THESE
En vue de l’obtention du
DOCTORAT DE L’UNIVERSITE DE TOULOUSE
Délivré par l’UNIVERSITE DE TOULOUSE III – Paul SABATIERS
pécialité :INFORMATIQUE
Par
Mohamed Mbarki
GESTION DE L’HETEROGENEITE DOCUMENTAIRE :
LE CAS D’UN ENTREPOT DE DOCUMENTS
MULTIMEDIA
Soutenue le 8 février 2008, devant le jury composé de :
Mr Mohand Boughanem Professeur à l’Université Toulouse III Examinateur
Mr Faïez Gargouri Maître de Conférences HDR à l'ISIM de Sfax Examinateur
Mr Jean-Marie Pinon Professeur à l’INSA de Lyon Rapporteur
Mr Ioan Roxin Professeur à l'Université de Franche-Comté Rapporteur
Mme Chantal Soulé-Dupuy Professeur à l’Université Toulouse I Directrice de thèse Mme Nathalie Vallès-Parlangeau Maître de Conférences à l’Université Toulouse I Co-encadrante
INSTITUT DE RECHERCHE EN INFORMATIQUE DE TOULOUSE
THESE
En vue de l’obtention du
DOCTORAT DE L’UNIVERSITE DE TOULOUSE
Délivré par l’UNIVERSITE DE TOULOUSE III – Paul SABATIERS
pécialité :INFORMATIQUE
Par
Mohamed Mbarki
GESTION DE L’HETEROGENEITE DOCUMENTAIRE :
LE CAS D’UN ENTREPOT DE DOCUMENTS
MULTIMEDIA
Soutenue le 8 février 2008, devant le jury composé de :
Mr Mohand Boughanem Professeur à l’Université Toulouse III Examinateur
Mr Faïez Gargouri Maître de Conférences HDR à l'ISIM de Sfax Examinateur
Mr Jean-Marie Pinon Professeur à l’INSA de Lyon Rapporteur
Mr Ioan Roxin Professeur à l'Université de Franche-Comté Rapporteur
Mme Chantal Soulé-Dupuy Professeur à l’Université Toulouse I Directrice de thèse Mme Nathalie Vallès-Parlangeau Maître de Conférences à l’Université Toulouse I Co-encadrante
INSTITUT DE RECHERCHE EN INFORMATIQUE DE TOULOUSE
La société de la connaissance est basée sur trois axes : la diffusion et l’usage de l’information via les nouvelles technologies, la déduction des connaissances induites par cette information et les impacts économiques qui peuvent en découler. Proposer aux acteurs et plus particulièrement aux "décideurs" de cette société des outils qui leur permettent d’élaborer de la "connaissance" ou du moins des "éléments de connaissance" à partir de l’information disponible semblent être assez difficile à assurer. Cette difficulté est due au dynamisme de l’environnement et la diversité des facteurs influençant la production, l’extraction et la communication des informations. En effet, ces informations sont englobées dans des documents qui sont collectés à partir des sources disséminées (Internet, Workflow, bibliothèques numériques, etc.). Ces documents sont ainsi hétérogènes sur le fond et sur la forme (ils peuvent concerner des domaines divers, sont plus ou moins structurés, peuvent être liés à des structures diverses, contiennent plusieurs type de média, sont stockés dans plusieurs type de supports, etc.). Les défis actuels sont de concevoir de nouvelles applications pour exploiter cette grande masse de documents très hétérogènes. Les travaux présentés dans cette thèse, visent à faire face à ces défis et notamment à proposer des solutions permettant de "gérer et créer de la connaissance" à partir de l’intégration de toute l’information disponible sur les documents hétérogènes. La manipulation des entrepôts de documents multimédia constitue le cadre applicatif de nos propositions. Notre approche s’articuler autour de trois axes complémentaires : (1) la représentation, (2) le stockage (ou l’intégration) et (3) l’exploitation des documents hétérogènes.
La représentation des documents concerne la détermination des informations à conserver et la façon selon laquelle elles doivent être organisées pour mieux appréhender et prévoir leurs usages. La solution que nous avons choisie pour répondre à ces besoins se base sur la proposition d’un modèle qui intègre plusieurs niveaux de description imbriqués et complémentaires (une couche générique et une couche spécifique, une description logique et une description sémantique).
Afin de gérer des documents hétérogènes, il faut pouvoir les stocker dans l’entrepôt selon le modèle proposé. Nous élaborons ainsi un processus d’intégration qui permet de définir des méthodes d’extraction de structures des documents à intégrer, de vérifier l’existence de structures identiques ou de structures approchantes dans l'entrepôt (comparaison de structures et classification automatique), d’offrir la possibilité de définir des règles de transformation des structures (classification dirigée), de proposer librement la composition de nouvelles structures et d’insérer les contenus de documents.
Pour assurer l’exploitation des documents intégrés, nous proposons des outils permettant de manipuler aussi bien la structure que le contenu (accès sémantique) par le biais de deux techniques complémentaires : (1) la recherche d’information documentaire qui permet de trouver des granules documentaires ou des documents entiers selon des critères de recherches bien spécifiques. (2) L’analyse multidimensionnelle qui consiste à visualiser les informations documentaires de l’entrepôt selon plusieurs dimensions.
La validation de nos propositions se base sur la réalisation d’un outil de gestion d'entrepôt de documents multimédia intitulé MDOCREP (Multimedia DOCument REPository). Ce prototype permet de gérer des entrepôts de documents multimédia en assurant notamment l’intégration, la classification, l’interrogation et la visualisation multidimensionnelles des documents. La fiabilité du notre approche et la performance de ce prototype ont été validées à travers l’utilisation d’un corpus formé par des documents hétérogènes extraits de sources diverses et qui ne sont pas associés à un domaine particulier.
Mot clés :
Hétérogénéité documentaire, entrepôt, modélisation, extraction de structure, classification, comparaison de structures, adaptation de structures, intégration de structure, intégration de contenu, exploitation, recherche documentaire, analyse multidimensionnelle.
A mon père
Paix à son âme
Je tiens à remercier très sincèrement Messieurs Claude Chrisment et Gilles Zurfluh, responsables de l’équipe « Systèmes d’Informations Généralisées (SIG) », pour m’avoir accueilli au sein de leur équipe afin de mener à bien cette étude.
Je présente ma reconnaissance envers Madame Chantal Soulé-Dupuy professeur à l'Université Toulouse I qui a accepté sans réserve de diriger cette thèse. Elle s’y est grandement impliquée par ses directives, ses remarques et suggestions. Je tiens à la remercier aussi pour la liberté qu’elle m'a laissée dans la conduite de ma recherche. J'ai admiré ses qualités scientifiques, pédagogiques, mais surtout humaines. Merci d’avoir guidé mes premiers pas dans le chemin de la recherche.
Mes remerciements vont également à Madame Natalie Vallès-Parlangeau, maître de conférences à l'Université Toulouse I pour avoir encadré et suivi cette étude, pour ses conseils judicieux, ses lectures minutieuses et aussi pour ses encouragements dans les moments clés de son élaboration. J'ai puisé un grand nombre d'idées dans mes conversations avec elle. Ses remarques pertinentes m’ont amené à reconsidérer ma position et réviser bien des points.
Mes remerciements les plus respectueux vont à Messieurs Jean-Marie Pinon, professeur à l’INSA de Lyon et Ioan Roxin, professeur à l’Université de Franche-Comté qui m’ont fait l’honneur d’évaluer cette thèse et d’en être rapporteurs. Je les remercie pour leurs conseils et leurs suggestions qui ont permis l’amélioration de ce manuscrit.
Mes remerciements vont également à Messieurs Faïez Gargouri, maître de conférences HDR et directeur de l’ISIM de Sfax et Mohand Boughanem, professeur à l’Université Paul Sabatier pour avoir accepté d’examiner mes travaux de recherche. Je les remercie pour l’honneur qu’ils me font en participant à mon jury.
