HAL Id: hal-01852650
https://hal.inria.fr/hal-01852650
Submitted on 2 Aug 2018
HAL is a multi-disciplinary open access
archive for the deposit and dissemination of
sci-entific research documents, whether they are
pub-lished or not. The documents may come from
teaching and research institutions in France or
abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est
destinée au dépôt et à la diffusion de documents
scientifiques de niveau recherche, publiés ou non,
émanant des établissements d’enseignement et de
recherche français ou étrangers, des laboratoires
publics ou privés.
Evaluating search engines and defining a consensus
implementation
Ahmed Kamoun, Patrick Maillé, Bruno Tuffin
To cite this version:
Ahmed Kamoun, Patrick Maillé, Bruno Tuffin. Evaluating search engines and defining a consensus
implementation. VALUETOOLS 2019 - 12th EAI International Conference on Performance Evaluation
Methodologies and Tools, Mar 2019, Palma de Majorque, Spain. pp.1-10. �hal-01852650�
Evaluating search engines and defining a consensus
implementation
Ahmed Kamoun
IMT Atlantique
Rennes, France
[email protected]
Patrick Maillé
IMT Atlantique
Rennes, France
[email protected]
Bruno Tuffin
Inria Rennes Bretagne Atlantique
Campus Universitaire de Beaulieu, 35042 Rennes Cedex, France
[email protected]
August 2, 2018
Abstract
Different search engines provide different outputs for the same keyword. This may be due to different definitions of relevance, and/or to different knowledge/anticipation of users’ preferences, but rankings are also suspected to be biased towards own content, which may prejudicial to other content providers. In this paper, we make some initial steps toward a rigorous comparison and analysis of search engines, by proposing a definition for a consensual relevance of a page with respect to a keyword, from a set of search engines. More specifically, we look at the results of several search engines for a sample of keywords, and define for each keyword the visibility of a page based on its ranking over all search engines. This allows to define a score of the search engine for a keyword, and then its average score over all keywords. Based on the pages visibility, we can also define the consensus search engine as the one showing the most visible results for each keyword. We have implemented this model and present an analysis of the results.
1
Introduction
Search Engines (SEs) play a crucial rule in the current Internet world. If you wish to reach some content, except if you have a specific target in mind, you dial keywords on an SE through a web browser to discover the (expected) most relevant content. The number of searches worldwide per year is not precisely known, but just talking about Google, it is thought that they handle at least two trillions of requests per year, and that it can even be much more than that1. As a consequence, if you are a small content provider or a new comer, your visibility and business success will highly depend on your ranking on SEs.
SEs are regularly accused of biasing their rankings2 by not only trying to provide as an out-put an ordered list of links based on relevance, but to also include criteria based on revenues it could drive. The problem was brought in 2009 by Adam Raff, co-founder of the price-comparison company Foundem, saying that Google was voluntarily penalizing his company in rankings with respect to Google’s own services. Such a behavior would indeed be rational from the SE perspec-tive, as it could yield significant revenue increases; a mathematical model highlighting the optimal
1
https://searchengineland.com/google-now-handles-2-999-trillion-searches-per-year-250247 2
See for example
non-neutral–i.e., not based on relevance only–strategies of SEs is for example described in [3]. The issue led to the use of expression search neutrality debate, in relation to the net neutrality debate where Internet Service Providers are accused of differentiating service at the packet level to favor some applications, content, or users. Indeed, similarly, new valid content can hardly be reached if not properly considered by SEs. This is now an important debate worldwide [2, 5, 8]. But while defining a neutral behavior of ISPs at the network level is quite easy, a neutral behavior for SEs involves having a clear definition of relevance. Up to now this relevance is defined by SE-specific algorithms such as PageRank [7], that can additionally be (and are claimed to be) refined by tak-ing into account location, cookies, etc. The exact used algorithms and their relation to relevance are sometimes hard to know without requiring a total transparency of SEs and free access to their algorithms, which they are reluctant to disclose.
Because of the different used algorithms, it is interesting to compare search engines, for example by giving them a grade (or score). It is often said that if someone is not happy, she can just switch, she is just one click away from another SE. But while it could be true in a fully competitive market, it is not so easy in practice with SEs since most people just know one or two SEs and do not have a sufficient expertise to evaluate them and switch. As of May 2018, Statcounter Global Stats3 gives worldwide a market share of 90.14% to Google, 3.24% to Bing, 2.18% to Baidu, 2.08% to Yahoo!...
