Contrôle d’accès par les ontologies
Outil de validation automatique des droits d’accès
Mémoire
Étienne Théodore SADIO
Maîtrise en informatique
Maître ès sciences (M.Sc.)
Québec, Canada
Résumé
De nos jours, nous assistons à l’émergence d’un écosystème informatique au sein de l’entreprise due à la cohabitation de plusieurs types de systèmes et d’équipements informatique. Cette diversité ajoute de la complexité dans la gestion de la sécurité informatique en général et le contrôle d’accès en particulier. En effet, plusieurs systèmes informatiques implémentent le contrôle d’accès en se basant sur des modèles comme le MAC1, DAC2, RBAC3 entre autres. Ainsi, chaque système a sa propre stratégie donc son propre de modèle de contrôle d’accès. Cela crée une hétérogénéité dans la gestion des droits d’accès.
Pour répondre à ce besoin de gestion du contrôle d’accès, nous avons, dans ce mémoire, présenté la conception d’une ontologie et d’un outil de gestion automatique des droits d’accès dans un environnement hétérogène. Cet outil se base sur notre ontologie qui permet d’introduire une abstraction sur les modèles de contrôle d’accès implémentés dans les différents systèmes à analyser. Ainsi, les administrateurs de sécurité disposent un outil pour valider l’ensemble des droits d’accès dans leurs écosystèmes informatique.
1. MAC : contrôle d’accès obligatoire 2. DAC : contrôle d’accès discrétionnaire 3. RBAC : contrôle d’accès à base de rôles
Abstract
Today, we are seeing the emergence of an IT ecosystem within companies due to the coexistence of several types of systems and computer equipements. This diversity adds complexity in management of computer security in general and particulary in access control. Indeed, several computer systems implement access control techniques based on models like MAC4, DAC5, RBAC6 among others. Each system has its own strategy based on its own access control model. This creates a heterogeneity in the management of access rights.
To respond to this need related to the management of access control, we presented the design of an ontology and we developped an automated management tool of access rights in a hetero-geneous environment. This tool is based on our ontology which introduces an abstraction on access control models implemented in different systems that we want analyze. Thus, security administrators have a tool to validate all access rights in their IT ecosystems.
4. MAC: Mandatory Access Control 5. DAC: Discretionary Access Control 6. RBAC: Role Based Access Control
Table des matières
Résumé iii
Abstract v
Table des matières vii
Liste des tableaux ix
Liste des figures xi
Remerciements xv Introduction 1 Contexte. . . 1 Problematique . . . 2 Objectif et méthodologie . . . 3 Organisation . . . 3
1 Etat de l’art et motivation. 5 1.1 Introduction. . . 5
1.2 Besoins des administrateurs en sécurité informatique . . . 5
1.3 Architecture de système informatique et modèles de contrôle d’accès . . . . 6
1.4 Processus d’audit et de validation des droits d’accès. . . 14
1.5 Outils de gestion des droits d’accès . . . 16
1.6 Modèle UML pour la gestion du contrôle d’accès. . . 21
1.7 Gestion sémantique des droits d’accès : AMO . . . 23
1.8 Conclusion . . . 26
2 Modèle de gestion basé sur le concept des ontologies. 27 2.1 Introduction. . . 27
2.2 Pourquoi une ontologie . . . 27
2.3 Liste des concepts intervenant dans le contrôle d’accès. . . 39
2.4 Relation entre les différents concepts du contrôle d’accès.. . . 40
2.5 Graphe de représentation de l’ontologie. . . 42
2.6 Raisonnement sur la validation des droits d’accès. . . 43
2.7 Conclusion . . . 43
3 Implémantation de l’outil de traitement 45 3.1 Introduction. . . 45
3.2 Architecture . . . 45
3.3 Outils de provisioning . . . 47
3.4 Mécanisme de validation de droits d’accès . . . 47