Les encouragements de mes amis, de mes collègues Baccar, Karim, Yessin, Houssem, Moultazem, les Anis (Oubada, Gaddour et Jedidi), Faiza, Samiha, Lotfi, Manel, Fredj, Wissem, Wassim, Kaïs, Hamid, Lobna, Bouchra, Estella, Desiré, Dana, Ronan, Guillaume et bien d’autres encore, étaient la bouffée d’oxygène qui me ressourçait dans les moments pénibles, de solitude et de souffrance, où l’on a terriblement besoin d’un petit mot, d’un petit geste, aussi humble soit-il, de soutien moral.
Mes collègues Karim et Wassim sont cordialement remerciés pour m’avoir détaché des mes charges pédagogiques durant deux mois. Merci à Karim qui était toujours un bon collègue et ami dans le bureau, dans les réunions de travail et en dehors de l'IRIT.
Je voudrais rendre hommage à mes professeurs qui ont contribué à ma formation de loin ou de près, en France ou en Tunisie.
Merci à mon père qui m’a beaucoup appris, qui m’a toujours encouragé et rêvé de me voir docteur et que dieu a voulu qu'il nous laisse juste quelques mois avant ma soutenance. Que son âme repose en paix. Merci à mon adorable mère, à celle qui a toujours été présente et continue de l’être pour faire mon bonheur. Merci pour t’être sacrifiée pour que tes enfants grandissent et prospèrent. Merci aussi à mes sœurs chéries Asma, Amel et Ikram d’être toujours à mes côtés et qui par leurs présence et leurs amour ont donné du goût et un sens à notre vie de famille. Je ne manquerai pas de dire un grand merci à mon beau-frère Hammadi et à mon très cher ami Baccar (mon frérot). Qu'ils trouvent avec ceci un modeste geste de reconnaissance et de remerciement. Enfin, je tiens à remercier ma future femme (inchallah) Feryel pour son soutien constant et sa présence malgré la distance merci pour ton courage, ton appui sans limite, ta persévérance et ta compréhension.
Sommaire
Introduction Générale………1
PREMIERE PARTIE - DOCUMENTS MULTIMEDIA : PRESENTATION ET ETAT DE L’ART SUR LES APPROCHES DE GESTION Chapitre I - Documents multimédia : concepts de base I.1. Introduction... 13
I.2. Document : du textuel vers le multimédia... 13
I.2.1. Définition et évolution du concept de "document"...13
I.2.2. Document multimédia : définition et composition...14
I.3. Les structures documentaires ... 16
I.3.1. Typologie des structures documentaires...16
I.3.2. Bilan sur la typologie des structures documentaires ...20
I.3.3. Les différentes représentations de structures...20
I.3.4. Bilan sur les représentations de structures...23
I.3.5. Les enjeux de la structuration...23
I.4. Les standards documentaires...27
I.4.1. Les standards de structuration...27
I.4.2. Bilan sur les standards de structuration ...35
I.4.3. Les standards de description...37
I.4.4. Bilan sur les standards de description ...43
I.5. Conclusion sur les concepts de base...43
Chapitre II - Gestion des documents multimédia : Etat de l’art II.1. Introduction...49
II.2. Indexation de documents multimédia...50
II.2.1. Exemples de descripteurs...50
II.2.2. Bilan sur les descripteurs...52
II.2.3. Exemples de projets d’indexation...53
II.3. Modélisation de documents multimédia ...56
II.3.1. Exemples de modélisation de documents multimédia ...57
II.3.2. Bilan sur la modélisation des documents multimédia...62
II.4. Construction d’espaces de stockage et intégration de documents ...63
II.4.1. Les étapes de construction d’un espace de stockage...63
II.4.2. Les types d’intégration...65
II.4.3. La comparaison de structures...65
II.4.4. Bilan sur la comparaison de structures...68
II.5. Interrogation de documents...69
II.5.1. Les langages de requêtes spécifiques ...71
II.5.2. Les langages de requêtes issus de SQL ...73
II.5.3. Bilan sur les langages de requêtes ...77
II.6. Conclusion...78
DEUXIEME PARTIE - GESTION DE L’HETEROGENEITE DOCUMENTAIRE : PROPOSITION D’UN MODELE GENERIQUE ET APPLICATION AU CAS DES ENTREPOTS DE DOCUMENTS Chapitre III - Un modèle générique de représentation de documents multimédia III.1. Introduction...87
III.2. Modélisation des documents multimédia...88
III.2.1. Gestion de l’hétérogénéité intra document...88
III.2.2. Gestion de l’hétérogénéité inter documents ...95
III.2.3. Notre modèle de représentation des documents multimédia...101
III.3. Démarche de classification des documents... 107
III.3.1. Extraction de structures spécifiques ...109
III.3.2. Comparaison de structures...110
III.3.3. Adaptation des structures ...126
III.4. Conclusion... 129
Chapitre IV Validation - Proposition d’un outil de gestion d’entrepôts de documents multimédia IV.1. Introduction... 135
IV.2. Cadre applicatif ... 136
IV.2.1. Entrepôt de documents : définitions et objectifs...136
IV.2.2. Architecture de MDOCREP : un outil de gestion d’entrepôts de documents multimédia...137
IV.3. Intégration de documents ... 140
IV.3.1. Exemples de mise en œuvre du processus d'intégration...144
IV.3.2. Expérimentations et discussion sur la classification ...151
IV.4. Exploitation de l'entrepôt ... 160
IV.4.1. Recherche d’information documentaire ...160
IV.4.2. Analyse multidimensionnelle...164
IV.5. Conclusion... 183
Conclusion Générale..………185
Liste des publications..………..193
Bibliographie………..195
Annexes……… 205
Table des figures………243
Table des tableaux.………247
Glossaire...…...………248
1. Contexte et problématique
Le document électronique représente aujourd’hui un vecteur et un support d’information que les organisations doivent apprendre à ne plus négliger si elles veulent être sûres d’identifier et de gérer toutes les données qui leur sont utiles au quotidien. En effet, il est entendu aujourd’hui que plus de la moitié des données nécessaires au fonctionnement d’une organisation sont encapsulées dans des documents, et non uniquement présentes dans les bases de données opérationnelles. En conséquence, ces organisations sont confrontées à la gestion d’un volume croissant de données provenant de sources disséminées, d’applications différentes et ayant des structures souvent hétérogènes. Une gestion optimisée de ces données, et en particulier des documents qui les encapsulent, est essentielle. Les organisations ne peuvent réaliser pleinement la valeur ajoutée que représentent ces informations (données, documents, etc.), à moins qu’elles ne puissent les intégrer efficacement à différents systèmes et les échanger d’un système à un autre, pour les exploiter et les acheminer vers la bonne personne et de la meilleure façon. Or leur intégration demeure encore aujourd’hui une des difficultés majeures, en amont même de tout processus d’analyse et d’exploitation.
Pour gérer efficacement ces documents et données, il est indispensable d’avoir une vue d’ensemble du processus, en considérant tous les aspects, de la modélisation à l’exploitation en passant par le stockage, sans perdre de vue l’aspect hétérogénéité. L'hétérogénéité de ces documents se trouve à deux niveaux :
- sur le fond, les documents peuvent concerner des domaines très divers. L’utilisateur doit fouiller et parcourir les documents pour trouver l’information utile ;
- sur la forme, les documents peuvent être plus ou moins structurés, de formats standards ou non, et de structures différentes. L’utilisateur doit ainsi disposer d’outils adéquats pour visualiser et/ou exploiter l’information.
Les défis que nous nous proposons de relever dans cette thèse concernent la conception de nouvelles approches pour gérer ces grandes masses de documents hétérogènes, en faciliter l’accès et la manipulation.
2. Propositions et contributions
Nos contributions se situent dans le cadre de la modélisation et de l’intégration de documents hétérogènes dans le but d’en faciliter l’exploitation. Nous cherchons notamment à spécifier de nouvelles méthodes et de nouveaux outils pour la modélisation, le stockage et l'exploitation
des fragments d’information contenus dans ces documents.
En amont du stockage de documents, des recherches sur les informations à conserver, et sur la façon selon laquelle elles doivent être organisées, sont nécessaires afin de mieux appréhender et prévoir leurs usages. L’approche que nous avons choisie pour répondre à ces besoins se base sur la proposition d’un modèle qui permette de :
- décrire n'importe quel type de données (structurées, semi-structurées et non structurées) ; - supporter n’importe quel type de média (texte, image, son, vidéo) ;
- supporter plusieurs structures et tout type de fragmentation de documents ;
- représenter et décrire les fragments ou granules de documents qui composent les documents ;
- décrire le contenu des documents par des ensembles non-prédéfinis de métadonnées ; - classer les documents ayant des structures similaires ou approchantes (par exemple, classe des curriculum vitae, classe des flashs d’informations, classe des réponses à des appels d’offres, etc.).
