets with successful delivery of the old ones to the congested phase depends on the underlying mechanism of packet rejection. It is possible to achieve larger values for the critical load by varying the rejection of the packets issued from a given node by its neighbors.
We have proposed an asymmetric protocol, where we found the existence of a whole interval where the packet rejection is strongly beneficial to the overall performance of the system.
We have also shown that for the dynamic protocol, the transition point is shifted toward higher values permitting the network to handle more traffic load, despite the fact that the critical load decreases when increasing the rejection parameter.
Second, we propose also a new model for computer virus attacks and recovery at the level of information packets. The model we propose is based on one hand on the SI and SIR stochastic epidemic models for computer virus propagation and on the other hand on the time-discrete Markov chain of the minimal traffic routing protocol.
We have applied this model to the scale free Barabasi-Albert network to determine how the dynamics of virus propagation is affected by the traffic flow in both the free flow and the congested phases. The numerical results show essentially that the proportion of infected and recovered packets increases when the rate of infection λ and the recovery rate β increase in the free flow phase while in the congested phase, the number of infected (recovered) packets presents a maximum (minimum) at certain critical value of β characterizing a certain competition between the infection and the recovery rates.
Keywords : traffic, network, internet, markov chaine, minimal, congestion, spread, virus, SI, SIR.
7
Résumé
Cette thèse porte sur la modélisation et la simulation des protocoles de routage, permettant de réduire la congestion, ainsi que sur le problème de propagation des virus dans les réseaux. Dans un premier temps, nous avons proposé un taux de rejet de paquets d'informations sur le modèle de trafic minimal, au niveau de chaque lien reliant les routeurs sur les réseaux sans échelle (Scale free), et nous avons montré que la valeur du point de transition, entre la phase de la circulation libre (Free Flow) ou nous avons une balance entre les paquets reçus et les paquets envoyés, et la phase de la congestion, change en fonction du mécanisme du rejet du paquet d’informations suscité.
Il est possible d’atteindre de grande valeur du point de transition critique, tout en variant le taux de rejet de paquets émis, par un nœud donné à ses voisins.
Les protocoles de rejet de paquets dynamiques et statiques (symétrique et asymétrique) ont été proposés :
Concernant le protocole asymétrique : nous avons constaté l'existence d’un intervalle de points, dans lequel le rejet de paquets a été important pour le rendement global du système.
Quant au protocole dynamique : il a été constaté que le point de transition est décalé vers des valeurs plus élevées, permettant au réseau de traiter plus de trafic et ce en dépit du fait que la valeur de transition critique diminue lorsqu'on augmente le paramètre du taux du rejet.
Dans un deuxième temps, des modèles d’attaque et de correction des virus informatiques ont été également proposés, au niveau des paquets d'informations. Ils sont basés, d'une part sur les modèles stochastiques épidémiques SI et SIR, pour la propagation du virus dans l'ordinateur, et d'autre part sur la chaîne discrète de Markov du protocole de routage du trafic minimal. Nous avons appliqué également ces modèles sur les réseaux de type sans échelle Barabasi-Albert, pour déterminer comment la dynamique de la propagation du virus est affectée par le flux du trafic dans les deux phases (circulation libre (Free Flow) et congestion). Les résultats numériques ont montré que la proportion des paquets infectés et celle des paquets corrigés augmentent lorsque le taux d'infection λ et le taux de correction β augmentent dans la phase d'écoulement libre. Tandis que dans la phase congestionnée, le nombre de paquets infectés (réparés) présente un maximum (minimum) à une certaine valeur critique de β, caractérisant une certaine concurrence entre les taux d'infection et de réparation.
Mots clés : trafic, réseau, internet, chaine de markov, minimal, congestion, propagation, virus, SI, SIR.
8
Introduction générale
Un réseau est une structure composée de nœuds, représentant généralement un individu, une organisation, un routeur... et d’arêtes représentant les liens entre les nœuds.
Les liens peuvent représenter différentes relations comme l’amitié, le commerce, un conflit, une relation de travail, câble . . .
Ainsi, les réseaux sont des modélisations de l’interaction à l’aide des graphes où les nœuds sont les acteurs individuels ou collectifs et les arêtes sont les relations qui interviennent entre eux. Les graphes résultants sont le plus souvent complexes en raison de la diversité des nœuds et des liens possibles.
Les recherches ont montré que de tels réseaux se retrouvent à différents niveaux d’organisation, en citant entre autres le réseau familial et le réseau composé par les membres d’une même nation [1].
De plus, le type de réseau considéré influence sur les méthodes d’analyse utilisées ainsi que sur les résultats attendus.
Dans quelques exemples de réseaux sociaux et des études associées, on trouve le réseau des collaborations scientifiques [2], le réseau des contacts par courrier électronique [3], les participations croisées des dirigeants aux conseils d’administration d’entreprises américaines [4], les acteurs hollywoodiens [5] et d’autres.
Emile Durkheim et Ferdinand Tonnies sont considérés comme les précurseurs des réseaux sociaux vers la fin du XIXe siècle.
Tonnies disait que les groupes sociaux pouvaient être considérés comme des liens personnels et sociaux, que ce soit entre individus partageant des valeurs et des croyances, ou entre des liens plus formels et impersonnels [6].
Durkheim a donné une explication des faits sociaux. Explication non centrée sur l’individu mais basée sur l’idée que les phénomènes sociaux apparaissent avec l’interaction sociale. C’est à dire sans prendre en compte les caractéristiques propres de chaque acteur [7]. Dans les années 1930, José-Luis Moreno fut le premier à systématiquement enregistrer et analyser les interactions sociales dans de petits groupes, particulièrement les salles de classes et les groupes de travail. Ce qui a donné naissance à la sociométrie [8].
Puis en 1940, Alfred Radcliffe-Brown a pris position, en faveur de l’étude systématique des réseaux sociaux, au sein des populations étudiées [9].
Dans le même temps, un groupe de chercheurs de Harvard, dirigé par Loyd Warner et Elton Mayo, a exploré les relations interpersonnelles sur les lieux de travail [10]. Nous pouvons ainsi dire que ces anthropologues sont les fondateurs de l’intérêt porté à l’analyse des réseaux. Cette nouvelle discipline a ensuite développé des ramifications dans d’autres branches telles que les communications, la sociolinguistique ou même la biologie et la géographie.
A partir de 1954, J.A. Barnes utilise le terme de réseau plus spécifiquement, en parlant de groupes restreints, tels que la famille ou la tribu, ou de catégories sociales.
9
Ensuite, dans les années 1960, de nombreux universitaires ont travaillé ensemble pour combiner différentes études.
En 1967, le psychologue Stanley Milgram [11] a mené une expérimentation sur l’existence d’un petit nombre de liens entre deux personnes. Il a demandé à un groupe de citoyens américains de faire parvenir un courrier à une personne, tout en passant par leurs connaissances. La personne à joindre n’était pas connue et seuls quelques indices, comme le métier, le nom et la situation sociale, permettaient d’orienter le courrier vers la personne adéquate. Milgram a constaté que les courriers arrivés à bon port n’avaient transité que par un faible nombre de personnes, s’arrêtant à une moyenne de cinq intermédiaires, soit six liens.
Même si des études ont montré que ce nombre peut être plus élevé selon les cas [12], ces six degrés de séparation sont maintenant bien connus du public.
Récemment, une étude similaire a été menée par l’université de Columbia et a montré que cinq à sept degrés sont suffisants pour relier deux personnes par e-mail [13].
En 1973, Mark Granovetter a développé une théorie sur l’importance des liens faibles [14]. Un lien faible rattache un individu à une connaissance éloignée et constitue tout de même, d’un point de vue structurel, une base d’échange.
Il résulte donc qu’avoir de nombreux liens faibles est important, quand on cherche une information ou on diffuse une innovation.
Si un individu a tendance à créer des liens forts avec des personnes, partageant des opinions et des traits communs [15], cela limite aussi les connaissances qu’il peut acquérir par eux car ces connaissances sont similaires à chacun d'eux.
Pour augmenter leurs connaissances, les membres d’un tel groupe devront chercher l’information parmi des individus avec lesquels, ils ont créé des liens moins importants. C’est ce que Granovetter appelle la force des liens faibles.
L’analyse des réseaux est ainsi passée de la métaphore à un champ de recherche à part entière, avec ses propres théories, ses méthodes, ses chercheurs et ses outils, principalement informatiques et statistiques.
