HAL Id: hal-01431077
https://hal.archives-ouvertes.fr/hal-01431077
Submitted on 10 Jan 2017HAL is a multi-disciplinary open access
archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés.
Projet de base de données textuelles pour l’Institut de la
Langue Française
Étienne Brunet
To cite this version:
Étienne Brunet. Projet de base de données textuelles pour l’Institut de la Langue Française. bases de données dans les humanités et les sciences sociales, Jun 1980, Madrid, Espagne. �hal-01431077�
Etienne Brunet
Projet de base de données textuelles
pour l’Institut de la Langue Française
Résumé
L'exploitation systématique de l'immense corpus du Trésor de la langue française, gros de 70 millions d'occurrences, a fait l'objet d'une Table Ronde à l'Institut de la langue française (27-29 mai 1980, Nancy). On rend compte ici des critiques et des propositions qui furent faites alors, et particulièrement d'un projet de création d'une base de données textuelles, applicable au corpus littéraire du XIXe et du XXe siècle. En constituant un fichier des lignes et un fichier inverse des mots, l'un et l'autre d'un demi-milliard de caractères, et en recourant à quelques fichiers annexes (de lemmatisation et de statistique), on disposerait d'une base de données, qu'un langage simple d'interrogation conversationnelle mettrait à la disposition de la communauté scientifique. Des index, des concordances et des statistiques de types variés seraient livrés au consultant, dont le choix pourrait s'exercer sur les formes, les vocables, les constituants du mot, les catégories grammaticales, les homographes, les cooccurrences, le vocabulaire significatif, la recherche pouvant en chaque cas être limitée à un texte ou sous-texte, à un auteur, à un genre littéraire ou à une époque particulière.
SUMMARY
A symposium was held at the Institut de la Langue Française (I.L.F.) in Nancy, France (27-29 mai May, 1980). It was devoted to the systematic exploitation of the huge corpus of the "Tresor de la Langue Française" (T.L.F.) which contains 70 million word-tokens.
This is an account of the criticisms and proposals that were then made, with special emphasis on a plan for creating a textual data base concerning the literary corpus of the 19 th and 20 th centuries. This would imply the creation of a line file and a reverse word order file both of half a milliard characters, and the use of a few auxiliary files (for lemmatization and statistics),and would provide a data base that a simple conversational interrogation language would make available to the community of scholars. Indexes, concordances and statistics of various description could be supplied to the user who would be free to direct his attention to word-forms, word-types, morphemes, parts of speech, homographs, collocations or significant vocabulary at will. In each case the field of investigation could be restricted to a single text or sub-text, to a single author, a whole literary genre or a particular period..
Lors de la première conférence sur les bases de données dans les humanités qui s'est tenue en août dernier en Amérique, j'ai eu l'occasion d'évoquer et même de détailler les trésors qui gisent à Nancy au sein de l'Institut de la Langue Française. Faut-il rappeler ici qu'au bout de quinze ans de capitalisation, les données textuelles qui y ont été amassées représentent actuellement 140 millions de mots, soit une bibliothèque de 2000 volumes sur support magnétique, ou si l'on veut un seul gros volume qui aurait 500 000 pages. De ces données la moitié a été exploitée à des fins lexicographiques, l'objectif premier étant de réaliser un dictionnaire de la langue contemporaine, le Trésor de la Langue Française, dont on prévoit l'achèvement aux environs de 1987 (la rédaction actuellement a parcouru la moitié de l'alphabet).