L’instanciation de ce modèle, pour la constitution d’un espace de stockage via un système de gestion de documents hétérogènes, doit alors garantir la classification de ces documents tout en préservant leurs spécificités (structurelles notamment). La démarche de classification que nous proposons intègre des méthodes de fragmentation et d’extraction de structures de documents, ainsi que des algorithmes de comparaison de structures de documents. Il s’agit en particulier de comparer la structure du document à intégrer avec les structures qui existent déjà dans l'espace de stockage. Cette comparaison permet de vérifier l’existence de structures identiques ou approchantes, d’étudier les adaptations à réaliser sur des structures ou de conclure à la création de nouvelles structures.
Par la suite, l’exploitation des documents et des granules de documents peut reposer aussi bien sur la structure que sur le contenu (accès sémantique) des documents modélisés. Les spécificités du modèle proposé élargissent ainsi les possibilités d’exploitation des documents par le biais de deux processus complémentaires :
(1) un processus de recherche d’information documentaire impliquant la structure des documents et/ou le contenu des granules de documents. Ce processus permet de rechercher et restituer des passages de documents en réponse à une requête utilisateur composée généralement de mots-clés décrivant la structure des documents et/ou le contenu des granules. Ce processus permet ainsi de restituer des granules documentaires ou des documents entiers (selon le niveau de précision souhaité par l’utilisateur) qui vérifient des critères de recherches bien spécifiques ; (2) un processus d’analyse multidimensionnelle. Ce processus consiste à permettre d’analyser les informations modélisées et stockées selon des dimensions non prédéfinies. L’objectif est d’agréger et de visualiser d’une manière graphique et synthétique le contenu d’une grande masse documentaire en présentant le sujet d’analyse selon plusieurs axes. Le choix des paramètres, sujets et axes d’analyses, doit être souple et dynamique.
Dans le cadre de cette thèse, nous présentons une application des approches de modélisation, de classification et d’exploitation proposées via la mise en œuvre d’un outil de gestion de documents multimédia hétérogènes. Cet outil appelé MDOCREP, pour Multimedia DOCument REPository, repose sur la conception d’un entrepôt de documents visant à structurer l’ensemble des informations contenues dans des collections de documents, à les consolider et à permettre leur exploitation. Au travers de cet outil nous avons pu valider l’ensemble de nos propositions dans la mesure où il permet d’instancier le modèle proposé et d’assurer la gestion d’entrepôts de documents multimédia en intégrant les démarches de classification et d’exploitation du contenu de l'entrepôt. La fiabilité du notre approche et les performances de ce prototype ont été
démontrées à travers l’utilisation d’un corpus composé de documents extraits de sources diverses associés à plusieurs domaines. Il s’agit de documents, éventuellement annotés, fournis dans le cadre de benchmarks ou de projets portant sur des contenus hétérogènes : émissions radio, sites web et autres.
3. Organisation du mémoire
Comme le résume la figure suivante, ce mémoire est décomposé en deux grandes parties chacune comprenant deux chapitres.
La première partie introduit et décrit tout le contexte de nos travaux et constitue un état de l’art des domaines abordés dans le cadre de notre thèse. La seconde partie présente nos principales contributions et décrit le cadre de leur validation.
Le premier chapitre traite l'évolution de concept document, du texte vers le multimédia, et aborde ensuite la description des documents multimédia. Nous présentons également dans ce chapitre un panorama des typologies et des méthodes de représentation des structures de documents sur lesquelles repose la description de l'organisation et du contenu des documents. Nous introduisons à ce niveau les concepts de semistructuralité et de multistructuralité. La dernière section de ce chapitre est consacrée à un tour d'horizon des standards documentaires qui permettent de gérer la représentation et la description des documents.
Le deuxième chapitre présente un état de l'art des travaux qui ont été réalisés dans le cadre de la modélisation, du stockage et de l'exploitation de documents multimédia hétérogènes. Dans une première section, nous passons en revue quelques exemples de descripteurs et de projets d'indexation classés par type de medium traité. Une deuxième section dresse un panorama des modèles de représentation de documents multimédia. Ces travaux de modélisation reposent sur les principes d’indexation introduits précédemment. Une troisième section introduit et définit les principes généraux d’un processus d'intégration de documents dans un espace de stockage. Sont
plus particulièrement abordées ici quelques approches de comparaison de structures. Dans la dernière section de ce chapitre, nous décrivons quelques langages d’interrogation de documents. Le troisième chapitre est dédié à la présentation de nos travaux concernant la modélisation de documents multimédia et visant à gérer l'hétérogénéité documentaire. Pour gérer l’hétérogénéité intra-document, nous proposons d’utiliser une dichotomie entre structures et contenus des documents. Il s’agit de traduire séparément l’organisation structurelle des fragments de documents multimédia et la sémantique du contenu de chacun d’eux. Pour gérer l’hétérogénéité inter documents, nous proposons une démarche de classification basée sur une comparaison et le calcul d’un degré de ressemblance entre structures de documents afin de créer des structures génériques qui traduisent des organisations communes à des ensembles de structures similaires. Le modèle générique proposé, ainsi que la démarche de classification étudiée sont décrits dans ce chapitre.
Le quatrième chapitre présente le cadre applicatif qui a été choisi, les développements réalisés ainsi que les validations effectuées. Dans un premier temps, nous définissons le concept d’entrepôt de documents qui constitue le cadre applicatif et nous détaillons les objectifs associés. Nous présentons ensuite l’architecture de l’outil de gestion de documents multimédia MDOCREP (Multimedia DOCument REPository) qui a été développé. Nous focalisons ensuite ce chapitre sur les deux modules qui nous ont permis de valider les propositions décrites dans le chapitre précédent. Le premier met en œuvre la démarche de classification et de stockage dans l’entrepôt de documents multimédia hétérogènes. Le deuxième module permet l’exploitation du contenu de l’entrepôt par le biais de deux processus complémentaires : recherche d’information documentaire et analyse multidimensionnelle. Nous décrivons notamment les résultats des expérimentations réalisées avec MDOCREP.
Nous concluons ce mémoire en rappelant nos contributions, les apports et l’originalité de notre travail, en précisant ses limites et les perspectives de recherche envisageables.
PREMIERE PARTIE :
DOCUMENTS MULTIMEDIA : PRESENTATION ET
ETAT DE L’ART SUR LES APPROCHES DE GESTION
Chapitre I
I.1. Introduction... 13 I.2. Document : du textuel vers le multimédia... 13
I.2.1. Définition et évolution du concept de "document" ...13 I.2.2. Document multimédia : définition et composition...14
I.3. Les structures documentaires ... 16
I.3.1. Typologie des structures documentaires...16 I.3.1.1. Structure logique...16 I.3.1.2. Structure physique ...17 I.3.1.3. Structure spatiale...18 I.3.1.4. Structure temporelle...18 I.3.1.5. Structure sémantique...19 I.3.1.6. Autres types de structures ...20 I.3.2. Bilan sur la typologie des structures documentaires ...20 I.3.3. Les différentes représentations de structures...20 I.3.3.1. Représentation sous forme de liste ...21 I.3.3.2. Représentation sous forme d’arbre ...22 I.3.3.3. Représentation sous forme de forêt...22 I.3.3.4. Représentation sous forme de graphe ...23 I.3.4. Bilan sur les représentations de structures...23 I.3.5. Les enjeux de la structuration...23 I.3.5.1. Les données semi-structurées ...24 I.3.5.2. Les documents multi-structurés ...24
I.4. Les standards documentaires...27
I.4.1. Les standards de structuration...27 I.4.1.1. SGML et HYTIME...27 I.4.1.2. HTML ...30 I.4.1.3. XML et ses langages complémentaires...31 I.4.1.4. XHTML ...33 I.4.1.5. SMIL...34 I.4.2. Bilan sur les standards de structuration ...35 I.4.3. Les standards de description ...37 I.4.3.1. IPTC ...37 I.4.3.2. Dublin Core (DC)...38 I.4.3.3. RDF ...39 I.4.3.4. XMP ...40 I.4.3.5. MPEG-7...41 I.4.4. Bilan sur les standards de description ...43
I.1. Introduction
Le concept de document a connu des mutations profondes : d’une part, les contenus textuels ont été enrichis par d’autres types de média (image, son, audiovisuel, etc.) et d’autre part, le développement rapide des technologies numériques a modifié considérablement les conditions de stockage et de consultation de ces documents. Au croisement de ces mutations émerge la problématique de la gestion des documents numériques multimédia.