Internet [16] est le réseau informatique mondial le plus adapté à ces études. C'est une création du département de la Défense Américaine, nommé ARPANET, afin de relier l’ensemble des sites militaires américains. C’est en fait un réseau de communication permettant à un ordinateur de transmettre des informations à un autre ordinateur quelle que soit sa position sur la planète. L’internet connaît de nos jours une mutation au niveau de ses usages. De réseau mono service pour transporter des fichiers binaires ou textuels, il y a vingt ans, à un réseau multiservices pour le transport de données diverses et variées comme des données audio et vidéo (films, vidéo à la demande, téléphonie, etc.).
Malgré cela, les tentatives pour garantir la qualité de service de l’Internet ont échoué, notamment à cause d’une complète méconnaissance du trafic internet (Internet traffic en anglais), qui désigne la circulation des flux d'informations sur Internet.
10
Afin d'éviter le problème de la congestion et d'offrir aux utilisateurs un service de bonne qualité, fiable et rapide, de nombreuses recherches ont été réalisées à cet effet.
Or, pour concevoir des procédures efficaces de contrôle de la circulation des informations, une connaissance approfondie des propriétés statistiques du trafic de données dans de tels réseaux s'impose.
La modélisation du trafic sur réseau consiste à établir des modèles réalistes incluant la topologie et le type de réseau, les propriétés des nœuds et des liens, les protocoles de routage, les problèmes qui peuvent affectés le réseau (panne, virus ...) et la manière par laquelle les paquets circulent dans le réseau. Ceci mène à comprendre et à étudier les propriétés du réseau internet.
L'analyse mathématique du trafic sur les réseaux de communication est une discipline ancienne qui remonte à 1917, avec les travaux menés par l'ingénieur danois Agner K. Erlang. Sa démarche a constitué une base pour les autres recherches qui suivent, jusqu'à l'année 1990 environ.
La démarche mathématique, mise en œuvre par Erlang et par d'autres chercheurs après lui, décrit le trafic en s'appuyant sur le modèle de la chaine de Markov, qui est une suite d'événements aléatoires, dans laquelle la probabilité de choisir un événement donné ne dépend que de l'événement précédant. Cette démarche markovienne d'Erlang considère que le trafic est régi par une loi qui décrit le comportement du nombre d'évènements, se produisant dans un laps de temps fixé.
Le réseau Internet a connu dernièrement un développement remarquable par l'ajout de nouveaux services pour faciliter l'accès. Ce qui rend le réseau Internet indéfiniment extensible. Ces modifications structurelles effectuées sur le réseau Internet ont changé les propriétés statistiques du trafic et il a fallu développer une théorie mathématique adaptée à ces nouvelles données.
En effet, des analyses statistiques ont été effectuées, au milieu des années 1990, par des chercheurs de Bellcore, aux États-Unis, et de l'INRIA (Institut national de recherche en informatique et en automatique), en France, et ont montré, d'abord sur des réseaux locaux puis sur le web, que le trafic ne pouvait plus être décrit à l'aide de lois de probabilité de Poisson [17].
En observant des processus aléatoires à mémoire longue, nous constatons que la probabilité qu'un événement se réalise, dépend également d'événements produits dans un temps relativement loin dans le passé. Chose qui ne concorde pas avec les modélisations markoviennes classiques.
Afin d'établir le bon modèle décrivant le trafic Internet et d'en améliorer le fonctionnement, une modélisation statistique particulière du réseau Internet reposant sur l'analyse mathématique du trafic a été effectuée. Les scientifiques ont répartis cette étude selon leur domaine de recherche : les géographes étudiaient les réseaux planaires, les sociologues les réseaux non planaires.
11
L’arrivée des physiciens a quelque peu perturbé cette division du travail en proposant deux nouveaux modèles de graphes qui ont connu une popularité quasi instantanée ;
les réseaux petit-monde (small world networks) [18], et
les réseaux sans échelle (scale-free networks) [19].
Les réseaux sans échelle (scale-free en anglais) se définissent précisément par l'impossibilité d'identifier, pour un phénomène donné, une quelconque échelle qui lui serait caractéristique. Autrement dit, il y a invariance d'échelle lorsqu'aucune échelle ne caractérise le système et que toutes les échelles jouent des rôles également équivalents.
Les premières observations de comportement en lois d'échelle, en cas d'Internet, ont été effectuées à la fin des années 80 [20-22]), sur des données Ethernet, de haute qualité, collectées dans un laboratoire de Bellcore [23,24].
Dans les années suivantes, des analyses complémentaires, réalisées sur des données et sur des réseaux différents, ont confirmé l'existence de phénomènes d'invariance d'échelle.
Dans l'état actuel, des recherches se dirigent vers l'analyse paquet par paquet des flux transmis, pour tenter d'identifier la nature des lois d'échelle, leur cause et les éléments qui les déterminent et qui les contrôlent [25-27].
Toujours, dans le but d'améliorer le trafic sur réseau Internet, et en plus de ces études qui visent l'analyse du trafic sur réseau Internet, il existe un autre facteur auquel on peut jouer pour augmenter la fluidité du trafic des données. Il s'agit des algorithmes qui gouvernent la manière dont les informations sont acheminées dans le réseau, ou ce qu'on appelle les algorithmes de routage. Leur rôle est de faire transiter des paquets d'un nœud vers leurs destinations, selon un algorithme de routage bien défini.
Plusieurs politiques de routage, proposées jusqu'à présent, sont basées sur les propriétés statiques du réseau de communication.
A titre d’exemples de ces politiques, on trouve les acheminements aléatoires (random walks) [28,29], les plus courts chemins (shortest-path) [30,31] et le chemin efficace (efficient-path) [32]. Ces mécanismes de routage peuvent être facilement reformulés pour incorporer les informations sur l'état dynamique du système, à savoir, l'état des routeurs ; congestionnés ou pas. Ce qui permet de modifier les chemins empruntés par les paquets d'informations afin de contourner les routes très encombrées.
En plus de la conception des protocoles de routage, plusieurs stratégies efficaces, pour éviter la congestion, ont été mises en œuvre. On trouve à titre d’exemples, l'adaptation d'une probabilité de rejet du flux entrant [33,34] et les mécanismes de chute de paquet (packet-dropping) [35] pour éviter l'encombrement de chaque nœud, ou l'ajout d'une mémoire de routeur afin d'éviter le piégeage des paquets entre deux nœuds adjacents [36].
Toutes ces études ont supposé que la topologie du réseau et les mécanismes, pour éviter la congestion, sont statiques. Alors ni la topologie ni les stratégies de routage ne sont changées. Cependant, cette approche néglige le fait que pour le même graphe, la politique de routage optimale dépend fortement de l'état de congestion du système [33, 34, 37-40].
12
Par conséquent et afin d'équilibrer correctement la congestion dans un système de communication, il semble approprié de permettre aux routeurs de contrôler leur propre stratégie. Cette solution a pour but d’éviter la congestion, suivant un mécanisme d'adaptation permettant aux nœuds de choisir leurs stratégies individuelles, au lieu d'imposer une politique commune par l'exploitation de leur information locale sur l'état du système de la congestion, ainsi que de décider d'accepter ou non les paquets entrants, en utilisant des stratégies tel que (minimal, myope...) [41,42].
En réalité, la décision de rejeter les paquets d'informations par un nœud quelconque ne doit pas dépondre uniquement de l'état du nœud en question mais également de celui de son voisin. Alors est-il possible de créer des protocoles de rejet dépondant des paires de nœuds, (émetteur, récepteur) ayant une influence sur la réduction de la congestion ?
Malheureusement, de nombreux inconvénients pourraient affecter les paquets d’informations au cours de leur passage via les nœuds. Exemple : les virus informatiques.
Un virus informatique est un code mobile malicieux tels que les virus, les vers, les chevaux de Troie, la bombe logique et ainsi de suite [43-45].
Chaque code a sa façon, de se propager dans l'Internet. En effet, le virus attaque principalement le système de fichiers, le ver pénètre au système de recherche et attaque l'ordinateur, quant aux chevaux de Troie, ils se camouflent et encouragent les utilisateurs à les télécharger. Les virus informatiques ont les mêmes spécificités, à savoir : l'infectiosité, l’invisibilité, la latence, et l'imprévisibilité [46].
Ils sont considérés comme l'arme la plus distractive dans l'internet, et leur propagation a un effet néfaste sur le monde de l'informatique [47-49] (la science, l'économie, les entreprises, etc.) [50].
En 1988, un étudiant, de l'Université Cornell, a compilé un code appelé le virus de la vie sans fin. La propagation de ce code a mis fin à des milliers d'ordinateurs [51].
Il y a également les "Code Red" et "Nimda" qui ont provoqué plusieurs milliards de pertes économiques, lors de leur diffusion dans Internet [52,53].