Les données exploitées concernent uniquement le corpus du XIX-XXe siècle. Quant aux textes antérieurs, principalement ceux du XVIIe et du XVllle, leur enregistrement (non achevé) se justifie par des objectifs plus lointains qui peuvent être la rédaction de nouveaux dictionnaires représentatifs de la langue classique, ou de la langue du XVIe siècle, ou la constitution d'un dictionnaire électronique qu'on pourrait consulter à l'aide d'un terminal et qui éviterait les écueils où tombent les dictionnaires traditionnels : l'encombrement de la masse totale mais aussi l'exiguïté de chaque article, le coût et la lenteur de l'impression, de la diffusion et de la consultation, et surtout le vice originel de toutes ces entreprises lexicographiques qui meurent le jour même où elles naissent, car la mise à jour y est impossible, sinon sous la forme incommode de suppléments. L'idée qui semble prévaloir à l'Institut de la Langue Française est qu'il faut s'orienter vers cette deuxième réalisation qui s'apparente directement à l'objet de ce colloque puisqu'il s'agirait d'une base de données lexicographiques.
I - LA TABLE RONDE DE NANCY (27-29 Mai 1980) sur les bases de données textuelles -
1 - Ce n'est pourtant pas de ce type de base de données que je veux parler aujourd'hui mais d'un sujet plus actuel puis qu'il vient de faire l'objet d'une Table Ronde de trois jours à Nancy, où les participants avaient été conviés à réfléchir aux problèmes d'une base de données textuelles. Je retrouve ici plusieurs des 45 participants invités à cette Table Ronde, dont la plupart venaient de l'extérieur de l'ILF. Car en voulant créer cette base de données textuelles on avait le souci d'ouvrir le Trésor à l’ensemble de
l a comm unaut é s ci ent i fi que et cet t e com m unaut é devait d'abo rd êt r e e nt end u e.
Il f a u t b i en a v ou e r q u e c et t e co m m u na u t é fi t e nt e nd r e quel ques crit i ques , et , com m e cel a arri ve, l es cri t i ques ét ai ent s ouvent cont ra di ct oi res .
a ) C e r t a i n s s ' e f f r a y a i e n t d e l a b o u l i m i e d ' u n e m a c h i n e à s a i s i r , q u i a b s o r b e c h a q u e a n n é e 5 m i l l i o n s d e m o t s s u p p l é m e n t a i r e s e t q u i e n g l o u t i t d e s s o m m e s c o n s i d é r a b l e s e n v u e d e r e c h e r c h e s s e ul e m en t vi r t u e l l es . D 'a u t r e s au c o nt r ai re c o n s t a t a i en t a v ec r e g r e t l e s l a c u n e s d u c o r p u s , o ù c e r t a i n s a u t e u r s s o n t p e u r e p r é s e n t és , o ù m a n qu e nt c e rt a i n s t e x t es e s s e nt i el s, où f o nt d é f au t l e s n o t e s , l e s v a r i a n t e s , l e s v e r s i o n s d ' u n t e x t e d o n t o n f i x e u n é t a t et non l e deveni r, où l e choix m êm e de cet ét at du t ext e et de l 'é-d i t i o n 'é-d e r é f é r e n c e p r ê t a i t à 'é-d i s c u s s i o n . D a n s c e c o r p u s é n o r m e c h a c u n e s t i m a i t q u 'i l y a v a i t t r o p e t t r o p p e u : t r op p o u r l e s a u t r e s et t r o p pe u po u r s oi , t r o p pe u po u r l 'o bj et p a r t i c ul i e r , l i t t é r a i r e , l i n gu i s t i q u e o u h i s t o r i q u e , o ù u n c h e r c h e u r s e t r o u v e e n gagé.