Nous commençons ce chapitre par suivre ces deux mutations dans le temps à travers l’évolution du concept de document. Nous présentons ensuite les composants de base d’un document multimédia.
Cette présentation nous renvoie à de nombreux enjeux concernant la gestion de l’aspect hétérogène des documents multimédia. Pour assurer cette gestion et afin de décrire les documents multimédia et les différentes relations qui décrivent leur composition, plusieurs types de structures (logique, physique, temporelle, etc.) peuvent être utilisés. Nous consacrons la troisième section à un tour d’horizon de ces types de structures et leurs représentations (liste, arbre, graphe, etc.). L’étude de la typologie structurelle nous a amené à évoquer des problèmes concernant deux aspects : celui de multi-structuralité et celui de semistructuralité.
Les résolutions de tels problèmes se basent sur l’utilisation des standards documentaires qui permettent de gérer d’une manière uniforme :
(1) la présentation des structures globales de document ;
(2) la description des contenus en utilisant notamment des métadonnées.
Ces standards contribuent à la mise en place d’une gestion flexible des structures des documents : les documents normalisés sont plus largement diffusables et exploitables (réutilisation, adaptation, collaboration, etc.). Un panorama des standards les plus utilisés sera présenté dans la dernière section de ce chapitre. Nous commençons cette dernière section par présenter les standards de structuration. Nous la clôturons par la définition de métadonnées ainsi que les différentes standards de description qui gèrent l’organisation de ces métadonnées afin d’assurer une présentation détaillée et précise de contenus des documents multimédia.
I.2. Document : du textuel vers le multimédia
La numérisation a permis la dématérialisation de documents : le conteneur de documents est passé du papier aux supports magnétique et électronique. En même temps, le document, classiquement textuel, a pu s’enrichir d’éléments issus d’autres média. Dans cette section, nous présentons l’évolution du concept de "document". Nous présentons également les média de base qui peuvent être englobés dans un document multimédia.
I.2.1. Définition et évolution du concept de "document"
Une définition générique du concept de "document" est donnée par le Larousse : « tout renseignement écrit ou objet servant de preuve ou d’information ».
Cette définition met en avant deux points : L’aspect informationnel et l’aspect matériel du document. L’aspect matériel concerne le support de l’information, donc son stockage. Un des aspects important est aussi l’échange. Cet aspect est abordé dans la définition de [Blasselle B., 1997], qui mentionne qu’un document permet d’assurer la « transmission de connaissance, de savoir et d’information ». Cette capacité de transmission est assurée par la présentation de l’information sous une forme persistante et portative du contenu, qui est classiquement le support papier. Grâce à la numérisation, les formes de stockage ont connu des évolutions en passant du format papier classique au format électronique. Ce format offre des capacités de sauvegarde et des possibilités d’échanges nettement plus importantes. Il a conféré au document de nouvelles capacités aussi bien au niveau du contenu informationnel qu’au niveau des traitements possibles. Dans un tel document, l’information véhiculée intègre du texte, des images fixes ou animées, des graphiques, du son, de la vidéo, etc. En outre, un document électronique ne se contente plus de remplir les fonctionnalités d’un simple document papier, il permet d’offrir d’autres possibilités de gestion tels que : une restitution selon différents formats, une communication avec d’autres systèmes informatiques (échanges, partage, etc.), des recherches d’informations, etc. [Dupoirier G., 1995].
La numérisation des documents a ainsi amené à des nouvelles définitions du terme document comme celle donnée par l'ISO (International Organization for Standardization) : « Un document est l’ensemble d’un support d’information et des données enregistrées sur celui-ci sous forme en général permanente et lisible par l’homme et la machine ». Contrairement au document matériel traditionnel, l'accès à l'information sur les supports numériques n'est jamais direct. « Il passe au minimum par le décodage d'une représentation sous forme binaire de l'information pour en proposer une présentation sous une forme sémiotique lisible » [Bachimont B. et Crozat S., 2004]. Le document numérique peut être considéré ainsi comme une reconstruction dynamique d’un document matériel.
Le remplacement des formes matérielles (le support papier) par des formes immatérielles (électroniques ou numériques) présente plusieurs avantages : gains de temps et d'espace, amélioration de la réactivité, réduction des coûts de stockage et d’échange, etc. Rapidement sont venus s'ajouter aux documents issus de la numérisation, des documents directement créés sous forme numérique (éditions informatiques ou bureautiques, messages électroniques, etc.). Le document est donc devenu de plus en plus riche et complexe en intégrant des contenus multimédia (texte, vidéo, image, graphique, son, etc.). Ces contenus sont regroupés dans ce que l’on appelle désormais des documents multimédia.
I.2.2. Document multimédia : définition et composition
Le terme "multimédia" se rapporte à une communication à travers plusieurs types de média utilisés conjointement. En se référant à la définition du concept de "document", nous pouvons définir un document multimédia comme étant l’agencement interactif dans le temps et dans l’espace d’éléments distincts de natures différentes (issus de plusieurs types de média) afin d’enrichir le contenu de l’information diffusée.
Les média peuvent être vus ainsi comme les briques fondatrices des documents multimédia. Un medium est définit comme « un type de données abstrait c’est à dire une description d'une structure de données
ainsi qu'un ensemble d'opérations définies sur ces données telles que les opérations pour la saisie et la présentation de données » [Apers P. M. G. et al., 1997]. Les média les plus utilisés sont : le texte, l’audio, l’image et la vidéo. Nous présentons dans cette section une définition générale de chaque média. De plus amples informations concernant leurs manipulations seront détaillées dans le chapitre suivant.
• Le Texte
Un texte est une succession organisée de chaînes de caractères. La représentation et le traitement du medium texte sont assurés par plusieurs standards tels que RTF (Rich Text Format), PDF (Portable Document Format), Text, LaTeX (Lamport TEX). Ces standards sont essentiels, car ils permettent de réaliser sur le document électronique des manipulations fastidieuses à effectuer sur un support papier, d’assurer l’intégrité, la réutilisabilité et la portabilité lors d’échanges de documents, et donc de favoriser le partage de documents. La notion d’hypertexte apporte la notion de navigation au sein des documents et entre documents. Elle permet au lecteur de se détacher du parcours discursif prévu par l’auteur, pour adopter un parcours du document personnalisé, non-linéaire, qui peut être non-exhaustif.
• L’audio
Le son ou l’audio est un medium très populaire. En fait, le son numérique est le résultat des phases d’échantillonnage et de quantification d’un signal continu produit par une source sonore. Il se caractérise par un certain nombre de paramètres comme la fréquence d’échantillonnage, la taille de l’échantillon, le pas de quantification, le nombre de canaux utilisés, etc. Par ailleurs, le son requiert de gros volumes ce qui explique pourquoi nous le trouvons généralement sous une forme compressée. Parmi les formats audio les plus connus, nous citons le format Wave (WAVEform audio format) de Microsoft et le format MP3 (MPeg-1 audio layer 3).
La modalité sonore peut prendre différentes formes : parole, musique, bruit, etc. Ce medium peut jouer différents rôles dans le document : source d’information supplémentaire ou complémentaire, agrément, canal de sortie supplémentaire lorsque les interfaces visuelles classiques sont saturées, aide aux handicapés visuels, alarme, etc.
• L’image
L’image est un medium fondamental pour de nombreux domaines professionnels tels que la météorologie, la production de films, les publications, la télédétection, etc. Par image, on entend image numérique, c’est à dire une image qui se présente sous la forme d’une matrice de pixels ou sous une forme vectorielle. Nous parlons également d’image au format matriciel ou raster.