En 2003, un virus appelé "2003 worm King", s’est propagé rapidement et a attaqué les ordinateurs du monde entier. Ce qui a entraîné le blocage du réseau Internet et la paralysation des serveurs [54].
Cohen [55] et Murray [56] ont proposé d'exploiter les techniques développées dans la dynamique de l'épidémie biologique pour étudier les lois régissant la propagation des virus informatiques.
De multiples modèles épidémiques de virus informatiques ont été proposés, à savoir entre autres :
Les modèles classiques : tels que les modèles de SIS [57,58], les modèles SIR [59,60], les modèles SIRS [61,62], et
Les modèles non conventionnels : tels que les modèles retardés [63-65], les modèles impulsifs [66,67], et des modèles stochastiques [66,68].
13
En réalité, la propagation des virus informatiques se fait au niveau des paquets d'informations. Au niveau de n'importe quel ordinateur, nous avons des paquets qui sont susceptibles, infectés ou bien traités à l'aide d'un antivirus.
Peut-on proposer des modèles qui permettront de voir l'évolution de ces derniers au niveau des nœuds ? L'état du système (circulation libre ou congestion) influencera-t-il sur la propagation du virus ?
Dans ce mémoire, nous allons nous intéresser à l’étude de quelques caractéristiques du réseau Internet, à savoir :
les protocoles de rejets agissant aussi bien au niveau des nœuds que des liens dans le but de réduire le taux de congestion dans les réseaux sans échelle,
la propagation des virus au niveau des paquets d'informations dans le même réseau. A cet effet, cette thèse est organisée en six chapitres, à savoir :
Le premier chapitre est consacré au traitement du réseau en général, tout en introduisant la notion de la théorie des graphes, le routage, des explications sur la propagation des virus, tout en citant quelques modèles de propagation (état de l'art).
Le deuxième chapitre est consacré à l'étude des différents réseaux (régulier, aléatoire, petit monde et sans échelle), tout en se focalisant sur les réseaux de type sans échelle "scale free" qui sont utilisés dans nos simulations.
Le troisième chapitre est consacré aux algorithmes de routage : Modèle de trafic minimal, qui est le modèle le plus simple, et les modèles myope et empathique, permettant aux nœuds d'adapter leur propre taux de rejet et ce afin de réduire la congestion.
Le quatrième chapitre vise la proposition des protocoles statiques (symétrique et asymétrique) et dynamiques, de rejet de paquet d'informations au niveau des liens entre les nœuds, et leurs applications sur le modèle de trafic minimal dans un réseau sans échelle et ce dans le but de réduire la congestion.
Le cinquième chapitre traite l'introduction et l'explication des modèles de propagation de virus (SI et SIR) qui sont les modèles les plus utilisés dans le domaine de l'informatique.
Le sixième chapitre est consacré à l'infection du réseau tout en proposant de nouveaux modèles d'attaque au niveau des paquets d'informations, qui seront basés sur la mixture d'une part des modèles stochastiques et épidémiques SI et SIR pour la propagation du virus de l'ordinateur et d'autres part sur la chaîne de Markov du protocole de routage du trafic minimal.
Enfin, une conclusion générale faisant part de la synthèse des principaux résultats obtenus au cours des travaux de la thèse, et quelques perspectives des travaux de recherches.
14
Chapitre 1 : État de l’art
I. Théorie des graphes
I.1. Bref historique sur la théorie des graphes.
L'origine de la théorie des graphes est généralement attribuée à Leonard Euler et à son article [69] sur le problème des sept ponts de Königsberg.
La ville est alors construite sur deux îles et les berges environnantes, qui sont reliées par sept ponts. Euler se demande s’il existe une promenade à travers la ville qui permet de passer une fois et une seule sur chaque pont et de revenir à son point de départ (voir figure 1.1).
Pour résoudre le problème, Euler introduit les premiers éléments de la théorie des graphes et montre qu'un tel chemin n'existe pas, car ce graphe comprend un trop grand nombre de sommets incidents à un nombre impair d'arêtes.
Les mathématiciens se sont ensuite largement intéressés aux graphes réguliers, et à des problèmes statiques sur graphes, comme le problème de la coloration de graphes, avant que le développement des lois de l'électricité n'attire leur attention sur des problèmes de flots sur réseaux.
Ce n'est finalement qu'au milieu du XXe siècle qu'Erdös et Rényi [70, 71] introduisirent la notion de probabilité dans la construction des graphes.
15 I.2. Qu’est-ce qu’un graphe ?
I.2.1. Définition
On appelle graphe G = (X,A) la donnée d’un ensemble X, dont les éléments sont appelés sommets ou nœuds, et d’une partie de A symétrique((𝑥, 𝑦) ∈ 𝐴 ⇔ (𝑦, 𝑥) ∈ 𝐴 ) dont les éléments sont appelés arêtes ou liens.
En présence d’une arête a = (x, y) qui peut être notée simplement xy, on dit que x et y sont les extrémités de a, que a est incidente en x et en y, et que y est un successeur ou voisin de x et vice versa.
Graphiquement, les sommets peuvent être représentés par des points et l’arête a = (x, y) par un trait reliant x à y.
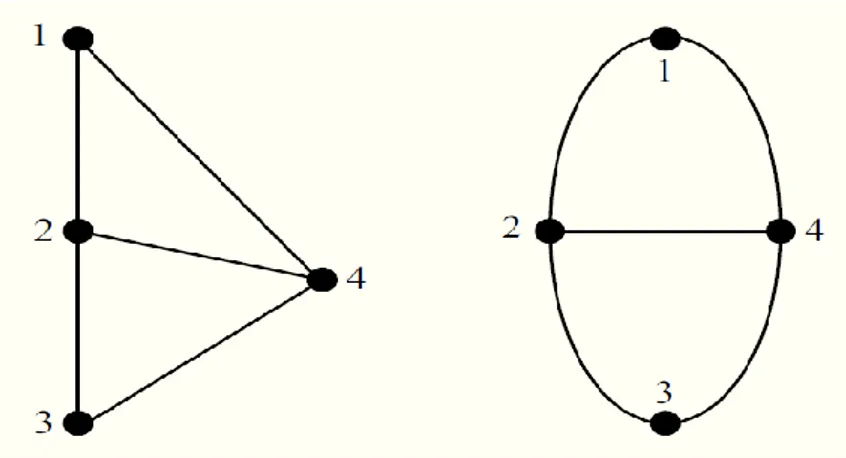
On notera que la disposition des points et la longueur ou la forme (rectiligne ou incurvée) des traits n’ont aucune importance. Seule l’incidence des différentes arêtes et sommets comptent. A titre d’exemple, les deux graphes de la figure 1.2 sont identiques.
Figure 1.2 : Deux représentations graphiques d’un même graphe
Par la suite, nous utiliserons davantage les termes de nœud (node) et de lien (link) plutôt que sommet et arête.
La densité du graphe désigne le rapport du nombre de liens L (= |E|) au nombre de nœuds N (= |V |).
I.2.2. Graphes non orientés
Deux nœuds liés sont dits voisins (neighbours) l’un de l’autre. On qualifie de chemin (path) entre deux nœuds, une séquence de liens consécutifs dont ils sont les extrémités. La longueur de ce chemin sera le nombre de liens qu’il comporte ; la distance entre deux nœuds sera le minimum des longueurs de chemins allant de l’un à l’autre.
Si un graphe ne contient pas de liens associant un nœud à lui-même (boucle - self-loop), on parle de graphe simple (simple graph), mais nous nous dispenserons de cette précision quand il n’y a pas d’ambiguïté sur le caractère simple ou non du graphe.
16
On utilisera abondamment la notion de degré (degree) d’un nœud (K). Il s’agit du nombre d’extrémités de liens partant de celui-ci.
Remarquons que pour un graphe simple, le degré s’assimile au nombre de voisins et le degré moyen (𝐾̅ ) à la densité du graphe. La matrice d’adjacence (adjacency matrix) A est une représentation matricielle exactement équivalente au graphe. Cette matrice (N × N) est binaire, mab = 1, s'il existe un lien entre les nœuds xa et xb, mab = 0 dans le cas contraire. On notera
qu’elle est nécessairement symétrique selon notre définition d’un graphe, et pour un graphe simple ses éléments diagonaux sont nuls.
De plus, nous ne pouvons dès maintenant faire l’observation que lorsqu’il s’agira de considérer des graphes de plus grande taille. Les matrices d’adjacences associées seront souvent éparses : le degré moyen est très petit devant le nombre de nœuds du graphe (𝐾̅<< N).