Our paper has several goals:
• First, to propose a so-called consensus SE, defined such as some “average” behavior of SEs, based on the idea that this average SE should be closer to one truly based on relevance. Considering a list of several SEs, we give a score to all the provided links, by weighing them by the position click-through-rate on each SE, estimating the position-dependent probability to be clicked. The consensus SE then ranks links according to their score.
• To give a score to SEs, comparing their results to the consensus SE. From the score of links, we can give a score to SEs by summing the scores of the presented lists weighted by their positions. It then allows us to rank the SEs themselves and show which one seems the closest to the “optimal” consensus SE, for a single keyword and for a list of keywords.
• To discuss and compare the behavior of SEs with respect to requests in practice. We have implemented and tested our model, computing grades for SEs and distributions of scores in terms of requests. From the rankings of SEs for any keyword, we can also investigate if there is a suspect deviation of some SEs toward their own content with respect to competitors. This would help to detect violations to a (potential) search neutrality principle.
Note that algorithms comparing rankings exist in the literature, see [6] and references therein, based on differences between vectors, but there is to our knowledge no algorithm like ours taking into account the click-through-rates (weights) associated to positions.
The rest of the paper is organized as follows. Section 2 presents the model: the definition of link scores for any keyword, the corresponding SE score as well as the consensus SE. Section 3 presents an implementation of this model in practice and compares the most notable SEs. Finally, Section 4 concludes this preliminary work and introduces the perspectives of extension.
2
Scoring model and consensus search engine
We consider n SEs, m keywords representative of real searches, and a finite set of ℓ pages/links corresponding to all the results displayed for the whole set of searches. When dialing a keyword, SEs rank links. We will limit ourselves to the first displayed page of each SE, considered here for simplicity the same number a for all SEs, but we could consider different values for each SE, and even a = ℓ.
The ranking is made according to a score assigned to each page for the considered keyword. This score is supposed to correspond the relevance of the page. According to their rank, pages are more or less likely to be seen and clicked. The probability to be clicked is called the click-through-rate (CTR) [4]; it is in general SE-, position- and link- dependent, but we assume here for convenience, and as commonly adopted in the literature, a separability property: the CTR of link i at position l is the product q′
iql of two factors, qi′ depending on the link i only, and ql depending on the position l only. We typically have q1 ≥ q2 ≥ · · · ≥qa. The difficulty is that the link-relative term qi, upon which a “neutral” ranking would be based, is unknown. But the′ position-relative terms ql can be estimated, and we assume in this paper that they are known and the same on all SEs, i.e, that SEs’ presentation does not influence the CTR. We then make the following reasoning:
• SEs favor the most relevant (according to them) links by ranking them high, that is, providing them with a good position and hence a high visibility, which can be quantified by the position-relative term ql;
• for a given keyword, a link that is given a high visibility by all SEs is likely to be “objectively relevant”. Hence we use the average visibility offered by the set of SEs to a link, as an indication of the link relevance for that keyword. We will call that value the score of the link for the keyword, which includes the link-relative term q′
i.
• We expect that considering several SEs will average out the possible biases introduced by individual SEs, when estimating relevance; also, the analysis may highlight some SEs that significantly differ from the consensus for some sensitive keywords, which would help us detect non-neutral behaviors.
2.1
Page score
The notion of score of the page as defined by SEs is (or should) be related to the notion of relevance for any keyword. As briefly explained in the introduction, the idea of relevance is subjective and depends on so many possible parameters that it can hardly be argued that SEs do not consider a valid definition without knowing the algorithm they use. But transparency is very unlikely because the algorithm is the key element of their business.
In this paper, as explained above we use a different and original option for defining the score, as the exposition (or visibility) provided by all SEs, which can be easily computed.
Formally, for page i and keyword k, the score is the average visibility over all considered SEs:
Ri,k:= 1 n n X j=1 qπj(i,k) (1)
where πj(i, k) denotes the position of page i on SE j for keyword k. In this definition, if a page is not displayed by an SE, the CTR is taken as 0. Another way to say it is to define a position a + 1 for non displayed pages, with qa+1= 0.
2.2
Search engine score
Using the score of pages (corresponding to their importance), we can define the score of an SE j for a given keyword k as the total “page score visibility” of its results for that keyword. Mathematically, that SE score Sj,k can be expressed as
Sj,k:= X pages i
qπj(i,k)Ri,k,
where again qp = 0 if a page is ranked at position p ≥ a + 1 (i.e., not shown), and for each page i, Ri,k is computed as in Eq. (1).
