HAL Id: tel-03155006
https://tel.archives-ouvertes.fr/tel-03155006
Submitted on 1 Mar 2021
HAL is a multi-disciplinary open access
archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés.
Benjamin Moreau
To cite this version:
Benjamin Moreau. Facilitating Reuse on the Web of Data. Data Structures and Algorithms [cs.DS]. Université de Nantes - Faculté des Sciences et Techniques, 2020. English. �tel-03155006�
Benjamin Moreau
Université de Nantes
Comue Université Bretagne Loire École Doctorale N°601
Mathématiques et Sciences et Technologies de l’Information et de la Communication Spécialité : Informatique
Facilitating Reuse on the Web of Data
Thèse présentée et soutenue à Nantes, le 6 Novembre 2020
Unité de recherche : Laboratoire des Sciences du Numérique de Nantes
Composition du Jury
Président : M Pascal Molli Professeur, Université de Nantes
Rapporteurs : Mme Serena Villata Chargée de recherche CNRS HDR, Sophia Antipolis
M Olivier Curé Maître de conférences HDR, Université Marne-la-Vallée Examinateurs : M Bernd Amann Professeur, Sorbonne Université
M Serge Garlatti Professeur, IMT Atlantique de Brest
M Philippe Pucheral Professeur, Université de Versailles Saint Quentin Directeur de thèse : Mme Patricia Serrano Alvarado Maître de conférences HDR, Université de Nantes Co-encadrant de thèse : M Emmanuel Desmontils Maître de conférences, Université de Nantes Invités : M David Thoumas Co-Founder & CTO, Opendatasoft
I would like to thanks people that have contributed to this thesis through their ideas, knowledge, advice, and general support.
First, I want to thank Serena VILLATA and Olivier CURÉ for accepting reading my Ph.D. thesis and writing up a report. I would also like to thank Bernd AMANN, Serge GARLATTI, Philippe PUCHERAL and, Pascal MOLLI for accepting to be part of the Ph.D. jury. I also thank Sylvie CAZALENS and Serge GARLATTI for following the progress of my thesis each year.
I want to thank my supervisor Patricia SERRANO ALVARADO for offering and encouraging me to do this thesis. I also want to thank my second supervisor Emmanuel DESMONTILS for introducing me to teaching. That was an enriching experience. Thank you both for supporting me with your knowledge and experience through these three years.
I am also thankful to all the GDD team and the LS2N laboratory that provided a excellent environment, and that helped me throughout my thesis: Thomas MINIER, Arnaud GRALL, Matthieu PERRIN, Achour MOSTEFAOUI, Hala SKAF-MOLLI, Pascal MOLLI, Pauline FOLZ, and Brice NÉDELEC.
I also thank Margo BERNELIN and Sonia DESMOULIN-CANSELIER from the laboratory of Droit et Changement Social for our helpful discussions about my work. I would also want to thank all students from the University of Nantes that participate in this work: Chanez AMRI, Alan BARON, Marion HUNAULT, Fatim TOURE, and Manoé KIEFFER.
Last but not least, I am very thankful to the Opendatasoft team for having welcomed me so well in the company and entrusting me during these three years. They all taught me a lot and gave me the opportunity to have interesting discus-sions with their clients. Finally, I want to thank David THOUMAS and Nicolas TERPOLILLI for taking the time to have followed and actively participated in this thesis.
1 Introduction 1
1.1 Reuse on the Web of Data . . . 1
1.2 Research Issues . . . 4
1.3 Contributions . . . 6
1.4 Organization . . . 9
2 Preliminaries 11 2.1 The Web of Data . . . 11
2.2 Querying the Web of Data . . . 17
3 Integrating Data into the Web of Data 21 3.1 Introduction and Motivation . . . 22
3.2 Querying non-RDF Datasets using Triple Patterns . . . 25
3.3 Assessing the Quality of RDF Mappings with EvaMap . . . 34
3.4 Generating RDF Mappings with a Semi-Automatic Tool . . . 39
3.5 Conclusion . . . 44
4 Modelling the Compatibility of Licenses 47 4.1 Introduction and Motivation . . . 48
4.2 Related Work . . . 50
4.3 CaLi: a Lattice-based License Model . . . 52
4.4 A CaLi Ordering for Creative Commons Licenses . . . 58
4.5 Implementation of CaLi Orderings. . . 60
4.6 Conclusion . . . 65
5 Ensuring License Compliance in Federated Query Processing 67 5.1 Introduction and Motivation . . . 68
5.2 Related Work . . . 70
5.3 A Federated License-Aware Query Processing Strategy . . . 73
5.4 Experimental Evaluation . . . 82
6.2 Perspectives . . . 90 A Supplemental Materials 93 List of Figures 107 List of Algorithms 109 List of Tables 111 List of Listings 113 Bibliography 115
Introduction
Contents
1.1 Reuse on the Web of Data . . . 1
1.2 Research Issues. . . 4
1.2.1 Ordering Licenses in Terms of Compatibility . . . 5
1.2.2 Ensuring License Compliance During Federated Query
Processing . . . 5
1.3 Contributions. . . 6
1.3.1 CaLi, a Model that Orders Licenses in Terms of
Com-patibility . . . 6
1.3.2 FLiQue, a License Aware Federated Query Processing
Strategy . . . 7
1.3.3 Integrating Data into the Web of Data . . . 8
1.4 Organization . . . 9
1.1
Reuse on the Web of Data
The Web of Data, also known as the Semantic Web [2], is an extension of the World Wide Web based on standards set by the World Wide Web Consortium (W3C)1. It
provides a normalized way to find, share, reuse and combine information. Semantics is encoded in the data with ontologies that are sets of concepts and categories that formally represent an area or domain. Semantic data is machine-readable and machine-understandable offering significant advantages such as reasoning over
data and facilitating interoperability among heterogeneous data sources in terms of format or schema.
The W3C recommendation to represent data on the Web of Data is the Re-source Description Framework (RDF). RDF allows writing directed labelled graphs (RDF graphs) using triples hsubject, predicate, objecti where the elements may be Internationalized Resource Identifiers (IRIs), blank nodes, or datatyped literals. A triple represents a statement about a resource. For example, Listing 1 shows two RDF triples stating that Opendatasoft is a company located in the city of Paris. 1 ex:Opendatasoft a dbo:Company .
2 ex:Opendatasoft dbo:locationCity dbpedia:Paris .
Listing 1: Two triples about Opendatasoft.
OWL (Web Ontology Language)2 and RDFS (RDF Schema)3 are the two recommended languages to describe RDF ontologies. These languages are based on description logics, making automatic processing of data possible such as inferring implicit triples or checking the consistency of an RDF dataset4.
The main idea behind the Web of Data is to break data silos by creating a global graph-based web of interlinked datasets [4]. This web of interlinked datasets is often called the Linked Data5. To make such a web a reality, Tim Berners-Lee proposed
the Linked Data principles6 that are best practices to publish RDF datasets on the
Web. These principles are about:
1. the use of IRIs as names for resources;
2. the ability to get further information and navigate among resources using the Hypertext Transfer Protocol (HTTP);
3. and the use of existing IRIs to refer to a resource the same way other datasets do.
These principles encourage the publication of interlinked and interoperable data. The last decade has seen significant growth in the Web of Data. Over 2.5 billion web pages describe resources using the schema.org7 ontology [3]. Since 2007, the
2 https://www.w3.org/TR/owl2-overview/ 3 https://www.w3.org/TR/rdf-schema/ 4 https://www.w3.org/standards/semanticweb/inference 5 https://www.w3.org/standards/semanticweb/data 6https://en.wikipedia.org/wiki/Linked_data#Principles 7https://schema.org/
Linked Open Data cloud (LOD) grew from 12 RDF datasets to more than 1239 in May 20208. Tim Berners-Lee suggested the 5-star deployment scheme9 that
promotes the publication of RDF Open Data according to Linked Data principles. The SPARQL Query Language is the W3C recommended language to retrieve and manipulate information on the Web of Data. Query engines can execute SPARQL queries on live HTTP interfaces. To take advantage of the interoperability of the Linked Data, SPARQL allows expressing queries across several RDF graphs published by autonomous data providers10. They are called federated queries and
can be evaluated on a set of RDF data sources by a federated SPARQL query engine.