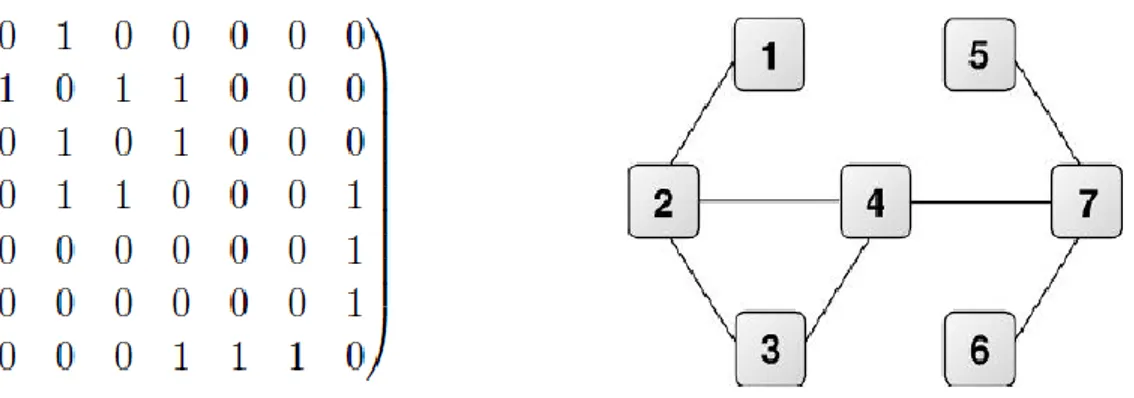
Pour illustrer ces définitions, imaginons un groupe de sept individus dont on cherche à décrire les interactions et les possibles échanges d’informations. Le graphe simple ci-dessous (et la matrice d’adjacence qui lui est associée) pourrait représenter l’existence de discussion entre les membres du groupe sur une période donnée. Ce qui se prête bien à un modèle de graphe non-orienté puisque l’échange d’informations peut être réciproque.
Fig. 1.3 : Exemple de graphe simple, non-orienté et matrice d’adjacence associée. I.2.3. Graphes orientés
Dans un graphe orienté (directed graph ou digraph), un lien est dirigé d’un nœud vers un autre. On parle alors d’arc (arc) d’une source vers une destination (ou extrémité initiale et terminale). La notion de degré sera alors généralisée en degré sortant (outdegree) et degré entrant (indegree). Pour définir un chemin orienté (ou chaîne) entre les nœuds xa et xb, il faut pouvoir construire
une suite d’arcs de la forme : {(xa, x1); (x1, x2); ...; (xk−1, xk); (xk, xb)}.
Dans le contexte des graphes orientés, on définira également une matrice d’adjacence. Les lignes correspondront aux nœuds sources et les colonnes aux destinations. Contrairement au cas précédent cette matrice n’est pas symétrique.
17
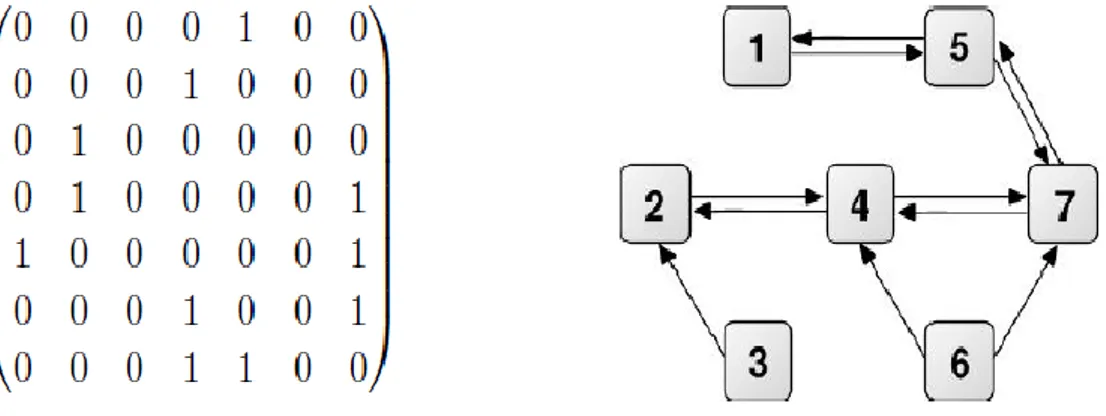
Reprenant le groupe d’individus de l’exemple précédent, le graphe suivant, simple et orienté, pourrait représenter l’existence d’échanges par e-mails entre ses membres, pour lesquels on identifie clairement un émetteur et un récepteur de l’information.
Fig. 1.4 : Exemple de graphe simple, orienté et matrice d’adjacence associée. I.2.4. Graphes pondérés
Le multi-graphe est une extension de la notion de graphe autorisant l’existence de liens multiples entre les nœuds. On utilisera plutôt le terme de graphes pondérés (weighted graphs). Il est bien sûr aussi possible de construire des graphes pondérés et orientés.
On trouve parfois une distinction entre multi-graphe et pseudo-graphe. Le second peut comprendre des boucles, mais le terme multi-graphe est souvent utilisé en ce sens. On ne fera donc pas la nuance.
La matrice d’adjacence est toujours définie, mais elle n’est plus binaire : la valeur de mab étant
le nombre de liens (la multiplicité ou poids) existant entre les nœuds xa et xb.
Selon cette définition mab∈ N, on peut généraliser la notion de graphe pondéré à des cas ou
mab∈ R, si l’on souhaite quantifier une relation autrement que par le nombre d’interactions
entre agents.
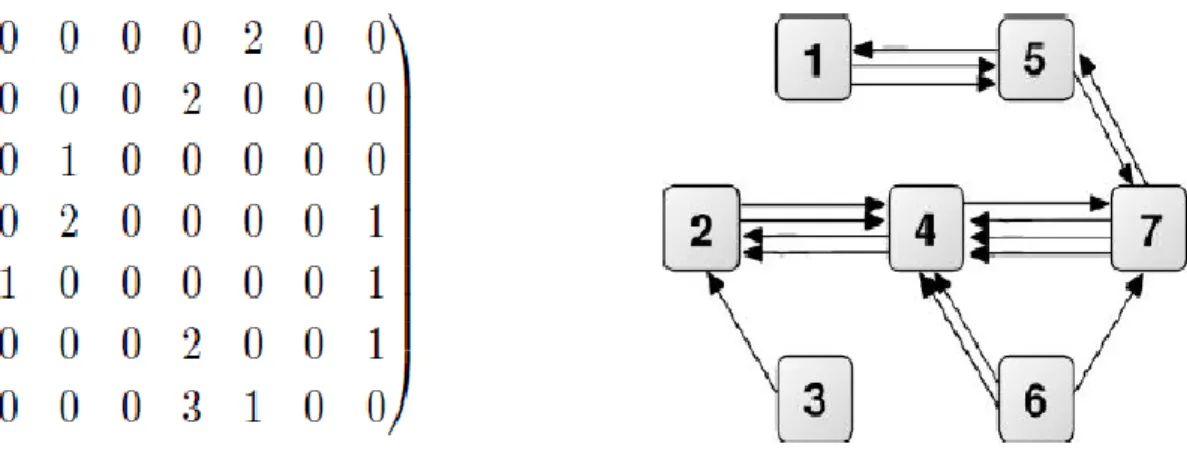
Dans notre exemple, on pourrait quantifier les échanges d’informations. Il existe alors de nombreuses mesures imaginables : le nombre d’e-mails échangés, leur taille (en caractères, en octets), ou encore une estimation de leur contenu informatif par les membres du groupe. On pourra obtenir par exemple :
18
Fig. 1.5 : Exemple de graphe pondéré, orienté et matrice d’adjacence associée. I.3. Graphe et Chaîne de Markov
I.3.1. Chaîne de Markov
Supposons qu’il y ait un système physique ou mathématique à n états possibles tel qu’à n’importe quel moment, le système soit dans un, et seulement un, de ses n états.
Supposons aussi que durant une période d’observation donnée, disons la kème période, la probabilité que le système soit dans un état particulier dépend seulement de son état à la période k−1. Un tel système s'appelle une chaîne de Markov ou un processus de Markov.
Définitions :
Processus stochastique
On s’intéresse à l’évolution d’un phénomène au cours du temps. Cette évolution est aléatoire. On va la représenter par une famille de variables aléatoires. Un processus stochastique (ou aléatoire) est alors : {Xt ; t ∈ T} Où :
Xt est une variable aléatoire, indexée par le paramètre t, qui est un instant. Les variables
aléatoires sont définies sur un espace probabilisé (Ω, Ε, P). D’une façon générale Xt est l’état
du système à l’instant t.
