HAL Id: hal-01526505
https://hal.archives-ouvertes.fr/hal-01526505
Submitted on 23 May 2017HAL is a multi-disciplinary open access
archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés.
Préférences spatiales et espaces urbains multicentriques
Catherine Baumont
To cite this version:
Catherine Baumont. Préférences spatiales et espaces urbains multicentriques. [Rapport de recherche] Laboratoire d’analyse et de techniques économiques(LATEC). 1993, 24 p., bibliographie. �hal-01526505�
LABORATOIRE D'ANALYSE
ET DE TECHNIQUES ÉCONOMIQUES
UMR 5601 CNRS
DOCUMENT DE TRAVAIL
�I
CENTRE NATIONALI
DE LA RECHERCHE SCIENTIFIQUE'1
Pôle d'Economie et de Gestion
UNIVERSITE
DE BOURGOGNE
2, boulevard Gabriel - 21000 DIJON - Tél. 03 80 3954 30 - Fax 03 80 39 54 43
PREFERENCES SPATIALES
ET ESPACES URBAINS MULTICENTRIQUES
Catherine BAUMONT n*9308
Catherine BAUMONT est Maître de Conférences en Sciences Economiques à l'ENESAD (Etablissement National d'Enseignement Supérieur Agronomique de Dijon).
I INTRODUCTION
La plupart des modèles de localisation résidentielle considère une représentation très simplifiée de l'espace urbain : espace monocentrique, localisations indifférenciées. Dans cette optique, la prise en compte de centres économiques multiples et 1'introduction de préférences spatiales constituent des voies d'évolution possibles pour l'analyse spatiale urbaine.
Néanmoins, le passage d'un centre unique à une multiplicité de centres ne peut être une simple tentative de généralisation visant à mieux expliquer ou comprendre les comportements de localisation dans les espaces urbains. En effet, les modèles multicentriques permettent d'intégrer d'autres hypothèses (la hiérarchie des centres par exemple, Papageorgiou 1971) et soulèvent d'autres problématiques (l'inadéquation entre l'espace économique et l'espace physique, Papageorgiou 1976, Baumont 1992) que les modèles monocentriques.
De même, l'introduction des préférences des agents pour les localisations, que nous appellerons préférences spatiales1, est
incompatible avec certaines hypothèses mathématiques "idéales" telle la convexité des ensembles de consommation (Zoller 1988) et prive ainsi l'analyse des choix résidentiels de ces principaux résultats théoriques. Pourtant, en amont de l'analyse des choix résidentiels, la construction d'une structure de préférence-indifférence spatiale permet, quelles que soient les hypothèses mathématiques exclues en aval, d'approcher les comportements de localisation sous un angle nouveau : le lieu résidentiel possède des qualités propres en plus de sa position vis-à-vis du ou des centres économiques. Il est désiré pour lui-même.
L'objet de cet article est d'analyser le concept de préférences spatiales dans les espaces multicentriques. Son mode d'intégration dans l'analyse des comportements de localisation résidentielle sera déjà examiné (section II). Ensuite, nous montrerons comment l'utilisation des préférences spatiales peut servir à détecter le caractère multicentrique d'un espace (section III). Enfin, plusieurs résultats empiriques
illustrant les points précédents seront présentés (section IV).
i
Il existe une autre façon de concevoir les p r é f é r e n c e s s p a t i a l e s lorsque l'on suppose que la structure de préférence dépend d e s o n lieu d'émission (Billot 1 9 9 3 ) . Ce n'est pas l'optique retenue ici.
II LE CONCEPT DE PREFERENCES SPATIALES
On considère un espace urbain multicentrique E. C'est un ensemble fermé de localisations i.
La ville possède un nombre fixé n de centres économiques indicés k (k € [l;n]. Chaque centre économique est compris ici dans son sens usuel. C'est un "lieu" où sont regroupés les emplois et les biens de consommation. Un centre est repéré dans l'espace par sa localisation. Si le centre n'est pas réductible à un point, sa localisation sera donnée par une position géographique précise placée au "centre" de la surface considérée. Dans l'espace multicentrique chaque localisation i est ainsi caractérisée par sa position par rapport à chacun des n centres économiques. Traditionnellement, c'est la distance Dik entre la localisation i et chaque centre économique k qui est employée.
Dans un tel schéma, l'espace monocentrique est un cas particulier puisque n = 1.
D'une façon générale on dira que les préférences spatiales sont l'expression d'un besoin de localisation par rapport à ces n centres économiques. La position de la localisation dans l'espace procure une satisfaction, au même titre que la consommation des autres biens. Plus précisément, le consommateur peut identifier le niveau de satisfaction procuré par chaque localisation i, puis les classer selon une relation de préférence-indifférence. En conséquence, la fonction d'utilité devient spatialisée.
Ainsi, prendre en compte les préférences spatiales dans un modèle de localisation c'est proposer d'une part un mode de classification des localisations selon une relation de préférence-indifférence spatiale et d'autre part, leur mode d'expression dans la fonction d'utilité de 1' agent.
Examinons successivement ces deux principes avant de présenter leurs principales propriétés.
2.1 L'expression des préférences spatiales
On rappelle que l'introduction du facteur spatial dans l'analyse des comportements de consommation se fait à double titre. D'une part, l'espace devient élément de choix puisqu'il est consommé au même titre que les autres biens, d'autre part l'espace est support des choix, puisque les biens devenant localisés, des déplacements sont nécessaires
pour satisfaire les besoins de consommation. Compte tenu de ce double rôle il faut considérer que les localisations se distinguent les unes des autres de par leurs caractéristiques de contenu (c'est l'aspect "choix d'espace") et de par leurs caractéristiques de position dans l'espace (c'est l'aspect "support des choix"). Nous appellerons les premières
caractéristiques intrinsèques et les secondes caractéristiques relatives.
Chaque localisation devient un panier de caractéristiques diverses, satisfaisant des besoins de natures différentes. Les classements opérés par les consommateurs sur les localisations peuvent alors être analysés selon les mêmes principes que pour les paniers de biens traditionnels. Notons que la seule considération des caractéristiques relatives ne suffirait pas à créer des préférences spatiales car : "quel sens peut-il y avoir à supposer une préférence pour la localisation en présence d'un espace homogène où chaque parcelle de terrain est rigoureusement identique à n'importe quelle autre ?" (Zoller 1988).
Remarquons, enfin que notre analyse des préférences spatiales ne s'inscrit pas dans la nouvelle théorie du consommateur (Lancaster 1966) comme pourrait le suggérer l'emploi du terme "caractéristique". En effet, le consommateur n'exprime pas de préférence vis à vis des caractéristiques, pour ensuite choisir la localisation idéale, il exprime directement ses préférences sur les localisations vues comme des paniers de caractéristiques. Ceci étant précisé, analysons plus avant les différentes caractéristiques.