The SE score can also be computed more simply, by just summing on the displayed pages: Sj,k= a X p=1 qpR˜πj(p,k),k (2)
where ˜πj(p, k) is the page ranked at the pth position by SE j for keyword k, i.e., ˜πj(·, k) is the inverse permutation of πj(·, k).
The higher an SE ranks highly exposed pages, the higher its score. The score therefore corre-sponds to the exposition of pages that are well-exposed on average by SEs.
To define the score of SE j, for the whole set of keywords, we average over all keywords:
Sj := 1 m m X k=1 Sj,k. (3)
2.3
Consensus search engine
From our definitions of scores in the previous subsection, we can define the consensus SE as the one maximizing the SE score for each keyword. Formally, for a given keyword k, the goal of the consensus SE is to find an ordered list of the ℓ pages (actually, getting the first a is sufficient), where π(k)(p) is for the page at position p, such that
π(k)(·) = argmaxπ(·) a X p=1
qpRπ(p),k.
Note that this maximization is easy to solve: it suffices to order the pages such that Rπ(k)(1),k ≥
Rπ(k)(2),k ≥ · · ·, i.e., to display pages in the decreasing order of their score (visibility).
The total score of the consensus SE can then also be computed, and is straightforwardly maximal.
3
Analysis in practice
We have implement in Python a web crawler that looks, for a set of keywords, the results provided by nine different search engines. From those results, the scores can be computed as described in the previous section, as well as the results and score of a consensus SE. The brute results can be found at https://partage.mines-telecom.fr/index.php/s/aG3SYhVYPtRCBKH. The code to get page URLs is adapted to each SE, because they display the results differently. It also deals with results display that can group pages and subpages (that is, lower level pages on a same web site) that could be treated as different otherwise. Another solved issue is that a priori different URLs can lead to the same page. It is for example the case of http://www.maps.com/FunFacts.aspx, http://www.maps.com/funfacts.aspx, http://www.maps.com/FunFacts.aspx?nav=FF, http: //www.maps.com/FunFacts, etc. It can be checked that they actually lead to the same web page output when accessing the links proposed by the SEs. Note on the other hand that it requires a longer time for our crawler to get to each page and check whether the URL gets modified.
We (arbitrarily) consider the following set of nine SEs among the most popular, in terms of number of requests according to https://www.alexa.com/siteinfo:
• Google • Yahoo! • Bing • AOL • ask.com
• duckduckgo • Ecosia • StartPage • Qwant.
We include SEs such as Qwant or StartPage, which are said to respect privacy and neutrality. We also clear the cookies to prevent them from affecting the results (most SEs use cookies to learn our preferences).
We consider 216 different queries included in February 2018 common searches. The choice is based on the so-called trending searches in various domains according to https://trends. google.fr/trends/topcharts. We arbitrarily chose keywords in different categories to cover a large range of possibilities.
We limit ourselves to the first page of search engines results, usually made of the first 10 links. That is, we let a = 10. The click-through rates qp are set as measured in [1] and displayed in Table 1.
q1 q2 q3 q4 q5 q6 q7 q8 q9 q10 0.364 0.125 0.095 0.079 0.061 0.041 0.038 0.035 0.03 0.022
Table 1: CTR values used in the simulations, taken from [1]
3.1
Search engines scores
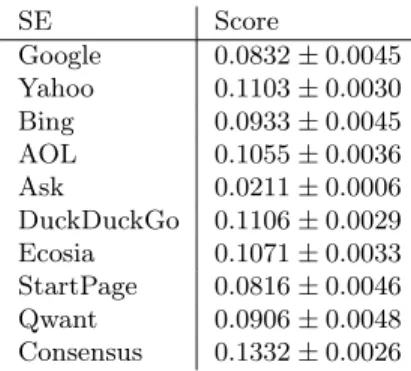
Table 2 provides the average scores of the nine considered search engines, as well as that of the consensus SE, according to Eq. (3). We also include the 95% confidence intervals that would be obtained (abusively) assuming requests are independently drawn from a distribution on all possible requests. Under the same assumption, we can also implement statistical tests to determine
SE Score Google 0 .0832 ± 0.0045 Yahoo 0 .1103 ± 0.0030 Bing 0 .0933 ± 0.0045 AOL 0 .1055 ± 0.0036 Ask 0 .0211 ± 0.0006 DuckDuckGo 0 .1106 ± 0.0029 Ecosia 0 .1071 ± 0.0033 StartPage 0 .0816 ± 0.0046 Qwant 0 .0906 ± 0.0048 Consensus 0 .1332 ± 0.0026
Table 2: SE scores, and 95% confidence intervals half-widths.
