Lifelogging protection scheme for internet-based personal assistants
Texte intégral
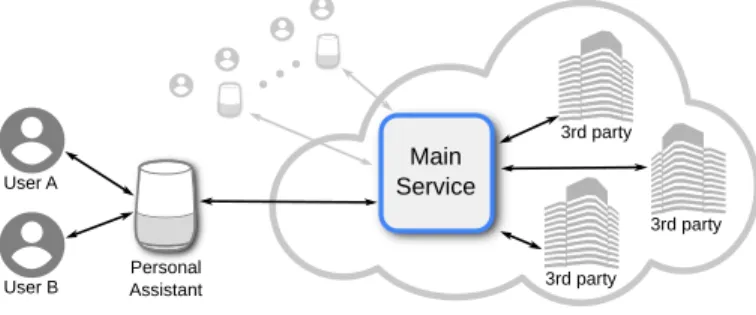
Figure

Documents relatifs
This is a long term store of information about the learner, organised within a user model. We keep the PUML in a Dropbox file system that has been mapped into the user file space.
Keywords: Legal ontology · data protection · information privacy · Pro- tection of Personal Information Act · General Data Protection Regula- tion..
When an instance of the class corresponding to this module is created, the constructor creates a thread for gathering information about processes, process start thread, processes
We have hypothesized within this research program that end user supporting technologies that develop a personal relationship with will provide unique benefits to the user by providing
What these similar technologies lack is the personal feedback loop be- tween the end user and the technology, where the personal assistant adapts to the end user and the
Design parameters and performance characterisation of the DBD plasma actuators that will be employed further on in the thesis to realize instability/flow control in the
In this paper, we introduce a method to generate (non-cryptographics) identity-based signatures computed from 1) collection of data from user biomet- rics, computer configuration,
Department of Allergy, Immunology and Respiratory Medicine, Alfred Hospital and Central Clinical School, Monash University, Melbourne, Victoria, Australia; Department of