• Les caractéristiques intrinsèques des lieux sont essentiellement
définies en fonction des attraits du site ou de ses inconvénients pour une occupation résidentielle : aménités résidentielles (qualités écologiques, esthétiques ... du lieu), type de population y résidant, niveau de sécurité civile . . . Dans cette optique, chaque localisation est un ensemble de "quantités" de caractéristiques, cette "quantité" pouvant tout aussi bien être évaluée qualitativement ou quantitativement. Par exemple, si on s'intéresse à la pureté de l'air, une échelle linguistique d'évaluation, du type {très satisfaisant, satisfaisant, moyen, médiocre,
insuffisant}, peut être retenue.
• Les caractéristiques relatives des lieux sont liées à leur situation
par rapport à d'autres lieux soit parce que l'individu devra s'y rendre : lieux de consommation de biens privés ou public, de loisir, de travail...
soit parce qu'ils symbolisent un attrait ou un inconvénient pour l'individu : une forêt, un quartier purement résidentiel ...En fait, les caractéristiques relatives traduisent à la fois les déplacements inhérents à tout choix de consommation d'espace en un lieu i distinct des lieux d'emploi, de travail ou de loisir et les goûts en matière de proximité ou d'éloignement.
A ce titre, chaque localisation est un ensemble de quantités de
séparation spatiale par rapport à d'autres lieux privilégiés : ce sont
les centres économiques retenus dans notre étude.
2.2. Principe de classement
On utilise une relation de préférence-indifférence spatiale. Chaque localisation i est un vecteur de quantités de caractéristiques de contenu (on est ici dans l'espace usuel des biens) et de quantité de séparation spatiale (on est ici dans l'espace au sens éthymologique du terme).
Si on suppose qu' il y a t caractéristiques de contenu et n centres économiques, alors chaque localisation est un vecteur à t+n composantes.
Pour définir le mode de classement, nous aborderons deux points 1/ la compararabilité des localisations et 2/ les conditions de classement.
1/ Peut-on toujours classer deux localisations i et i* soit en terme de préférence (i préféré a i ' ou i' préféré à i) ou d'indifférence ?
Il n'existe pas de cas d'incomparabilité car les localisations sont appréciées à la fois par rapport à leurs qualités intrinsèques et relatives (Billot 1988). Si deux lieux possèdent les mêmes qualités relatives, ils ne possèdent pas les mêmes qualités intrinsèques, sinon ils seraient identiques. On dit encore que la localisation est un facteur de différenciation en elle-même puisque selon Debreu (1966), deux biens disponibles en deux localisations différentes sont différents.
La relation de préférence-indifférence spatiale est complète.
2/ Comment s'effectuent les classements ?
On distingue dans un premier temps les caractéristiques intrinsèques des caractéristiques relatives.
Pour les caractéristiques intrinsèques, on applique les principes traditionnels en assimilant une localisation à un panier de quantités de biens (les biens sont les caractéristiques). On suppose que le problème
de l'évaluation de chaque quantité de caractéristique est possible et qu'il permet de respecter l'ordre standard des préférences, à savoir que plus sera toujours préféré à moins. Pour cela "il suffit de compter négativement les attributs négatifs" (Rouget 1981) en identifiant des indicateurs appropriés. Par exemple, on n'utilisera pas un indicateur de pollution, mais l'indicateur inverse. On ne parlera pas de risque civil
(délinquance, criminalité . . . ) mais de sécurité civile ... La théorie standard des préférences s'applique donc immédiatement puisqu'en fait aucune "spatialisation" des préférences n'est encore apparue.
Considérons maintenant, chaque localisation comme un panier de quantités de séparation spatiale permettant de traduire "l'intérêt" du consommateur à se localiser par rapport à chaque centre de l'espace. Cette quantité de séparation spatiale peut prendre différentes acceptions. Ce peut être une distance, une mesure d'accessibilité ou une mesure d'attraction si on considère que seule la longueur du déplacement importe au consommateur, ou qu'il tient compte en plus des facilités d'accès ou du contenu même du centre. Le mode d'évaluation dépend alors du problème de localisation traité et des motivations des agents.
Mais, quel que soit l'indicateur choisi, un problème apparaît quant à la cohérence des évaluations avec les préférences standards. En effet, deux principes fondamentaux remettent en cause la simple transposition de la théorie des préférences a-spatiales aux préférences spatiales. Ces principes s'énoncent ainsi :
Pi : il n'existe pas d'axiome de dépréciation de la distance comme c'est le cas pour le temps par exemple (Ponsard 1955).
P2 : les quantités de séparations spatiales ne sont pas indépendantes les unes des autres.
Le principe Pi signifie qu'un éloignement peut aussi bien être jugé utile qu'un rapprochement. Pour les centres, par exemple, s'il sont répulsifs, le consommateur jugera préférable de s'en éloigner, alors que s' ils sont attractifs, au contraire, tout éloignement diminuera la satisfaction de l'individu. Et bien sûr dans une structure urbaine multicentrique les deux types de centres peuvent coexister.
Le principe P2 s'applique alors automatiquement, dans le sens où s'éloigner d'un centre indique souvent se rapprocher d'un autre centre. Plus généralement, toute modification d'une caractéristique relative
induit une modification d'une ou de plusieurs autres caractéristiques relatives. La "consommation" des caractéristiques relatives est une
consommation jointe imposée par la localisation prédéterminée des
centres. Cela signifie d'une part que l'hypothèse ceteris paribus ne tient plus et d'autre part que l'ensemble des caractéristiques relatives est borné : toutes les combinaisons de distances ne peuvent exister
(Baumont, 1992). Ce dernier point n'est pas gênant outre mesure pour la description des préférences, mais induit des conséquences sur les propriétés de la relation de préférence-indifférence.
Précisons enfin que si l'espace est monocentrique, il n'y a plus qu'une seule caractéristique relative et donc le principe P2 devient caduque.
2.3. Propriétés
On s' intéresse ici 1/ aux propriétés des ensembles de caractéristiques intrinsèques et relatives, et 2/ aux propriétés de la relation de préférence indifférence.
1/ On peut toujours envisager que tous les niveaux de caractéristiques intrinsèques existent (l'ensemble correspondant est "continu"), mais nous venons de préciser que l'ensemble des caractéristiques relatives, telles qu'elles apparaissent dans l'espace physique sur lequel les agents évoluent, est borné.