An example of a federated query would be to asks for the population of each city where the Opendatasoft company is located. Listing 2 shows this federated query. Such a query can be evaluated on RDF graphs of Listing 1 and DBpedia11
dataset that describes among others statements about the city of Paris. Listing 3
shows two RDF triples from DBpedia about the city of Paris. The result of the federated query contains data from both RDF graphs.
1 PREFIX ex: <https://example.org/> .
2 PREFIX dbo: <http://dbpedia.org/ontology/> . 3
4 SELECT *
5 WHERE
6 {
7 ex:Opendatasoft dbo:locationCity ?city . 8 ?city dbo:populationTotal ?population .
9 }
Listing 2: A SPARQL query that retrieves population of each city where Open-datasoft company is located.
8The Linked Open Data Cloud is a diagram that depicts publicly available linked datasets
https://lod-cloud.net/#about
9
https://5stardata.info/
10
https://www.w3.org/TR/sparql11-federated-query/
11DBpedia is an RDF dataset generated by extracting structured information from the infoboxes in Wikipediahttps://wiki.dbpedia.org/
1 dbpedia:Paris a dbo:City .
2 dbpedia:Paris dbo:populationTotal "2229621"^^xsd:integer .
Listing 3: Two triples about the city of Paris.
Linked Data principles and federated queries encourage the reuse of datasets on the Web of Data to create new ones. Thus, in the Web of Data, reuse is common and occurs, for example, when an RDF dataset uses IRIs from existing ontologies or another dataset, or when the result of a federated query is used.
To facilitate reuse, resource producers should systematically protect their re-sources with licenses before sharing or publishing them12 [64]. A license specifies
precisely the conditions of reuse of a resource, i.e., what actions are permitted, obliged, and prohibited when using it. To protect a new resource, resource producers
can create a new license or reuse an existing one. For instance, very well known and reusable licenses are the set of Creative Commons RDF licenses13 that are
de-scribed using the CC Rights Expression Language (CC REL)14. Datasets published
on the web are usually distributed along with licenses. At the time of writing, publicly available catalogs of datasets, such as Opendatasoft’s Data Network15
or DataHub.io16 respectively have 80% and 86% of their datasets protected by
licenses.
When several licensed datasets are reused to create a new one, the resulting dataset must be protected with a license such that all licenses of reused datasets are compatible with it. For instance, the result of the federated query in Listing 2
should be protected by a license such that the license of the RDF graph in Listing
1and the license of DBpedia are both compatible with.
1.2
Research Issues
To facilitate reuse of licensed datasets, web applications that combine them should preserve license compliance. More precisely, we focus on license compliance during federated query processing. But, to make this possible, applications need to know the compatibility among licenses. In this thesis, we focus on two problems, (1) how to position licenses in terms of compatibility and (2) how to create a license-aware federated query engine.
12 https://en.wikipedia.org/wiki/FAIR_data 13 https://creativecommons.org/licenses/ 14 https://wiki.creativecommons.org/wiki/CC_REL 15https://data.opendatasoft.com/ 16https://old.datahub.io/
1.2.1
Ordering Licenses in Terms of Compatibility
Choosing the appropriate license for a combined dataset or choosing appropriate licensed datasets for a combination is a difficult process. It involves choosing a license compliant with all the licenses of combined datasets as well as analyzing the reusability of the resulting dataset through the compatibility of its license. Finding the right trade-off between protection and reusability is delicate. The risk is either, to choose a license too restrictive making the dataset difficult to reuse, or to choose a not enough restrictive license that will not sufficiently protect the dataset.
Relations of compatibility, compliance and restrictiveness on licenses could be very useful in a wide range of applications. We consider simplified definitions of compliance and compatibility inspired by works like [19, 23, 34, 70]: a license lj is compliant with a license li if a resource licensed under li can be licensed under lj without violating li. If a license lj is compliant with li then we consider that li is compatible with lj and that resources licensed under li are reusable with resources licensed under lj. In general, if li is compatible with lj then lj is more (or equally) restrictive than li.
In this thesis, we are interested in facilitating users to choose a license for a combined dataset or selecting licensed datasets for a combination. We think that an automatic ordering over licenses would facilitate this task.
There exist some works[34,71] proposing compatibility graphs of well-known licenses. However, these graphs are built from a manual interpretation of each license, making it impossible to insert a new license automatically.
Thus, the first research problem we focus on is: given a license li, how to auto-matically position li over a set of licenses in terms of compatibility and compliance?
The challenge is to generalize the definition of the ordering relations among licenses while taking into account the semantics of the actions that influence the compatibility and compliance relation.
1.2.2
Ensuring License Compliance During Federated
Query Processing
Another problem occurs when multiple licensed datasets across the Web of Data participate in the evaluation of a federated query. The query result must be protected by a license that is compliant with each license of involved datasets. However, such a license does not always exist, and this leads to a query result that cannot be reused.
A solution to the compatibility of licenses is to negotiate licenses with data providers. But this negotiation takes time and is not always possible. Another solution is to discard data sources of conflicting licenses during the source selection process. But removing data sources before query evaluation can lead to an empty
query result. This problem can be tackled by using query relaxation techniques [15, 16,31, 32]. That is, to relax the constraints of a query to match triples from other datasets. But the number of possible relaxed queries is exponential with the size of the query and the relaxation possibilities of it. Moreover, checking if each relaxed query returns a non-empty result is costly in terms of execution time in a federated context.
In this thesis, we are interested in facilitating the combination of licensed datasets using a license compliant federated query engine. Existing federated query engines do not ensure license compliance with all licenses involved in query execution.
Thus, the second problem we focus on is: given a SPARQL query and a federation of licensed datasets, how to guarantee a relevant and non-empty query result whose license is compliant with each license of involved datasets?
In a distributed environment, the challenge is to limit the overhead on the query execution time when the relaxation process is necessary.
1.3
Contributions
To answer our research problems, we propose two contributions: (1) CaLi, a model that can partially order licenses in terms of compatibility, and (2) FLiQue, a license aware query processing strategy for federated query engines. Sections 1.3.1 and
1.3.2 introduce these contributions.
This thesis is done in collaboration with the Opendatasoft17 company.
Open-datasoft is a data-sharing platform that can be used to easily access, reuse, and share data across an organization or publicly on the web. Within the scope of this thesis, we also proposed several demonstrators to facilitate the integration of datasets to the Web of Data. Section 1.3.3 introduces these contributions.
1.3.1
CaLi, a Model that Orders Licenses in Terms of
Compatibility
To automatically position a license over a set of licenses in terms of compatibility and compliance, we propose CaLi. CaLi is a model to order licenses that uses restrictiveness relations and constraints among licenses to define compatibility and compliance. We validate CaLi experimentally with an algorithm that can add any RDF license in a set of ordered licenses in terms of compatibility and compliance.
Our approach enables the development of license compliant applications. We show the usability of CaLi with a license-based search engine that can find resources reusable under a specific license.
This contribution led to the following publications:
1. B. Moreau, P. Serrano-Alvarado, and E. Desmontils. “CaLi: A Lattice-Based Model for License Classifications”. In: Gestion de Données – Principes, Technologies et Applications (BDA). Oct 2018, Bucharest, Romania.
https://hal.archives-ouvertes.fr/hal-01934596
2. B. Moreau, P. Serrano-Alvarado, M. Perrin, and E. Desmontils. “Modelling the Compatibility of Licenses”. In: Extended Semantic Web Conference (ESWC). Jun 2019, Portorož, Slovenia.
https://hal.archives-ouvertes.fr/hal-02069076
3. B. Moreau, P. Serrano-Alvarado, M. Perrin, and E. Desmontils. “A License-Based Search Engine”. In: Extended Semantic Web Conference (ESWC), Demo session. Jun 2019, Portorož, Slovenia.
https://hal.archives-ouvertes.fr/hal-02097027
4. B. Moreau, P. Serrano-Alvarado, M. Perrin, and E. Desmontils. "Modéliser la Compatibilité Entre les Licences". In: Journées Francophones d’Ingénierie des Connaissances (IC), Jun 2020, Angers, France.
https://hal.archives-ouvertes.fr/hal-02877913
1.3.2
FLiQue, a License Aware Federated Query
Processing Strategy
To guarantee a relevant, license compliant, and non-empty query result for any federated SPARQL query, we propose FLiQue, a federated license-aware query processing strategy. FLiQue is designed to detect and prevent license conflicts and gives informed feedback with licenses able to protect a result set of a federated query. If necessary, it uses query relaxation to propose a set of relevant relaxed queries whose result set can be licensed. Finally, to reduce the overhead induced by the query relaxation process in a federated context, FLiQue uses pre-calculated dataset summaries instead of communicating with the federation.