3.5 Exemple . . . 50
3.6 AVTAC : Framework pour le contrôle d’accès . . . 61
3.7 Conclusion . . . 64
Conclusion 67 Enrichissement de l’ontologie . . . 67
Analyse du domaine de la sécurité informatique plus largement . . . 68
A Document XACML 69 A.1 Traduction droit d’accès linux en XACML . . . 69
A.2 Traduction droit d’accès Windows en XACML . . . 72
Liste des tableaux
1.1 Exemple de liste de contrôle d’accès . . . 10
1.2 Exemple de Les listes de capacités . . . 10
1.3 modèle de contrôle d’accès discrétionnaires. . . 10
1.4 Modèle RBAC . . . 12
2.1 Correspondance OWL-DL et logique descriptive SHOIN(D) . . . 35
3.1 Grammaire BNF d’un sous ensemble de XACML-3.0 . . . 48
3.2 SDDL Syntax . . . 60
Liste des figures
1.1 Caputure d’écrant de SetACL Studio . . . 18
1.2 architecture de OpenIDM . . . 20
1.3 SecureUML Méamodel . . . 23
1.4 Ontologie AMO . . . 25
2.1 Familles de loguique descriptive . . . 34
2.2 Hierarchie des classes. . . 42
2.3 Graph Ontologie Simplifié . . . 43
3.1 Architecture de l’outil de validation. . . 46
3.2 linux strcture basic des droits d’accès. . . 51
3.3 Droit d’accès Linux : Example . . . 51
3.4 ACL Minimale . . . 52
3.5 ACL Etendue . . . 52
3.6 Structure d’un descripteur de sécurité . . . 57
3.7 Example 1 . . . 58
3.8 Example 2 . . . 59
3.9 Language SDDL . . . 59
3.10 Language SDDL : ACE . . . 59
3.11 Capture d’écran n°1 de l’outil de validation . . . 62
3.12 Capture d’écran n°2 de l’outil de validation . . . 62
Je dédie ce mémoire à mon père Aloyse SADIO, à ma mère Ivette Tine et à mes deux soeurs Marie Rosalie Sadio et Josephine Marie Élisabeth Sadio. Vous êtes ma fierté et le rocher sur lequel je m’appuie pour avancer.
Remerciements
Je tiens à remercier tous ceux ou celles qui, de près ou de loin, ont contribué à la réussite de ce travail. Je désire remercier tout particulièrement mon directeur de recherche, le professeur Mohamed Mejri qui m’a accompagné et m’a encadré dans cette aventure. J’ai beaucoup appris avec toi en terme de valeur humaine et d’exigence du travail bien fait. Ton support, tes conseils et tes encouragements m’ont permis d’arriver à un tel résultat.
Je tiens à remercier le professeur Hatem Ben STA qui a supervisé comme codirecteur mon travail et qui a beaucoup contribué dans l’approche intégrant l’utilisation des ontologies. Vous m’avez guidé tout en me laissant la liberté de décider. Merci pour tout.
Je remercie le professeur Kamel Adi qui a accepté de corriger mon mémoire.
J’exprime également toute ma gratitude à mes collègues de LSI, en particulier Khadija Arra-chid, Memel Emmanuel Lathe et Maxime Leblanc, qui, par nos échanges, ont permis d’enrichir mes travaux de recherche.
Aucun mot ne peut exprimer ma gratitude que j’éprouve, pour ma famille qui a été d’un soutien inestimable durant toute cette aventure or de mon pays de naissance. Infiniment merci. Sans vous, cette aventure ne serait pas possible. Et comme le dit un proverbe chinois " Quand tout va bien on peut compter sur les autres, quand tout va mal on ne peut compter que sur sa famille."
Je tiens, également, à faire un clin d’oeil à mes amis qui ont été là pour me motiver et partager des moments formidables. Je veux nommer Adolphe Ndiaye, Jean Édouard Dioh, Anani Thiery Hema, Thierno Barry, Ibrahima Issoufou et Mamadou Seydou Cissé. Merci pour votre disponibilité.
Puisque la montagne ne vient pas à nous, allons à la montagne.
Introduction
Contexte
La sécurité informatique est un monde qui regroupe un ensemble de compétences et de savoir-faire. Cela s’explique par le fait que la notion de sécurité informatique intègre les notions de confidentialité, d’intégrité, de disponibilité, de la non-répudiation, d’imputation et d’authen-tification. L’un des aspects de la sécurité informatique est le contrôle d’accès qui en est un de ces piliers.
