Les modèles vectoriels de la mémoire sémantique : description, validation et perspectives
Texte intégral
Figure

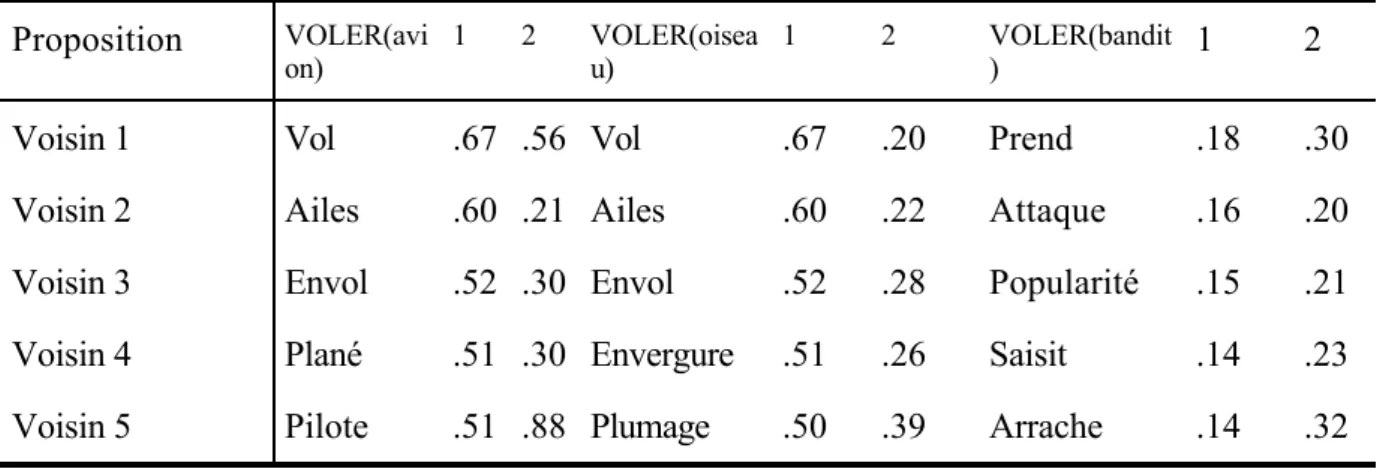
Documents relatifs
La mise en place de guichets uniques de l’habitat est un des objectifs communs des trois signataires : il s’agit, à terme, de mettre en place un lieu unique d’information,
Directive (UE) 2018/844 du Parlement européen et du Conseil du 30 mai 2018 modifiant la directive 2010/31/UE sur la performance énergétique des bâti- ments et la directive
C es derniers mois ont été marqués par une forte production réglementaire dans le domaine de la construction, avec la parution de nombreux textes pris en application de la loi
Labellisé Plateforme du Bâtiment durable sur la thématique des « Eco-matériaux », CoDEM - le BATLAB est un centre de transfert spécialisé dans le développement de
La loi de transition énergétique oblige les constructions neuves sous maîtrise d’ouvrage de l’État, des établissements publics et des collectivités territoriales, à faire
Pour cela, je me suis appuyé sur les services du Préfet de région (SGAR, Mission Achats), la MIGPIE (Mission Interdépartementale pour la Ges- tion du Patrimoine Immobilier de
Le plan de transition numérique pour le bâtiment (PTNB) a pour objectif fondamental d’impulser un élan de la filière autour du développement d’outils numériques à tous les
Le programme «Habiter mieux» cible depuis son démarrage un public de propriétaires occupants disposant de ressources modestes, et éprouvant des diicultés, pour cette raison, à