Our approach enables the creation of license-aware federated query engines facilitating reuse and creation of license compliant datasets on the Web of Data. We show the usability of our approach by integrating FLiQue in a state-of-the-art federated query engine. We experimentally validate our approach with a federated query benchmark to show the overhead produced by our approach compared to the original federated query engine.
The contribution led to the following publication:
5. B. Moreau, and P. Serrano-Alvarado. “Ensuring License Compliance in Fed-erated Query Processing”. In: Gestion de Données – Principes, Technologies et Applications (BDA). Oct 2020, Online.
https://hal.archives-ouvertes.fr/hal-02904076
1.3.3
Integrating Data into the Web of Data
Opendatasoft’s Data Network18 allows to search, find and reuse datasets among
publicly available datasets published with the Opendatasoft platform. However, despite the benefits of the Web of Data, many data publishers like Opendatasoft are sharing data in documents, or column-oriented formats and not in RDF. One of the reasons is that the integration of data in the Web of Data needs an investment in terms of time, storage, and maintainability.
To facilitate the integration of structured datasets in the Web of Data, we propose three solutions
• ODMTP, an interface to execute SPARQL queries on non-RDF datasets with high availability using RDF mappings. An RDF mapping allows describing the transformation of a structured dataset into RDF. The advantage of this approach is that the RDF dataset is not materialized and thus it does not increase storage costs.
• EvaMap, a framework that can evaluate the quality of an RDF mapping. EvaMap can evaluate the quality of the resulting RDF dataset at the beginning of the integration process on the RDF mapping and, thus, saves time. • The SemanticBot, a conversational interface to semi-automatically generate
RDF mappings for structured datasets. It allows users that are not familiar with RDF concepts to integrate their dataset in the Web of Data easily and quickly.
These contributions led to the the following demonstration papers:
6. B. Moreau, P. Serrano-Alvarado, E. Desmontils, and D. Thoumas. “Querying non-RDF Datasets Using Triple Patterns”. In: International Semantic Web Conference (ISWC), Demo session. Oct 2017, Vienna, Austria.
https://hal.archives-ouvertes.fr/hal-01583518 18https://data.opendatasoft.com/
7. B. Moreau, E. Desmontils, and P. Serrano-Alvarado. “Enrichissement de Données RDF Intégrées à la Volée”. In: Atelier Web des Données (AWD) in EGC. Jan 2019, Metz, France.
https://hal.archives-ouvertes.fr/hal-01990875
8. B. Moreau and P. Serrano-Alvarado. “Assessing the Quality of RDF Mappings with EvaMap”. In: Extended Semantic Web Conference (ESWC), Demo session. Jun 2020, Heraklion, Greece.
https://hal.archives-ouvertes.fr/hal-02612705
9. B. Moreau, N. Terpolilli, and P. Serrano-Alvarado. “A Semi-Automatic Tool for Linked Data Integration”. In: International Semantic Web Conference (ISWC), Demo session. Oct 2019, Auckland, New Zealand.
https://hal.archives-ouvertes.fr/hal-02194315
10. B. Moreau, N. Terpolilli, and P. Serrano-Alvarado. “SemanticBot: Intégration Semi-Automatique de Données au Web des Données”. In: Atelier Web des Données (AWD) in EGC. Jan 2020, Brussels, Belgium.
https://hal.archives-ouvertes.fr/hal-02454592
1.4
Organization
In the following, we introduce the organization of this document.
Chapter 2 explains the main concepts concerning the representation and the
manipulation of information on the Web of Data. It is dedicated to readers that are not familiar with the Web of Data and contains the main concepts required for a good understanding of this thesis.
Chapter 3 gives a more in-depth explanation of RDF mappings and presents
our demonstrators concerning the integration of data into the Web of Data. First, we present ODMTP, an approach to execute SPARQL queries on non-RDF datasets with high availability using RDF mappings. Then, we present EvaMap, a framework that can evaluate the quality of an RDF dataset through its RDF mapping. Finally, we present the SemanticBot, a conversational interface, to semi-automatically generate RDF mappings for structured datasets.
Chapter 4 presents CaLi, our model, that partially orders licenses in terms of
compatibility. We also show how it can be used to create license-aware applications through a demonstrator of a license-aware search engine for datasets and source codes.
Chapter 5 presents FLiQue, our license aware query processing strategy for
federated query engines. We show how it can be integrated into a federated query engine to ensure that compliant licenses protect the results of federated queries. Chapter 6 outlines conclusions and presents new challenges that are highlighted
Preliminaries
Contents
2.1 The Web of Data . . . 11
2.1.1 The Resource Description Framework . . . 12
2.1.2 Ontologies . . . 14
2.1.3 Inference . . . 15
2.1.4 Linked Data Principles . . . 15
2.2 Querying the Web of Data . . . 17
2.2.1 The RDF Query Language . . . 17
2.2.2 SPARQL Query Engines . . . 18 This chapter is intended to provide readers that are not familiar with the Web of Data with a more in-depth understanding of the context of this thesis. First section explains the main concepts of the Web of Data, the Resource Description Framework, inference, and the principles of Linked Data. Second section reminds the fundamentals of SPARQL and federated queries to retrieve and manipulate the Web of Data.
2.1
The Web of Data
This section shows standardized semantic web technologies that make the Web of Data possible. Section 2.1.1 presents the standard model for data representation on the Web of Data, ontologies to encodes the semantic in the data are introduced in Section 2.1.2, Section 2.1.3 presents the inference that enables discovering knowledge, and the Linked Data principles to create a web of interlinked data is presented in Section 2.1.4.
2.1.1
The Resource Description Framework
The Resource Description Framework1 (RDF) is the standard model for data
representation on the Web of Data. The RDF model provides three RDF terms to represent information:
1. Internationalized Resource Identifiers (IRIs) that extends URL with various alphabets used in different languages. It identifies web resources uniquely. I denotes the infinite set of IRIs.
2. Literals that are values. Literals can be tagged with a data type (e.g., string, integer, date, etc.) or a language (e.g., @fr, @en, etc.). L denotes the infinite set of Literals.
3. Blank Nodes that are identifiers locally scoped to a dataset. B denotes the infinite set of blank nodes.
An RDF graph is a set of RDF triples. An RDF triple hsubject, predicate, objecti describes a statement about a resource where the subject, is either an IRI or a blank node, the predicate is an IRI and, the object is either an IRI, a literal or a blank node. That is hsubject, predicate, objecti ∈ h(I ∪ B) × I × (I ∪ L ∪ B)i.
Several serialization formats for storing and exchanging RDF graphs are available such as Turtle, JSON-LD, RDF-XML, RDFa, etc.
For example, Listing 4shows an RDF graph serialized in the Turtle format. It contains five triples. These triples are statements about a resource identified by the IRI:
<https://example.org/Opendatasoft>.
They respectively state that it is a company, founded in 2011, and located in three cities identified by the following IRIs:
<http://dbpedia.org/resource/Paris> <http://dbpedia.org/resource/Boston> <http://dbpedia.org/resource/Nantes>
Listings 9,10, and 11in the Appendix A show the same RDF graph serialized in other formats.
1 @prefix ex: <https://example.org/> .
2 @prefix dbo: <http://dbpedia.org/ontology/> .
3 @prefix dbpedia: <http://dbpedia.org/resource/> .
4 @prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
5
6 ex:Opendatasoft a dbo:Company .
7 ex:Opendatasoft dbo:formationYear "2011"^^xsd:gYear . 8 ex:Opendatasoft dbo:locationCity dbpedia:Paris . 9 ex:Opendatasoft dbo:locationCity dbpedia:Boston . 10 ex:Opendatasoft dbo:locationCity dbpedia:Nantes .
Listing 4: An RDF graph serialized in Turtle that describes five statements about Opendatasoft.
Notice the usage of prefixes to reduce the size of the IRIs. A prefixed name is a prefix label and a local part separated by a colon “:”. RDF turns a prefixed name into an IRI by concatenating the IRI corresponding to the prefix label with the local part (e.g., ex:Opendatasoft is converted into the IRI:
<https://example.org/Opendatasoft>).