Le contrôle d’accès peut-être défini comme étant la vérification qu’une entité demandant l’accès à une ressource a les droits nécessaires pour le faire. Ainsi on peut naturellement le définir comme étant l’ensemble des règles qui régissent cette vérification en se basant sur une politique de sécurité. Dans la vie de tous les jours, cette politique de contrôle d’accès peut être considérée dans plusieurs exemples. Prenons le cas d’une personne qui veut passer la frontière dans un pays ; le contrôle d’accès se définit ici par le fait de s’assurer que la personne dispose de tous ses documents légaux à savoir le passeport, visas et autres.
Dans un autre exemple, une personne qui veut accéder aux ressources d’un cours à l’université, le contrôle d’accès sera la vérification de l’inscription de cette personne à la formation dans laquelle ce cours est donné.
Ces règles sont définies dans le monde de l’informatique en terme de droit d’accès. Le contrôle d’accès peut se résumer alors comme étant la gestion des droits d’accès.
Plusieurs systèmes informatiques implémentent le contrôle d’accès en se basant sur des modèles comme le MAC, DAC, RBAC entre autres. Un modèle de contrôle d’accès permet de définir une stratégie de définition de règles pour l’attribution des droits d’accès. Ainsi, chaque système a sa propre stratégie donc son propre modéle de contrôle d’accès. Cela crée une hétérogénéité dans la gestion des droits d’accès, taches que les administrateurs en sécurités informatiques doivent s’acquitter en prenant le soin de ne pas introduire des erreurs qui peuvent se transformer en faille majeure de sécurité.
Problematique
Pour être compétitive de nos jours, une entreprise doit être flexible en disposant d’une vitesse de réorganisation accélérée pour pouvoir suivre les phénomènes de fusion, de cession d’une activité et d’acquisition d’entreprises. Il suffit de lire la presse économique pour se rendre compte que dans les entreprises ça évolue de plus en plus vite.
De plus, avec la place de choix qu’occupent les systèmes informatiques dans la compétitivité de l’entreprise moderne, il va de soit que toute réorganisation au sein de l’entreprise affecte l’organisation des systèmes informatiques.
Ainsi la tâche de gestion des systèmes informatiques est plus complexe du fait de la diversité des solutions techniques informatiques (équipements réseau divers, OS multiples (Linux, Mac, Windows), appareil mobile). Pour les administrateurs, il est primordial de pouvoir remplir tout cahier de charge induit par une réorganisation au sein de l’entreprise, aussi bien durant une fusion, une cession ou une acquisition que lors de changement occasionner par un flux de personnel.
Dans MAGDA7 (Methode d’administration et de gestion des droits et accréditation), le Club de la sécurité des systèmes d’information français (CLUSIF8) a fait plusieurs constats :
– L’administration des systèmes de sécurité est faite par des personnes les plus aptes et les mieux placer au sein de l’entreprise pour les contourner. Ainsi cette population s’attribue en général des droits exorbitants pour accomplir leurs tâches.
– L’intégration des métiers au système informatique provoque un accroissement de l’hété-rogénéité des plates-formes et des méthodes d’administrations.
– La vitesse de la réorganisation dans l’entreprise induite par les rachats, les fusions et les absorptions d’entreprises se propage mal ou trop lentement dans l’attribution des droits d’accès.
– La restructuration et réorganisation provoque un flux de départs, d’absences, de rempla-cements et très souvent l’intervention d’acteurs externes a l’entreprise. On assiste alors à une mauvaise gestion de ces flux en termes de contrôle d’accès.
– La gestion combinatoire insupportable dès que l’entreprise dépasse une taille modeste et/ou que l’on fait face à un environnement réellement ouvert (n utilisateurs confrontés à m ressources pour p types d’usages).
Ces constatations montrent les grands défis de l’affectation des droits d’accès au sein d’une entreprise. Il s’agit d’un processus qui a besoin d’être audité et validé régulièrement. D’où
7. MAGDA :http ://www.clusif.asso.fr/fr/production/ouvrages/pdf/magda.pdf 8. CLUSIF :https ://www.clusif.asso.fr/
la pertinence de fournir aux administrateurs de sécurité informatique un outil de gestion automatisé des droits d’accès.
