Learning probabilistic relational models with (partially structured) graph databases
Texte intégral
Figure
![Fig. 1. Example of an ER diagram (inspired from [8]).](https://thumb-eu.123doks.com/thumbv2/123doknet/12201784.316066/3.918.141.387.82.294/fig-example-er-diagram-inspired.webp)
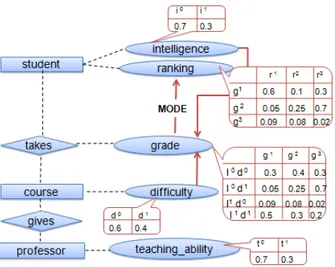

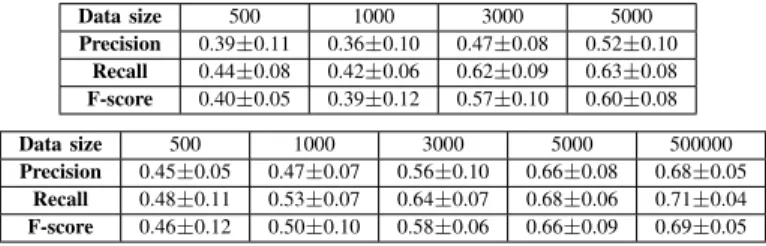

Documents relatifs
The query semantics of our sequenced TP data model is based on an intriguing analogy between the temporal and probabilistic semantics: rather than iterating over snapshots or
We plan to design al- gorithms which intervene in the first phase of the process of cross-model data exchange, where, given some examples from the source database, the algorithms
Given a graph and a goal query, we start with an empty sample and we continuously select a node that we ask the user to label, until the learned query selects exactly the same set
We first introduce the notion of λ-K¨ onig relational graph model (Definition 6.5), and show that a relational graph model D is extensional and λ-K¨ onig exactly when the
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
In this section, we will give some properties of these Green functions that we will need later. The proof of the following lemma is based on elementary potential theory on the
We gave an overview of a provenance-based framework for routing queries, and of di↵erent approaches considered to lower the complexity of query evaluation: considering the shape of
We propose to use a metagraph data model that allows storing more complex relationships than a flat graph or hypergraph data models.. This paper is devoted to methods of storage of