The “a” in the predicate position of the first triple is an abbreviation for the IRI: <http://www.w3.org/1999/02/22-rdf-syntax-ns##type>.
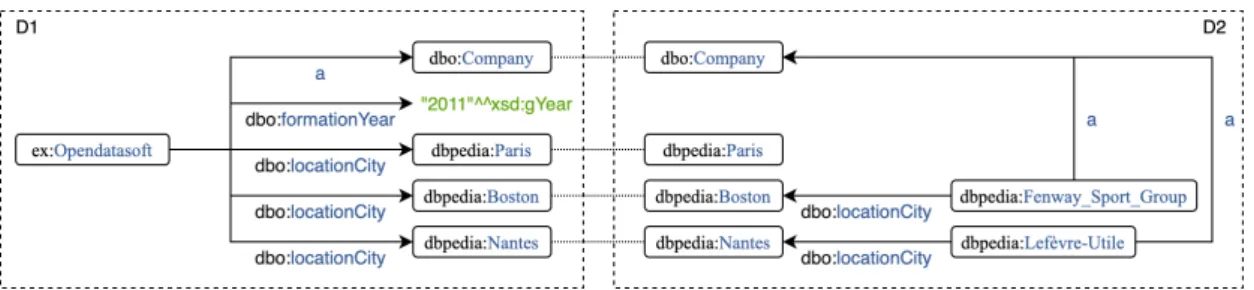
An RDF graph can also be visualized as a labelled directed multigraph where nodes represent subjects and objects, and arcs represent predicates. Figure 2.1
shows the RDF graph of Listing 4 as a labelled directed multigraph.
2.1.2
Ontologies
The main advantage of RDF is its capability to encode the semantics with the data for both machines and humans using ontologies.
An ontology, also called vocabulary, defines concepts and relationships used to formally describe an area of concern.
Languages such as RDF Schema (RDFS) and Web Ontology Langage (OWL) enable the description of RDF ontologies.
An RDF ontology provides a set of classes that can be understood as types of objects, properties that are relations between classes and, constraints that restrict the usage of classes and properties.
Ontologies for a variety of domains are published on the Web of Data, for instance, on the Linked Open Vocabularies (LOV) [68]. Figure2.2shows an excerpt of the DBpedia ontology2 used in Figure 2.1. DBpedia is a widely used
cross-domain ontology which has been manually created based on the most commonly used infoboxes within Wikipedia.
Figure 2.2: An extract of the DBpedia ontology.
In ontologies, classes are organized in a class hierarchy, also called a tax-onomy, using the property rdfs:subClassOf. It is also possible to define a property hierarchy using rdfs:subPropertyOf. In the DBpedia ontology, the class dbo:Company is defined as a sub-class of dbo:Organisation, itself defined as a sub-class of dbo:Agent that is a sub-class of owl:Thing. It means that resources of type dbo:Company are also resources of types dbo:Organisation,
dbo:Agent, and owl:Thing. A property may be seen as a function that
asso-ciates a set of objects (i.e., a class), called domain, to another set of objects,
called range. That is P roperty : domain → range. RDFS provides properties rdfs:domain and rdfs:range to restrict domain and range of a property to a set of objects that belong to a specific class. In the DBpedia ontology, property
dbo:locationCityassociates objects of type dbo:Organisationto objects of type
dbo:City, dbo:formationYear associates objects of type dbo:Organisation to literals of datatype xsd:gYear.
2.1.3
Inference
One of the main advantages of the RDF representation model is that it enables deducing implicit statements in RDF graphs through ontologies. This approach, called inference, is based on entailment rules defined in both RDFS3 and OWL4.
A saturated RDF graph is a graph where there are no longer statements to deduce. Figure 2.3 shows the saturated RDF graph of Figure 2.1. Inferred information is represented with red dashed lines. Resources dbpedia:Paris, dbpedia:Boston and, dbpedia:Nantesare inferred as resources of type dbo:City because the class dbo:City is the range of the property dbo:locationCity. Moreover, ex:Opendatasoft is inferred as a resource of type dbo:Organisation,
dbo:Agent and owl:Thing because these are super-classes of dbo:Company.
Figure 2.3: The saturated RDF graph of Figure 2.1.
2.1.4
Linked Data Principles
To take full advantage of the Web of Data, data producers must respect Linked Data principles as well as possible. Linked Data is a set of best practices to publish data on the Web of Data [4].
1. Use Internationalized Resource Identifier (IRIs) to identify any object or concept in the data.
3https://www.w3.org/TR/rdf-mt/#RDFSRules 4https://www.w3.org/TR/owl-ref/#Property
2. Use dereferenceable HTTP IRIs. That is, returning information about the object or concept when someone looks up for its IRI.
3. Use already existing IRIs as much as possible to link RDF graphs.
Figure 2.4 shows RDF graphs D1 and D2 that respect the third principle of Linked Data. Dotted lines represent the links between the two graphs. Notice that using the same IRIs in several RDF graphs creates links among datasets. That is, describing statements about the same resource or using the same ontology to describe a resource.
Publishing RDF data according to Linked Data principles, makes it readable and understandable by both machines and humans. Thus, it has many advantages, such as:
• interoperability, because several datasets may describe the same resources and use equivalent ontologies;
• discoverability, because search engines understand ontologies;
• and maintainability, because ontologies remove ambiguities that may exist on the name of attributes used in datasets;
Figure 2.4: Links between two RDF graphs that share the same IRIs. When published as open data, RDF datasets that respect the principles of Linked Data are interlinked and form a Linked Open Data Cloud5 (LOD). Some
of these RDF datasets are more and more used such as DBpedia6, Wikidata7,
Geonames8, etc.
Since the 2012 announcement by Google9, knowledge graph (KG) [30] has become
a non-formally defined term for a graph that uses an ontology to describe entities
5 https://lod-cloud.net/ 6 https://wiki.dbpedia.org/ 7 https://www.wikidata.org/ 8https://www.geonames.org/ 9https://www.blog.google/products/search/introducing-knowledge-graph-things-not/
such as real-world objects, events, situations or abstract concepts. Knowledge graphs are now used in a variety of domains such as: query engines (e.g., Google, Yahoo!10, Bing11), social media (e.g., Facebook [51], LinkedIn12), commerce (e.g.,
Amazon13, Ebay14), and media (e.g., BBC15, New York Times16).
2.2
Querying the Web of Data
This section presents the RDF query language (SPARQL) (cf. Section2.2.1) and query engines (cf. Section 2.2.2) that are used to retrieve and manipulate RDF graphs on the Web of Data.
2.2.1
The RDF Query Language
SPARQL Protocol and RDF Query Language (SPARQL)17 is a query language to
retrieve and manipulate data available in RDF format.
A SPARQL query, denoted by Q, is a set of basic graph patterns (BGP) that is a set of triple patterns. A triple pattern (tp) is a triple where subject, predicate and object may be a variable, denoted by V . That is hsubject, predicate, objecti ∈ h(I ∪ B ∪ V ) × (I ∪ V ) × (I ∪ L ∪ B ∪ V )i.
Listing 5 shows an example of SPARQL query that retrieves companies, associ-ated to their city, that are locassoci-ated in the same city as an office of the Opendatasoft company. This query contains one BGP which consists of three triple patterns tp1, tp2, and tp3. 10 https://www.researchgate.net/publication/322899161_The_Yahoo_Knowledge_ Graph 11 https://blogs.bing.com/search-quality-insights/2017-07/ bring-rich-knowledge-of-people-places-things-and-local-businesses-to-your-apps 12 https://engineering.linkedin.com/blog/2016/10/building-the-linkedin-knowledge-graph 13 https://blog.aboutamazon.com/innovation/making-search-easier 14 https://www.ebayinc.com/stories/news/cracking-the-code-on-conversational-commerce/ 15 https://www.bbc.co.uk/blogs/internet/entries/78d4a720-8796-30bd-830d-648de6fc9508 16https://open.nytimes.com/build-your-own-nyt-linked-data-application-8b91fb71fd23 17https://www.w3.org/TR/rdf-sparql-query/
1 PREFIX ex: <https://example.org/> .
2 PREFIX dbo: <http://dbpedia.org/ontology/> . 3
4 SELECT ?city ?company
5 WHERE
6 { #BGP
7 ex:Opendatasoft dbo:locationCity ?city . #tp1
8 ?company dbo:locationCity ?city . #tp2
9 ?company a dbo:Company . #tp3
10 }
Listing 5: A SPARQL query that retrieves companies, associated to their city, that are located in the same city as an office of the Opendatasoft company.