T est un ensemble d’instants. Il peut prendre deux types de valeurs :
fini ou infini mais dénombrable : le temps est alors dit discret,
non dénombrable (T est alors un intervalle de Ρ) : le temps est dit continu.Xt prend donc un certain nombre de valeurs au cours du temps. Ainsi Xt 𝜖 S. L’ensemble S est
l’espace des états, c’est l’ensemble des états possibles du processus. Il peut-être :
discret, c’est-à-dire fini ou infini dénombrable. Le processus est alors appelé une chaîne,
non dénombrable : c’est alors un processus continu. Dans cette thèse, nous allons travailler avec S fini et T discret.
19 Propriété de la chaîne de Markov
Soit une chaîne {Xt ; t ≥ 0} à temps continu (T = [0 ; +∞[ ) définie sur l’espace d’états S. On
dit qu’elle satisfait à la propriété de Markov quand :
∀t > 0 ∀h > 0 ∀n ∈Ν∀t1, t2, …, tn∈ ]0 ; t[ ∀I, s, s1, …, sn∈ S, on a :
P(Xt+h= I | Xt = s et Xt1 = s1 et Xt2 = s2 et … et Xtn = sn) = P(Xt+h= I | Xt = s),
où pour deux évènements A, B ∈ Ε, P(A | B) désigne la probabilité conditionnelle de A sachant B.
Cela traduit le fait que pour connaître l’évolution future du processus, il suffit de connaître la valeur de son état à l’instant présent. Une telle chaîne est dite de Markov ou markovienne. Chaîne de Markov à temps discret
Soit la chaîne {Xn ; n ∈ Ν} à temps discret (T = Ν), Xn∈ S. Elle est dite de Markov quand :
∀n∈Ν, ∀s0, …, sn∈ S, P(Xn = sn | X0 = s0 et ··· et Xn−1= sn−1) = P(Xn = sn | Xn−1= sn−1)
Une chaîne de Markov à temps discret est homogène dans le temps si : ∀n> 0, ∀k ≥ 0, ∀s, σ ∈ S, P(Xn = s | Xn−1 = σ) = P(Xn+k= s | Xn+k−1 = σ)
I.3.2. Lien entre chaîne de Markov et théorie des graphes
Dans le cas d’une chaîne de Markov où l’ensemble E (appelé ensemble des états) est fini, on peut représenter la chaîne sous forme graphique. En effet, les sommets représentent les états de la chaîne et les arrêtes représentent les probabilités de transition. Ainsi, en connaissant la matrice de transition, on peut déterminer le graphe associé à la chaîne.
Exemple : Si on a E = {a, b}, la probabilité de passer de a à b (ou de b à a) est 1/2 et la probabilité de rester en a ou b est aussi 1/2, la matrice de transition sera :
𝑷 = ( 𝟏 𝟐 𝟏 𝟐 𝟏 𝟐 𝟏 𝟐 )
et le graphe associé est :
20
Définition : On dit qu’une chaîne est irréductible si son graphe associé ne possède qu’une composante connexe.
Figure 1.7 : Graphe connexe
On dit que Ti est le temps du premier passage dans l’état i si : Ti = inf{n ≥ 1; Xn = i}.
Le temps moyen de premier retour en i (si on est parti de l’état i) est défini comme Ei(Ti). On dira qu’une chaîne est positivement récurrente si pour tous les états i, on a la propriété suivante Ei(Ti) < ∞.
Une chaîne de Markov irréductible est positivement récurrente si et seulement si elle possède une unique loi stationnaire. Cela signifie que pour une chaîne de Markov, possédant une composante connexe dans son graphe, il y a une loi stationnaire unique.
I.4. Outils mathématiques et physiques
Mathématiquement, un réseau est considéré comme une structure qui représente des interactions entre unités et il est modélisé par un graphe, c’est-à-dire une liste d’unités (ou de nœuds) et un ensemble de liens (ou d’arcs, non orientés dans le cas qui nous intéresse ici) regroupés dans une matrice de connectivité (symétrique ici).
Pour standardiser et mesurer les résultats observés, de nombreux outils algébriques ont donc été empruntés à la théorie des graphes et différents indicateurs de l’état d’un réseau, d’un nœud ou d’un lien en sont sortis. Chacun peut être utilisé sur le réseau entier ou sur un sous ensemble de celui-ci, allant du sous-réseau au nœud simple.
Les indicateurs locaux
La centralité : Elle peut prendre trois formes dans un réseau.
la centralité de degré qui représente l’importance d’un nœud en fonction du nombre de liens qu’il possède avec les autres acteurs. On parlera plus souvent de degré d’un nœud.
la centralité d’intermédiarité mesurée par le nombre de plus court chemin passant par un individu et représentant le fait qu’un individu puisse être incontournable ou non dans un réseau.
la centralité de proximité qui est la distance moyenne entre un individu et les autres individus.
21
Le plus court chemin : Le plus court chemin représente la distance la plus courte pour relier deux nœuds.
Les indicateurs globaux
Le coefficient de clusterisation : Le coefficient de clusterisation est une mesure permettant de représenter le fait que deux nœuds voisins d’un troisième nœud soient voisins ou non entre eux. Le coefficient global se calcule ainsi : C = (nb triplets fermes/nb triplets).
Dans cette équation, un triplet représente un ensemble de trois nœuds connectés par deux liens, et un triplet fermé représente trois nœuds connectés par trois liens.
La cohésion : La cohésion permet de mettre en évidence les liens directs entre chaque individu d’un même réseau. Si chaque individu est relié à chacun des autres individus, on parlera alors d’une clique.
La densité : La densité d’un réseau est mesurée par le nombre de liens existants par rapport au nombre total de liens possibles. Si ce rapport est égal à 1, aucun autre lien ne peut être créé et on aura alors un graphe complet.
Le diamètre : Le diamètre d’un réseau est le plus long des plus courts chemins présents. Le chemin moyen : Le chemin moyen est la distance moyenne entre tous les nœuds d’un réseau. C’est en fait la moyenne de tous les plus courts chemins du graphe.
La distribution de degré : La distribution d’un graphe est la courbe représentant le nombre de nœuds de chaque degré possible au sein du graphe. Nous verrons que cette distribution constitue une signature de la topologie du graphe considéré.
Les indicateurs locaux et globaux
La centralisation : La centralisation d’un nœud se mesure par le nombre de liens divisé par la somme de tous les liens du réseau. Un nœud central possède un nombre de liens beaucoup plus important que les autres. La centralisation est à associer à la centralité de degré.
Par extension, un réseau fortement centralisé sera alors composé de quelques nœuds principaux, appelés hubs, auxquels seront rattachés la majorité des autres nœuds.
II. Types de réseaux
Les modèles de réseaux permettent plus simplement de donner une topologie, de distinguer et de qualifier différents types de réseaux.
Ils servent également pour la représentation des systèmes complexes lorsque les processus dynamiques étudiés reposent sur les interactions entre un grand nombre d'éléments distincts. De récents progrès ont été réalisés dans l'étude des systèmes complexes, qui sont présents dans de nombreux domaines : biologie, sociologie, psychologie, informatique,... .Ils recouvrent ainsi le World Wide Web [72], l’internet [73], les réseaux de communication, d'énergie [74] et de transport [75], les interactions sociales [76] ou interactions entre protéine [77].
Sachant qu’il existe un continuum entre ces types, qui sont déterminés à partir de mesures statistiques, un réseau donné va plus ou moins se rapprocher de certains de ces types de réseaux.
22
Ces modèles de réseaux sont également intéressants, car ils sont en général associés à des modèles de génération de graphes (pour produire de tels réseaux), qui peuvent être un point de comparaison avec les réseaux.