Par ailleurs, ni l'ensemble des caractéristiques intrinsèques ni l'ensemble des caractéristiques relatives ne sont convexes. En effet, cela signifierait, dans le premier cas, que la combinaison de deux lieux présentant des attributs moyens suffirait à former un lieu de qualité supérieure (Zoller et Paelinck 1982). Dans le second cas, cela impliquerait que l'agent économique a le don d'ubiquité puisqu'il aurait intérêt à résider simultanément en un grand nombre de lieux (Zoller 1988, Billot 1993).
2/ On montre que la relation de préférence-indifférence spatiale est complète, réflexive et anti symétrique. Par contre, la propriété de transitivité des préférences spatiales n'est pas envisageable (Baumont 1990), du fait des caractéristiques relatives. En effet, nous avons vu que la consommation des caractéristiques relatives était une consommation jointe, ce qui remettait en cause les classements standards.
Par exemple, considérons un espace tricentrique, le centre 1 étant répulsif (on préfère s'en éloigner) et les centres 2 et 3 étant attractifs (on préfère s'en rapprocher). Soient trois localisations A, B et C et leurs distances respectives aux trois centres.
A (Al = 2 A2 = 6 A3 = 6.5) B (Bi = 6 B2 = 7 B3 = 1.5) C (Ci = 5 C2 = 2.5 C3 = 1)
Supposons que la localisation A soit préférée à la localisation B (1'éloignement du centre répulsif 1 et le rapprochement du centre attractif 3 fait plus que compenser l'éloignement supplémentaire du centre attractif 2) et que la localisation B soit préféré à la localisation C (le rapprochement des centres attractifs 2 et 3 fait plus que compenser le rapprochement du centre répulsif 1).
Comparons maintenant les localisations A et C. On voit immédiatement que C est obligatoirement préférée à A car C est plus proche des centres attractifs et plus éloignée du centre répulsif que A. Par conséquent, la transitivité des préférences n'est pas assurée ici.
En conclusion, la relation de préférence-indifférence spatiale ne peut constituer une relation de préordre. Ce résultat est gênant lorsque l'on recherche la localisation optimale c'est-à-dire dès que l'on passe au problème du choix d'une localisation maximisant l'utilité spatialisée sous contrainte budgétaire (Baumont 1991). Par contre, il ne remet pas en cause l'existence d'une structure de préférence-indifférence spatiale et sa transcription en terme d'utilité, nommée utilité spatialisée, même si celle-ci n'est plus nécessairement concave ou continue.
C'est précisément en employant maintenant une fonction d'utilité spatialisée que nous allons tester le caractère multicentrique d'un espace.
III PREFERENCES SPATIALES ET TEST DE MULTICENTRICITE
Alors que différentes méthodes peuvent être employées pour juger du caractère multicentrique d'un espace, un test basé sur les préférences spatiales n'a pas encore été employé. Aussi on peut se demander quels sont les apports théoriques de cette autre procédure (3.1) et s'interroger sur sa faisabilité (3.2).
3.1. Justifications théoriques
Tester la multicentricité d'un espace revient à s'assurer qu'il n'est pas monocentrique, c'est-à-dire que les répartitions spatiales des densités résidentielles (Gordon, Richardson et Wong 1986, Griffith 1981 et Odland 1978) ou des prix des logements, par exemple, ne sont pas influencées seulement par un centre unique localisé au centre de l'espace considéré.
Les procédures basées sur la structure des prix des logements se rapprochent le plus de celle que nous avons adoptée. En effet, il s'agit, via la construction et l'estimation économétrique d'un modèle hédonique (Heikkila et alii 1989, Johnson et Ragas 1987, Achour et Lapointe 1980), d'expliquer la formation des prix des logements par différents critères. Ces différents critères sont liés aux caractéristiques des logements, mais aussi aux caractéristiques propres des localisations où ils se situent et enfin à la position des logement par rapport à différents centres économiques. Les deux derniers groupes d'attributs renvoient respectivement aux caractéristiques intrinsèques et aux caractéristiques relatives des lieux employées dans notre structure de préférences spatiales.
Admettons que le prix d'un logement localisé en i se note P(i) et qu'il dépende de r caractéristiques résidentielles notées Ri (1 € [l;r]), de t caractéristiques intrinsèques notées Gf (f e [l;t]) et de n caractéristiques relatives évaluées par les distances Dik (k e [l;n]).
Le modèle hédonique s'écrit :
r t n
P(i) = jT o^Ri + £ pfGf + £ rkDlk
1 = 1 f=l k=l
et les pondérations a , 0 et y représentent les prix implicites de chaque caractéristique dans le prix global du logement.
Si les estimations de ces pondérations révèlent que plus d'un coefficient est significativement différent de zéro, alors l'influence de plus d'un centre est reconnue et la structure urbaine est multicentrique.
Plus généralement, les modèles hédoniques sont utilisés pour révéler
les attributs a-spatiaux (Ri) ou spatiaux (Gf seulement) explicatifs des prix des logements (Linneman 1980 et 1981, Nelson 1978, Apps 1973) ou pour légitimer les structures monocentriques lorsque la présence
d'externalités négatives (exprimées dans Gf) masque la décroissance des prix avec la distance au CBD (Coulson 1991).
En fait, lorsque l'on travaille sur les modèles hédoniques, on révèle indirectement les préférences spatiales des individus (lorsque des critères Gk et Dik sont utilisés) à travers la somme que le consommateur serait prêt à payer pour bénéficier d'une quantité supplémentaire d'une caractéristique : c'est le prix implicite de cette caractéristique.
Par contre, si on travaille à partir des préférences spatiales, on ne se place plus en aval du processus de choix (à l'équilibre du marché), mais en amont, ce qui permet d'apprécier directement la perception
spatiale des individus. Dans le premier cas, on se sert d'éléments
objectifs : les prix observés sur le marché tandis que dans le second cas, on apprécie immédiatement les préférences subjectives, ce qui est plus logique.
La fonction d'utilité exprimant la satisfaction retirée en un lieu i
de l'espace par le consommateur peut être définie de la manière la plus exhaustive par :
Ui = U | L, Ri, Z, Gf, Dik
J
[1] où L est la quantité de logement consommée et Ri sont les quantités de caractéristiques des logements, Z est la quantité de bien composite consommée, Gf et Dik sont les quantités de caractéristiques intrinsèques et relatives des lieux.Plus précisément, notre but étant de tester la multicentricité de la structure urbaine, nous n'avons retenu que les variables L, Z et Dik et nous avons employé une forme multiplicative.
a b n c
U = A . L . Z . I T D k [2]
i k=l ik
• D ^ désigne plus précisément la distance entre i et chaque centre k (V k € [l;n]).
• A, a , b et c (V k € [l;n]) sont des paramètres et a, b et c (V k €
k k [l;n]) indiquent plus précisément l'élasticité de l'utilité à la
consommation de chaque variable.