Une image peut être présentée et codée selon plusieurs formats [Roxin I. et Mercier D., 2004]. Parmi les plus répandus, nous pouvons citer les formats BMP (BitMaP), JPEG (Joint Photographic Experts Group), TIFF (Tagged Image File Format), PNG (Portable Network Graphics), SPIFF (Still Picture Interfrange File Format), etc.
• La vidéo
appelées "frames" et d’une bande sonore synchronisée. Les "frames" résultent soit des phases d’échantillonnage et de quantification d’un signal vidéo analogique, soit de programmes informatiques générant des images de synthèse. La vidéo se caractérise plutôt par les paramètres de fréquence d’échantillonnage, de taille d’échantillon, de pas de quantification, de taux d’images, etc.
Une vidéo peut être présentée dans plusieurs conteneurs ("Containers"). Les conteneurs les plus répandus sont MPEG (Moving Pictures Experts Group) et AVI (Audio Video Interleaved) de Microsoft. Il s’agit du medium le plus coûteux en terme de stockage et par conséquent il requiert encore plus de compression que les autres média.
I.3. Les structures documentaires
Un des problèmes à résoudre aujourd’hui est la gestion de l’agencement et de l’organisation de ces différents média pour assurer un stockage et une exploitation aisés des documents multimédia. La définition et l’utilisation des structures documentaires permettent de faciliter la réalisation de ces objectifs.
Le mot structure vient du latin "struere" qui signifie construire et agencer. Il reflète donc l’idée d’une entité organisée. L’agencement entre les éléments d’un document peut être assuré par plusieurs types de relations. Un document peut être considéré comme étant un ensemble d’éléments organisés hiérarchiquement (selon une organisation logique) et/ou un enchaînement temporel d’éléments (organisation temporelle) et/ou un agencement d’un ensemble de blocs (organisation physique), etc. A chaque organisation correspond un type particulier de structure : ces structures pouvant être représentées suivant plusieurs formes (liste, arbre, graphe, etc.) selon leurs niveaux de complexité. Nous introduisons dans cette section les différents types de structuration d’un document et un panorama de représentations de ces structures.
I.3.1. Typologie des structures documentaires
Nous présentons dans cette section les structures les plus citées dans la littérature. Afin d’illustrer les différences entre ces structures ainsi que leurs spécificités, nous nous appuierons nos exemples sur un même document de base : "Prévisions_météo" (cf. Figure I.1).
I.3.1.1. Structure logique
La structure logique reflète « l’organisation explicite d’abstractions logiques représentant des parties de document » [Fourel F., 1998]. Ces abstractions logiques correspondent généralement à des entités d’informations qui existent indépendamment les unes des autres du fait qu’elles contiennent suffisamment d’informations pour être compréhensibles. La structure logique permet un découpage de l’information d’un point de vue hiérarchique selon un principe de décomposition plus ou moins fin. Ce mécanisme impose d’identifier de façon non ambiguë les granules d’information composant le document. L’organisation de cette structure est explicite et elle est définie a priori.
La structure logique des documents s’appuie sur 3 entités [Roisin C., 1999] : (1) les éléments de base non décomposables qui constituent le contenu ;
(2) les éléments composites obtenus par composition d’éléments de base ou d’autres éléments composites ;
(3) les attributs qui peuvent être associés aux éléments pour leur adjoindre des informations supplémentaires.
Figure I. 1. Document "Prévisions_météo"
La figure I.2 présente la structure logique du document de base (figure I.I). Ce document est constituée d’un "titre", d’une "Date", d’une ou plusieurs "Ville" (d’après la cardinalité "+"), d’une "Photo" et d’une "Présentation-Audio". Cette structure indique aussi que chaque ville est composée par les éléments "Nom", "Température" et "Vent". Chaque "Température" est composée de deux autres éléments (celle prise le "Matin" et celle prise l’après-midi "Ap-midi"). L’élément "Vent" est composé des éléments "Direction" et "Force".
Figure I. 2. Structure logique du document "Prévisions_météo"
I.3.1.2. Structure physique
La structure physique correspond à l’organisation des éléments de la structure logique sur un support de présentation. Cette organisation dépend alors essentiellement du média de diffusion (écran, papier, etc.). Elle permet de traduire un ensemble de règles de présentation (succession de
lignes, de paragraphes, de pages, de blocs, de caractères typographiques, etc.). La structure physique de notre page météo est présentée dans la figure I.3.
Figure I. 3. Structure physique du document " Prévisions_météo"
I.3.1.3. Structure spatiale
La structure spatiale exprime les contraintes d’ordonnancement des différentes parties d’un document sur le support de présentation. Elle permet donc de définir la taille des différentes zones, les superpositions, les juxtapositions, etc. La structure spatiale du document est la suivante.
Figure I. 4. Structure spatiale du document "Prévisions_météo"
I.3.1.4. Structure temporelle
La structure temporelle permet de décrire l’enchaînement des éléments du document dans le temps. Certains de ces éléments peuvent avoir eux aussi leurs propres dimensions temporelles
(vidéo, audio). La figure I.5 présente la structure temporelle du document. Cette structure montre par exemple que :
(1) l’apparition de la photo (la carte) s’effectue 15 secondes après celle de l’entête et qu’elle va durer jusqu’à la fin de l’affichage du document ;
(2) la présentation textuelle de la deuxième ville ("D_Texte_Ville 2") commence vingt secondes après celle du premier document ;
(3) les présentations textuelles des villes ne disparaissent pas après leurs affichages ;
(4) les présentations audio des villes ("P_Audio_Ville i") se lancent d'une manière séquentielle.
Figure I. 5. Structure temporelle du document "Prévisions_météo"
I.3.1.5. Structure sémantique
La structure sémantique établit une présentation structurée de l'information contenue dans le document. Une structure sémantique pour le document "Prévisions_météo" est présentée dans la figure I.6. Cette structure permet de détailler la description des contenus des éléments "Photo" et "Présentation Audio".
I.3.1.6. Autres types de structures
Avec le développement de nouvelles techniques de communication et d’accès aux informations, il convient d’ajouter à cette typologie les concepts de structure hypermédia [Auffret G., 1999] et
structure hypertexte [Aguiar F. et Beigbeder M., 2004]. Ces structures regroupent l’ensemble des liens que contiennent les documents (lien intra et inter document) et entre les différents types de média.
D’autres structures liées uniquement à des domaines d’études bien spécifiques peuvent être évoquées. Par exemple, [Fourel F., 1998] introduit les structures "linguistique " et "du discours" qui font partie du domaine du traitement automatique des langues. La structure linguistique
permet de fournir des informations d’ordre lexical, morphologique, syntaxique, etc. entre les éléments de contenu des documents. La structure du discours reflète l’organisation qui rend le document compréhensible. L’organisation syntaxique ne garantit pas qu’un document soit compréhensible pour le lecteur, seule l’organisation des idées, c'est-à-dire la structure du discours, peut être le garant de la compréhension du document.
La structure rhétorique [Mann W. C. et Thompson S. A., 1987] [Luc C., 2001] permet de représenter les relations qui relient des segments de texte adjacents entre eux. Deux types de segments peuvent être distingués : les segments primordiaux pour la cohérence (segments noyaux) et les segments optionnels (segments satellites). La structure rhétorique décrit l’organisation structurelle d’un texte, quelque soit le niveau hiérarchique de ce dernier. Elle permet de lier un noyau et un satellite, deux ou plusieurs noyaux entre eux et un noyau avec plusieurs satellites. La structure rhétorique finale d’un texte est strictement hiérarchique et se présente sous la forme d’un arbre RST (Rhetorical Structure Theory).