Nous citons ci-dessous les types principaux de réseaux :
•
Des réseaux réguliers : Ils correspondent, à des réseaux dont le degré de connectivité est constant et les connexions déterministes. Il s’agit le plus souvent de réseaux réguliers avec des voisins topologiques (exemple : une grille), donc avec un fort coefficient de clustering, mais de très courts chemins (à cause de l’absence de connexions à longue distance).•
Des réseaux aléatoires non corrélés : Ils sont des réseaux sans aucune organisation, dont le degré de connectivité est décrit par une variable aléatoire. On génère ce type de réseaux en spécifiant simplement le nombre total de nœuds et une probabilité de connexion entre nœuds. Il faut souligner que, malgré le hasard qui semble régné dans de tels réseaux, il existe des résultats mathématiques intéressants [78] qui y sont associés. On peut par exemple montrer qu’un réseau aléatoire est presque surement connecté quand sa probabilité de connexion est très grande devant log(N)/N. On peut également montrer que le plus court chemin est fonction de log(N)/log(pN) avec p la densité de connexion.•
Des réseaux petit monde (small world) : Ils sont des réseaux aléatoires dont le plus court chemin moyen est faible mais dont le coefficient de clustering est élevé [79]. Ils se rapprochent donc des réseaux aléatoires et des réseaux réguliers et profitent des propriétés des deux. On peut également le voir comme un réseau régulier auquel on a ajouté des liens de façon aléatoire, incluant des liens à longue distance et faisant donc chuter le plus court chemin tout en gardant un fort coefficient de clustering local. Le plus court chemin est donc réduit à la fois localement et sur de grandes distances, à un coût réduit en termes de connectivité. Cela permet de faire des calculs complexes localement et de propager facilement l’information à tout le réseau. Il n’est donc pas surprenant qu’une telle structure, efficace localement et globalement, se retrouve dans de nombreux réseaux, comme dans le système nerveux ou dans le réseau électrique.•
Des réseaux sans échelle (scale-free) : Ce sont des réseaux aléatoires dont la distribution de connectivité obéit à une loi de puissance [80]. C’est-à-dire que si on range les nœuds en fonction de leur degré de connectivité, le nombre de nœuds de degré k est proportionnel à k-p,avec p généralement compris entre 2 et 3. Ceci veut donc dire que des nœuds à très forte connectivité sont rares mais qu’ils existent. Ces réseaux vont donc être caractérisés par la présence de tels nœuds très fortement connectés, que l’on appelle des hubs. On retrouve typiquement de tels réseaux sur le web ou dans les réseaux sociaux, où la présence de hubs est expliquée par la règle d’attachement préférentiel (on a tendance à se connecter à des nœuds déjà très connectés). Concernant les propriétés de tels réseaux, le coefficient de clustering décroît (en suivant aussi une loi de puissance) quand le degré de connectivité croît. Ce qui permet de voir de tels réseaux comme des sous-graphes connectés entre eux par des hubs. Grâce à la présence de ces hubs, le plus court chemin est également réduit dans les réseaux scale-free. On peut montrer que le diamètre d’un réseau petit monde est proportionnel à log(N) et celui d’un réseau scale-free à log(log(N)). Une autre propriété notable de ces réseaux est leur robustesse face à la
23
destruction (aléatoire) de nœuds, car les hubs, essentiels à la communication, sont peu nombreux. Par contre, une attaque dirigée vers les hubs peut rapidement anéantir un tel réseau (dans un réseau aléatoire, une attaque dirigée ou pas aura les mêmes effets).
III.
Routage
Définition
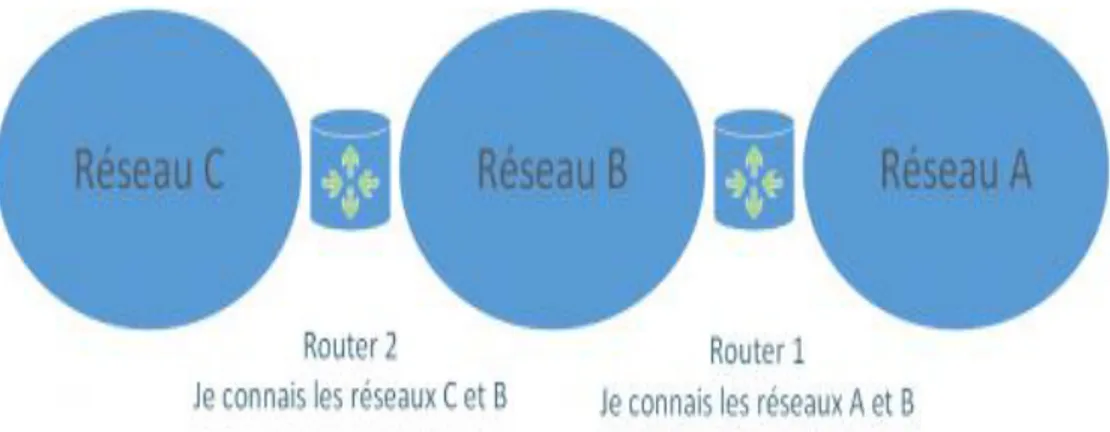
Internet n’est qu’un immense réseau de liens et d’interconnexions entre plusieurs réseaux. Pour savoir le chemin à emprunter, parmi tous ces liens, pour aller d’un réseau A à un réseau B, il faut qu’un protocole de routage ait été mis en place.
Le but du routage est de définir une route ou un chemin à un paquet, quand celui-ci arrive sur un routeur.
Le but du routage est donc d’assurer qu’il existe toujours un chemin pour aller d’un réseau à un autre.
Figure 1.8 : les réseaux liés via des routeurs
On voit dans la figure1.8 trois réseaux séparés entre eux par un routeur. Chaque poste de chaque réseau contient dans sa configuration l’IP d’une passerelle qui constitue l’élément vers lequel les postes vont envoyer des paquets. Le rôle de la passerelle (passerelle = routeur) est donc de transmettre ce ou ces paquets à leurs destinataires.
Le routeur 2 connait ici les réseaux C et B mais ne connait pas le réseau A. C’est ici que le routage intervient.
Le routage sert en effet à indiquer au routeur 2 par quel chemin il doit passer pour joindre un réseau auquel il n’est pas directement connecté.
24
Figure 1.9 : Quatre routeurs lient quatre réseaux différents
On voit dans la figure 1.9 que pour aller du réseau B au réseau A, il existe deux chemins possible.
Le routage a pour rôle de déterminer une route (normalement, la meilleure) pour communiquer d’un réseau vers un autre, quand il en existe plusieurs possibles.
III.1. Modes de routage
Il existe deux modes de routage bien distincts, lorsque nous souhaitons aborder la mise en place d’un protocole de routage.
Il s’agit du routage statique et du routage dynamique. III.1.1. Routage statique
Dans le routage statique, les administrateurs vont configurer les routeurs un à un au sein du réseau afin d’y saisir les routes (par l’intermédiaire du port de sortie ou d’IP de destination) à emprunter pour aller sur tel ou tel réseau.
Concrètement, un routeur sera un pont entre deux réseaux et le routeur suivant sera un autre pont entre deux autres réseaux :
25
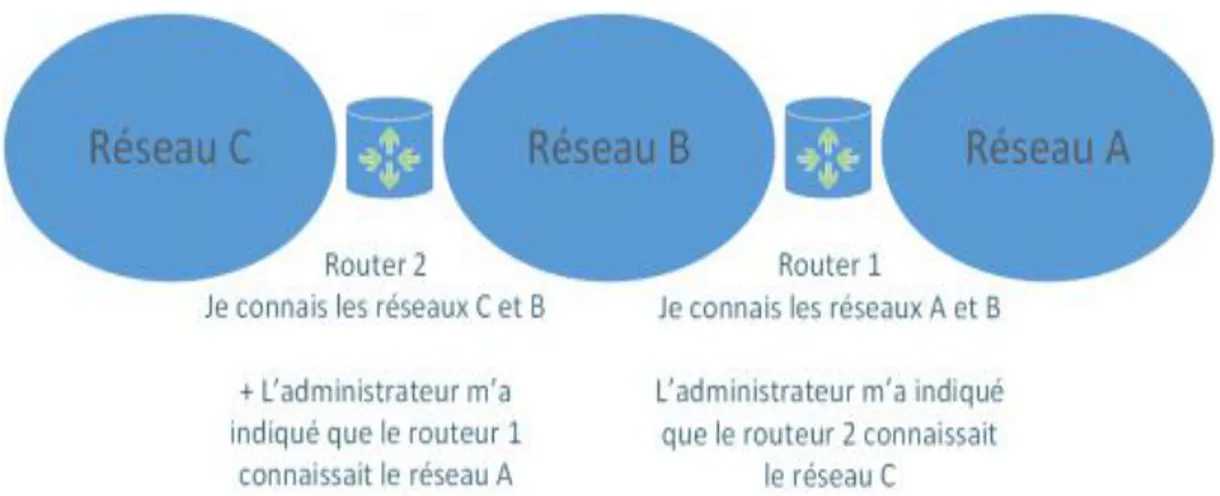
Dans la figure 1.10, l’administrateur a indiqué au routeur 2 que le réseau A pouvait être joint à travers le routeur 1 qu’il connait puisqu’il se situe sur le même réseau (B) que lui.