2.2.2
SPARQL Query Engines
A SPARQL query engine can evaluate a SPARQL query on an RDF graph. That is to match each BGP of the query to sub-graphs of the RDF graph. A BGP matches an RDF graph when RDF terms from that graph may be substituted for the variables, and the result are two equivalent RDF graphs.
Figure2.5 shows the BGP of the SPARQL query in Listing5 matching a sub-graph of an RDF sub-graph. The RDF sub-sub-graph that matches the BGP is highlighted. Notice that sub-graph containing the resource dbpedia:Paris does not match the BGP because, in our example, no other company is located in this city.
The SELECT clause of the SPARQL query identifies the variables to appear in the result set of the query. RDF terms that match these variables are retrieved from the RDF graph. In the query of Listing5, theSELECT clause identifies the variables ?city and ?company. If the query is evaluated on the RDF graph of Figure 2.5, the resources that match the variables ?city and ?company in the matching sub-graph are respectively dbpedia:Boston with dbpedia:Fenway_Sport_group and dbpedia:Nantes with dbpedia:Lefèvre-Utile.
To take advantage of the interoperability provided by the Linked Data, SPARQL allows expressing queries across several RDF graphs published by autonomous data providers18. A federated SPARQL query engine [54] can evaluate a federated
SPARQL query on a set of RDF data sources, known as a federation. An RDF data source is any dataset accessible in RDF format (e.g., RDF file, triplestore, etc.)
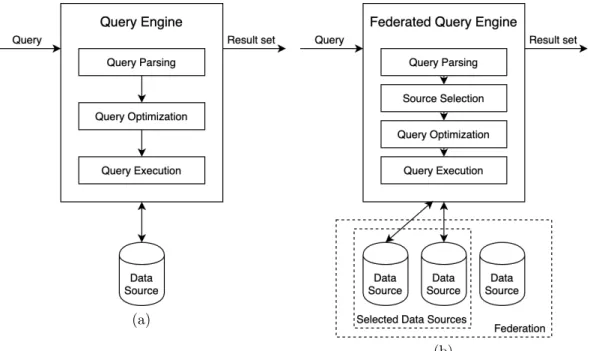
As an example, consider that dataset D1 and dataset D2 in Figure 2.4 are two autonomous RDF data sources on the web. Then, a federated query engine can evaluate the federated query in Listing 5 on D1 and D2 as if they were a single RDF graph.
(a)
(b)
Figure 2.6: A query processed by a query engine (a) and a federated query engine (b).
Figure2.6shows how a query is processed on a query engine (a) and a federated query engine (b). During federated query processing, not all data sources participate in the evaluation of a federated query. Thus, the source selection process allows the identification of the data sources in the federation that may contain relevant data. During the processing of query in Listing5, the source selection process can identify data source D1 as relevant to evaluate triple pattern tp1, tp2 and tp3, and D2 as relevant to evaluate tp2 and tp3. It is because D1 contains one triple that match tp1 and tp3, and three triples that matches tp2, and D2 contains two triples that matches tp2 and two triples that matches tp3.
Data published on the web in RDF format and queryable through a live SPARQL interface are integrated into the Web of Data. Once integrated, data has the advantage of being highly reusable. The following chapter presents approaches that facilitate the integration of non-RDF data into the Web of Data.
Integrating Data into the Web of
Data
Contents
3.1 Introduction and Motivation . . . 22
3.1.1 Virtually Integrate non-RDF Datasets with Triple
Pat-tern Fragments Interface . . . 24
3.1.2 Assessing the Quality of RDF Mappings . . . 24
3.1.3 Facilitating the Creation of RDF Mappings . . . 24
3.2 Querying non-RDF Datasets using Triple Patterns . . . 25
3.2.1 ODMTP: On-Demand Mapping using Triple Patterns . 27
3.2.2 Supporting Inference with ODMTP . . . 28
3.2.3 Implementation . . . 30
3.2.4 Experimental Evaluation . . . 31
3.3 Assessing the Quality of RDF Mappings with EvaMap. . . 34
3.3.1 EvaMap: A Framework to Evaluate RDF Mappings . . 36
3.3.2 Implementation and Demonstration Tool . . . 38
3.4 Generating RDF Mappings with a Semi-Automatic Tool. . . . 39
3.4.1 SemanticBot: A Conversational Interface to Generate
RDF Mappings . . . 41
3.4.2 Implementation and Demonstration Tool . . . 43
The majority of datasets on the web are not published as RDF. Yet, transforming structured datasets into RDF datasets is possible thanks to RDF Mappings. During the process of transformation and publication of non-RDF datasets as RDF, data producers face several challenges, which can be obstacles to integrate datasets to the Web of Data. We think that facilitating this process can help some data-producers to publish RDF data and, thus, will foster the Web of Data growth.
This chapter is based on articles [41,42,45,49,50] and presents three approaches that aim to facilitate the publication of RDF datasets through RDF mappings. Section3.2 presents ODMTP. It allows executing SPARQL queries on non-RDF datasets through RDF mappings with high availability. Then, Section 3.3 presents EvaMap, a framework to evaluate the quality of RDF mappings. Finally, Section
3.4 presents SemanticBot, a semi-automatic tool to generate RDF mappings for structured datasets.
3.1
Introduction and Motivation
Despite the growing number of information on the Web of Data and the benefits of Linked Data, a lot of datasets are not available in RDF or do not always respect Linked Data principles. Publishing data sources as RDF datasets that respect Linked Data principles requires methods to translate structured datasets into an RDF representation. This is possible through the implicit description of a mapping, for instance, in the source code of a software, that describes the transformation of the data into RDF. Another solution is through the explicit description of an RDF Mapping such that the mapping is an RDF dataset that can be shared and reused. Many RDF mapping languages where proposed to transform relational databases in RDF [66]. More recent works like RDF Mapping Language (RML) [13] or SPARQLGenerate [37] propose generic languages to integrate data from heterogeneous formats into RDF.
An RDF mapping is an RDF graph that allows describing the transformation of a structured dataset into RDF. It consists of a set of triples that are transformation rules containing references to the initial dataset, and represents the semantics of the resulting RDF dataset. Consider Table 3.1 that shows an excerpt of a structured dataset describing Roman Emperors and Figure 3.1 that represents an RDF mapping allowing to transform such dataset in RDF. In this mapping, Bold text starting with $ are references to a column in the dataset.
A mapper generates an RDF dataset by evaluating an RDF mapping on a dataset. Figure3.1 shows the RDF dataset resulting from the transformation of the dataset in Table 3.1 with the mapping in Figure 3.1. In this example, the mapper generates the RDF dataset by replacing references in the RDF mapping
string date string string float float
Name Birth Birth City Birth Province Lat Long
Augustus 0062-09-23 Rome
Caligula 0012-08-31 Antitum
Claudius 0009-08-01 Lugdunum Gallia Lugdunensis 47.932559 0.191854
... ... ... ... ... ...
Table 3.1: An excerpt from a structured and typed dataset describing Roman emperors.
Figure 3.1: An RDF mapping for Roman emperors dataset. by values of the referenced columns for each row in the initial dataset.
Figure 3.2: An RDF dataset describing Roman emperors.
However, publishing an existing dataset as an RDF dataset that respects Linked Data principles is not easy. In this chapter, we focus on three problems that data producers face during transformation and publication process.
3.1.1
Virtually Integrate non-RDF Datasets with Triple
Pattern Fragments Interface
After the transformation of a dataset into RDF, storing the result in a triple-store is an important investment in terms of storage and maintainability. Existing works propose to use RDF mappings to integrate datasets as RDF virtually. That is to enable querying non-RDF datasets with SPARQL as if they were stored as RDF. These works focus on the SPARQL endpoint interface to expose non-RDF data. But, this interface suffers from availability issues [5]. To tackle this problem, Triple Pattern Fragments (TPF) [69] has been proposed. However, no work focus on the TPF interface to expose non-RDF data.
Thus, the first problem we focus on is: how to virtually integrate non-RDF datasets as RDF simply and efficiently using RDF mappings and Triple Pattern Fragments interface?