whether the scores of search engines are significantly different. The corresponding p-values are given in Table 3. For two search engines, the p-value is the probability of error when rejecting the hypothesis they have similar scores. A small value indicates a statistically significant difference between both search engines (1% means 1% chance of error).
We can remark a group of four SEs with scores above the others: DuckDuckGo, Yahoo!, Ecosia, and AOL, around 0.11. The statistical analysis using the p-value allows to differentiate even more, with DuckDuckGo and Yahoo! as a first group, and Ecosia, and AOL slightly below. Then, Bing and Qwant get scores around 0.09 (and can not be strongly differentiated from the p-value in
Yahoo Bing AOL Ask DuckDuckGo Ecosia StartPage Qwant Consensus Google 1.3e-38 5.5e-05 9.7e-24 7.7e-70 6.3e-42 5.4e-30 1.3e-01 5.4e-03 6.8e-82
Yahoo 5.0e-23 3.5e-08 1.5e-131 5.4e-01 1.9e-04 1.0e-40 2.4e-25 2.4e-129 Bing 5.8e-11 2.6e-81 3.1e-23 2.8e-15 6.6e-06 6.1e-02 4.0e-70 AOL 6.1e-112 3.9e-07 1.3e-01 2.0e-26 1.9e-13 1.6e-78 Ask 4.5e-135 5.1e-120 4.5e-67 8.3e-75 4.0e-163 DuckDuckGo 4.5e-05 4.5e-42 4.4e-25 1.4e-130
Ecosia 5.6e-32 1.8e-17 2.0e-91
StartPage 9.4e-04 2.3e-82
Qwant 1.6e-67
Table 3: p-values for the tests comparing the average scores of search engines (T-test on related samples of scores).
Table 3)), and Google and StartPage around 0.082 (since StartPage is based on Google, close results were expected). Finally, quite far from the others, Ask.com has a score around 0.02.
The consensus SE has a score of 0.133, significantly above all the SEs as shown in Table 3.
3.2
Analysis
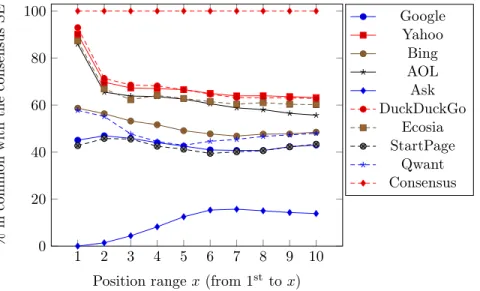
Figure 1 displays by SE the percentage of common results with the consensus SE for each position range. Again for all our searched keywords, we count the proportion of links in the 1st position correspond to the link in 1stposition in the consensus SE, then do the same for the first 2 positions, then for the first 3, etc.
1 2 3 4 5 6 7 8 9 10 0 20 40 60 80 100
Position range x (from 1st to x)
% in co m m o n w it h th e co n se n su s S E Google Yahoo Bing AOL Ask DuckDuckGo Ecosia StartPage Qwant Consensus
Figure 1: Similarities in position with the consensus
The results are consistent with the previous tables: the figure highlights the same groups of SE, while Ask.com clearly is far from the consensus.
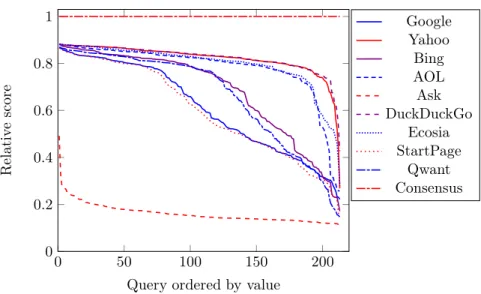
We also draw in Figure 2 the distribution of the score of SEs relatively to the consensus where on the x-axis, we have the pages ordered (for each SE) by the relative score from the largest to the smallest.