b ) Les critiques portaient non seulement sur la
constitut i o n d u c o r p u s e t l e c h o i x d e s t e x t e s , m a i s s u r l a r e p r é s e n t a t i o n d e s t e x t e s e n m é m o i r e e t s u r l a p e r t e d ' i n f o r m a t i o n q u i r é s u l t e d ' u n s y s t è m e i n s u f f i s a n t d e c o d a g e , o ù l e s s i g n e s d e p o n c t u a t i o n o n t é t é r e s p e c t é s j u s q u e d a n s l e u r a m b i g u ï t é ( q u ' o n s o n g e a u x f o n c t i o n s b i e n d i s t i n c t e s d u p o i n t : m a r q u e d e f i n d e p h r a s e m a i s a u s s i d e s u s p e n s i o n , d 'a b r é v i a t i o n o u d e s i gl a i s o n ) , e t o ù o n t é t é négl i gés l es él ém ents qui perm ett ent de s it uer l e l ocut eur et d'at t r i b u e r l e d i s c o u r s à l 'a u t e u r o u à s e s p e r s o n n a ge s . U n e f i d é l i t é t ypo grap hi q ue t rop cou rt e ou t r op m yop e fa vori s e l a di st ors i on q u i a c c o m p a g n e l a t r a n s c r i p t i o n e n l i n é a i r e c o n t i n u d ' u n e i n f o r m a t i o n q u i s e p r é s e n t e a u l e c t e u r s o u s l a f o r m e s t r u c t u r é e d ' u n e s u r f a c e ( e t m ê m e d ' u n v o l u m e ) . L ' e n s e m b l e d e s t e x t e s d u c o r p u s e s t d é f o r m é q u a n d i l e s t r é d u i t à u n e l i g n e t r è s l o n g u e q u i f e r a i t l e t o u r d e l a t e r r e . D e c e c ô t é l e s c r i t i q u e s o n t é t é c o n s t r u c t i ves , pl usi eurs s ys t èm es de codage a yant ét é proposés (not amm ent par L a f o n e t T o u r n i e r ) q u i p e u v e n t a t t é n u e r l a p e r t e d ' i n f o r m a t i o n t o u t e n m é n a g e a n t l a s t a n d a r d i s a t i o n e t l a c o m p a t i b i l i t é .
c ) A c ô t é d e s c r i t i q u e s i l y e u t d e s c o m p a r a i s o n s e t pl usi eurs orat eurs parl èrent de réal isat ions si mi l ai res qui sont en c o u rs a u C an ad a , à Ox f or d , à P a ri s , à G r en ob l e, à T o ul ou s e e t a i l leurs.
d ) A l ' h e u r e d u b i l a n , o n p e u t p o r t e r à l ' a c t i f d e l a T a b l e R o n d e d e N a n c y d ' a b o r d u n p e u p l u s d e c l a r t é t e r m i n o l o g i q u e, l es n o t i o n s d e b a s e e t d e b a n q u e . d e d o n n é e s a ya n t f a i t l 'o b j e t d e débats contradicto ires, et si chacun ne met pas le même sens dans ces t e r m e s, c h a c u n s a i t a u m o i n s e n q u e l s e n s d 'a u t r e s l e s e m p l o i e n t . D e s d é c i s i o n s , i l n ' y e n e u t p o i n t e t c e n ' é t a i t p a s l e r ô l e d e c e c o n s e i l de r é f l ex i on . M ai s i l y e u t d e s vo e ux q u as i un a ni m es : u n vo eu d ' o u v e r t u r e e t d e f é d é r a l i s m e , c h a c u n s o u h a i t a n t u n e c i r c u l a t i o n p l u s r a p i d e d e s t e x t e s , d e s d o n n é e s , d e s m o ye n s e t d e s i d é e s . E t s u r l e s u j e t p r i n c i p a l d e c e t t e T a b l e R o n d e , o n p e u t a v a n c e r q u e l e p r i n c i p e m ê m e d ' u n e b a s e d e d o n n é e s n ' a p a s é t é c o m b a t t u , m ê m e s i c er t a i n s co nt i n u e nt à s 'i nt e r r o ge r s u r c e t t e m o d e o u c et t e f i è v r e q ui s 'e s t em p a ré e d e s m i l i e ux s c i en t i fi q u es . C e qu i a ét é d i s c u t é c e s o n t l e s m o d a l i t é s , l e s é c h é a n c e s , l e s m o ye n s e t l e s o b j e c t i f s d e c et t e b a s e . Et j e n e c a ch er a i p a s qu e d e s di f fi c u l t é s t e c h n i q u e s - o u p l u s p r é c i s é m e n t f i n a n c i è r e s - s o n t a p p a r u e s l e d e r n i e r j o u r l o rs q ue l es i m pl i c a t i o ns c o n c rè t es d u p r oj et o nt é t é e x am i n é es .