The challenge is to limit the overhead produced by the virtual integration on the global query execution time.
3.1.2
Assessing the Quality of RDF Mappings
Making an RDF mapping for a dataset is a crucial step in the integration of a dataset into the Web of Data. The quality of the resulting RDF dataset highly depends on the quality of its RDF mapping. Making a relevant RDF mapping for a dataset while respecting the Linked Data principles is a challenging task. Moreover, in addition to possible errors a user can make, different RDF mappings are possible for the same dataset, for example, depending on the ontology chosen to describe the dataset.
Thus another problem we focus on is: How to automatically help users to create RDF mappings without errors and how to choose the best mapping from a set of RDF mappings?
The challenge is to evaluate the quality of the RDF mapping instead of the resulting RDF dataset to identify errors at the beginning of the transformation process and saves time.
3.1.3
Facilitating the Creation of RDF Mappings
Writing a relevant mapping for a dataset is not a simple task. It requires answering several questions, for instance: what are the concepts described in the dataset? Which existing RDF ontologies are relevant to describe these concepts? But, answering these questions requires both to know the dataset perfectly and to be familiar with RDF. Unfortunately, many data producers are not familiar with RDF and are not yet ready to invest time in writing RDF mappings.
The third problem we focus on is: how to simplify as much as possible the creation of RDF mappings for existing structured datasets?
The challenge we face is to automate the part of the integration process that requires getting familiar with RDF.
In the following, we present three contributions that answer our three problems.
3.2
Querying non-RDF Datasets using Triple
Patterns
Transforming existing datasets as RDF and storing them in triple-stores requires to store data as RDF and non-RDF in two separate databases and to synchronize them during updates. Existing works [17,39] propose to query non-RDF datasets on-demand with SPARQL. That is to virtually integrate non-RDF data sources through RDF mappings to make run-time evaluations of SPARQL queries.
Several HTTP client-server interfaces have been proposed to publish and access datasets on the Web of Data [26, 40, 69], but the SPARQL endpoint interface remains the most popular despite a study [5] that shows that this interface suffers from availability issues.
Each of these client-server SPARQL interfaces is characterized by the type of requests the server can evaluate. The type of requests has a significant impact on the effort made by the server during the evaluation of a SPARQL query and, thus, on its availability. Figure 3.3 shows several HTTP client-server SPARQL interfaces ordered according to the effort made by the server during the evaluation of a SPARQL query.
Figure 3.3: HTTP client-server SPARQL interfaces.
Triple Pattern Fragments interface [69] is one of the interfaces proposed to query RDF datasets with high availability. One of the reasons for server availability is the simplicity of the server interface. An important part of the query execution is on the client-side.
Differences between SPARQL endpoints and TPF interfaces are respectively shown in Figures 3.4 and3.5. With TPF, the client receives a SPARQL query and decomposes it into Triple Pattern Queries (TPQ). TPQs are sent to TPF servers.
A server matches triple pattern and page to an RDF dataset and sends results back to the client along with metadata and controls (e.g., the total number of triples matching the triple pattern, the number of triples per page, the link to the next page, etc.). RDF graph returned by TPF servers are called fragments and are used by the TPF client to build the complete answer of the SPARQL query. Listing 12
in the Appendix A shows a fragment returned by a TPF server.
Figure 3.4: The SPARQL Endpoint interface.
Figure 3.5: The Triple Pattern Fragments interface.
Existing works focus on exposing non-RDF datasets through SPARQL endpoints but not through Triple Pattern Fragments interface. Figure3.6shows the execution of a SPARQL query on a virtually integrated non-RDF dataset.
Figure 3.6: The execution of a SPARQL query on a virtually integrated non-RDF dataset.
As explained in section2.1.3, the inference is the execution of entailment rules on RDF datasets through ontologies to discover implicit triples. Supporting inference
in a query engine is very important to return complete results. But supporting inference on virtually integrated non-RDF datasets is not straightforward because explicit triples are required to deduce implicit triples.
In this section, the problem we focus on is how to integrate non-RDF datasets on-demand as Linked Data simply and efficiently using TPF.
The challenge is to support inference and limit the overhead produced by the virtual integration and the inference on the global query execution time.
We propose ODMTP, an On-Demand Mapping using Triple Patterns over non-RDF datasets [45] that supports inference [41]. To illustrate our approach, we implemented ODMTP to query Twitter, GitHub, and LinkedIn with SPARQL queries.
3.2.1
ODMTP: On-Demand Mapping using Triple
Patterns
We propose to modify the TPF server such that, instead of evaluating TPQs over an RDF store, it sends TPQs to ODMTP.
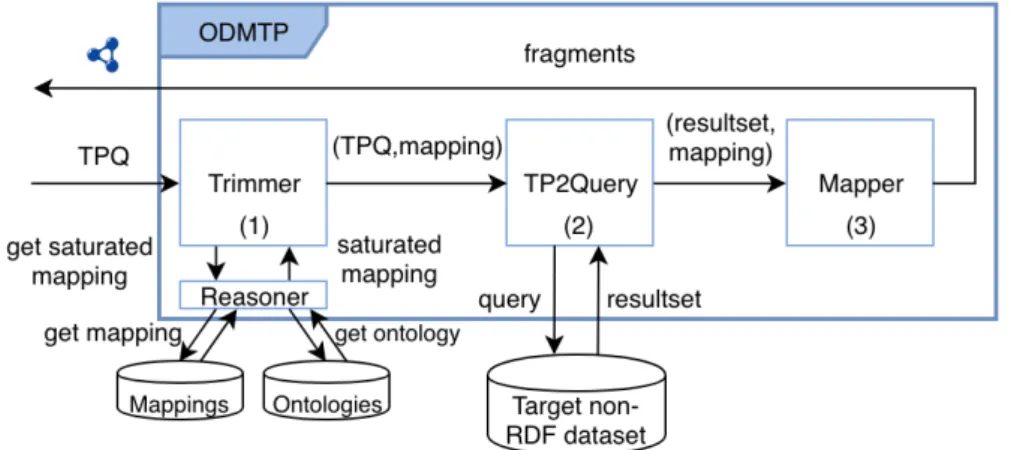
Figure 3.7 presents the global architecture of ODMTP. TPF clients receive SPARQL queries and decompose them into several TPQs. TPQs are sent to ODMTP through a TPF server.
Figure 3.7: The global architecture of ODMTP.
When ODMTP receives a TPQ, it translates it into the target query language and sends it to the target non-RDF dataset. The query engine of the non-RDF dataset evaluates this query and returns the result set to ODMTP. Then, ODMTP translates this answer in triples, it constructs fragments and sends them to the TPF server.
ODMTP translations are possible thanks to the RDF mapping of the target dataset. Several mappings can be defined for one target dataset depending on the needs of semantic applications.
Figure 3.8 shows more details about the ODMTP module. The trimmer component receives a TPQ and from a mapping file it extracts the mappings
pertinent to the triple pattern. Then, the TPQ and its corresponding mapping is received by TP2Query that uses the mapping to translate the triple pattern into a query in the query language of the non-RDF dataset. TP2Query communicates with the query engine of the non-RDF dataset and obtains the result set corresponding to TPQ. It also estimates the total number of triples matching the triple pattern. The implementation of this component depends on the non-RDF dataset. Finally, the Mapper component uses the mapping to translate the resultset in triples. And it produces the fragment that is sent to the TPF server.
Figure 3.8: The components of the ODMTP module.
3.2.2
Supporting Inference with ODMTP
Supporting inference in a query engine is very important to return complete results. Implicit triples can be materialized before query execution or returned during query execution.
Existing works [20,67] propose to materialize implicit triples. But, this approach increases the size of RDF datasets. Other works [53, 58] use query rewriting to evaluate queries on implicit triples without materializing them. The size of the RDF dataset remains constant but the query execution time increases.
Supporting inference on virtually integrated non-RDF datasets is not straightfor-ward because explicit triples are required to deduce implicit triples. Moreover, query rewriting approaches increase the query execution time that is already increased by virtual integration. To limit the overhead produced by inference, we propose a simple approach that consists of applying entailment rules on RDF mapping to allow the execution of new SPARQL queries on non-RDF datasets.
