Intégration de la visualisation à multiples vues pour le développement du logiciel
Texte intégral
Figure

![Figure 2.1 – Un extrait des travaux de Healey [40]. Il s’agit d’une visualisation d’une carte géographique avec des bandes représentant par une hauteur et une couleur des variables reliées à la position.](https://thumb-eu.123doks.com/thumbv2/123doknet/11346032.284407/27.918.271.713.375.645/figure-extrait-visualisation-géographique-représentant-variables-reliées-position.webp)
![Figure 2.2 – Exemple de visualisation en médecine montrant les cavités sinusales [47].](https://thumb-eu.123doks.com/thumbv2/123doknet/11346032.284407/30.918.302.681.264.440/figure-exemple-visualisation-médecine-montrant-cavités-sinusales.webp)
![Figure 2.3 – Exemple de visualisation d’informations pour représenter les tendances du vote [24]](https://thumb-eu.123doks.com/thumbv2/123doknet/11346032.284407/31.918.304.680.192.569/figure-exemple-visualisation-informations-représenter-tendances-vote.webp)
![Figure 2.4 – Visualisation des lignes de code à l’aide de bandes de couleurs avec l’outil SEESOFT [2].](https://thumb-eu.123doks.com/thumbv2/123doknet/11346032.284407/33.918.269.709.284.654/figure-visualisation-lignes-code-bandes-couleurs-outil-seesoft.webp)
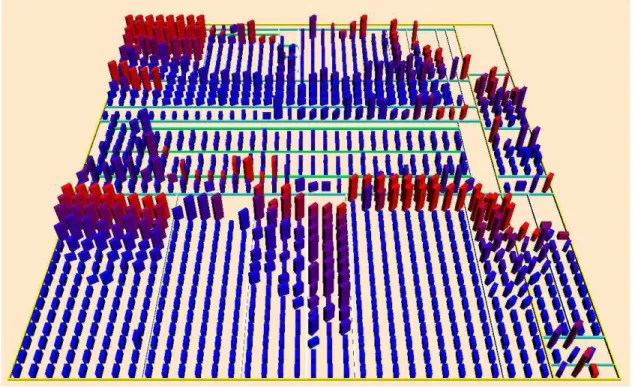
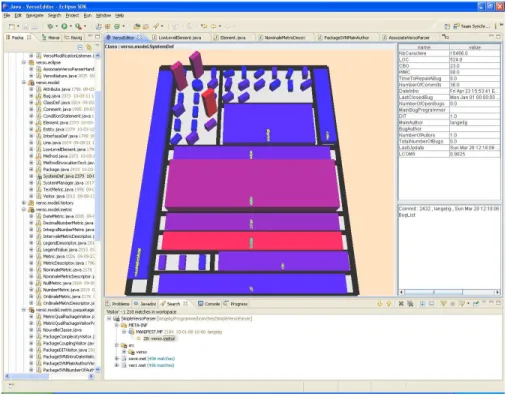
![Figure 2.5 – Représentation de ArgoUML avec Code City [95]. Dans cette visualisation, la hauteur et la taille de la base des éléments représentent des métriques](https://thumb-eu.123doks.com/thumbv2/123doknet/11346032.284407/34.918.273.708.531.790/figure-représentation-argouml-visualisation-hauteur-éléments-représentent-métriques.webp)
![Figure 2.6 – Une vue d’EXTRAVIS [16]. EXTRAVIS est un outil pour la visualisation de grande trace d’exécution](https://thumb-eu.123doks.com/thumbv2/123doknet/11346032.284407/36.918.270.712.470.828/figure-extravis-extravis-outil-visualisation-grande-trace-exécution.webp)
![Figure 2.7 – Visualisation de l’évolution du logiciel à l’aide d’une matrice. Les objets peuvent être aussi simples que des pixels [97] (gauche) ou encore être des symboles plus complexes montrant plusieurs métriques à la fois [55] (droite).](https://thumb-eu.123doks.com/thumbv2/123doknet/11346032.284407/38.918.212.777.164.394/figure-visualisation-évolution-logiciel-symboles-complexes-montrant-métriques.webp)
Documents relatifs
L’annonce est un moment difficile pour les parents mais il ne faut pas oublier que ça n’a certainement pas dû être facile non plus pour le médecin qui leur a annoncé
L’expression « élève en difficulté scolaire » est par exemple utilisée par les enseignants pour désigner un élève dont les méthodes de travail et les démarches de
Dans le chapitre qui suit, nous avons regroupé deux concepts étroitement liés, à savoir, celui de l’altérité et la notion de différence. Ces concepts nous permettront de
La suite logique de cette fonction étant la conception d'un système permettant de générer facilement plusieurs fichiers "bâtiment" en faisant varier la valeur U
Les comptes du systeme Courcier3 quant, a eux, ne se rapportent qu'aux secteurs institutionnels s entreprises, administrations, menages, reste du monde. Une synthese des comptes
Ce.tte reunion devait s'inscrire dans Le programme mondial d'etude et d'applioa- tion.du Systeme de comptabilite nationale revise des Nations Unies, en oe qui oonoerne le secteur
Les delegues ant suggere que l'etude consacTe8 a 1 'urbanisation Bait etendue aux looali tes de moins de 20.000 habitants. lIs ont aussi demande que la oreation de moyens de
En moyenne annuelle, ils fléchissent de 13,7 % Ainsi, dans l’indice genevois des prix à la consommation, plus de la moitié de la baisse des prix des biens et services de