Objectifs et méthodologie
L’objectif de nos travaux est de fournir aux administrateurs des outils pour auditer et valider des droits d’accès dans un environnement hétérogène. Notre méthodologie consiste à :
– comprendre les différents modèles du contrôle d’accès et d’étudier les modèles les plus utilisés dans l’industrie ;
– trouver des concepts du domaine de la sécurité informatique pour décrire et retrouver tous les modèles de contrôle d’accès
– montrer comment l’utilisation de la technologie des ontologies permet de retrouver les différents concepts du contrôle d’accès.
Organisation
Le présent document est orgamisé comme suit :
– Le premier chapitre détaillera les motivations qui ont suscité nos travaux en analysant les besoins des entreprises sur le plan du contrôle d’accès. Nous décrirons le contrôle d’accès et ces différents modèles, pour finir par un état de l’art des outils et technologie qui sont présent dans le marché de la gestion des droits d’accès.
– Dans le second chapitre, nous allons présenter notre approche utilisant la technologie des ontologies. Une présentation générale des ontologies sera faite dans un premier temps, et nous montrerons en quoi l’utilisation des ontologies peut servir à mettre en oeuvre un outil de gestion et d’audit du contrôle d’accès.
– Dans le troisième chapitre nous présenterons notre outil de gestion et de validation des droits d’accès, en montrant l’architecture générale de notre prototype, et présenter ses modes de fonctionnement.
– Nous allons finir notre document par une conclusion où nous dégagerons les perspectives de nos travaux.
Chapitre 1
Etat de l’art et motivation.
1.1
Introduction
Le contrôle d’accès est l’un des fondements de la sécurité informatique. Dans plusieurs entre-prises, la tâche première des administrateurs en sécurité est de faire la gestion, l’audit et la validation d’accès aux ressources. Alors, il est important de mettre le doigt sur l’analyse des besoins des administrateurs en thermes de sécurité informatique pour montrer la probléma-tique liée au contrôle d’accès. De plus, mettre en relief la compréhension informelle et formelle du contrôle d’accès, de la politique de contrôle d’accès et des différents modèles de contrôle d’accès nous permettra de fournir les mécanismes d’audit et de validation des droits d’accès au sein des entreprises. Ainsi, il sera plus facile d’interroger l’état de l’art, afin de montrer ce qui se fait dans le marché de l’informatique.
1.2
Besoins des administrateurs en sécurité informatique
De nos jours, dans les structures sociales, professionnelles et même familiales, l’informatique occupe une place très importante. De plus, nous assistons à l’interconnexion des différentes ressources informatiques à travers un réseau local ou même via internet.
Une personne utilisant les nouvelles technologies ne peut pas se passer de gadgets, comme l’ordinateur, le Smartphone et la tablette de lecture, qui sont devenus indispensables avec l’avènement des réseaux sociaux comme Facebook, Linkedin et autres. Ainsi cette personne voudra passer d’un gadget à l’autre et y retrouver ses mêmes logiciels favoris, elle voudra aussi partager ses centres d’intérêt (vidée, musique, photo) avec le monde qui l’entoure en utilisant ses gadgets.
De même à l’échelle de l’entreprise comme à l’échelle de la personne, les métiers s’appuient sur des systèmes informatiques pour plus d’efficacité en terme d’organisation et d’optimisation. De plus, ces systèmes sont connectés et la notion de partage de ressources est présente.
Cependant, la mise en oeuvre du contrôle d’accès à toutes les ressources informatiques (fichiers, équipements, logiciels) est un problème qui représente un danger autant à l’échelle d’une personne qu’à l’échelle de l’entreprise. Il est vrai que pour une personne l’ignorance du danger peut s’expliquer, car la majorité des personnes qui utilisent ces outils informatiques sont des novices et n’appréhendent pas toutes les implications des risques encourus.
Par contre dans une entreprise, ce danger commence à être pris en considération du faite de la médiatisation des dommages qu’auraient subis d’autres entreprises à cause d’attaques malveillantes aussi bien à l’interne qu’à l’externe.
