On the Influence of the instance structure for metaheuristic performances -- Application to a graph drawing problem
Texte intégral
Figure
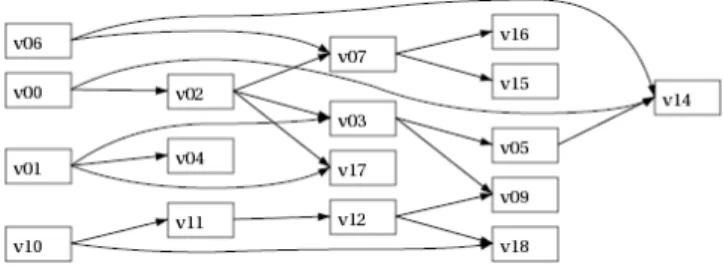
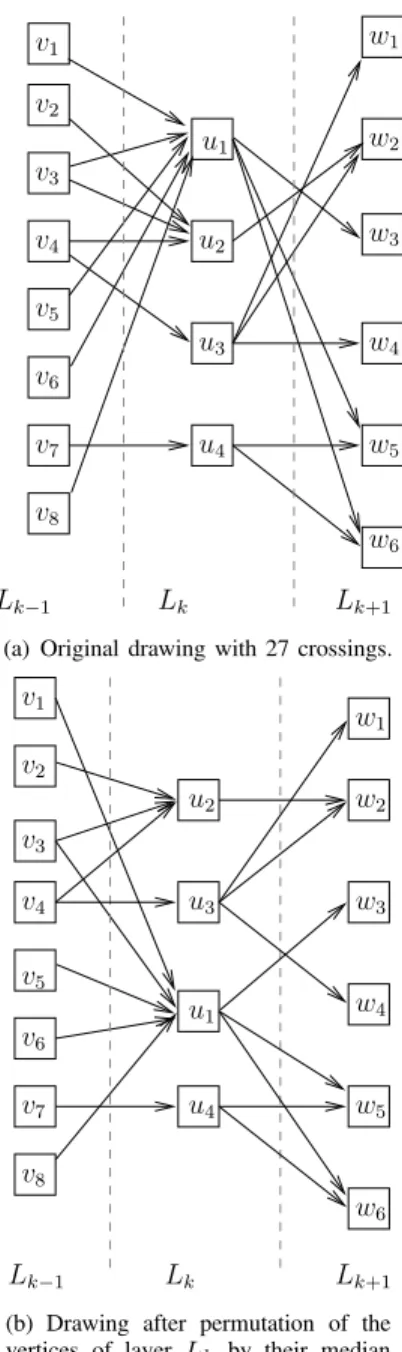
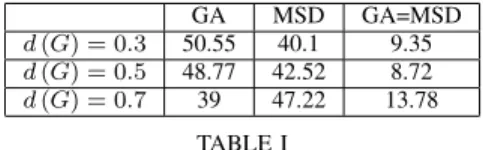
Documents relatifs
Given a classification problem D, we use our algorithm and the genetic algorithm to search the feature f with high- est fitness λ D (f ) and we compare the sets of features ex-
Consider an infinite sequence of equal mass m indexed by n in Z (each mass representing an atom)... Conclude that E(t) ≤ Ce −γt E(0) for any solution y(x, t) of the damped
Russell used acquaintance to that effect: ÒI say that I am acquainted with an object when I have a direct cognitive relation to that object, that is when I am directly aware of
Our research showed that an estimated quarter of a million people in Glasgow (84 000 homes) and a very conservative estimate of 10 million people nation- wide, shared our
joli (jolie), pretty mauvais (mauvaise), bad nouveau (nouvelle), new petit (petite), little vieux (vieille), old.. ordinal
First introduced by Faddeev and Kashaev [7, 9], the quantum dilogarithm G b (x) and its variants S b (x) and g b (x) play a crucial role in the study of positive representations
The complexity of Mrs Smith’s presentation points to the challenges facing primary care providers in man- aging complex chronic diseases in older adults.. We acknowledge
In our model, consumer preferences are such that there is a positive correlation between the valuation of the tying good and the tied environmental quality, as illustrated for