2 - C e proj et n 'es t d onc en co re qu ' un p r oj et et s 'i l es t m i s u n j o u r à e x é c u t i o n c e s e r a p r o b a b l e m e n t s o u s u n e f o r m e m o d i f i é e , s i m p l i f i é e e t p l a n i f i é e s e l o n l e s u r g e n c e s d u c a l e n d r i e r e t l es b es oi ns des ut i l i s at eurs .
Pour anal ys er ces besoi ns une ét ude de marché s 'im pos e. E l l e d e v r a i t s ' a p p u y e r s u r u n e e n q u ê t e m e n é e a u x E t a t s -U n i s p a r M . M ori s s e y aup rès d 'un e c e nt ai ne d e che rc heu r s s péci al i s é s dans l 'h i s t o i r e o u l a l i t t é r a t u r e f r a n ç a i s e s . E l l e m e t t r a i t à p r o f i t é g a l e m e n t l a s yn t h è s e o p é r é e p a r M m e M a r t i n d e t o u t e s l e s d e m a n d e s , q u i o nt é t é pr é s en t é es à l 'IL F e t q ui n e s on t p as né gl i ge a b l es p ui s q u e c e s d e r n i è r e s a n n é e s l e s e r v i c e d e s p r e s t a t i o n s e x t é r i e u r e s e n a r e ç u 1 5 0 0. M a i s on p e u t i m a gi n e r q u e b i e n d e s d e m an d es n 'o n t pas ét é prés ent ées, ou n'ont m êm e pas ét é ex pri m ées, faut e de s a voi r pré ci s ém e nt ce q ui pe ut êt re ex t r ai t des donn ée s de N anc y.
I l s ' a g i t d o n c d e t e n i r c o m p t e d e b e s o i n s v i r t u e l s a u t a n t q u e r é e l s e t p o u r l es m es u r er i l f a ut d 'a b o r d l es év e i l l er pa r u n e s e ns i bi l i s a t i o n d u p u b l i c s c i e n t i f i q u e , c e q u e s o u l i g n a i t l e d i r e c t e u r d e l 'ILF , B e r n a r d Q u e m a d a , à l 'o u v e rt ur e d u C ol l o qu e et c e qu e l e fo n d a t e u r d u T r é s o r , l e r e c t e u r l m b s , r é s u m a i t d a n s c e t t e f o r m u l e : d u s a v o i r d ' a b o r d , d u s a v o i r -f a i r e e n s u i t e , e t e n -f i n d u -f a i r e s a v o i r . C e s o u c i d e -f a i r e
s a v o i r e s t d ' a u t a n t p l u s n é c e s s a i r e q u e l e s d o n n é e s a m a s s é e s s o n t p l u s d i gn e s d ' ê t r e e x p l o i t é e s . D e p u i s p l u s i e u r s a n n é es q u e j e l e s ex pl o r e j e p u i s di r e qu 'e l l es p r é s e nt e nt pl us i e u rs avantages considérables qui restreignent la portée des critiques qu'on a entendues à Nancy : le premier est le plus évident c'est la masse énorme de la documentation qui est certainement jusqu'à ce jour la plus étendue qui- ait été constituée dans le monde en matière de langage. Le second réside dans la constance des options de saisie et de traitement. On peut n'être pas entièrement satisfait de ces options, regretter les insuffisances du codage, de la lemmatisation, de la distinction des homographes ou de celle des catégories grammaticales. Mais on doit reconnaître qu'elles n'ont pas changé en quinze ans et qu'elles s'imposent à tous les textes, à tous les auteurs, à toutes les périodes et à tous les genres littéraires - ce qui permet les confrontations et les études comparatives. A cette cohérence dans l'enregistrement s'ajoute l'homogénéité dans le corpus dont on peut contester qu'il soit représentatif de la langue française (car la langue parlée n'y figure guère) mais qui est certainement représentatif de la littérature française : le corpus du Trésor est délibérément littéraire et les grands écrivains y tiennent une place prépondérante. Et cela facilite également les études comparatives et la méthode la plus opératoire qui est la distinction des semblables. Un dernier avantage enfin peut être trouvé dans la longue expérience d'une équipe ancienne et nombreuse qui ne s'est pas contentée d'amasser les données et d'empiler les textes et qui a élaboré une série très abondante de traitements et de longues chaînes de programmes. Au point qu'on peut dire que la base de données existe déjà de façon latente, puisqu'elle dispose du matériau et des outils et qu'elle permet et a permis des formes partielles d'exploitation. Reste à affiner les matériaux, à les rendre disponibles immédiatement à l'ensemble des utilisateurs potentiels, en proposant un système d'interrogation simple et proche du langage naturel, et en faisant sauter le verrou technique qui décourage encore aujourd'hui les consultants. Voici comment l'on pourrait faire.