Ainsi le concept de politique de sécurité de système informatique sur lequel repose le système d’information est une chose qui a trouvé une place de choix dans les entreprises. Cette politique de sécurité recouvre plusieurs notions de sécurités à savoir l’intégrité des données, la confi-dentialité, la non-répudiation. Ces notions de sécurités doivent être assurées par un ensemble de mécanismes parmi lesquels le contrôle d’accès. La mise en oeuvre de ce dernier pose une vraie problématique ce qui fait qu’elle a une place importante dans toute cette architecture de sécurité et pour cette raison elle a sa propre politique.
Une aide non négligeable est apportée par la connaissance de certains modèles de contrôle d’ac-cès qui entrainent dans leur implémentation une méthodologie de gestions des droits d’acd’ac-cès par les administrateurs.
1.3
Architecture de système informatique et modèles de
contrôle d’accès
La conception d’un système d’information est faite à partir des besoins de l’entreprise qui va l’utiliser. Ainsi, les architectures des systèmes informatiques varient d’une entreprise à l’autre. On peut alors remarquer que cette diversité implique l’existence de plusieurs manières de faire le contrôle d’accès. Donc, il est primordial de savoir quel modèle de contrôle d’accès est implémenté dans une architecture d’un système donné.
Cependant une majorité des technologies informatiques comme les équipements réseaux, les OS1, les SGBD2 et les PGI3, etc. utilisés dans les entreprises sont développées avec des exigences très génériques et ils implémentent leurs propres modèles de contrôle d’accès. Dès lors il est pertinent d’avoir une bonne connaissance et maitrise des modèles de contrôles d’accès les plus rependus et implémentés.
1. Systemes d’exploitation, ex : Windows linux 2. Systeme de gestion de base de données 3. progiciel de gestion intégré
1.3.1 Cadre sémantique pour le contrôle d’accès
Dans [1] on y décrit un cadre sémantique pour le contrôle d’accès afin de pouvoir traduire les modèle de contrôles d’accès dans une représentation unique.
Définitions et notation
Entités : Les entités du système peuvent être réparties en deux ensembles : l’ensemble S des sujets, également appelés entités actives, qui correspondent aux entités qui effectuent les actions dans le système, et l’ensemble O des objets, également appelés entités passives, qui subissent les actions. Les sujets et les objets sont généralement considérés comme des entités atomiques. Dans certains modèles, on parle d’utilisateur plutôt de sujet. Ces deux ensembles ne sont pas nécessairement disjoints : par exemple, un processus peut à la fois être un sujet et ainsi effectuer des opérations, et un objet, dans le cas où un autre processus tente de l’arrêter. Exemple : Considérons un système de gestion des ressources. L’ensemble Se= {s1, s2, . . . , sn}
représente les utilisateurs du réseau, et l’ensemble Oe = {o1, o2, . . . , om} représente les
res-sources (imprimantes, stockage réseau, scanners, etc.).
Accès : l’ensemble A des modes d’accès caractérisent les différents types d’accès effectués par les sujets sur les objets. Cet ensemble contient généralement lire, écrire, éxécute. Une approche classique consiste à représenter un accés, noté A par un triplet (s, o, x) signifiant que le sujet s accéde à l’objet o selon le mode d’accès x.
Exemple : Considérons un système de gestion des ressources. L’ensemble Se= {s1, s2, . . . , sn}
représente les utilisateurs du réseau, et l’ensemble Oe = {o1, o2, . . . , om} représente les
res-sources (imprimantes, stockage réseau, scanners, etc.). L’ensemble Ae est défini commme le
produit cartésien Se× Oe× Ae , oû Ae= {lire; ecrire}.
Parametres de sécurité : Il est souvent nécessaire d’associer de l’information aux entités afin de pouvoir exprimer la politique de sécurité et également décrire précisément le systéme. Ces informations sont construites à partir de ce que nous appelerons les paramétres de sécurité, noté par ρ.
Exemple : dans la suite de l’exemple précédant, chaque utilisateur et chaque ressource peut appartenir à une ou plusieurs équipes de travail (comptabilité, ressources humaines, etc.), et nous introduisons le paramétre de sécurité ρ = {t1, t2, . . . , tk}, où chaque tireprèsente un nom
d’équipe.