It allows to see the variations of score per SE. Again the same SE groups appear, but the infor-mation is stronger than just the mean. For the first quarter of requests, scores are close for all
0 50 100 150 200 0 0.2 0.4 0.6 0.8 1
Query ordered by value
R el a ti v e sc o re Google Yahoo Bing AOL Ask DuckDuckGo Ecosia StartPage Qwant Consensus
Figure 2: Distribution of scores relative to the consensus, from largest to smallest.
SEs except Ask.com, the difference becomes significant later with some SEs which cannot keep up with he best ones.
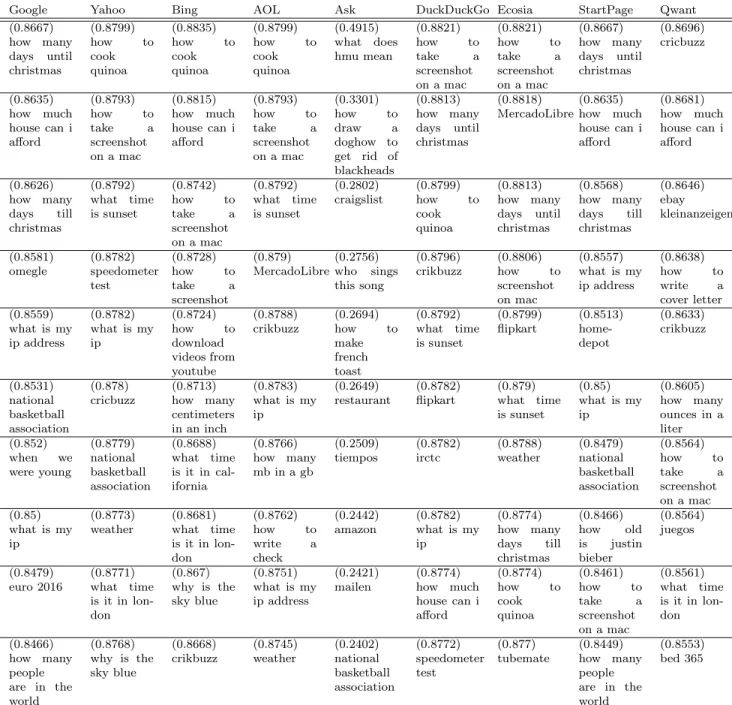
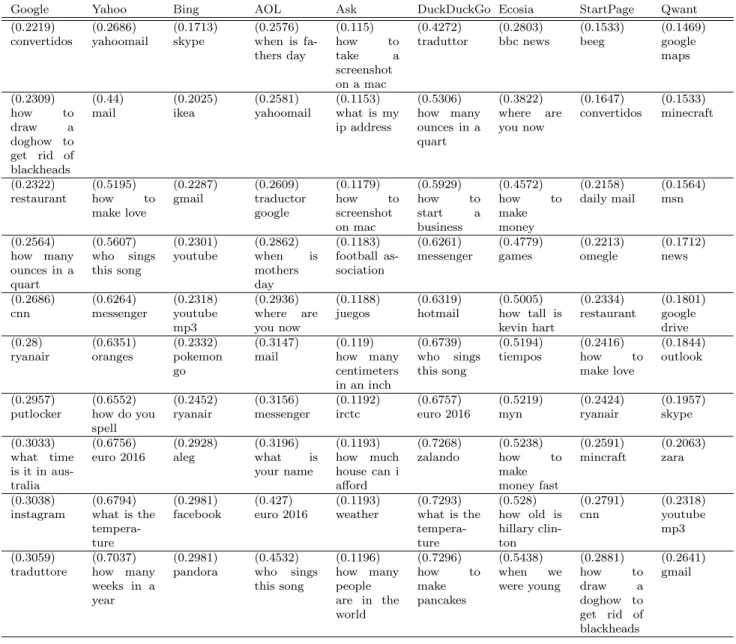
To identify deviations from other search engines, we highlight respectively in Tables 4 and 5 for each SE the (ordered) 10 queries with the highest and lowest relative score with respect to the consensus SE. Those queries correspond to the extreme left (for Table 4) and extreme right (for Table 5) of Fig. 2.
Search terms displayed in Table 4 appear to be quite complex–or specific–searches, for which there is not much room for disagreement among SEs.