Il - LA CONSTITUTION DE LA BASE DES DONNEES TEXTUELLES
1 - Il faudrait d'abord délimiter l'étendue de la base. Il me semble que le corpus XIX-XX, gros de 70 millions d'occurrences, présente une priorité. Constitué depuis longtemps et support permanent de la rédaction du dictionnaire, il a été soumis à divers traitements de lemmatisation, de codage grammatical, de distinction des homographes qui .résolvent une partie des problèmes. Et pour aller plus vite je proposerais qu'on ferme le corpus et qu'on en fasse une base autonome, déjà suffisamment
encombrante. Et cela n'exclut pas d'autres bases qu'on pourra établir plus tard à partir des textes du XVIIIe ou du XVIIe siècle.
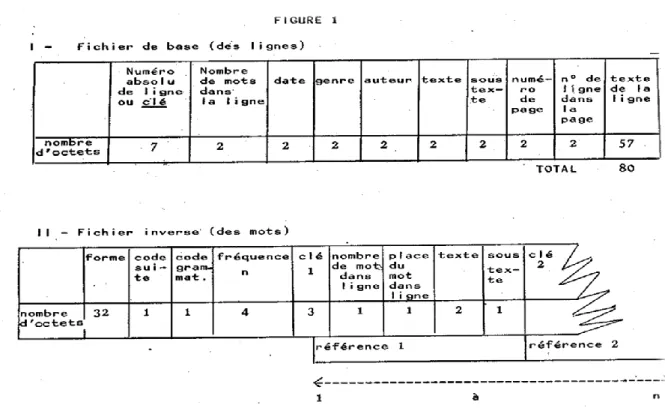
2 - Une fois délimité, le corpus doit être unifié pour constituer le fichier de base. L'opération est déjà à moitié engagée puisqu'on dispose à l'heure actuelle de la totalité des textes en continu sur bande magnétique. Il suffit de transposer ce fichier sé quentiel en fichier sélectif en y ajoutant une clé qui peut être un numéro de ligne de 7 chiffres puisqu'il y aura vraisemblablement quelques millions de lignes (aux environs de 7 millions si l'on compte en moyenne 10 mots par ligne sur un total de 70 millions de mots). Cela représente près de 600 millions de caractère, chaque ligne ayant un format fixe de 80 caractères répartis selon le schéma de la fi gure 1.
