Bootstrapping factor models with cross sectional dependence
Texte intégral
Figure
Documents relatifs
In[17, 18], the existence and uniqueness of solutions were investigated for a nonlinear fractional differential equation with three‐point boundary conditions by using a Schauder’s
La crise financière mondiale mène à une baisse du volume des flux financiers, qui touche particulièrement certains pays émergents pour lesquels les investisseurs
Les estimés ponctuels de même que les intervalles de confiance pour les covariables sont si- milaires aux estimés obtenus en utilisant le modèle de Cox sans ajustement pour le
Dans la présente recherche, le terme récidive sexuelle est défini comme étant toutes nouvelles condamnations de nature sexuelle inscrite à la fiche criminelle de l’individu (fiche
Furthermore, Groh and her colleagues (2014) found in a sample of 825 participants modest but significant association between disorganized attachment at fifteen
Toutefois, on obtient des résultats semblables avec la dérivée partielle ci-dessus pour les différents types de variables (Liao, 1994). Le fait que la variable sexe soit
Mais depuis 1975, la formation brute de capital fixe (FBCF) connaît en agriculture, un retournement de tendance prononcé, et plus encore pour le matériel que pour les bâtiments..
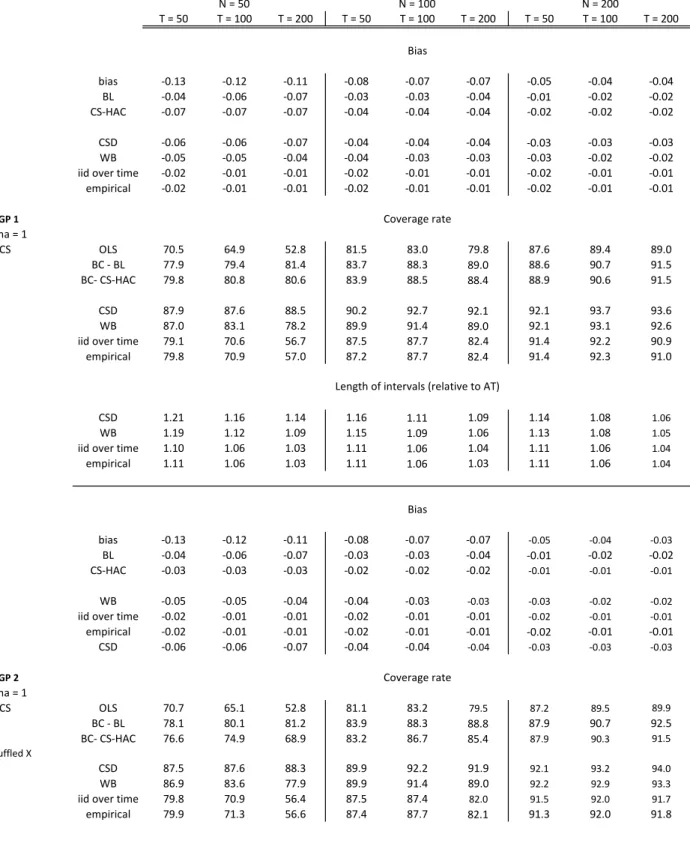
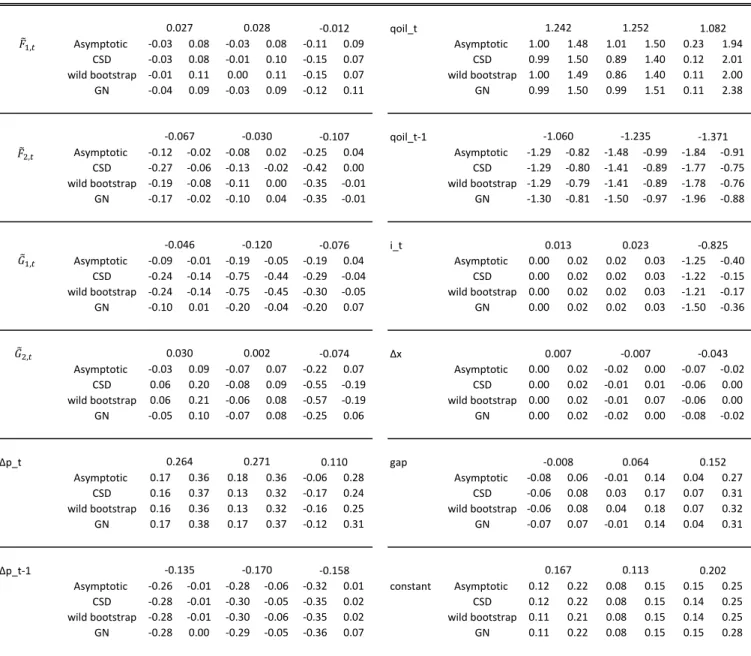
The power of tests based on symmetric and equal-tail bootstrap P values against certain alternatives may be quite different, as is shown in Section 8... these tests may have