As an example, consider the RDF mapping for the Roman emperors dataset in Figure 3.1. With this mapping, ODMTP can execute query of Listing 6that asks for resources of type dbo:Place but returns an empty result when the query of
Listing 7 asking for resources of type dbo:Location is executed. Figure3.9 shows an extract of the DBpedia ontology that defines super classes and equivalent classes of the dbo:Place class. The query of Listing 7 should not return an empty result set because dbo:Place is equivalent to the class dbo:Location. To tackle this problem, we use the ontology to deduce and materialize implicit transformation rules in the RDF mapping. Figure 3.10 shows the saturated RDF mapping of Figure 3.1. Inferred transformation rules are represented with red dashed lines. The saturated mapping allows ODMTP to execute queries on implicit triples such as the query in Listing 7.
Figure 3.9: Super classes and equivalent classes of the dbo:Place class.
Figure 3.10: The saturated RDF mapping of Figure 3.1 according to the ontology of Figure 3.9.
PREFIX dbo: <http://dbpedia.org/ontology/>. SELECT ?place
WHERE {
?place a dbo:Place . }
Listing 6: A query that retrieves re-sources of type dbo:Place.
PREFIX dbo: <http://dbpedia.org/ontology/>. SELECT ?loc
WHERE {
?loc a dbo:Location . }
Listing 7: A query that retrieves re-sources of type dbo:Location. ODMTP supports inference through its reasoner module. Figure 3.11 shows the reasoner module integrated into the ODMTP approach. It can infer implicit
triples from the RDF mapping using RDFS and OWL entailment rules and the ontology used in the mapping.
Figure 3.11: The reasoner module integrated to ODMTP.
The saturated RDF mapping is computed before query execution during the deployment of ODMTP. Thus, the execution time remains constant. Moreover, the overhead in terms of storage is limited because the number of implicit triples in an RDF mapping is small compared to implicit triples in the resulting RDF dataset. A limitation of this approach is that only the rules concerning properties and classes in the RDF mapping are taken into account in our approach. Rules that apply to instances are not supported by ODMTP because instances are not materialized in RDF mappings. The list of supported rules is available on the repository of ODMTP1.
3.2.3
Implementation
To show the usability of our approach, we implemented ODMTP for Twitter, GitHub, and LinkedIn APIs. This implementation is available on GitHub under the MIT license2. ODMTP is a Django3 application that can receive requests
from any TPF client4. Our implementation allows users to query tweets, GitHub
repositories, or LinkedIn profiles using SPARQL. RDF mappings are also available on the repository5. Moreover an online video demonstration is available6.
1 https://github.com/benjimor/odmtp-tpf#supported-rules 2 https://github.com/benjimor/odmtp-tpf 3 https://www.djangoproject.com/ 4 http://query.linkeddatafragments.org/ 5https://github.com/benjimor/odmtp-tpf/tree/master/mapping 6https://youtu.be/wruH8teK9tU
S P O S P ?o S ?p O S ?p ?o ?s P O ?s P ?o ?s ?p O ?s ?p ?o
Table 3.2: The eight types of triple patterns.
3.2.4
Experimental Evaluation
The goal of our experimental evaluation is to measure the overhead produced by the ODMTP TPF server compared to the original TPF server in terms of execution time of a triple pattern query. This execution time is tightly related to the performance and the capabilities of the data source of the TPF server. The ODMTP TPF server is a Python implementation connected to several datasets stored in JSON and queried through Elasticsearch. The cardinality of datasets goes from 100,000 to 500,000 triples. Experiments were executed locally7.
We measured the time to evaluate the eight possible types of triple patterns to see if the place of the variable in a triple pattern has an impact on the execution time. Table 3.2 shows the eight types of triple patterns. Variables are preceded with a question mark. Constants are in bold capitals and can be IRIs, Literals, or blank nodes. We executed each query five times and get the average execution time.
We also measured the time to evaluate the last page (i.e., the potentially most expensive result page) to take into account the pagination capabilities of the TPF server data source.
We compared these performances with two traditional TPF servers. One is connected to RDF datasets materialized in HDT [14] files that support pagination. The other is connected to RDF datasets materialized in Turtle files (TTL) that do not support pagination.
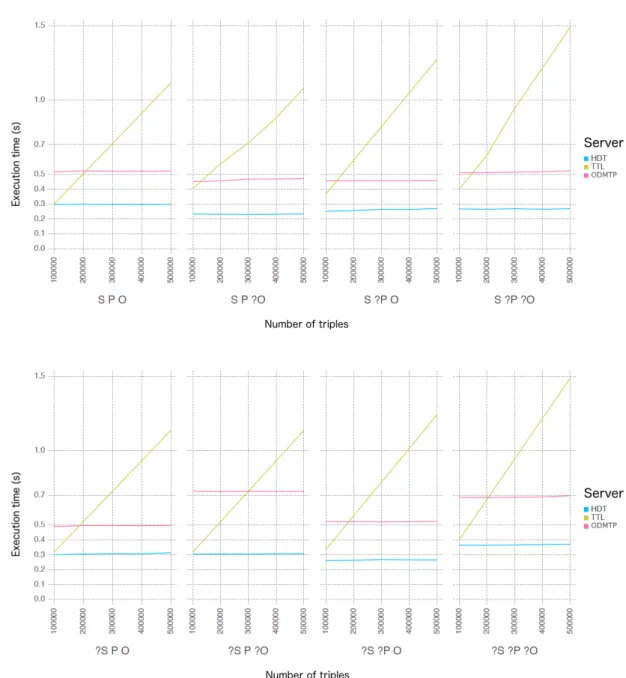
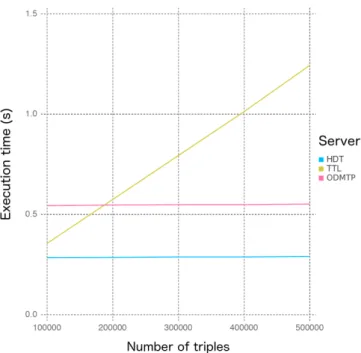
Figure 3.12 shows the average execution time of the last page for each type of triple pattern, depending on the size of the dataset. The execution time increases linearly with the size of the dataset when the TPF server query a data source that does not support pagination. That is because, to compute a page, it needs to compute all previous pages. For the sources that support pagination, we see that execution time does not increase with dataset size and that the type of triple pattern
does have an impact on the execution time but does not affect the complexity. Thus, we can compute the average overhead of ODMTP comparing to a TPF server connected to an HDT data source.
Figure 3.12: The average execution time to retrieve the last page for each type of triple pattern.
Figure 3.13 shows the average execution time of the last page for all types of triple patterns. On average, ODMTP produced a constant overhead (on average
+0,250 seconds). The reason for this limited overhead is the set of efficient indexes produced by Lucene8 that is used by Elasticsearch.
Figure 3.13: The average execution time to retrieve the last page of a triple triple pattern.
Finally, we also measured the average execution time of a complete SPARQL query that retrieves all triples of the dataset (i.e., a query with a BGP containing the triple pattern ?s ?p ?o). We compared the execution time of the complete set of TPQs with our ODMTP approach versus the TPF server connected to the HDT file. The execution time is measured on the client side.
Figure 3.14shows the average execution time of the SPARQL query depending on the size of the RDF dataset. The execution time of this SPARQL query grows linearly with both TPF servers. It grows faster with ODMTP compared to the TPF server with an HDT file. That is because of the overhead produced by ODMTP for each TPQ to execute in order to answer the complete SPARQL query.
Figure 3.14: The average time to execute a SPARQL query.
This experimental evaluation confirms that ODMTP can evaluate any triple pattern query in constant time despite the size of the dataset. Moreover, the complexity of the ODMTP approach is similar to a TPF server connected to an HDT file.
3.3
Assessing the Quality of RDF Mappings with
EvaMap
Making a relevant RDF mapping for a dataset is a challenging task because it requires to answer several questions:
1. What are the different resources described in the dataset (e.g., cars, persons, cities, places, etc.)?
2. What are the attributes of these resources (e.g., price, age, etc.)? 3. How should the IRI of resources be defined?
4. What are the possible relations between the different resources (e.g., the city is the birthplace of the person)?
5. Which ontology, classes, and properties should be used?
As well as possible errors by the user, different answers are possible for some of these questions and, thus, different RDF mappings are possible for the same dataset.