3 - La même figure 1 décrit également la structure du fi chier inverse qui contiendra des mots (des formes) et des renvois aux enregistrements du fichier de base et dont la taille avoisine aussi le demi-milliard de caractères. Ce fichier est à constituer car on ne peut reprendre un produit qui existe déjà sous l e nom de fichier-répertoire et qui répond mal au présent objectif puisqu'il ignore la localisation de la ligne. Le fichier inverse n'est pas obtenu d'un coup tel qu'on le montre dans la figure 1. Il faut d'abord dégrouper les mots dans chaque ligne, les compter et les entreposer dans un fichier qui sera soumis au tri, à la fusion et au tassement, toutes opérations de routine qui ne posent aucun problème. Le fichier inverse est au bout du compte un fichier de format variable, l'enregistrement ayant une longueur proportionnelle à la fréquence. Une limite s'impose toutefois pour les mots très fréquents qui donneront lieu à plusieurs enregistrements autant qu'ils contiendront de milliers d'occurrences. Un code spécial avertira que l'enregistrement courant comporte une suite. Un code grammatical sera également introduit en l'empruntant à certain fichier qui le possède déjà, le fichier de correspondance des graphies et des vedettes ou fichier de lemmatisation. Les homographes seront désignés par un code spécial qu'on peut extraire du même fichier.
FIGURE 1 - Fichier de base (des lignes)
III – L’INTERROGATION
1 - L'interrogation sollicite d'abord le fichier inverse en lui proposant une forme dont on veut connaître la fréquence et les références. Elle peut réclamer aussi le secours de fichiers annexes et notamment d'un fichier de lemmatisation où sont établies les correspondances entre les graphies et les vedettes. Par le truchement de ce fichier latéral on peut par exemple obtenir toutes les formes conjuguées d'un verbe dont on ne fournit que l'infinitif. Le fichier inverse contenant un code grammatical, certains choix et certaines limitations peuvent s'exercer à ce niveau, soit qu'on précise les catégories désirées, soit qu'on désigne les catégories exclues, grâce à l'opérateur SAUF. Le fichier inverse répond aussi, aux questions qui portent sur les c o n s t i t u a n t s d u m o t , radicaux, r a c i n e s , s u f f i x e s , p r é f i x e s , e t e n f i n l e t t r e s o u c o m b i n a i s o n s d e l e t t r e s . L' o p é r a t e u r d e m a s q u e e n p o s i t i o n f i n a l e o u i n i t i a l e p e r m e t d e t r o n q u e r l a c h a î n e d e c a r a c t è r e s q u ' o n v e u t i s o l e r . L e s r e n v o i s ( o u r é f é r e n c e s ) c o n t e n a n t n o n s e u l e m e n t l e n u m é r o d e l i g n e ( o u c l é ) , m a i s a u s s i l e n o m b r e d e m o t s d a n s l a l i g n e e t l a p l a c e d u m o t dans la ligne, le fichier inverse suffit à signaler les c o o c c u r r e n c e s s o i t i m m é d i a t e s s o i t G r â c e a u x o p é r a t e u r s A N D , A D J o u O R , o n p e u t r e c e n s e r l e s a s s o c i a t i o n s l e x i c a l e s , l e s c o n s t r u c t i o n s s y n t a x i q u e s , l e s c l i c h é s . D a n s c e r t a i n e s r e c h e r c h e s d e c o n t e x t e , l e f i c h i e r i n v e r s e p e u t e n c o r e ê t r e c o n s u l t é , p a r e x e m p l e lorsqu'on veut
distinguer l es h o m o g r a p h e s par l 'exam en de l 'envi r o n n e m e n t i m m é d i a t , c e q u i p e u t s e f a i r e a u s s i e n r e c o u r a n t a u t e x t e d u f i c h i e r d e b a s e . Le m ê m e f i c h i e r i n v e r s e e s t c o n s u l t é p o u r l ' e x a m e n d e s c r i t è r e s l i m i t a t i f s q u e s o n t l e s p r é c i s i o n s d e g e n r e , d ' é p o q u e , d ' a u t e u r , d e t e x t e o u d e s o u s - t e x t e . A i n s i o n p e u t c i r c o n s c r i r e l e c h a m p d e l a r e c h e r c h e à l ' é p o q u e 1 8 3 0 - 1 8 4 0 , a u x t e x t e s e n v e r s , à t e l a u t e u r o u à t e l t e x t e . Q u a n d l e s c o n t r a i n t e s s o n t f o r t e s e t q u e le champ est ress erré - par exem pl e quand le cham p ne dépas se pas l 'é t e n d u e d 'u n t e x t e - l e c r i t è r e p r i m a i r e p e u t d e v e n i r i n d é f i n i : e n u t i l i s a n t l e s ym b o l e * o n s i gn i f i e a u s ys t è m e q u 'o n n e v e u t p a s s e l i m i t e r à un e f o r m e o u à u n v o c a b l e , e t q u 'o n l e s d é s i r e t o u s . O n obt i endr a al o rs l 'i nd ex al pha bét i qu e du t ex t e (ou du s ous -t ex t e) c on sidéré.