Le routage statique permet donc à l’administrateur de saisir manuellement les routes sur les routeurs et ainsi de choisir lui-même le chemin qui lui semble le meilleur pour aller d’un réseau A à un réseau B.
Par exemple, si un nouveau réseau vient de se créer sur le routeur 1, il faudra indiquer au routeur 2 qu’il faut à nouveau passer par le routeur 1 pour aller sur le réseau D.
Le routage statique présente plusieurs avantages, à savoir :
Économie de la bande passante : Étant donné qu’aucune information ne transite entre les routeurs pour qu’ils se tiennent à jour, la bande passante n’est pas encombrée avec des messages d’informations et de routage.
Sécurité : Contrairement aux protocoles de routage dynamique qu’on va voir plus bas, le routage statique ne diffuse pas d’informations sur le réseau puisque les informations de routage sont directement saisies de manière définitive dans la configuration par l’administrateur.
Connaissance du chemin à l’avance : L’administrateur ayant configuré l’ensemble de la topologie saura exactement par où passent les paquets pour aller d’un réseau à un autre. Cela peut donc faciliter la compréhension d’un incident sur le réseau lors des transmissions de paquets.
Mais aussi des inconvénients :
La configuration de réseaux de taille importante peut devenir assez longue et complexe. Il faut en effet connaitre l’intégralité de la topologie pour saisir les informations de manière exhaustive et correcte pour que les réseaux communiquent entre eux. Cela peut devenir une source d’erreur et de complexité supplémentaire quand la taille du réseau grandit.
A chaque fois que le réseau évolue, il faut que chaque routeur soit au courant de l’évolution par une mise à jour manuelle de la part de l’administrateur, qui doit modifier les routes selon l’évolution.
On voit donc que le routage statique peut être intéressant pour de petits réseaux de quelques routeurs n’évoluant pas souvent.
En revanche, pour des réseaux à forte évolution ou pour les réseaux de grande taille, le routage statique peut devenir complexe et long à maintenir.
III.1.2. Routage dynamique
Le routage dynamique permet quant à lui de se mettre à jour de façon automatique.
La définition d’un protocole de routage va permettre au routeur de se comprendre et d’échanger des informations de façon périodique ou événementielle afin que chaque routeur soit au courant des évolutions du réseau sans intervention manuelle de l’administrateur du réseau.
Concrètement, le protocole de routage fixe la façon dont les routeurs vont communiquer mais également la façon dont ils vont calculer les meilleures routes à emprunter.
26
On verra un peu plus bas qu’il existe pour cela deux méthodes, mais avant, voici un schéma qui illustre le routage dynamique :
Figure 1.11 : Routage dynamique
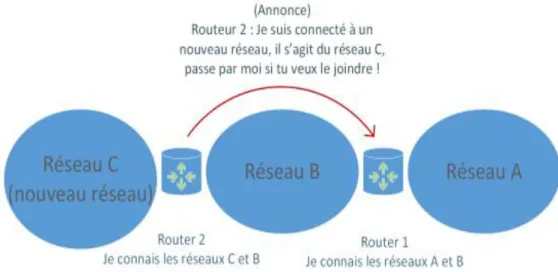
On voit dans la figure 1.11 que dans un premier temps, on ajoute le réseau C au routeur 2 (on le connecte à l’interface du routeur 2).
Une annonce va ensuite suivre pour que les autres routeurs sachent que le réseau C est joignable via le routeur 2. Par la suite, les routeurs continueront à communiquer périodiquement pour voir si chacun des routeurs est toujours joignable.
Si un routeur tombe en panne et qu’une autre route existe pour accéder à un réseau, les tables de routage des routeurs vont se modifier dynamiquement via des communications faites entre les routeurs et vont réaliser le calcul de la meilleure route possible à emprunter. Cela facilite la transmission des informations entre les routeurs et la mise à jour des topologies réseaux. On doit bien sûr pour cela définir la façon dont ils vont communiquer et calculer les routes (le protocole de routage qu’ils doivent utiliser). Ils pourront ensuite se comprendre par l’échange de messages de mise à jour, des messages “hello” (indiquant que l’hôte est toujours joignable), des requêtes et des réponses diverses et différentes selon le protocole de routage.
Il est important de savoir que certains protocoles de routage calculent les routes en fonction de la vitesse des liens les liants, d’autres en fonction du nombre de routeurs à passer avant d’atteindre notre destination (saut), etc.
Le routage dynamique présente les avantages suivants :
Une maintenance réduite par l’automatisation des échanges et des décisions de routage.
Une modularité et une flexibilité accrues. Il est plus facile de faire évoluer le réseau avec un autre réseau qui se met à jour automatiquement.
Sa performance et sa mise en place ne dépendent pas de la taille du réseau. Mais aussi des inconvénients :
27
Il consomme de la bande passante par les messages que les routeurs s’envoient périodiquement sur le réseau
La diffusion automatique de messages sur le réseau peut constituer un problème de sécurité, car un attaquant peut obtenir des informations sur la topologie du réseau simplement en écoutant et en lisant les messages d’informations du protocole de routage et même en les créant afin de se faire passer pour un membre du réseau.
Le traitement des messages réseau et le calcul des meilleures routes à emprunter représentent une consommation supplémentaire de CPU et de RAM, qui peut encombrer certains éléments du réseau peu robuste.
L'objectif du routage est de déterminer une route (i.e. un ensemble de liens à parcourir), respectant certaines contraintes, pour établir une connexion d'un nœud source vers un nœud destinataire. Le but d'un algorithme de routage est de permettre le calcul de la route entre ces deux nœuds au sens d'un certain critère, et la diffusion des informations nécessaires à ce calcul.
III.2. Algorithme de routage
Un algorithme de routage détermine l'ensemble des liens qui constituent la route à parcourir, pour établir une connexion entre un nœud source et un nœud destinataire. Il permet de recueillir les informations nécessaires pour calculer la route entre ces deux nœuds, tout en respectant certaines contraintes.
Pour choisir un algorithme de routage, il faut tenir compte des contraintes matérielles de l'environnement. Il faut, pour chaque paramètre constituant la stratégie de l'algorithme, le choisir parmi les possibilités qui sont offertes.
La classification, ci-dessous, des algorithmes montre qu'il y a trois principaux choix à faire. Cette partie explique le fonctionnement de chaque famille d'algorithme, et évoque les variantes possibles.
III.2.1. Routage fixe et routage adaptatif Routage fixe
La méthode du routage fixe définit les chemins que les différents paquets doivent suivre à partir des caractéristiques générales du réseau, tels que la topologie et le trafic moyen escompté sur les différents canaux de transmission.
Les règles d'acheminement sont en principe établies une fois pour toute et visent à privilégier un critère de performance choisi par le concepteur.
Dans la plupart des cas, l'optimisation du réseau vise à minimiser le temps moyen de la traversée par les paquets.
La méthode du routage fixe se traduit au niveau de chaque nœud par une table de routage dont la consultation permet au nœud de déterminer sur quelle voie de sortie, il doit transmettre un paquet qu'il vient de recevoir, afin de l'acheminer dans les meilleures conditions possibles vers sa destination.
28
La méthode du routage fixe est donc simple dans son principe, puisque le seul traitement effectué au niveau des nœuds se résume à la gestion des files d'attentes des voies et à des consultations de tables.
Par conséquent, l'algorithme d'optimisation des chemins n'est mis en œuvre qu'au moment de la conception du réseau.
En pratique, les tables de routage ne peuvent pas être complètement fixes, car la topologie du réseau peut changer par d’éventuelle défaillance d'équipements ou à cause de l'introduction de nouveaux utilisateurs.
Le routage fixe est donc une méthode où les tables de routage ne sont que rarement remise à jour, par opposition au routage adaptatif, avec lequel les tables de routage sont corrigées en permanence, en fonction par exemple de l'état instantané du trafic.
On voit que la méthode de routage fixe vise une optimisation globale à long terme, alors que la méthode adaptative a pour ambition de satisfaire à tout instant à un ou plusieurs critères d'optimalité.
Exemple de table de routage fixe :
Table de routage du nœud C :
Adresse destination Adresse du prochain nœud
A A B D C - D D E E F F G A H A I F J F
29 Routage adaptatif
Bien que le routage fixe soit plus simple à se mettre en œuvre et à se valider, dans un souci d'efficacité, on s'oriente de plus en plus vers des méthodes de routage adaptatif.
Le routage adaptatif est une solution nécessitant la mise à jour régulière des tables de routage en fonction des changements de la topologie ou de la charge du réseau.