In addition to the mapping in Figure 3.1, Figure 3.15 presents two possible mappings for the dataset in Table3.1. Unlike mapping3.15(a), mapping3.15(b) does not include a class description in resource IRIs and does not reference the Birth Province column.
Figure 3.15: Two other RDF mappings for the Roman emperors dataset.
We think that assessing the quality of mappings is important because it directly impacts the quality of the resulting RDF dataset. A triple in an RDF mapping can generate multiple triples in the resulting RDF dataset. Thus, correcting an error in the mapping is more effective than correcting the generated errors in the RDF dataset. Moreover, to save time during the publishing process, the earlier quality is assessed, the better [12].
We believe that a tool capable of evaluating the quality of an RDF mapping and returning feedback would make the creation and the choice of RDF mappings easier.
In this work, we answer the following question: Given a structured dataset, how to help users to create RDF mappings without errors automatically, and how to choose the best mapping from a set of RDF mappings?
In the state-of-the-art, [12] proposes a framework that assesses and refines RML mappings. However, authors focus on logical errors due to incorrect usage of ontologies (e.g., violation of domain, range, disjoin classes, etc.). [72] proposes a framework to assess the quality of RDF datasets through metrics. Metrics are organized in dimensions evaluating different aspects of a dataset (e.g., availability, interlinking, etc.). But, [72] does not propose to assess the quality of an RDF mapping. In our work, like in [12], we evaluate metrics on the RDF mapping instead of on the resulting RDF dataset. This choice allows us to identify errors at the beginning of the publishing process and saves time.
However, not all metrics can be applied to mapping. Thus, the challenge is to evaluate as many metrics as possible on the RDF mapping.
Based on the framework proposed in [72], we propose EvaMap [42]. EvaMap is a framework to Evaluate RDF Mappings. We propose an extension of the set of metrics proposed in [72]. The goal is to control the quality of the resulting dataset through its mapping without having to generate the RDF dataset. It is also capable of returning feedback to the user to improve its mapping.
Dimension Description
Availability Checks if IRIs are dereferenceable
Clarity Checks human-readability of the mapping and the resulting dataset
Conciseness Checks if the mapping and the resulting dataset is minimal while being complete Consistency Checks if the mapping is free from logical errors
Coverability Checks if the RDF mapping is exhaustive compared to the initial dataset Connectability Checks if links exist between local and external resources
Reusability Checks if metadata enables reuse
Table 3.3: The set of dimensions used in EvaMap.
3.3.1
EvaMap: A Framework to Evaluate RDF Mappings
EvaMap uses a set of metrics organized in 7 dimensions. When it is possible, metrics are evaluated on the RDF mapping. Otherwise, they are evaluated on an extract of the resulting RDF dataset. For example, the available resource IRIs metric needs RDF dataset to check if generated IRIs are dereferenceable. In this case, EvaMap generates a sample such that applying each mapping rule to the entire input dataset is not necessary. Table 3.3 describes each dimension of EvaMap. These dimensions are based on [72]. From these dimensions, we propose the Coverability one that detects the lose of data between the input dataset and the resulting RDF dataset. Table 3.4 shows the set of metrics used by EvaMap. New metrics proposed in EvaMap are highlighted in blue. The last column indicates if the metric is evaluated on the RDF mapping or if the initial dataset is also needed.
In order to compute the quality of a mapping, Mi applied on a raw dataset D, we propose a function q(Mi, D) ∈ [0, 1] that is the weighted mean of the quality of each metric mj(Mi, D): q(Mi, D) = Pn j=1wj.mj(Mi, D) Pn j=1wj
EvaMap also computes the score for each dimension. To do that, it only considers the subset of metrics for the corresponding dimension.
Weights wj associated with metrics can be used to give more or less importance to each metric. For example, the user does not always want to generate RDF triples for all data in the input dataset. Thus, weights associated with coverability metrics can be lowered or set to zero.
Figure3.16shows the global architecture of EvaMap. In addition to the quality of the RDF mapping, it returns feedback to improve the mapping.
Dimension Metric Description Evaluation Ontology availability Checks if IRIs of classes and properties return a 2xx successHTTP code. Mapping Availability Dataset availability Checks if IRIs of instances return a 2xx success HTTP code. Dataset
Entities human-readability Checks if entities have a label or a description. Mapping Clarity IRIs human-readability Checks if IRIs are human-readable. Mapping Rules conciseness Checks that there are no several transformation rulesgenerating the same set of triples. Mapping
Conciseness IRIs conciseness Checks if IRIs are not too long. Mapping
Properties consistency Checks if domain and range of property are respected. Mapping Class hierarchy consistency Checks super-classes and equivalent classes. Mapping Property hierarchy consistency Checks super-properties and equivalent properties. Mapping Disjoint class consistency Checks that there are no instances belonging todisjoint classes. Mapping Consistency
Datatype consistency Checks if datatypes are consistent with datatypesin the input dataset. Dataset Coverability Vertical coverability Checks if all attributes of the input dataset areconsidered. Dataset Entities connectability Checks if entities are linked to other entities usingthe sameAs property. Mapping External connectability Checks if IRIs from external graphs are referenced. Mapping Local connectability Checks if IRIs from the local graph are linked to each other. Mapping Connectability
Ontology connectability Checks if already existing ontologies are used. Mapping License availability Checks if the mapping is protected with a license. Mapping License compatibility Checks if licenses of the dataset and the mapping arecompatible. Dataset Reusability
Expiration Checks if the last update of the mapping is newer thanthe last update of the dataset. Dataset Table 3.4: The set of metrics used in EvaMap.
3.3.2
Implementation and Demonstration Tool
We implemented EvaMap to evaluate YARRRML [28] mappings for datasets of the Opendatasoft’s Data Network9. The source code of our tool10 and web service11
are available on GitHub under the MIT license.
Our tool is available as a web service12. Users are able to select different
mappings and use EvaMap to compare them. For each mapping, the global quality score is computed as well as the quality score for each dimension. Our tool also gives feedback that can be used to refine the RDF mapping. For instance, users can assess two mappings for the dataset football-ligue. They can see that the mapping football-ligue obtains a worse global score than the mapping football-ligue-fixed. In the detailed report, users can analyze by dimension why these scores are different.
Figures3.17 and 3.18 respectively show the quality score and feedback on the clarity dimension returned by our implementation of EvaMap.
Figure 3.17: The quality score for an RDF mapping returned by EvaMap.
9 https://data.opendatasoft.com 10 https://github.com/benjimor/EvaMap 11https://github.com/benjimor/EvaMap-Web 12https://evamap.herokuapp.com/
Figure 3.18: The feedback on the clarity dimension for an RDF mapping returned by EvaMap.
3.4
Generating RDF Mappings with a
Semi-Automatic Tool
As we have seen previously, writing RDF mappings is not easy. Consider the Roman Emperor dataset in Table 3.1 and Figure 3.1 that represents an RDF mapping for this dataset. Writing this mapping requires to answer several questions, for instance: (i) what concepts contain the Name and Birth city columns? In this case, Name contains entities that are Persons (emperors) and Birth city contains entities that are Places (cities). (ii) What are the relationships between these two concepts? Here, Places are birth places of Persons. (iii) Which existing ontologies are relevant to describe these concepts? In this example, DBpedia, GeoNames, etc.
Answering these questions requires two types of skills. It requires, to know the dataset perfectly (i.e., its structure, context, meaning, etc.) and to be familiar with RDF concepts such as RDFS, OWL, and RDF mapping languages. Unfortunately, many data producers are not familiar with RDF and are not yet ready to invest time to integrate their data. In this work, we focus on how to simplify as much as possible the integration of existing structured datasets as Linked Data. The challenge we face is to automate part of the integration process that requires getting familiar with RDF.
Even if there exist simplified and human-readable syntaxes of mapping languages like YARRRML [28], writing a mapping requires to be familiar with RDF. Recently, interesting tools have been proposed to assist users during the creation of an RDF mapping. These tools use different representations of the mapping to hide the complexity of RDF mapping languages. KARMA [24] and RMLeditor [29] represent the mapping as a graph while Juma [33] uses a puzzle block metaphor to avoid misuse of RDF mapping languages terms. KARMA also uses machine learning to
automatically generate parts the RDF mappings that are common to previously integrated datasets. Figures3.19,3.20, and3.21respectively show the user interface of KARMA, RMLeditor, and Juma.
Figure 3.19: The user interface of KARMA.