État : Un état représente le système à un instant donné et contient au moins une description de l’ensemble des accès courants, c’est-à-dire de tous les accès qui ont été acceptés et qui n’ont pas encore été relachés. L’ensemble des états est noté Σ.
Fonction de securité : Un état doit également définir un ensemble de fonctions de sécurité, qui relient les différentes entités aux paramètres de sécurité. Étant donné que ces fonctions de sécurité sont spécifiées par les états, elles peuvent être modifiées lors de transitions, contraire-ment aux paramètres de sécurité, qui sont fixes pour une politique donnée. On definit Υ(σ), σ dans Σ, représente l’ensemble des fonctions de sécurité de l’état σ.
Υ : Σ → SF SF : ensembles des fonctions de sécurité.
Accès courant : Un accès courant désigne un accès qui a été accepté et qui n’a pas encore été relâché. La fonction qui transforme un ensemble d’états en un ensemble d’accès courants est noté Λ. Ainsi on a :
Λ : Σ → ℘(A)
Oû ℘(A) désigne l’ensemble des parties de A. Etant donné un état σ, Λ(σ) représente l’ensemble des accés courants du systéme dans l’état σ.
Exemple : La fonction ts: Se→ ℘(ρ) (resp. to : Oe → ℘(ρ)) associe à chaque utilisateur (resp.
ressource) un ensemble d’équipes. Un état σ ∈ Σ est un triplet (m ; ts; to), où m ∈ ℘(Ae) est
un ensemble d’accés et ts et to sont les fonctions de sécurité introduites ci-avant. Pour un état
σ = (m; ts; to), on a donc Λ(σ) = m et Υ(σ) = (ts; to).
Prédicat de securité : Une politique de sécurité spécifie les états sûrs d’un système. Ces états sûrs sont caractérisés par un prédicat. On note par Ω le prédicat de sécurité caractérisant un état respectant la politique de sécurité. En effet, l’ensemble σ ∈ Σ | Ω(σ) des états sûrs est noté Σ|Ω
Exemple : La politique considérée pour la gestion de ressources consiste à imposer que si un utilisateur accéde à une ressource, alors il doit appartenir à une équipe à laquelle appartient la ressource et impose qu’un utilisateur ne puisse accéder à plus de trois ressources differentes en même temps. On definit le prédicat Ωe ainsi :
∀σ = (m, ts, to) ∈ Σe Ωe(σ) ⇔ ∀s ∈ Se ∀o ∈ Oe ∀x ∈ Ae (s, o, x) ∈ m ⇒ ts(s) ∩ to(o) 6= ∅ ∧ ∀s ∈ Se x ∈ Ae card({o ∈ Oe| (s, o, x) ∈ m}) ≤ 3
Politique de sécurité : Une politique de contrôle d’accès dans un système informatique est l’attribution ou la non attribution de permissions pour accéder à une ressource. Formellement une politique de contrôle d’accès P par un quintuple :
P = (S, O, A, Σ, Ω).
où S est un ensemble de sujets non vide, O un ensemble d’objets, A est un ensemble de mode d’accès, Σ est l’ensemble des états sur lequel le système est mise en oeuvre, et Ω est le prédicat de sécurité qui définit les états sûrs du systéme.
Pour implémenter une politique de sécurité dans un système donné, il y a un grand nombre d’approches et de philosophies. La création de modèles de contrôle d’accès permet de mettre en pratique ces différentes approches et tous les modèles peuvent être retrouvés dans le cadre sémantique décrit dans cette sous-section. Ainsi, nous allons présenter quelques modèles dans la sous-section qui suit.
1.3.2 Exemples de modèles de contrôle d’accès
Il existe plusieurs modèles de contrôle d’accès bien documentés dans la littérature de la sécurité informatique et de nombreux articles en décrivent un grand nombre d’extensions.