Le t a b l e a u 2 c i a p r è s r e g r o u p e l e s c o m m a n d e s e t l e s o p é -rat eurs qu e l e s ys t è m e off re au c ons ul t ant . R em a rquon s qu 'i l n'es t p a s u t i l e d e d é t a i l l e r l e s précisions d e g e n r e o u d 'é p o q u e à l 'i n t é r i e u r d u f i c h i e r i n v e r s e , l ' i d e n t i f i c a t i o n d u texte s u f f i s a n t à res t i t u e r l a d at e et l e genr e, pa r l a cons ul t at i on pré al abl e d e t a b l e s a p p r o p r i é e s . Le p r i n c i p e est é v i d e m m e n t d e s o l l i c i t e r e n p r i o r i t é l e f i c h i e r i n v e r s e , p o u r d e s r a i s o n s é v i d e n t e s d e r a p i d i t é , e t d e r e c o u r i r l e m o i n s s o u v e n t p o s s i b l e a u f i c h i e r d e b a s e .
2 Le recours au fi chi er de bas e ne s 'i m pos e que lors -q u ' o n d o i t r e s t i t u e r l e contexte -q u ' i l s'agisse d ' u n e p h r a s e , d e n li gnes ou de n m ots. La cl é de chaque référence est alors utili s é e p o u r r e p é r e r l ' a d r e s s e d u contexte s o u h a i t é .
3 - N o t r e s ys t è m e p r é v o i t u n f i c h i e r d e f r é q u e n c e s q u i p e u t j o u e r p l u s i e u r s r ô l e s . T o u t d ' a b o r d u n r ô l e p r é v e n t i f p o u r é v i t e r l e s d é p e n s e s i n c o n s i d é r é e s . L ' u t i l i s a t e u r p e u t n e p a s m e s u r e r précisément le volume des résultats demandés et le coût du traitement, et le danger est grand lorsqu'il s'agit d'index. Si le système connaît l'étendue de chaque auteur, de chaque tex te ou sous- texte, comme aussi l'étendue des genres et des époques, et des gen res dans chaque époque, il peut le signaler à l'utilisateur, lequel prendra sa décision en connaissance de cause. Le fichier inverse d'ailleurs fera les mêmes réponses de précaution s'il s'agit d'une forme fréquente. Dans notre schéma n° 5 la réponse initiale du système, préalable à la recherche effective, est indiquée en pointillé. Mais le fichier des fréquences peut jouer un second rôle et aider les chercheurs qui se soucient de linguistique quantitative et qui par exemple souhaiteraient circonscrire le vocabulaire significatif d'un texte ou d'un auteur, ou savoir si telle forme ou tel vocable est véritablement caractéristique
du texte ou de l'auteur. C'est la statistique qui répond à ces ques tions par l'emploi de la loi normale ou de la loi hypergéométrique.
Si le fichier statistique contient le dictionnaire des fréquences par genre, par période, par genre dans chaque période et par auteur (tout au moins lorsqu'il s'agit des auteurs principaux), les éléments sont réunis pour le calcul de la probabilité attachée à telle ou telle fréquence observée dans le texte. Reste à choisir la norme de comparaison qui peut être le corpus entier ou telle subdivision que l'on voudra, genre, époque, auteur, ou intersection du genre et de l'époque. Le tableau 3 fournit les commandes nécessaires à ce genre de recherche.
