Reinforcement-Learning Approach Guidelines for Energy Management
Texte intégral
Figure

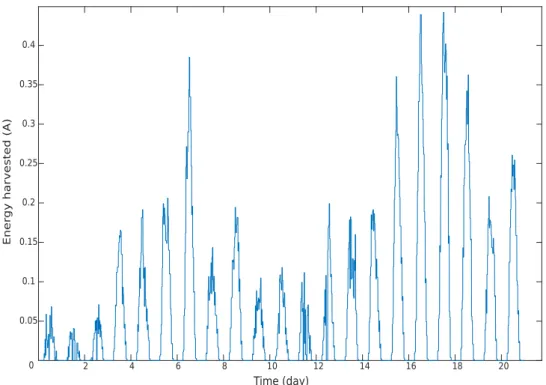
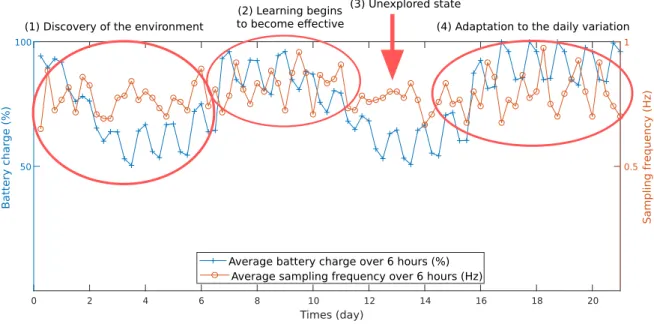
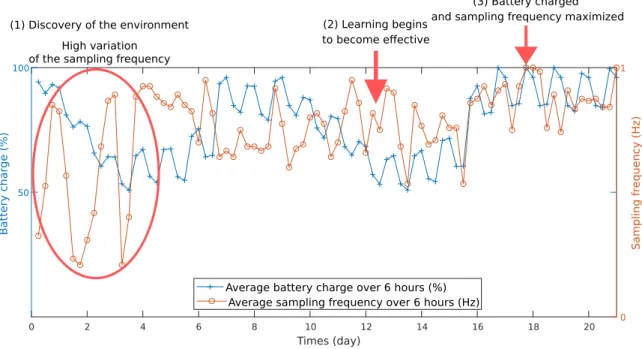
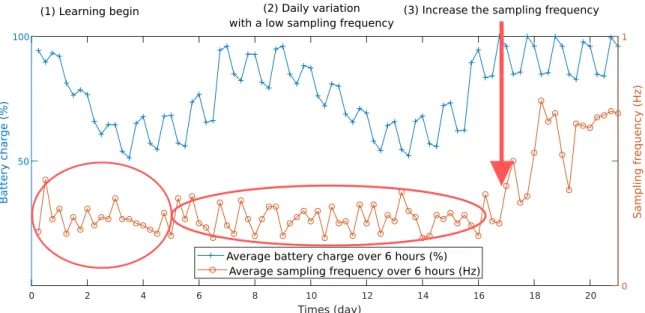
Documents relatifs
Overall, it was shown that the use of interactive machine learning techniques such as interactive deep reinforcement learning provide exciting new directions for research and have
Indeed, the proposed solution, named EDDPG, not only improves the exploration mechanism sug- gested for the Deep Deterministic Policy Gradients (DDPG) technique [6], it allows,
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
L’accès à ce site Web et l’utilisation de son contenu sont assujettis aux conditions présentées dans le site LISEZ CES CONDITIONS ATTENTIVEMENT AVANT D’UTILISER CE SITE WEB.
This leader detection is obtained while using a heuristic method that exploits the range data from the group of cooperative robots to obtain the parameters of an ellipse [25].
The resulting value is computed numerically and provides us for each feature a feature importance. We rank these features impor- tance and assign arbitrarily the value 100 to
Magnetization versus magnetic field for mixed cobalt-iron oxalate at room temperature (full diamonds) and for the oxides resulting from the selective laser decomposition at
Reward functions (R1) and (R2) increase the node’s con- sumption when the harvested energy increases whereas reward function (R4) increases the node’s consumption when it har- vests
