Performance and energy efficiency of big data applications in cloud environments: A Hadoop case study
Texte intégral
Figure
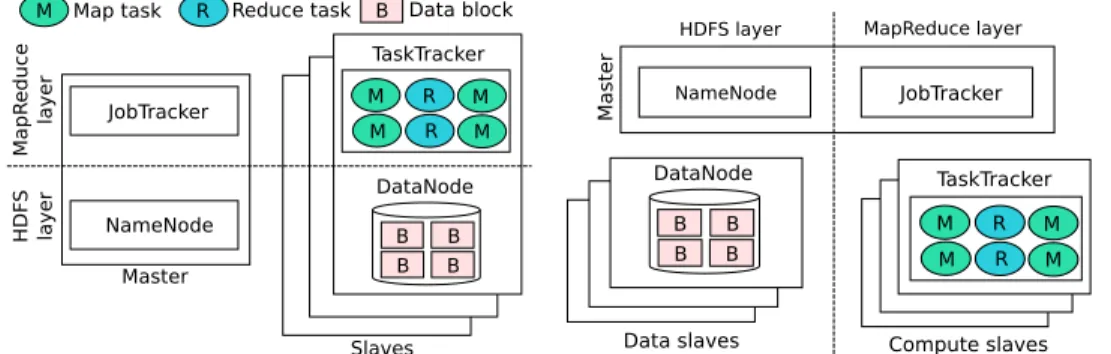
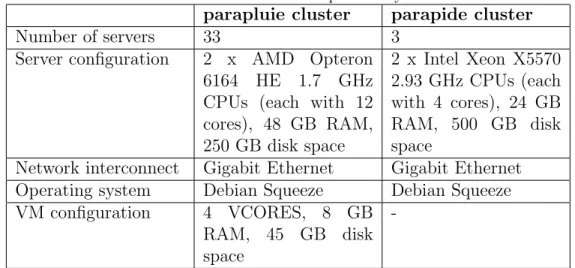

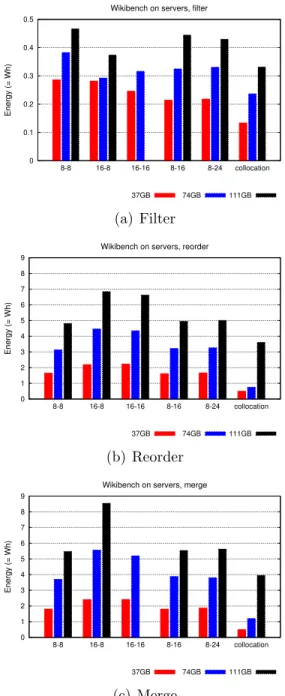
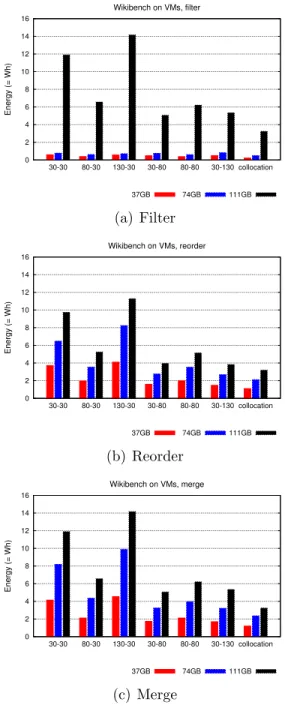

Documents relatifs
Ce sont des supports de cours mis à votre disposition pour vos études sous la licence Creative Commons Attribution - Pas d’Utilisation Commerciale - Partage dans les Mêmes
On the one hand, by using semantic analysis the data can be connected and the system can realize data sharing with RDF based on semantic data queries.. On the other hand,
Aucune d'entre elles ne doit être
Hadoop installation delivers the following example MapReduce jar file, which provides basic functionality of MapReduce and can be used for calculating, like Pi value, word counts in
Como su nombre lo dice, en esta etapa se crean diferentes grupos dentro de cada proceso y son ordenados para un manejo más sencillo y adecuado de los datos.. •
1) The prediction about Map task execution time: Figure 8 shows the the prediction about the Map task execution time for various sampling ratio K, K reflects the number of similar
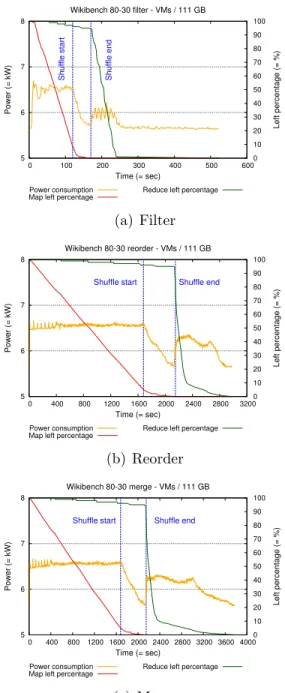
We compare the performance and the energy consumption of two technologies of virtualization (Docker containers and VMware) and bench- mark the software Hadoop (JoshBaer, 2015)
We come to the point that in most experiments the light technology offers better performances in completion time of workloads and it is more adapted to be used with the