Le test consiste alors à estimer économétriquement les paramètres de la fonction d'utilité et porte sur la significativité des paramètres c .
3.2 Faisabilité du test
Elle est appréciée à travers 1/ la construction d'un échantillon représentatif, 2 / la collecte des données et 3/ l'évaluation de l'utilité résidentielle.
1/ Construction de l'échantillon
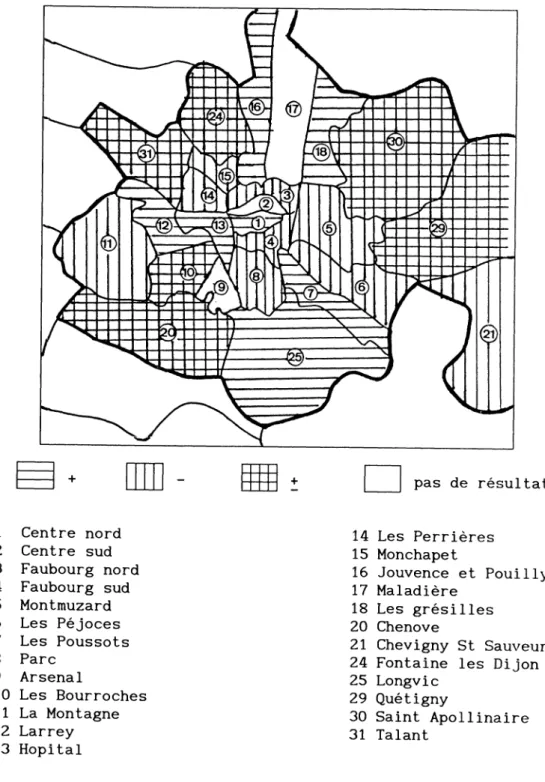
• La structure urbaine étudiée est l'agglomération dijonnaise (cf figure 1, p 20). Pour mettre en évidence le caractère multicentrique de cette agglomération, nous avons assimilé chaque zone administrative à un centre économique, la position précise du centre dans la zone étant définie selon la méthode décrite précédemment. Sur les 31 zones spatiales
initiales (18 quartiers administratifs de la ville de Dijon et 13 communes), nous n'avons retenu pour l'étude empirique que les 18 quartiers dijonnais et seulement 7 communes et ceci pour des raisons d'indisponibilité d'informations sur certaines communes.
Au total, 26 centres sont retenus : n = 26.
• L'échantillon employé est un échantillon stratifié selon le découpage
administratif à fraction sondée égale par rapport à la répartition des
logements dans l'agglomération : si x% des logements de l'agglomération appartiennent à la zone administrative k, alors dans l'échantillon, ce même pourcentage devra être retenu.
• Pour construire l'échantillon, nous nous sommes servis des annonces immobilières parues sur la période de décembre 1988 à janvier 1989. Au total, 847 observations ont été retenues. Pour chaque observation, les informations suivantes ont été collectées :
• données sur les logements : caractéristiques de surface (L) et éventuellement d'autres caractéristiques (Ri).
• données sur les individus : utilité résidentielle spatialisée (Ui) et consommation de bien composite (Z).
• donnée sur les localisations : caractéristiques relatives (Dik) et éventuellement caractéristiques intrinsèques (Gf).
2/ La collecte des données
On donne ici, quelques éléments pratiques concernant les caractéristiques L, Z, Ri, Gf et Dik, le problème de l'utilité Ui étant traité séparément.
logement et éventuellement de la surface de terrain associée.
• La quantité de bien composite consommée Z dépend de la composition du ménage habitant le logement, c'est-à-dire du nombre de personnes mais aussi du statut social du ménage.
• Les distances Dik séparant le lieu du logement et chaque centre k sont des distances euclidiennes.
• D'autres caractéristiques Ri sur les logements ont été collectées. • Le numéro de l'étage dans lequel il est situé (eta). a ) . • Le nombre de pièces (npi).
• Un indice de qualité (quai) relatif à la présence (comptée 1 ) ou à l'absence (comptée 0) de certaines prestations : une cave, un grenier, un garage, un parking privé et un ascenseur. La qualité peut alors prendre les valeurs 0 à 5.
• Des caractéristiques intrinsèques aux localisations Gf ont également été collectées. Elles sont plutôt relatives au standing résidentiel et social de la zone spatiale k dans lequel le logement est situé. Elles ont été obtenues à partir du recensement général de la population de 1982. Il s'agit :
• du nombre moyen de pièces des logements de la zone k (moypi). • du nombre moyen de personnes vivant dans les logements de la zone k (ipeup).
• du pourcentage moyen de cadres supérieurs vivant dans la zone k (es).
• d'un indicateur d'attraction commerciale de la zone k (picent) servant à évaluer si la zone est plutôt résidentielle (la valeur de l'indicateur sera faible) ou plutôt "économique" (la valeur de l'indicateur sera élevée). Cet indicateur a été calculé en appliquant la méthode de Fustier et Rouget (1985).
3/ L'évaluation de l'utilité
La connaissance de l'utilité est celle qui pose le plus de problèmes car l'utilité n'est pas observable en soi. Il faut donc l'apprécier a priori, c'est-à-dire sans préjuger d'une forme analytique précise. Trois techniques sont le plus souvent employées.
• Soit on procède par enquête en demandant aux individus de donner une note à l'utilité, ou la satisfaction, qu'ils retirent de leur lieu de
résidence. Cette technique n'a pas été retenue car elle fournit en fait des résultats sur 1'"équilibre résidentiel" puisque les individus ont choisi le lieu d'emploi où ils résident. Il sont alors le plus souvent "satisfaits" de leur choix (Clark et Cadwallader 1973).
• Soit, toujours par enquête, on va chercher à évaluer le revenu correspondant à des niveaux d'utilité donnés en demandant aux individus ce qu' ils estiment être un bon, un moyen ou un mauvais revenu s' ils devaient résider en un lieu précis. Cette technique s'applique plus à l'évaluation d'une fonction de bien être (Van Praag et Van Der Sar 1988) et n'a pas été retenue.
• Soit on recense un certain nombre d'attributs (autres que ceux retenu dans l'expression de la fonction d'utilité) dont la présence ou l'absence en un lieu de résidence est signe d'utilité ou de désutilité et on construit un indicateur d'utilité résidentielle. L'utilité résultante est de type cardinale. C'est la méthode que nous avons retenue.
Bien sûr, l'emploi d'une utilité de type cardinale est critiquable, car elle suppose que l'on peut agréger la satisfaction retirée de critères différents comme la présence d'un garage dans le logement ou le standing du quartier. Nous l'utiliserons cependant, estimant qu'elle permet de synthétiser les atouts d'une localisation résidentielle. Par ailleurs, si on prend garde à utiliser les valeurs obtenues par cette technique pour faire des classements, et non des mesures d'écart de satisfaction entre les logements, on peut accepter la structure de préférences obtenue.