Un travail exhaustif a été réalisé dans [2] pour décrir les modèles de contrôle d’accès les plus utilisés. Dans ce qui suit, nous allons présenter quelques-uns de ces modèles en les classifiants en trois catégories qui sont les modèles classiques, les modèles à rôles et les modèles alternatives. Modèles classiques
Modèles discrétionnaires Les modèles de contrôles d’accès discrétionnaires sont des moyens de limiter l’accès aux objets basés sur l’identité des sujets ou des groupes auxquels ils appar-tiennent. Les accès sont discrétionnaires, car un sujet avec une certaine autorisation d’accès est capable de transmettre cette permission à n’importe quel autre sujet.
Exemples :
– Liste de contrôle d’accès (ACL Access Control List)
Avec les ACL, une information est rattachée à chaque objet. Il s’agit d’une liste qui spécifie pour chaque sujet les droits d’accès à cet objet. Voici un petit exemple : On considére l’ensemble d’objets {toto; titi; tata}, l’ensemble de sujets {diane; florian}, ainsi que les droits d’accès {lecture; ecriture}.
Ainsi, l’utilisateur diane peut accéder en écriture à l’objet tata et en lecture à l’objet titi et à l’objet toto ; tandis que, l’utilisateur florian peut lire et écrire l’objet toto et lire l’objet titi.
Objet Liste
toto [(diane,lecture) ;(florian,écriture) ;(floriant, lecture)] titi [(diane,lecture) ; (florian,lecture)]
tata [(diane, écriture)]
Table 1.1: Exemple de liste de contrôle d’accès
– Listes de capacités (capabilities list)
Les listes de capacités fonctionnent sur le même principe que les ACL, sauf que les listes de droits d’accès sont rattachées aux sujets au lieu des objets. Les capacités sont l’autre face de la médaille du discrétionnaire. Chaque sujet a conscience de sa propre existence et de son interaction avec le monde. Exemple : En reprenant les mêmes sujets, objets et droits d’accès que ci-dessus, voici l’exemple repris en capacités :
sujet liste
diane [(toto,lecture) ;(titi,lecture) ;(tata,écriture)] florian [(toto,lecture) ;(titi,lecture) ;(toto,écriture)]
Table 1.2: Exemple de Les listes de capacités
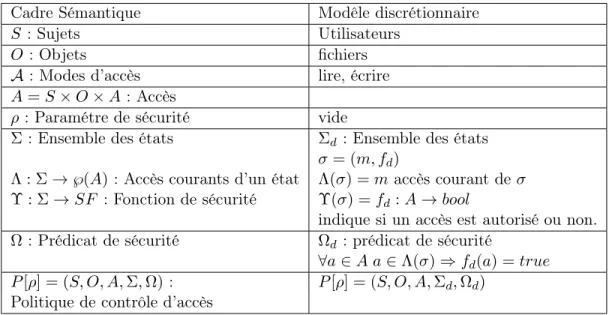
Dans le modèle de contrôle d’accès discrétionnaires on peut décrire le cadre sémantique pour identifier les different éléments du modèle. On a ainsi :
Cadre Sémantique Modêle discrétionnaire
S : Sujets Utilisateurs
O : Objets fichiers
A : Modes d’accès lire, écrire
A = S × O × A : Accès
ρ : Paramétre de sécurité vide
Σ: Ensemble des états Σd: Ensemble des états
σ = (m, fd)
Λ : Σ → ℘(A): Accès courants d’un état Λ(σ) = m accès courant de σ Υ : Σ → SF : Fonction de sécurité Υ(σ) = fd: A → bool
indique si un accès est autorisé ou non. Ω: Prédicat de sécurité Ωd: prédicat de sécurité
∀a ∈ A a ∈ Λ(σ) ⇒ fd(a) = true P [ρ] = (S, O, A, Σ, Ω): P [ρ] = (S, O, A, Σd, Ωd)
Politique de contrôle d’accès
Table 1.3: modèle de contrôle d’accès discrétionnaires
Modèle mandataires Le contrôle d’accès mandataire est exprimé en termes de niveaux de sécurité associés aux sujets et aux objets et à partir desquels sont dérivées les actions autorisées.
