On the Value of Improved Informativeness
Texte intégral
Figure
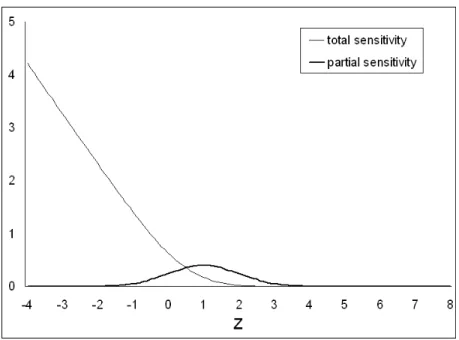
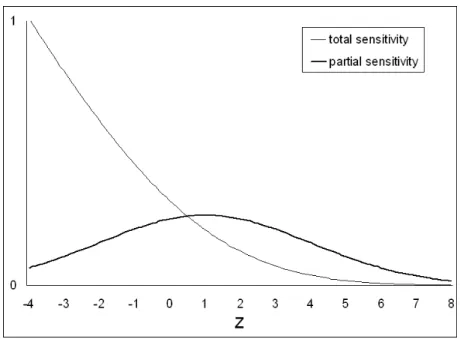
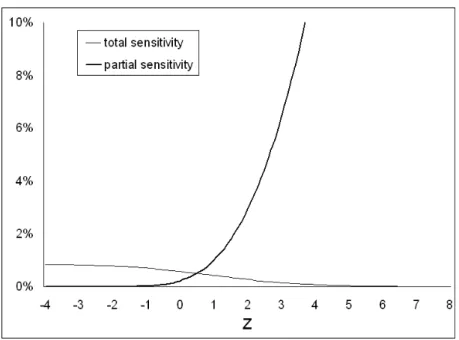
Documents relatifs
The most interesting result is perhaps that every separable non-atomic Banach lattice, such that the dual space has a weak order unit, can be represented by
Each one of the three definitions contains an auxiliary function which is continuous and mono- tonic.. These set functions are used for classifying noncountable
b) En déduire la nature du triangle OMN.. 5) Montrer que ces deux suites sont adjacentes. c) Montrer que f réalise une bijection de IR sur un intervalle J que
Cette formation vous permet de développer vos compétences et les participants aborderont les concepts portant sur les déclarations de modification de
[r]
[r]
For p > 5 and p / ∈ 2 N , the push- forward of the uniform measure on p-angulations (or indeed of any regular critical Boltzmann distribution on maps) by the
According to the values found at the preceding question, discuss and decide (if possible) on the nature of the critical points (extremum, saddle points ?).. Write the expression of