L'utilité U. peut donc être vue comme un ensemble de données qualitatives dont on cherche un processus d'agrégation. Plus précisément, nous poserons que l'utilité résidentielle en un lieu i prend alors la forme d'une somme pondérée de critères, relatifs au logement lui-même (ce sont les variables Ri) et à la zone administrative dans laquelle il est situé (ce sont les caractéristiques relatives Gf).
r t
On pose : Ui = £ pRi + £ p Gf [3]
1 = 1 f=i
trouver la "formule" d'utilité qui coïncide avec la fonction d'utilité
[ 2 ]2
a b n c
U = A . L . Z . Ï ï D k [2]
i k = l ik
Pour trouver les pondérations, nous sommes partis de la constatation suivante : selon la nature et le nombre des caractéristiques Ri et Gf retenues, les coefficents a, b et c^ de la régression varient. Ils sont, soit significatifs, soit non significatifs, positifs ou négatifs... L'idée est qu'il peut, alors, exister une formule, prenant dans notre cas
la forme d'une somme pondérée de critères, permettant d'obtenir la meilleure régression d'utilité de résidence, c'est-à-dire celle qui respecte les hypothèses du modèle d'équilibre spatial du ménage urbain, à savoir :
• les coefficients a et b sont obligatoirement positifs car ils expriment l'augmentation de l'utilité avec l'augmentation de la consommation,
• par contre, les signes des paramètres c^ sont indéterminés. Nous savons seulement que si le centre k est jugé attractif alors le signe de c^ sera négatif (l'utilité diminue avec 1'éloignement) alors que si le centre k est répulsif le signe de c^ sera positif (l'utilité augmente avec 1' éloignement).
Nous souhaitons donc obtenir un indice d'utilité qui permette de respecter l'hypothèse sur les signes des paramètres a et b. Le choix des variables et le calcul des pondérations à inclure dans l'indice d'utilité a été réalisé en partant d'une technique mise au point par Paelinck
(1985) dont nous avons retenu le principe de circularité (cf Annexe, page 22).
Le paragraphe suivant est maintenant consacré à la présentation des résultats empiriques obtenus d'une part sur l'évaluation de l'utilité et d'autre part sur le caractère multicentrique de l'agglomération dijonnaise.
En fait, quand on rapproche les formules d'utilité [1], [2] et [ 3 ] , on s'aperçoit que les arguments de la forme [1] sont r é p a r t i s e n t r e les formes [2] et [3], ce qui permet de décrire l'utilité d e d e u x f a ç o n s d i f f é r e n t e s .
IV RESULTATS EMPIRIQUES
4.1 Les indicateurs d'utilité
Trois formules d' indices ont été retenues. On dira que chacune de ces formules d'indice d'utilité reflète une forme de structure de préférences pour les individus.
Ui = 0.008 quai + 0.16 npi + 0.004 eta + 0.83 ipeup - 0.072 picent +
0.043 es
U2 = 0.009 quai + 0.183 npi + 0.004 eta
U3 = picent + ipeup + moypi
Avant de commenter ces différents résultats, on remarque que la formule U3 correspond à la première itération du processus d'estimation puisque toutes les pondérations sont égales à l'unité. Nous verrons par
la suite, que cette formule se distingue des deux premières.
Notons également que, quel que soit le nombre ou le type de variables retenus, on arrive à une certaine stabilité des pondérations, en valeur et en signe (sauf pour la formule U3), ce qui justifie le procédé itératif employé. On montre ainsi, qu'une formule d'indice explique effectivement mieux qu'une autre ce que l'on cherche à établir. Or, quand au départ, on ne sait pas comment évaluer 1'indice en question, il est légitime de ne s'intéresser qu'aux formes corroborant les hypothèses plutôt que de laisser "aux fruits du hasard" le temps d'établir la forme correcte. Et lorsque l'on doit évaluer un indice d'utilité, on entre précisément dans ce contexte.
Par exemple, la valeur de la pondération du critère "qualité" tourne autour de 0.008 ou 0.009, celle du critère "étage" autour de 0.004. Pour le "nombre de pièces", on obtient toujours des pondérations élevées : autour de 0.17. Par contre les valeurs des pondérations des caractéristiques des zones sont plus instables et nous reviendrons sur ce point dans un prochain paragraphe.
1) La formule Ui caractérise des individus qui accordent de l'importance
à la fois aux caractéristiques des logements et aux caractéristiques des zones dans lesquelles ils sont situés.
• Les caractéristiques des logements contribuent de façon positive à l'amélioration de l'utilité; le nombre de pièces du logement ayant la plus forte influence.
• Les caractéristiques des quartiers jouent soit un rôle positif (pour les variables ipeup et es), soit un rôle négatif (pour la variable picent). Ces résultats sont logiques et peuvent être interprétés comme suit.
• L' indice de centrante reflète principalement les propriétés économiques de la zone. Ainsi, un fort indice de c e n t r a n t e correspond à une zone commerciale importante et, par opposition, à une zone résidentielle moins dense. L'utilité résidentielle est donc décroissante avec l'indice de centrante. On retrouve là un résultat classique.
• L'effet positif du pourcentage de cadres supérieurs sur le niveau de l'utilité peut s'expliquer par le standing résidentiel de la zone reflété par cet indicateur. Ainsi, plus une zone est habitée par des cadres supérieurs, relativement aux autres catégories socio-professionnelles, et plus elle est le signe d'une image résidentielle attractive.
• L'effet positif de l'indice de peuplement est par contre plus délicat à interpréter. En effet, nous avons vu que cet indice pouvait refléter la rareté de l'offre de logement dans le sens où un fort indice de peuplement traduirait une offre résidentielle insuffisante. C'est ainsi que les quartiers centraux de la ville peuvent être caractérisés. Par contre, l'indice de peuplement peu également refléter la composition des ménages habitant les logements. Ainsi, de forts indices de peuplement sont à associer à des zones habitées par des familles, c'est-à-dire à des ménages constitués au minimum de trois personnes plus que par des couples sans enfant ou des personnes seules. C'est ainsi que les zones périphériques, plus pavillonnaires, peuvent être caractérisées. L'effet positif global de l'indice de peuplement prend alors en compte ces deux aspects.
2) La formule IÏ2 concerne un individu qui ne s'intéresse qu'aux attributs des logements. Ceux-ci contribuent tous de façon positive à
l'augmentation de la satisfaction.