I.3.2. Bilan sur la typologie des structures documentaires
La description d’une structure de document consiste à identifier chacun des éléments qui le constituent. Cette description peut prendre plusieurs formes. Nous distinguons ainsi une typologie structurelle diversifiée. En commençant par le niveau de description le plus bas, la structure physique correspond à l’organisation de l’information sur un support de présentation. Cette organisation dépend essentiellement du média de diffusion (écran, papier, etc.). La structure logique permet un découpage de l’information d’un point de vue hiérarchique. Elle permet d’identifier de façon non ambiguë les granules d’information (entité) composant le document. La structure sémantique permet de présenter le sens des contenus documentaires. Elle établit une image structurée de l'information contenue dans le document. La structure spatiale exprime les contraintes d’ordonnancement des différentes parties d’un document sur un support de présentation. La structure temporelle permet de décrire l’enchaînement des parties d’un document dans le temps. Certaines de ces parties peuvent avoir elles aussi leurs propres dimensions temporelles (vidéo, audio). D’autres structures liées uniquement à des domaines d’études bien spécifiques peuvent être évoquées (linguistique, de discours, hypermédia, etc.).
I.3.3. Les différentes représentations de structures
niveau de complexité. Un panorama de ces représentations va être présenté dans cette section. Le document qui sera le support de nos exemples décrit un monument historique (cf. Figure I.7).
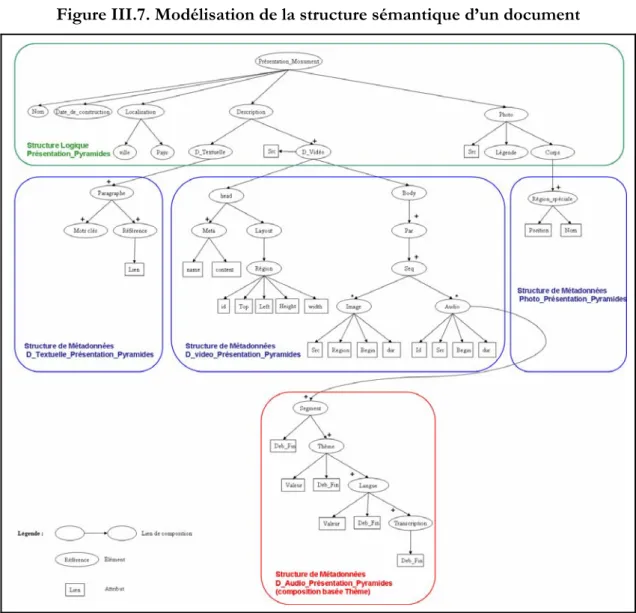
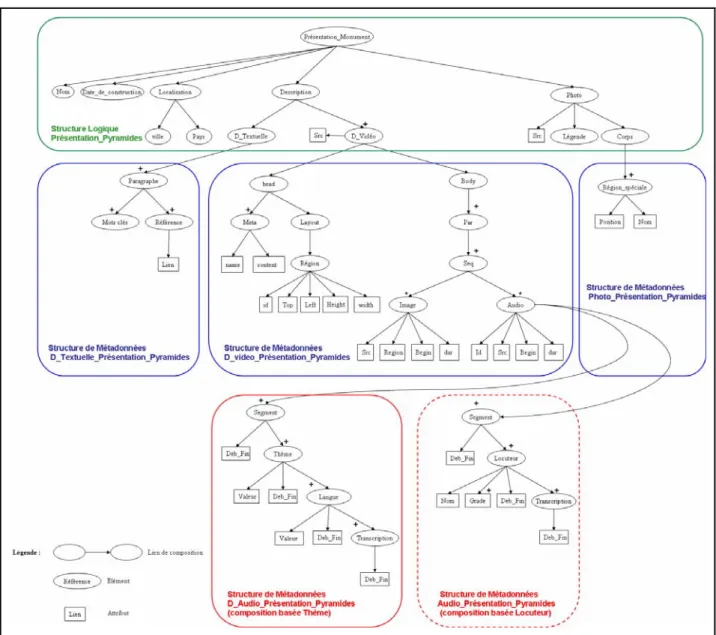
Figure I. 7. Extrait d’un document multimédia "Présentation_Monument"
I.3.3.1. Représentation sous forme de liste
La relation la plus simple est la relation d’ordre. Cette relation séquentielle est traduite par une représentation sous forme de liste c’est-à-dire une succession d’éléments, chacun ayant un rang dans la liste.
I.3.3.2. Représentation sous forme d’arbre
Ce type de représentation permet de prendre en compte les relations hiérarchiques qui s’ajoutent à la relation d’ordre. Ces relations traduisent les inclusions entre les éléments qui forment le document. Le parcours préfixé de l’arbre permet de retrouver l’ordre des éléments de la liste. Une telle représentation permet d’offrir plus de visibilité sur l’organisation générale d’un document.
Présentation_Monument Corps_Présentation Section Titre_Section Corps_Section + Localisation Date_Construction Nom_Monument Entête Photo_Principale Paragraphe +
Figure I. 9. Représentation sous forme d’arbre
I.3.3.3. Représentation sous forme de forêt
Les représentations sous forme de liste et d’arbre induisent un ordre total entre les éléments qui se trouvent dans le même document. Cependant, il existe des éléments juxtaposés indépendants dont la position n’est pas déterminée par rapport à la structure. C’est le cas par exemple d’une présentation audio qui accompagne le texte ou des Photos qui peuvent apparaître à la fin de chaque page (ou bien des liens vers ces photos) sans être incluses forcément dans des paragraphes bien précis (cf. Figure 1.10). Il peut donc être plus judicieux dans ce cas de considérer la structure d’un document comme étant une forêt.
I.3.3.4. Représentation sous forme de graphe
Il peut exister encore d’autres relations à l’intérieur d’un document qu’aucune des représentations précédentes ne peut traduire. C’est le cas des relations de renvois et des références croisées. Ces références n’introduisent pas seulement des liens entre éléments de la structure principale, mais elles peuvent également relier des éléments associés à des structures secondaires. Par exemple, dans les paragraphes, nous pouvons trouver des renvois vers les légendes des photos. Les mots clés de ces légendes peuvent être également reliés aux thèmes de la présentation audio.
Figure I. 11. Structure de graphe
I.3.4. Bilan sur les représentations de structures
Les représentations évoquées auparavant sont en fait complémentaires, la représentation sous forme d’arbre vient pallier les limites de la représentation sous forme de liste, la représentation sous forme de forêt vient compléter la représentation sous forme d’arbre. Une représentation arborescente permet plus d’opérations de par sa structure hiérarchique. La représentation sous forme de forêt prend en compte d’autres éléments qui ne pouvaient pas être déterminés dans la structure arborescente. La représentation sous forme de graphe permet de traduire des relations logiques plus complexes comme pour les renvois ou les références.
Nous ne pouvons pas dire qu’une représentation est meilleure qu’une autre, le choix de la représentation dépend du type de documents que nous utilisons. Pour un document simple, la représentation adéquate sera la représentation sous forme de liste. Pour un document plus complexe qui possède plusieurs renvois, la représentation sous forme de forêt est la plus adéquate. Ceci dit, la représentation arborescente semble la mieux placée entre richesse de description et simplicité d’utilisation.
I.3.5. Les enjeux de la structuration
L’évocation de la structuration nous renvoie à plusieurs enjeux concernant son utilisation afin d’assurer la gestion des documents. Nous citons notamment les problèmes liés à la non-stabilité
et à l’absence partielle de structure (semi-structuralité) et ceux relatifs au rattachement de plusieurs structures à un seul document (multi-structuralité).
I.3.5.1. Les données semi-structurées
Les données semi-structurées se caractérisent par des structures (1) irrégulières ;
(2) hétérogènes ; (3) partielles ;
(4) qui n’ont pas un format fixe ; (5) qui ont une évolution rapide.
Ces structures sont inconnues a priori et elles doivent être définies a posteriori en inférant le contenu du document. Une donnée semi-structurée n’est pas conforme à une organisation prédéfinie. En revanche, dans le but d’exploiter la structure et/ou le contenu de ce type de documents, des schémas spécifiques ont été proposés. Pour les documents XML, les DTDs (Document Type définition) et XML-schema [Henry S. et al., 2001] sont des standards retenus. Ces schémas offrent plus de flexibilité dans la description des structures en utilisant par exemple les cardinalités ("" : une occurrence, "?" : zéro ou une occurrence, "+" : une ou plusieurs occurrences, "*" : zéro ou plusieurs occurrences), les relations d’alternance (A|B : A OR B : A ou B), etc.