Par la suite, on s’intéressera exclusivement au routage adaptatif. Il est entendu que certaines des définitions, qui seront données, peuvent s'appliquer au routage fixe.
III.2.2. Sélection de la route Routage Aléatoire
Les principes de routage par inondation sont difficilement classifiables car ils ne tiennent pas compte des caractéristiques du réseau pour effectuer le routage.
Acheminement par inondation
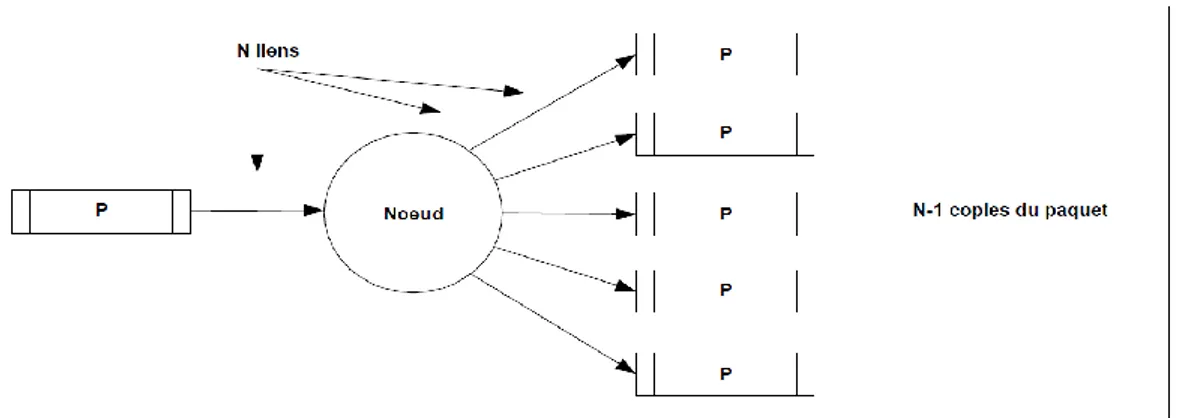
La technique d'acheminement par inondation (Flooding) est basée sur un principe simple consistant pour chaque nœud à retransmettre le paquet reçu sur toutes les voies de sortie du nœud, à l'exception de la voie d'arrivée.
Un nœud connecté à N nœuds retransmet donc N-1 répliques du paquet qu'il vient de recevoir. Principe du Flooding :
Figure 1.12 : Principe de flooding
On voit dans la figure 1.12 que la méthode par inondation assure l'arrivée d'au moins une copie du paquet au destinataire, pourvu qu'il existe au moins un chemin entre celui-ci et la source du paquet. Cette garantie d'acheminement est assurée même si la topologie change, à la suite par exemple d'une défaillance de certains composants du réseau.
La méthode par inondation permet donc une grande robustesse dans l'exploitation du réseau, ce qui explique que ses applications principales soient du domaine militaire.
D'autre part, comme toutes les liaisons possibles, entre le nœud d'origine et le nœud destinataire, les liaisons sont essayées de façon exhaustive.
30
La méthode précitée assure qu'au moins une des répliques du paquet atteindra le destinataire par le chemin le plus court, et donc avec un délai minimum, si le réseau est peu chargé. La technique par inondation présente également l'avantage d'être très simple à implanter, puisque l'acheminement des messages ne nécessite ni tables de routage ni même de connaître la position géographique du destinataire dans le réseau.
En effet, pour que le paquet parvienne à son destinataire, il suffit simplement que celui-ci soit capable de reconnaître que le message lui est adressé.
Le prix à payer pour ses qualités de simplicité, de robustesse, et de rapidité d'acheminement est évidemment une mauvaise utilisation des ressources du réseau et une tendance marquée à la congestion.
En effet, puisque chaque nœud produit en général plusieurs répliques du même paquet, le nombre total des répliques en transit dans le réseau croit très rapidement en fonction du nombre de nœuds traversés. Cela explique pourquoi, en dehors de quelques cas particuliers, cette technique est peu employée. Néanmoins, ce principe peut être utilisé de manière efficace pour la transmission de routage dans le cas de certaines techniques adaptatives.
Acheminement aléatoire
La technique de l'acheminement aléatoire (Random Routing, Stochastic Routing) partage avec la méthode de l'inondation la caractéristique de ne pas nécessiter que les nœuds connaissent la structure du réseau ou l'état du trafic pour prendre la décision du routage à leur niveau. Toutefois, les nœuds évitent ici d'envoyer systématiquement sur toutes les voies de sortie des répliques de paquets qu'ils reçoivent, et ce afin de ne pas produire un trafic fantôme trop important.
La méthode de routage aléatoire consiste à émettre une ou plusieurs répliques du paquet reçu sur des voies de sortie qui sont choisies soit au hasard, soit en fonction d'une information sur la direction générale suivie par le paquet.
Dans ce dernier cas, la méthode de routage est appelé inondation sélective (Selective Flooding). Avec la méthode d'acheminement aléatoire la plus simple, chaque nœud retransmet le paquet reçu sur l'une des voies de sortie choisie au hasard.
Avec un réseau convenablement maillé, le paquet finit toujours par arriver au destinataire, même si le chemin qu'il doit suivre est compliqué.
On voit que cette technique conduit à une réalisation très simple au niveau des nœuds, et qu'elle évite la saturation causée par la duplication des paquets.
En contrepartie de ces avantages, le délai d'acheminement est en moyenne plus long qu'avec des techniques déterministes classiques, puisque les paquets suivent en général des routes tortueuses au lieu de prendre le chemin le plus direct vers la destination.
31 Nœud après nœud
Le routage nœud après nœud (Hop by Hop) consiste à ne donner que l'adresse du prochain nœud pour accéder au destinataire. Le résultat d'une table de routage reposant sur ce principe est donné pour le routage fixe.
Ainsi, à chaque nœud, l'algorithme renvoie l'adresse permettant de se rapprocher du destinataire. Cette méthode est particulièrement adaptée aux protocoles basés sur le mode non connecté.
Routage de source
Le routage de source est la détermination complète de la route par la source. En effet, le premier commutateur décide de prendre l'ensemble des nœuds pour accéder au destinataire. Pour permettre ce calcul, le nœud doit posséder les caractéristiques et la topologie de l'ensemble du réseau.
Cette méthode est particulièrement utile pour les réseaux à haut débit ou l'on souhaite offrir un maximum de connections par unité de temps.
Dans ces conditions, il ne faut pas que les performances soient détériorées par un temps de calcul de route trop long.
Pour que ce routage soit efficace, il est indispensable que les données sur le réseau soient parfaitement à jour. Pour cette raison, cette technique est plutôt réservée au routage adaptatif qu'au routage fixe.
Table de routage du nœud C :
Adresse destination Adresse du prochain nœud
A A B D, B C - D D E E F F G A, G H A, G, H I F, I J F, I, J
32
Pour des réseaux de tailles raisonnables (typiquement quelques centaines de nœuds), on préfèrera le routage de source, car il est plus rapide. Le calcul de la route n'est effectué qu'une seule fois. Pour les autres réseaux, on choisira un routage adaptatif, nœud par nœud, pour ne pas surcharger en mémoire et en temps de calcul les nœuds du réseau.
Même si la contrainte prioritaire reste la taille du réseau, ce type de choix est aussi souvent lié au protocole utilisé qui impose des contraintes de mise en œuvre trop importantes.
On choisira, par exemple, plus facilement un routage nœud par nœud sur Internet. En effet, la taille maximale des paquets étant fixe.
Effectuer un routage de source, c’est imposer à l'algorithme de faire de l'assemblage/désassemblage de données.
Routage centralisé
Avec un routage centralisé, c'est un nœud qui possède toutes les informations sur l'état du réseau. Ce nœud est donc en mesure de calculer, à chaque instant, le chemin optimal entre deux nœuds.
Ainsi tout nœud source, désirant établir une connexion, doit s'adresser au nœud "principal". Ce qui augmente le temps pour calculer une route.
De plus, il existe un important problème de fiabilité. En effet, si ce nœud de routage venait d’être hors service, ou si un des liens, le reliant au reste du réseau, était coupé, il y aurait alors un impact sur le bon fonctionnement du réseau.
Routage local
Les méthodes de routage local et de routage réparti sont toutes deux basées sur l'établissement par chaque nœud de sa propre table de routage en fonction des informations qu'il peut glaner localement.
![Figure 1.1 : La rivière Pregel et l'île de Kneiphof [69]](https://thumb-eu.123doks.com/thumbv2/123doknet/2195219.11926/14.893.227.709.660.923/figure-la-riviere-pregel-et-ile-de-kneiphof.webp)