3) La formule U3 caractérise un ménage qui ne tient compte que des caractéristiques des zones spatiales. On remarque que toutes les
caractéristiques ont maintenant une contribution positive à l'augmentation de la satisfaction, ce qui contredit les résultats obtenus dans la formule Ui pour l'indice de centralité. Ce phénomène s'explique
par l'effet dominant des centres exprimé dans l'indicateur. Les individus possédant une telle structure de préférences spatiales sacrifient en quelque sorte l'aspect logement à l'aspect centre économique.
Finalement, chaque indice d'utilité reflète des goûts différents pour les ménages et doit conduire à une structure de préférences spatiales différente. C'est ce que nous allons maintenant montrer en
comparant les résultats obtenus à l'aide de ces indices d'utilité.
4.2 Le test de multicentricité
L'estimation des paramètres de la fonction d'utilité par la méthode des moindres carrés multiples a été réalisée sur le modèle statistique suivant
n
log(lM = Log A + a log L + b log Z + £ c^ log + e
k = l
(e terme d'erreur)
Les résultats des trois régressions sont donnés dans les tableaux suivants où les chiffres en petits caractères sont les valeurs du t de Student. Seules les variables dont les coefficients sont significatifs à 95 % et au-delà, ont été retenues.
Compte tenu de la méthode adoptée pour déterminer les indicateurs d'utilité, On obtient des valeurs de R proches de l'unité et on respecte
les conditions de signe sur les paramètres a et b. On notera, à ce propos, un phénomène intéressant. Quelle que soit la formule de départ adoptée pour l'indice (excepté pour la formule U 3 ) , on a toujours obtenu, au fur et à mesure des itérations : pour a un coefficient négatif et non significatif, au départ, évoluant peu à peu vers un coefficient positif non significatif, puis significatif et pour b des coefficients positifs et significatifs.
• L'examen des tableaux montre que la fonction d'utilité du ménage urbain prend effectivement en compte plusieurs caractéristiques relatives Dik (18 ou 19 distances suivant les indicateurs d'utilité). Le caractère
multicentrique de la ville est donc bien significatif pour les structures
Const L z C 1 c 2 C 3 C 4 C 5 c 6 C 7 u 1 - 6 . 1 4 9 0.031 0.254 - 0 . 0 6 2 -0.039 - 0 . 0 3 9 - 0 . 1 1 1 u 1 - 5 9 . 2 0 4 . 5 4 3 0 . 7 6 - 7 . 3 6 - 4 . 4 7 - 3 . 0 7 - 7 . 7 4 u 2 - 9 . 7 2 2 0.015 0. 978 0.051 - 0 . 0 4 2 - 0 . 0 3 1 -0.046 - 0 . 02 - 0 . 0 2 9 0. 2 u 2 - 8 8 . 2 5 3 . 0 8 1 6 6 . 3 7 6 . 1 - 5 . 4 4 - 4 . 0 8 - 5 . 8 - 2 . 0 9 - 2 . 1 6 2 . 1 8 u 2 - 7 . 8 5 4 0. 085 0. 105 - 0 . 2 2 7 -0.282 - 0 . 1 8 1 - 0 . 4 8 6 0. 158 u 2 - 7 . 8 5 3 . 2 3 3 . 2 9 - 6 . 2 7 - 8 . 2 6 - 3 . 4 5 - 6 . 7 5 2 . 9 3 c 8 C 9 C 1 0 C 1 1 C 1 2 C 1 3 C 1 4 C 1 5 c 1 6 c 17 U 1 0.065 -0. 1 0.067 0.065 -0.062 -0.083 0. 097 U 1 6. 4 5 - 5 . 2 5 4 . 0 5 6. 7 9 - 5 . 0 4 - 7 . 3 8 7 6 . 9 5 U 2 0. 03 -0.06 0.067 0.025 -0.05 -0.042 0. 031 U 2 2 . 4 6 - 5 . 7 7 . 4 7 3. 5 7 - 5 . 7 3 - 5 . 3 3 3 . 7 6 U 3 -0. 14 0.3 -0.415 0.285 0.283 -0.247 -0.315 0.51 U 3 - 2 . 7 1 7 . 2 8 - 5 . 6 4 . 4 9 7 . 4 5 - 5 . 1 2 - 7 . 3 3 1 3 . 1 2 c 1 8 C 2 0 C 2 1 C 2 4 C 2 5 C 2 9 c 3 0 C 3 1 R2 U 1 0. 109 0. 15 0.056 0.029 0.056 0.084 - 0 . 0 6 9 0. 82 U 1 1 0 . 0 2 1 2 . 0 9 3 . 8 4 4 . 2 9 7 . 0 9 8. 6 3 - 8 . 3 8 0. 82 U 2 0.069 0 . 0 8 3 0.027 0.016 0. 039 0 . 9 8 U 2 8 . 9 9 8 . 8 3 3 . 4 1 3 . 3 2 7 . 61 0 . 9 8 U 3 0. 527 - 0 . 3 0 4 - 0 . 3 6 1 0. 117 - 0 . 1 - 0 . 1 0 4 - 0 . 2 7 0. 68 U 3 1 . 6 4 - 1 8 . 7 7 - 1 8 . 5 1 4 . 2 6 - 9 . 6 6 - 7 . 9 9 - 9 . 0 6 0. 68
• On s'aperçoit ensuite qu'il existe des structures de préférences spatiales différentes puisqu'en fonction de l'indice d'utilité, des distances supplémentaires sont retenues, tandis que d'autres disparaissent. Par exemple, de l'indice Ui à l'indice U2, les distances aux centres 1, 4, 7, 9 et 21 apparaissent dans la structure de préférence de l'agent tandis que les distances aux centres 11, 24, 30 et 31
disparaissent. On trouve donc une confirmation de l'existence de structure de préférences spatiales différentes en fonction de l'indice d'utilité retenu.
• Par ailleurs, les signes attachés aux distances peuvent varier d'une régression à l'autre : zones 10, 20, 24, 29, 30 et 3 1 , tandis que d'autres sont stables : les quartiers 1, 7, 12, 13, 16 et 18, et les communes de Chevigny (21) et de Longvic (25) sont répulsifs (signe +) en terme de préférences résidentielles, tandis que les quartiers 2, 3 , 4, 5, 6, 8, 11, 14 et 15 sont attractifs (signe - ) . On remarque que ces quartiers sont regroupés géographiquement par lots (groupe des quartiers
contiguïté joue propre au phénomène de multicolinéarité spatiale (Heikkila 1988).