I.3.5.2. Les documents multi-structurés
Pour un même document, nous pouvons trouver plusieurs structures qui peuvent dépendre des besoins des utilisateurs, de leurs visions, du contexte dans lequel le document a été produit, ou du contexte dans lequel il doit être traité. La multi-structuralité reflète donc l’association de différentes structures à un même document. Ainsi, plusieurs définitions ont été proposées.
• Définitions :
Selon une première vision, les différences entre les structures qui décrivent un document sont dues seulement à la décomposition ou au regroupement des fragments de contenu de ce document. Dans ce contexte, [Durusau P. et O'Donnell M. B., 2002] et [Tennison J. et Piez W., 2002] considèrent que le concept de multi-structuralité est apparu du fait qu’il est souvent très difficile de réduire la structure d'un document à un arbre unique. Ils supposent que les documents textuels ont souvent plusieurs structures. Ils donnent l'exemple des poèmes qui ont à la fois une structure "poétique" sous forme de strophes et vers et une structure "textuelle" (ensemble des paragraphes).
La multi-structuralité peut être considérée également comme étant « la définition simultanée de plusieurs structures pour un même document de base ». [Chatti N. et al., 2007]. Dans ce cadre, un document multistructuré est décrit par un ensemble de structures mises en correspondance. L’une de ces structures est constitutive du document et toute autre structure doit être rattachée à cette structure pivot. La diversité de ces structures est due au cadre d’utilisation du document.
Dans ce sens, la multi-structuralité est une description d’un document par « un ensemble d’éléments en relation les uns avec les autres, au cours ou en vue d’un usage » [Abascal R. et al., 2004].
Les différences majeures entre les définitions proposées dans ces travaux par rapport à la première vision résident d’une part dans l’utilisation d’une seule structure de base sur laquelle seront liées les autres structures (physique, temporelle, spatiale, etc.), et d’autre part sur la possibilité d’attribuer d’autres points de vue au même document. Cette possibilité est traduite également dans la définition proposée par [Mechkour M., 1995]. En revanche, selon lui chaque point de vue peut exister indépendamment des autres.
• Gestion :
Les différentes façons de définir la multi-structuralité ont induit plusieurs approches pour gérer ce concept. Ces approches peuvent être classées en deux catégories selon la flexibilité de l’organisation des structures.
Les approches de la première catégorie utilisent des modèles basés sur des organisations prédéterminées. Dans ce cadre, le modèle EMIR² [Mechkour M, 1995] et son extension [Charhad M. et Quénot G., 2004] représentent le document comme étant un ensemble de « vues » (perceptuelle, structurelle, symbolique, spatiale, temporelle, événementielle) encore appelées « facettes ». Ces vues sont combinées afin d'établir une description globale du contenu. Ces modèles se caractérisent par la séparation qu’ils imposent dans la présentation des vues. L’objectif de cette catégorie de modèles est plutôt de décrire chaque vue indépendamment les unes des autres.
Ces modèles se caractérisent par l’aspect statique des structures de vues. En effet, ces structures sont formées par une liste d’objets fixes, ce qui engendre un manque de flexibilité dans la gestion des documents. Avec de tels modèles, nous ne pouvons exploiter que les informations qui sont identifiées dans les structures proposées. D’autre part, il faut sauvegarder pour chaque vue la liste de toutes ses informations même si elles ne sont pas renseignées (valeurs nulles).
Les approches de la deuxième catégorie utilisent des modèles non déterminés a priori et permettent de décrire toute organisation de documents.
[Durusau P. et O'Donnell M. B., 2002] proposent de construire dynamiquement les structures de documents au moment de leur stockage. Ils ne se limitent pas à une structuration (ou modélisation) fixe mais ils associent à chaque nouveau document une nouvelle structure indépendante. L’inconvénient est alors que si des documents partagent des granules documentaires, il n’est pas possible de détecter qu’ils ont des sous-structures communes. Le recouvrement entre structures n’est donc pas géré : les mêmes structures seront stockées plusieurs fois, l’information est disséminée ce qui ne facilite pas la recherche. En revanche, [Tennison J. et Piez W., 2002] proposent d’utiliser un nouveau langage de balisage (non XML) qui n'est pas défini en terme d'éléments, mais de "ranges" (des ensembles d’éléments ou branches d’un arbre) qui forment l’intersection de deux structures. L’utilisation des "ranges" permet de faciliter la gestion des recouvrements entre structures en traitant simultanément l’ensemble des éléments en commun au lieu de les traiter de façon indépendante.
[Chatti N. et al., 2007] proposent le modèle MSDM (Multi-Structured Document Model) qui rattache toutes les structures qui décrivent un document à une seule structure de base. Ce modèle met en évidence des relations entre ces structures. Ces relations permettent d’exprimer le partage du contenu commun et d’expliciter des liens spéciaux entre les éléments de structures différentes. La structure de base est représentée sous forme de liste ; il n’y a donc aucun lien de hiérarchie entre les éléments. Cette structure de base ne permet donc pas de traduire l’organisation d’un document (structure logique), elle permet juste de rattacher les différentes structures à des éléments du document.
Avec ce modèle, malgré la gestion des relations complexes entre plusieurs structures, la structure de base est caractérisée par une organisation « trop » simple (plate). En effet, tous les fragments de cette structure sont des feuilles d’une même racine qui ne joue aucun rôle fonctionnel dans la structure. Elle est donc incapable de traduire l’organisation d’un document puisqu’elle ne gère pas la description des relations de composition et de description entre fragments. Elle permet juste de rattacher les autres structures aux contenus documentaires.
• Synthèse :
La multi-structuralité est une caractéristique inhérente à tout document. Un document quelconque, complexe ou non, peut être décrit par différentes structures, soit liées à sa « nature » même, soit liées aux usages qui peuvent en être fait. Ces structures peuvent être plus ou moins indépendantes. Elles peuvent contenir leurs propres fragments ou reprendre ceux d’une ou de plusieurs autres structures tout en ajoutant des informations supplémentaires. De plus, nous pouvons avoir pour un même document plusieurs structures de même nature. Par exemple, nous pouvons trouver différentes annotations d’un même document, desquelles nous pourrons extraire deux structures sémantiques différentes.
Dans l’ensemble des travaux présentés dans cette section, chaque utilisateur n’est pas contraint par l’utilisation d’une seule structure. Il peut définir et rattacher librement à un même document de base d’autres structures selon plusieurs points de vue. Certains travaux permettent également d’exploiter les liens qui peuvent exister entre ces structures. Par contre, nous constatons l’absence de toute règle pour organiser leur stockage et faciliter ainsi la gestion et l’exploitation de ce grand nombre de structures.
Gérer cette multi-structuralité pose les problèmes :
- de la flexibilité : assurer liberté et souplesse dans la proposition des structures (nature et composition) ;
- du stockage : assurer un stockage efficace qui minimise les redondances ;
- de la manipulation et l’exploitation (offrir plusieurs points d’accès au contenu des documents suivant les différentes structures possibles).
La résolution des enjeux liés à la structuration des documents passe nécessairement par la normalisation de l’échange, de l’archivage et de l’exploitation des documents. Depuis quelques années, les processus de normalisation sont de plus en plus présents dans les différents domaines de traitement des documents multimédia. Les documents normalisés sont en fait plus largement diffusables et exploitables de façon automatisée. En effet, la pérennité des documents impose
leurs exploitations indépendamment du matériel et du logiciel. Dans la section suivante, nous décrivons les principaux standards de représentation et de description des documents.
I.4. Les standards documentaires
Les standards documentaires permettent de fédérer le savoir-faire en terme de description des documents. Ils visent notamment à :
- assurer une interopérabilité des formats sur différentes plates-formes, sous forme de formats d’échange entre deux systèmes hétérogènes ;
- décrire le document en terme de contenu et de composants selon le contexte d’application.
Ainsi, l’objectif de la normalisation est double. Il s’agit d’une part, de normaliser la structuration du document en terme d’organisation générale et d’autre part, de normaliser la description de contenus riches et hétérogènes des documents multimédia. Deux familles de standards sont alors utilisées : les standards de structuration et les standards de description.
