Supervised Learning for Sequential and Uncertain Decision Making Problems - Application to Short-Term Electric Power Generation Scheduling
Texte intégral
Figure

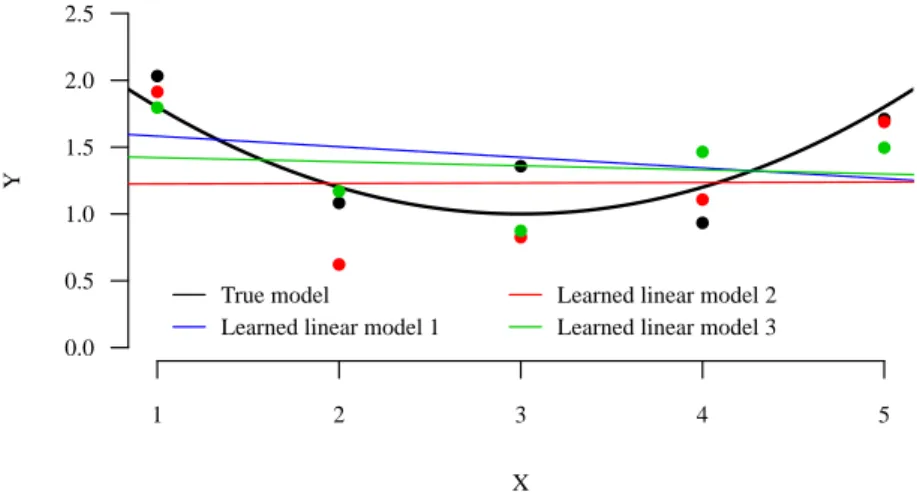
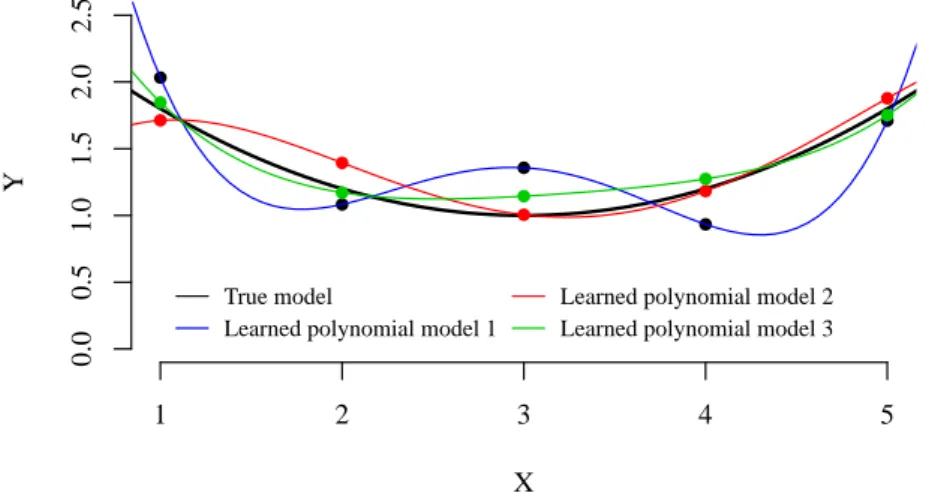
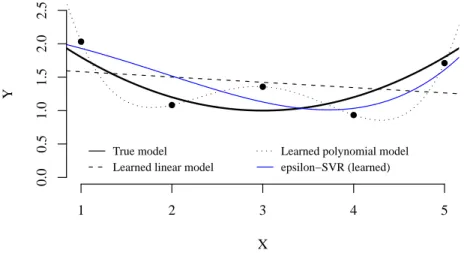
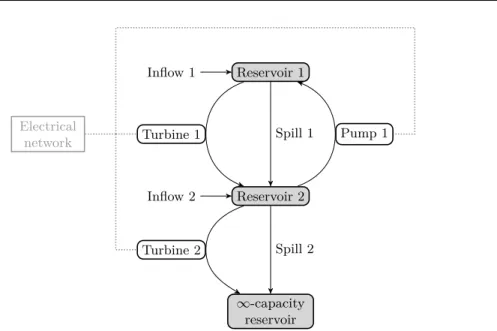
![Figure 3.5: Illustration with K = 3 of the supervised learning application to compute an approximation of π ? t r (ξ [0:t r −1] ).](https://thumb-eu.123doks.com/thumbv2/123doknet/6003735.149668/81.918.229.691.224.586/figure-illustration-k-supervised-learning-application-compute-approximation.webp)
Documents relatifs
El-Eulmi Bendeif, Slimane Dahaoui, Claude Lecomte, Michel Francois, NE Benali-Cherif.
Without formally using the full transition matrix of the designed Markov chain, Monte Carlo sampling techniques can be used to estimate this distribution by sampling
Our framework has proven to successfully mine macro-operators of different lengths for four different domains (barman, blocksworld, depots, satellite) and thanks to the selection
Unite´ de recherche Inria Lorraine, Technopoˆle de Nancy-Brabois, Campus scientifique, 615 rue du Jardin Botanique, BP 101, 54600 Villers Le`s Nancy Unite´ de recherche Inria
Unit´e de recherche INRIA Lorraine, Technopˆole de Nancy-Brabois, Campus scientifique, ` NANCY 615 rue du Jardin Botanique, BP 101, 54600 VILLERS LES Unit´e de recherche INRIA
Enfin, le système de protection était un monde relativement clos et les échappatoires étaient peu nombreuses : certains jeunes, toutefois, retrouvaient leur
א Abstract: understanding balances and fiqh analysis are considered from the accurate methods and complex processes at the scientific level, that provides Islamic jurisprudence
Recently, Chae, Hou and Li [Ch, HL] have proven that Navier-Stokes Boussinesq equations (8,9) (just called Boussinesq equa- tions in these papers) have global smooth solutions when d
