Interactive Elicitation for a Majority Sorting Model with Maximum Margin optimization
16
0
0
Texte intégral
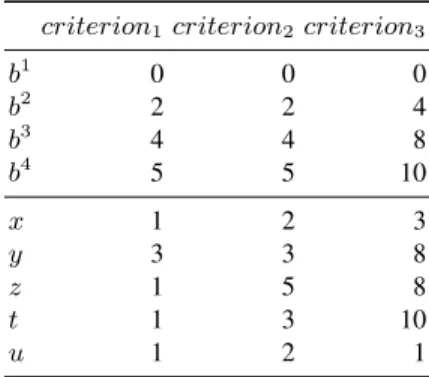
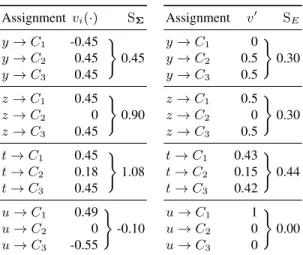
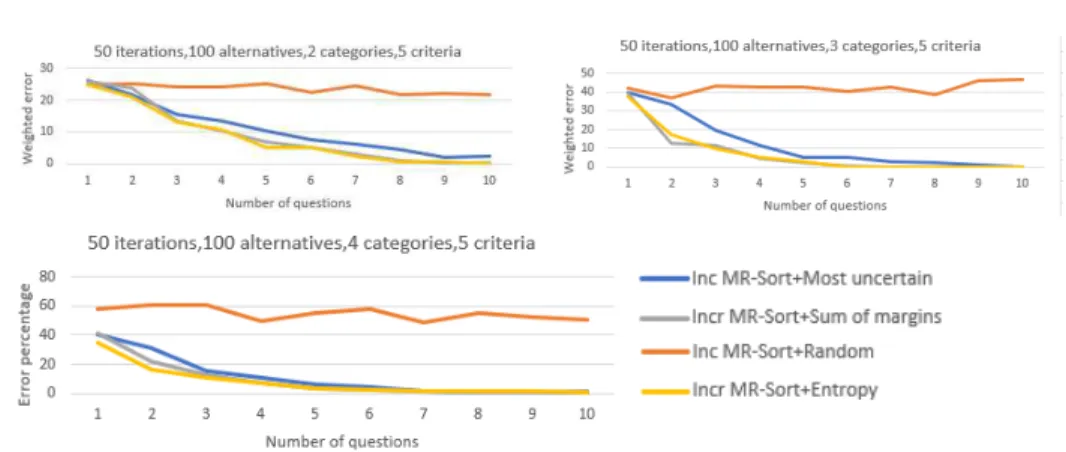
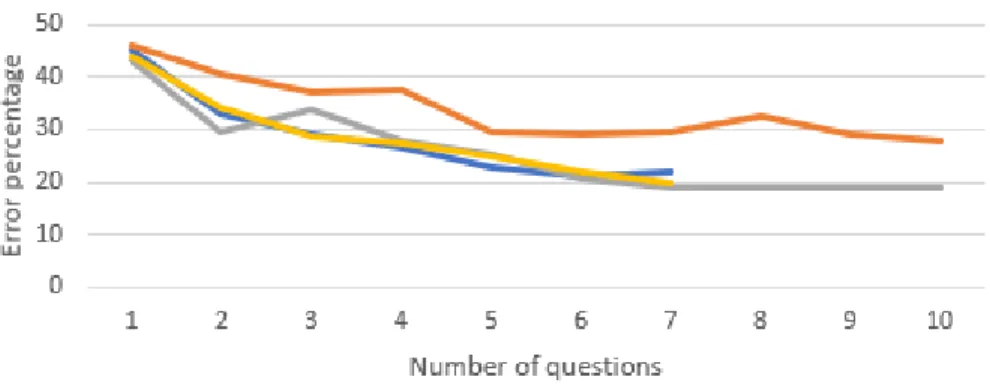
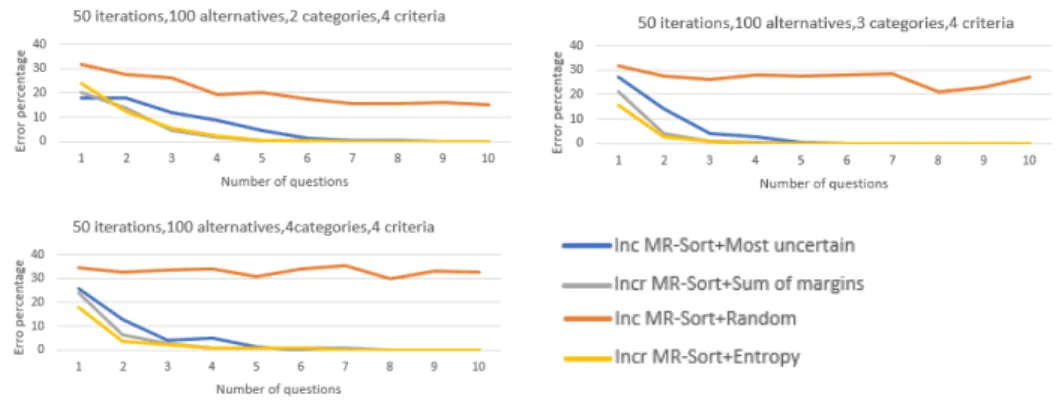
Figure

+3
Documents relatifs