I.4.1. Les standards de structuration
Les standards de structuration ont pour objet d'homogénéiser la présentation des documents et d'augmenter leur lisibilité afin de faciliter leur consultation et leur échange. Ces standards doivent incorporer les différents média ainsi que leur composition. Dans la cette section, nous décrivons les principales standards (SGML, HYTIME, HTML et XML, XHTML, SMIL) qui ont marqué et marquent à ce jour l’histoire du document électronique. À titre d’illustration, le document multimédia de la figure I.12 sera présenté suivant les principales standards de structuration que nous allons citer dans cette section.
I.4.1.1. SGML et HYTIME
SGML (Standard Generalized Markup Language) autorise une structuration de l’information à l’aide de balises. Une balise désigne une marque particulière ajoutée à un texte afin d’en déduire sa structure ou le format dans lequel il sera édité [Goldfarb C., 1981]. SGML a été adopté officiellement en octobre 1986 comme standard international [ISO 1986].
La structure globale d’un document SGML est la suivante :
(1) un ensemble de déclarations où sont précisées les caractéristiques SGML utilisées telles que la version, le jeu de caractères utilisé, etc. ;
(2) une Définition de Type de Document (DTD) qui décrit la structure logique et exprime la manière dont les différents éléments d’information sont organisés et articulés entre eux ;
(3) un contenu.
Le standard SGML permet de définir des classes de documents, c’est à dire des documents ayant la même structure logique, et ce, indépendamment de leurs formats d’édition. Cette structure logique est définie dans la DTD. Cette DTD, sous la forme d’une arborescence, indique tous les éléments que peut contenir une classe de documents SGML, ainsi que les contraintes
d’organisation.
La DTD doit décrire les balises qui limitent les différents composants, ainsi que les règles d’utilisation des balises (l’organisation hiérarchique des différents éléments d’une DTD). L’interprétation d’un document SGML nécessite donc la connaissance de la DTD. Les auteurs de documents utilisent ensuite cette DTD pour rédiger les documents, au moyen d’éditeurs de texte. Une fois le document créé, un analyseur syntaxique le transforme en un document dont le balisage est complet. En effet, cet analyseur restitue les balises volontairement omises (par souci de simplification) lors de la saisie et vérifie si tous les éléments utilisés ont bien un modèle de contenu conforme à la DTD.
Nous présentons dans la figure I.13 une DTD du document de la figure I.12 selon le standard SGML. La DTD "Programme-cinéma" correspond à un ensemble de films classés par salle de cinéma et date de présentation, à chaque "Date" correspond à un ensemble de cinémas (salles), l’élément "Cinéma" se compose d’un "Nom", d’une "Adresse", d’un numéro de téléphone "Num-Tel" et d’un ou de plusieurs "Films". Un Film se compose d’un "Titre", une "Durée", d’un ou de plusieurs "Réalisateur", d’un ou plusieurs "Acteur", d’une ou plusieurs "Séance" et d’une "Affiche". L’élément Film peut avoir éventuellement un attribut "Genre".
Figure I. 13. Exemple d’une DTD SGML
Nous présentons dans la figure I.14 un extrait du document SGML correspondant au document "Toulouse_Cinéma" (figure I.12), écrit selon la DTD de la figure I.13.
Figure I. 14. Exemple d’un document SGML
La structure physique d’un document SGML est prise en charge par le standard DSSSL (Document Style Semantics and Specification Language) [ISO 1997]. C’est un format de données qui permet de spécifier le style et la présentation d’un document. Le modèle DSSSL est basé sur la notion de zones contenant des objets divers tels que des graphiques, du texte, des formules, d’autres zones et pouvant se superposer indépendamment de leur contenu. A chaque zone est associé un ensemble de règles de mise en page qui assure le lien avec la structure logique définie par SGML.
• HYTIME
SGML ne permet pas de gérer les liens hypertextes. Le standard HYTIME (HYpermédia/TIME-based Structuring Language) [ISO 1992], extension du noyau SGML permet l’intégration de structures hypertextes par l’utilisation de balises de renvoi. Elle se base sur la mise en place d’une méta-DTD (document de base) qui relie des DTD élémentaires entre elles (documents hyperliés).
hypertextuelles qui traduisent les liens entre l’entête du document formé par l’ensemble des salles de cinéma et les documents (pages web) qui correspondent à chaque salle.
Un des intérêts du standard SGML est que la structure logique est indépendante de la présentation de l’information et donc des moyens de restitution (séparation entre la structure logique et la structure physique). Ainsi, il est possible, à partir du même fichier, de réaliser des présentations visuelles différentes. De plus, le fait de pouvoir spécifier des règles d’utilisation des balises dans une DTD est un aspect très important de SGML. En effet, ceci permet d’imposer une uniformité aux documents d’un même type rendant plus aisé l’exploitation de l’information contenue dans les documents d’une même classe ou DTD. Bien que précurseur dans le domaine de la structuration normalisée de documents, l’usage de SGML tend à disparaître au profit de HTML pour le Web et surtout de XML qui en reprend les principaux avantages.
I.4.1.2. HTML
HTML (HyperText Markup Language) [W3C 1999] est largement exploité pour la création des pages Web. Tous les documents HTML sont conformes à une seule DTD [W3C 1999] issue de SGML.
La structure minimale d’un document HTML est la suivante :
(1) un entête (Head) qui contient des méta-informations telles qu’un nom externe (Title) qui sera utilisé par les navigateurs Web, les auteurs, les mots-clés, etc. ;
(2) un corps (Body) qui contient le contenu du document.
HTML se caractérise par un mélange de nombreuses balises de présentation et d’hyperliens, ainsi que certaines balises décrivant la structure.
Nous pouvons considérer que HTML est un langage semi-structuré orienté présentation, car les balises de structuration utilisent des propriétés typographiques pour mettre en évidence la structure logique. C’est le cas des balises d’entête <H1> à <H6>, qui servent à délimiter uniquement les titres des sections d’un document (et non le début et la fin des sections) et qui, néanmoins, déterminent le niveau de hiérarchie de la section dans le document.
L’étude de la DTD HTML permet de distinguer quatre catégories de balises :
- balises de présentation : celles servant uniquement à la mise en page des informations (mise en forme des caractères, alignement des paragraphes, etc.) ;
- balises structurelles : celles pouvant être utilisées pour séparer les différentes parties logiques d’un document HTML (entête, corps, paragraphe, liste, etc.) ;
- balises de référence : celles implantant les liens hypertextes dans les documents HTML (lien hypertexte, ancre, etc.) ;
- balises informationnelles : celles définissant des informations supplémentaires localisées soit dans la partie corps (adresse, mot-clés, etc.), soit dans l’entête (méta-informations).
La figure I.15 présente un extrait du code HTML du document "Toulouse_cinéma" de la figure I.12.
Figure I. 15. Exemple d’un document HTML
HTML est un langage qui comporte trois avantages principaux : - langage facile à apprendre et à comprendre ;
- liens hypertextes très faciles à gérer. Il s’agit d’insérer les balises <A href = "http://…> dans le document ;
- possibilité d’intégration de la DTD HTML dans des logiciels de navigation comme Netscape ou Internet Explorer vu la faible quantité de balises à gérer.
Cependant, l’absence de structure logique explicite cause d’énormes problèmes pour le traitement automatique des structures de documents et la recherche d’informations. De plus, le mélange des balises contrôlant l’apparence à celles décrivant la structure du document rend la réutilisation de l’information très difficile.
I.4.1.3. XML et ses langages complémentaires
XML (EXtensible Markup Language) [W3C 2000a] est un langage de description et d’échange de données semi-structurées. Comme SGML dont il est issu, il permet de décrire la structure logique des documents. A l’aide d’un système de balisage, XML permet de marquer les éléments qui composent la structure et les relations entre ces éléments.
La structure d’un document XML est formée par :
(1) un prologue qui est un ensemble de déclarations dont la présence est facultative, mais conseillée ;
(2) un arbre d’éléments qui forme le contenu proprement dit du document ;
(3) des commentaires et des instructions de traitement dont la présence est facultative et qui peuvent être soit dans le prologue, soit dans l’arbre d’éléments.
XML utilise des balises et des attributs comme SGML mais laisse à l’utilisateur l’entière possibilité de définir son propre jeu de balises dans le but de personnaliser la structure des documents. Le standard XML a été conçu pour être utilisée de deux manières distinctes [Michard A., 1998] :