pas de résultat
1 Centre nord 14 Les Perrières
2 Centre sud 15 Monchapet
3 Faubourg nord 16 Jouvence et Pouilly 4 Faubourg sud 17 Maladière
5 Montmuzard 18 Les grésilles
6 Les Péjoces 20 Chenove
7 Les Poussots 21 Chevigny St Sauveur
8 Parc 24 Fontaine les Dijon
9 Arsenal 25 Longvic
10 Les Bourroches 29 Quétigny
11 La Montagne 30 Saint Apollinaire
12 Larrey 31 Talant
13 Hôpital
Figure 1 : Les centres de l'agglomération dijonnaise
On peut encore établir une "hiérarchie d'influence" (cf figure 1) en donnant à chaque coefficent un rang, positif ou négatif (Baumont 1990). Ainsi, la distance 20, du lieu de résidence à la commune de Chenove a la plus grande influence positive et constitue donc le centre
le plus répulsif de l'agglomération en matière de localisation résidentielle. Par contre la distance du lieu de résidence au quartier 11, à la plus forte influence négative : c'est le centre le plus attractif pour la localisation résidentielle. Les distances 1, 12, 16 et 18 ont une influence positive moyenne et la distance 25 a une influence positive faible. Enfin, les distances 2, 6, 14, 15 et 31 ont une influence négative moyenne et les distances 3, 5 et 8 ont une influence négative faible.
La nature instable de certaines zones suivant l'indicateur d'utilité peut s'expliquer par la composition de cet indicateur. En particulier la régression U3 s'oppose aux autres régressions pour le rôle des communes 20, 24, 29, 30 et 31. Lorsqu'on examine ces communes, on remarque qu'elles sont périphériques et plutôt de type pavillonnaire. On peut alors supposer qu'une structure de préférences résidentielles comme celle exhibée par la régression U3 privilégie l'habitat pavillonnaire tandis que celle associée aux autres régressions privilégie l'habitat dense.
Le contenu de l'indice d'utilité appuie cette thèse puisque LÏ3 ne contient que des caractéristiques de zone ce qui renforce la domination des spécificités des zones sur celles des logements (qui peuvent se trouver dans n'importe quelle zone).
Finalement, à chaque indice d'utilité correspond une structure de préférences spatiales qui influence les comportements en matière de localisation résidentielle. Mais au delà de ce résultat prévisible, on remarque que la nature des préférences spatiales modifie aussi les comportements en matière de consommation L et Z. Un premier commentaire s'impose : quel que soit l'indice d'utilité employé, la consommation de bien composite influence plus fortement la satisfaction que la consommation de logement. On peut cependant distinguer deux types de dominance, suivant les régressions : celle associée aux indices d'utilité Ui et U3 d'une part, et celle associée à l'indice d'utilité U2 d'autre part.
• Pour la régression U2 la consommation de logement est largement dominée par la consommation de bien composite : alors que b s'approche de
l'unité, a vaut seulement 0.015.
• Pour les régressions Ui et U3 la contribution de la consommation de bien composite à la satisfaction domine moins fortement la consommation
de logement. On constate même pour la régression U3 que les coefficients tendent à s'égaliser (a = 0.085 contre b = 0.105).
Une explication à ces phénomènes peut être donnée via l'examen de la composition des différents indices d'utilité : U2 ne contient que des caractéristiques a-spatiales de logement, Ui contient à la fois des caractéristiques a-spatiales de logement et des caractéristiques intrinsèques spatiales et enfin U3 ne contient que des caractéristiques intrinsèques spatiales. On dira alors qu'au fur et à mesure que les
caractéristiques intrinsèques spatiales sont introduites dans le calcul de l'utilité, la place de la consommation de logement (bien localisé) dans l'évaluation de l'utilité s'accentue tandis que celle du bien composite (bien non localisé) diminue.
V CONCLUSION
La prise en compte des préférences spatiales dans l'analyse des comportements de localisation résidentielle est une manière de spatialiser les préférences globales des individus. En effet, non seulement, on s'aperçoit que les individus ne sont pas indifférents à la situation géographique de leur résidence, mais qu'en plus les caractéristiques de ces localisations sont importantes. Ainsi, les caractéristiques relatives et intrinsèques des lieux sont tout aussi importantes.
Le concept de préférence spatiale permet en outre de tester le caractère multicentrique d'un espace grâce aux caractéristiques relatives des lieux vis-à-vis des centres économiques. Cependant, la mise en oeuvre de ce test suppose la connaissance des utilités.
Mais, en employant des indicateurs d'utilité aux contenus différents, on peut mettre en évidence des structures spatiales différenciées et donc des comportements de localisation différenciés. En particulier, on montre que les individus n'accordent pas tous la même importance aux centres économiques et qu'ils les jugent soit répulsifs soit attractifs.
Cet article a donc permis d'exhiber des préférences spatiales hétérogènes et on pourra maintenant s' interroger sur le rôle joué par les préférences spatiales dans l'équilibre résidentiel du consommateur.
BIBLIOGRAPHIE
Achour D. and Lapointe A. (1981) "Modèle hédonique de détermination de la valeur des aménités résidentielles" VEconomie du Centre-Est, 1, 71-102. Apps P. F. (1973) "An Approach to Urban Modelling and Evaluation. A Residential Model : 2 Implicit Prices for Housing Services" Environment
and planning, 5, 705-17.
Baumont C. (1990) Contribution à l'analyse des espaces urbains
multicentriques. La localisation résidentielle. Etudes théoriques et
empiriques. Thèse de doctorat, Université de Bourgogne, Dijon.
Baumont C. (1991) "L'équilibre spatial résidentiel dans les villes
multicentriques" Revue d'Economie Régionale et Urbaine, 5, 539-65.
Baumont C. (1992) "L'adéquation entre l'espace physique et l'espace économique multicentrique dans les problèmes de localisation" Revue
d'Economie Régionale et Urbaine, 2, 175-96.
Billot A. (1988) Préférence imprécise et équilibres économiques : une
analyse axiomatique, Thèse de Doctorat ès Sciences Economiques,
Université de Bourgogne, Dijon.
Billot A. (1993) "les préférences spatiales : quelques pistes", document
interne à paraître dans Dietionnaire des concepts en Analyse Spatiale,
Auray, Bailly, Derycke, Huriot Eds, Economica, Paris.
Beckmann M. J. and Papageorgiou Y. Y. (1989) "Heterogeneous Tastes and Residential Location" Journal of Regional Science, 3, 29, 317-23.
Clark W.A.V. and Cadwallader M. (1973) "Residential Preferences : an Alternate View of Intraurban Space" Environment and Planning A, 5, p 693-703.
Coulson N.E. (1991) "Really Useful Tests of the Monocentric Model" Lands
Economics, 67, 3, 299-307.
Debreu G. (1966) Théorie de la valeur, Dunod, Paris.
Fustier B. and Rouget B. (1985) "Approche empirique de la notion de centrante urbaine : le cas de l'agglomération dijonnaise" Document de
travail de l'I.M.E, 74, Université de Dijon.