4 - L ' u t i l i s a t e u r e n f i n d o i t a v o i r l e c h o i x d e s s o r t i e s e t dans l 'i nt errogat i on un ordre spéci al ED IT l ui perm et de préci s er quels élém ents il dési re et dans quel ordre. Le s résult ats di ffèrent en effet sel on qu 'i l s 'a gi t d 'un m ot d ans t o ut l e c orpu s ou d 'un t e x t e dans t out s on vocabul ai re. Il s di ffèrent s el on qu'on veut un i ndex ou une concor d a n c e . S ' a g i s s a n t d e c o n c o r d a n c e , l e c h o i x d e m e u r e e n t r e u n c o n t e x t e d 'u n e p h r a s e ou d e n l i gn e s o u d e n m o t s . Q u a nt a ux c al c ul s d e s t at i s t i q u e , i l s f o n t a p p e l à d e s m o t s - c l é s s p é c i f i q u e s c o m m e F R E Q U E N C E o u S EU IL. L'ens em bl e de ces m ot s -cl és e s t dét ai l l é d ans l e t abl e au 4 con s ac ré à l a c o m m ande ED IT.
O n p e u t i m a g i n e r u n s e c o n d t yp e d e s o r t i e q u i c o n s i s t e r a i t en un e s i m pl e copi e d 'une pa rt i e du fi chi er d e base . C e ser ai t l e m o ye n d 'a v o i r c o m m u n i c a t i o n d i r e c t e d 'u n t e x t e q u e l 'o n s e p r o p o s e r a i t d e s o u m e t t r e s u r p l a c e à d e s t r a i t e m e n t s l o c a u x . C e t r a n s f e r t d e l a b a s e t e x t u e l l e d e v r a i t s e l i m i t e r à d e p e t i t s v o l u m e s , t e l s q u ' i l s p u i s s e n t t e n i r d a n s l e s l i m i t e s d e s d i s q u e t t e s a c t u e l l e s . S ' i l s ' a g i t d e t e x t e s
l o n g s l a d u p l i c a t i o n d e b a n d e s s u r l e s i t e c e n t r a l m e p a r a î t ê t r e u n m o ye n p l u s a p p r o p r i é e t m o i n s c o û t e u x . D a n s l a f i gu r e 5 q u i r é s u m e l ' e n s e m b l e d u f o n c t i o n n e m e n t d u s ys t è m e l a d e m a n d e d e c o p i e d e s t e x t e s es t.l a s eul e qui ne t ransi t e pas p ar l e fi chi e r i nve rs e et qui s 'adr es s e d i r e c t e m e n t ( o u p r e s q u e ) a u f i c h i e r d e b a s e .
En conclusion répétons que notre projet n'est guère autre chose qu'un cahier des charges établi par un utilisateur littéraire qui n'a pas eu peur d'entrer dans la salle-machine. La réalisation d'un tel système doit bien entendu être confiée à un spécialiste des bases des données qui maîtrise les problèmes de distribution sur le réseau et qui connaisse les contraintes techniques posés par l'implémentation sur un matériel particulier. On peut seulement souhaiter que la base soit établie à Nancy, non seulement parce que les données s'y trouvent réunies, mais aussi parce que les possibilités du Centre de Calcul y ont été grandement améliorées (puisqu'on y dispose actuellement d'une capacité de stockage de 1 milliard 400 millions de caractères - ce qui suffit à. notre base de données - et que les interfaces ou organes de liaison (ou frontal) ont été récemment acquis qui permettent le raccordement au réseau Transpac.
On peut certes admettre des étapes progressives et n'en visager au début qu'un logiciel réduit et un corpus partiel. Mais la simplicité
volontaire du projet devrait permettre de rapprocher les échéances et on doit souhaiter que la réalisation ne piétine pas trop longuement et que l'on ne tourne pas trop longtemps autour d'un arbre dont les fruits sont mûrs.