On the other hand, Table 5 shows, for each SE, the terms for which they most disagree with the consensus, which may help highlight non-neutral behaviors. For example, it is interesting to note that Bing, the Microsoft-operated SE, differs most from the consensus (hence, from the other SEs) on some sensitive searches such as skype, gmail, youtube, and facebook. Similarly, AOL strongly disagrees with the consensus for yahoomail, mail, and messenger. While Qwant gets low scores for google maps, msn, outlook, news, google drive, skype, and gmail, all involving SE-controlled services. Finally, let us note that we may also have a look at searches like restaurantor cnn, for which Google is far from the consensus: is that to favor its own news and table-booking services? Our study is too preliminary to draw definite conclusions, but can help raise such questions.
4
Conclusions
In this paper, we have defined a measure of relevance of web pages for given queries based on the visibility/response from a whole set of search engines. This relevance takes into account the position of the web page thanks to a weight corresponding to the click-through-rate of the position. It then allowed to define a score of a search engine for a given query, and the average score for a whole set of queries.
We designed a tool in Python allowing to study the scores of nine known search engines and to build the consensus ranking maximizing the SE score, for a set of more that two hundred queries. A first analysis suggests that there are significant differences among search engines, that may help identify some sensitive terms subject to biases in the rankings.
We finally note that our method does not provide an absolute-value score for each SE allowing to decide which is the best one, but rather indicates whether an SE agrees with the others. The user may very well prefer an SE that is far from our consensus ranking, especially if that SE better
takes her preferences into account when performing the ranking.
In a follow up of this preliminary work, we plan to design statistical tests of potentially in-tentional deviations by search engines from their regular behavior, to highlight if non-neutrality by search engines can be detected and harm some content providers. This would be a useful tool within the search neutrality debate.
References
[1] R. Dejarnette. Click-through rate of top 10 search results in Google, 2012. http://www.internetmarketingninjas.com/blog/search-engine-optimization/
click-through-rate, last accessed June 68, 2017.
[2] Inria. Inria’s response to ARCEP consultation about network neutrality, 2012.
[3] P. L’Ecuyer, P. Maillé, N. Stier-Moses, and B. Tuffin. Revenue-maximizing rankings for online platforms with quality-sensitive consumers. Operations Research, 65(2):408–423, 2017. [4] P. Maillé, E. Markakis, M. Naldi, G. Stamoulis, and B. Tuffin. An overview of research on
sponsored search auctions. Electronic Commerce Research Journal, 12(3):265–300, 2012. [5] P. Maillé and B. Tuffin. Telecommunication Network Economics: From Theory to Applications.
Cambridge University Press, 2014.
[6] A. Mowshowitz and A. Kawaguchi. Measuring search engine bias. Information Processing & Management, 41(5):1193 – 1205, 2005.
[7] M. Page, S. Brin, R. Motwani, and T. Winograd. The pagerank citation ranking: Bringing order to the web. Technical Report 1999-66, Stanford InfoLab, November 1999. Previous number = SIDL-WP-1999-0120.
[8] J. D. Wright. Defining and measuring search bias: Some preliminary evidence. George Mason Law & Economics Research Paper 12-14, George Mason University School of Law, 2012.
Google Yahoo Bing AOL Ask DuckDuckGo Ecosia StartPage Qwant (0.8667) (0.8799) (0.8835) (0.8799) (0.4915) (0.8821) (0.8821) (0.8667) (0.8696) how many days until christmas how to cook quinoa how to cook quinoa how to cook quinoa what does hmu mean how to take a screenshot on a mac how to take a screenshot on a mac how many days until christmas cricbuzz (0.8635) (0.8793) (0.8815) (0.8793) (0.3301) (0.8813) (0.8818) (0.8635) (0.8681) how much house can i afford how to take a screenshot on a mac how much house can i afford how to take a screenshot on a mac how to draw a doghow to get rid of blackheads how many days until christmas