Gordon P. ,Richardson H.W. and Wong H.L. (1986) "The Distribution of Population and Employment in a Polycentric City : the Case of Los Angeles" Environment and Planning A, 18, 161-73.
Griffith D. A. (1981) "Modelling Urban Population Density in a Multi-Centered City" Journal of Urban Economics, 9, 298-310.
Heikkila E. (1988) "Multicollinearity in Regression Models with Multiple Distance Measures" Journal of Regional Science, 3, 28, 345-62.
Heikkila E., Gordon P., Kim J.I., Peiser R.B. and Richardson H.W. (1989) "What Happened to the CBD-Distance Gradient? : Land Value in a
Policentric City" Environment and Planning A, 21, 221-32.
Johnson M.S. and Ragas W.R. (1987) "CBD Land Values and Multiple Externalities" Land Economics, 63, 4, 337-47.
Lancaster K. (1966) "A New Approach to Consumer Theory" Journal of
Political Economy, 74, 132-57.
Linneman P. (1980) "Some Empirical Results on the Nature of the Hedonic Price Function for the Urban Housing Market" Journal of Urban Economics,
8, 47-68.
Linneman P. (1981) "The Demand for Residence Site Characteristic" Journal
of Urban Economics,9, 129-48
Nelson J.P. (1978) "Residential Choice, Hedonic Prices and the Demand for Urban Air Quality" Journal of Urban Economics, 5, 357-69.
Ödland J. (1978) "The Conditions for Multi-Center Cities" Economic
Geography, 54, 234-44.
Paelinck J.H.P. (1985) Eléments d'analyse économique spatiales, Editions Régionales Européennes, Diffusion Anthropos, Paris.
Papageorgiou Y. Y. (1971) "The Population Density and Rent Distribution Model within a Multicenter Framework" Environment and Planning A, 3, 267-82.
Papageorgiou Y.Y. (1976) "Urban Residential Analysis : 1. Spatial Consumer Behavior" Environment and Planning A, 8, 423-42.
Ponsard C. (1955) Economie et espace. Essai d' intégration du facteur
spatial en analyse économique, SEDES, Paris.
Rouget B. (1981) Equilibre spatial du consommateur : une analyse
multidimentionnelle, Thèse complémentaire, Dijon.
Van Praag B.M.S. and Van Der Sar N. L. (1987) "Household Cost Functions and Equivalence Scales" Journal of Human Resources, 23, 2, 193-210.
Zoller H. G. and Ponsard C. eds (1988), "L'espace résidentiel et le prix du logement" in Analyse économique spatiale, PUF Economie, Paris, 59-92. Zoller H. G. and Paelinck J.H.P. (1982) "Logement et qualités. Une analyse statique à court terme" Document de travail de l'I.M.E., 61, Université de Dijon.
ANNEXE Construction de l'indice d'utilité
La méthode employée repose sur la construction d'une suite de régressions dont on ne retient, à chaque fois que les variables les plus significatives.
Soit la régression suivante : Y = Z p^X^ + e (j = 1 à t)
où Y n'est pas observable directement, mais dont le contenu peut être assimilé à un panier de critères z : r = 1 à s.
r
Plus précisément, on postule que Y est une somme pondérée de ces critères
Y = S q z
r r
1/ On part d'une relation arbitraire = S z , c'est-à-dire que toutes les pondérations q sont égales à 1.
r
2/ On régresse Y^et les variables explicatives du modèle statistique. On obtient alors des estimations p des paramètres p^. Si ces estimations ne sont pas satisfaisantes, car elles ne correspondent pas aux signes attendus, alors on repère toutes les variables X, significatives et on construit une série statistique Y = S p X .
2 * j l j
3/ On régresse avec les critères z et on obtient des estimations q ^ pour les pondérations q .
r
On peut alors remarquer si des critères z préalablement retenus dans
r
l'étape 1/ pour caractériser Y en sont toujours des composantes.
4 / On choisit les critères z les plus significatifs et on construit une
r
série statistique Y = S q z .
3 rl r
5/ On régresse Y^ et toutes les variables explicatives X. du modèle statistique et on réitère les étapes 2/ à 5/ (à chaque fois, une nouvelle expression de Y et une nouvelle régression par rapport aux variables explicatives sont obtenues) jusqu'à ce que l'on obtienne une formule pour
calculer Y qui satisfasse les hypothèses sur les signes des coefficients
Remarques : nous n'avons pas la prétention de donner à cette méthode plus de valeur scientifique qu'elle n'en a réellement. Cependant pour qu'elle ne s'apparente pas à une simple "recette de cuisine" pour obtenir une régression intéressante, nous apportons quelques précisions,
sur les signes des coefficients, il ne s'agit en fait que d'un petit nombre de coefficients, c'est-à-dire que les hypothèses sur les signes ne doivent concerner qu'une ou deux variables explicatives. Pour les autres, c'est le modèle qui doit prédire leur signe.
(b) Il est important de ne retenir, à chaque étape du processus que les
variables explicatives (ou les critères) significatives, c'est-à-dire celles dont le test de Student est vérifié. De ce fait, on ne met pas en oeuvre un procédé parfaitement circulaire, puisqu'à chaque fois une partie du pouvoir explicatif de la forme de Y n'est pas prise en compte. Si on se contentait "de mettre à gauche ce qui se trouvait préalablement à droite", on n'obtiendrait rien de plus pour définir le contenu du panier de critères z caractérisant Y.
r
(c) Le procédé itératif s'arrête quand presque toutes les variables
explicatives X sont significatives, car alors on tend vers une forme stationnaire pour la forme de l'indice. En effet, plus on utilise de variables explicatives et plus on augmente la part de la régression expliquée dans le calcul de l'indice. Celui-ci tend alors à s'identifier à la régression elle-même et les pondérations p^ ou q^ n'évoluent plus aux étapes suivantes.
(d) Les coefficients de corrélation des différentes régressions tendent
vers l'unité, ce qui peut paraître suspect, mais trouve en fait son explication dans la remarque précédente.
RESUME
L'analyse des espaces urbains multicentriques et l'introduction des préférences spatiales dans les modèles de localisation résidentielle sont deux voies d'évolution de l'analyse des espaces urbains. L'objet de cet article est d'analyser le concept de préférences spatiales dans les espaces multicentriques. Son mode d'intégration dans l'analyse des comportements de localisation résidentielle est déjà examiné (section II). Ensuite, nous montrons comment l'utilisation des préférences spatiales peut servir à détecter le caractère multicentrique d'un espace
(section III). Enfin, plusieurs résultats empiriques illustrant les points précédents sont présentés (section IV).
MOTS CLES
Espaces multicentriques, localisation résidentielle, préférences spatiales, utilité spatiale.