MercadoLibre how much house can i afford how much house can i afford (0.8626) (0.8792) (0.8742) (0.8792) (0.2802) (0.8799) (0.8813) (0.8568) (0.8646) how many days till christmas what time is sunset how to take a screenshot on a mac what time is sunset craigslist how to cook quinoa how many days until christmas how many days till christmas ebay kleinanzeigen (0.8581) (0.8782) (0.8728) (0.879) (0.2756) (0.8796) (0.8806) (0.8557) (0.8638) omegle speedometer test how to take a screenshot
MercadoLibre who sings this song crikbuzz how to screenshot on mac what is my ip address how to write a cover letter (0.8559) (0.8782) (0.8724) (0.8788) (0.2694) (0.8792) (0.8799) (0.8513) (0.8633) what is my ip address what is my ip how to download videos from youtube crikbuzz how to make french toast what time is sunset flipkart home-depot crikbuzz (0.8531) (0.878) (0.8713) (0.8783) (0.2649) (0.8782) (0.879) (0.85) (0.8605) national basketball association
cricbuzz how many centimeters in an inch
what is my ip
restaurant flipkart what time is sunset what is my ip how many ounces in a liter (0.852) (0.8779) (0.8688) (0.8766) (0.2509) (0.8782) (0.8788) (0.8479) (0.8564) when we were young national basketball association what time is it in cal-ifornia how many mb in a gb
tiempos irctc weather national basketball association how to take a screenshot on a mac (0.85) (0.8773) (0.8681) (0.8762) (0.2442) (0.8782) (0.8774) (0.8466) (0.8564) what is my ip
weather what time is it in lon-don how to write a check amazon what is my ip how many days till christmas how old is justin bieber juegos (0.8479) (0.8771) (0.867) (0.8751) (0.2421) (0.8774) (0.8774) (0.8461) (0.8561) euro 2016 what time
is it in lon-don why is the sky blue what is my ip address
mailen how much house can i afford how to cook quinoa how to take a screenshot on a mac what time is it in lon-don (0.8466) (0.8768) (0.8668) (0.8745) (0.2402) (0.8772) (0.877) (0.8449) (0.8553) how many people are in the world why is the sky blue
crikbuzz weather national basketball association
speedometer test
tubemate how many people are in the world
bed 365
Table 4: Per SE, ordered list of 10 queries with the largest relative score with respect to the consensus (and their relative scores)
Google Yahoo Bing AOL Ask DuckDuckGo Ecosia StartPage Qwant (0.2219) (0.2686) (0.1713) (0.2576) (0.115) (0.4272) (0.2803) (0.1533) (0.1469) convertidos yahoomail skype when is
fa-thers day
how to take a screenshot on a mac
traduttor bbc news beeg google maps (0.2309) (0.44) (0.2025) (0.2581) (0.1153) (0.5306) (0.3822) (0.1647) (0.1533) how to draw a doghow to get rid of blackheads
mail ikea yahoomail what is my ip address how many ounces in a quart where are you now convertidos minecraft (0.2322) (0.5195) (0.2287) (0.2609) (0.1179) (0.5929) (0.4572) (0.2158) (0.1564) restaurant how to make love gmail traductor google how to screenshot on mac how to start a business how to make money daily mail msn (0.2564) (0.5607) (0.2301) (0.2862) (0.1183) (0.6261) (0.4779) (0.2213) (0.1712) how many ounces in a quart who sings this song youtube when is mothers day football as-sociation
messenger games omegle news
(0.2686) (0.6264) (0.2318) (0.2936) (0.1188) (0.6319) (0.5005) (0.2334) (0.1801) cnn messenger youtube
mp3
where are you now
juegos hotmail how tall is kevin hart
restaurant google drive (0.28) (0.6351) (0.2332) (0.3147) (0.119) (0.6739) (0.5194) (0.2416) (0.1844) ryanair oranges pokemon
go
mail how many centimeters in an inch who sings this song tiempos how to make love outlook (0.2957) (0.6552) (0.2452) (0.3156) (0.1192) (0.6757) (0.5219) (0.2424) (0.1957) putlocker how do you
spell
ryanair messenger irctc euro 2016 myn ryanair skype (0.3033) (0.6756) (0.2928) (0.3196) (0.1193) (0.7268) (0.5238) (0.2591) (0.2063) what time
is it in aus-tralia
euro 2016 aleg what is your name how much house can i afford zalando how to make money fast mincraft zara (0.3038) (0.6794) (0.2981) (0.427) (0.1193) (0.7293) (0.528) (0.2791) (0.2318) instagram what is the
tempera-ture
facebook euro 2016 weather what is the tempera-ture how old is hillary clin-ton cnn youtube mp3 (0.3059) (0.7037) (0.2981) (0.4532) (0.1196) (0.7296) (0.5438) (0.2881) (0.2641) traduttore how many
weeks in a year
pandora who sings this song how many people are in the world how to make pancakes when we were young how to draw a doghow to get rid of blackheads gmail
Table 5: Per SE, ordered list of 10 queries with the smallest relative score with respect to the consensus (and their relative score).