Il est utilisé lorsque la politique de sécurité des systèmes d’information impose que les décisions de protection ne doivent pas être prises par le propriétaire des objets concernés, et lorsque ces décisions de protection doivent lui être imposées par ledit système. Ces particularités sont : le modèle est fortement centralisé et il est rigide, mais contrôlable.
Comme exemples, on peut citer le modèle de Bell et LaPadula [3] qui est utilisé principalement dans les environnements militaires à cause de son contrôle centralisé, et il permet à l’adminis-trateur du système de définir des privilèges pour protéger la confidentialité et l’intégrité des ressources dans le système.
Les politiques obligatoires les plus fréquemment utilisées sont les politiques multiniveaux. Ces politiques reposent sur des classes de sécurité affectées aux informations et des niveaux d’habilitations actées aux utilisateurs.
Modèles à rôles
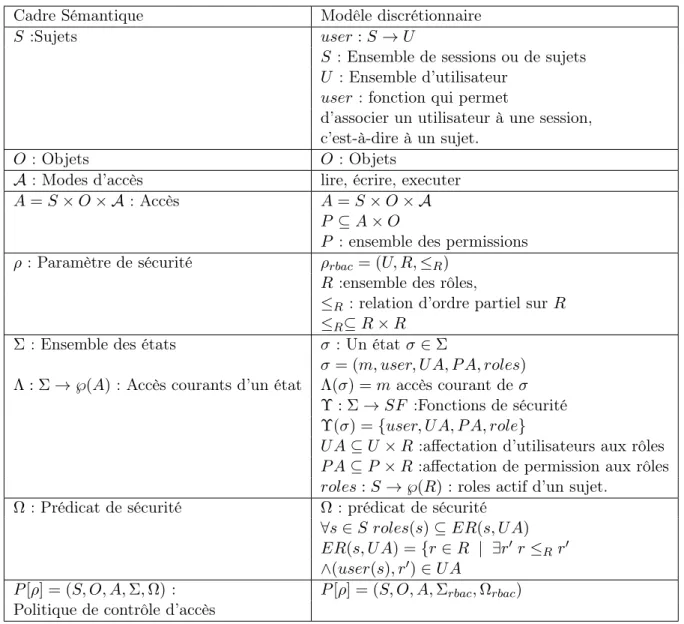
Modèle RBAC RBAC (Role Based Access Control ) est présenté dans [4]. Le principe de ce modèle est d’offrir un accès à l’information selon les rôles assignés aux sujets. Dans ce modèle, le rôle est le concept principal, les privilèges sont accordés à un rôle et si ce rôle est associé à une ou plusieurs entités, alors les entités obtiennent les privilèges indirectement à travers les rôles. Le cadre sémantique de RBAC est donné dans le tableau 1.4.
Dans le modèle RBAC [5], on fait une distinction entre les sujets et les utilisateurs. En effet, on considère un ensemble d’utilisateurs U comme étant l’entité qui peut initier une ou plusieurs sessions dans le système considéré. C’est la notion de session qui correspond à l’ensemble S des sujets dans RBAC. Ainsi, la fonction user permet d’associer un utilisateur à une session. Dans RBAC l’ensemble O des objets est complètement arbitraire et les modes d’accès classiques (lire, écrire, exécuter, etc.) sont aussi utilisé sur les objets. RBAC introduit la notion de permission. Une permission met en relation des opérations, ici identifier aux modes d’accès, et des objets. On note par P l’ensemble des permissions. P permet de considérer des modes d’accès spécifique à certains objets. Exemple : soit S = {s1, s2, s3, s4} et O = {o1, o2}. P =
{(a1; o1), (a1; o2), (a2; o1), (a2; o2)}avec ai ∈ A.
Dans le modèle RBAC le paramétre de sécurité ρrbac regroupe l’ensembles des utilisateurs U,
car la notion d’utilisateur va servir à spécifier un rôle associé à un sujet, l’ensemble des rôle noté R et une relation d’ordre partiel ≤R. Un état appartenant à Σrbac constitu un ensemble
d’accès courants m et les fonctions de sécurité suivantes : – user qui permet d’associer un utilisateur à un sujet ;
– role qui permet de faire le lien entre un utilisateur et les permissions qui lui sont associées. Cela est réalisé par les deux relations UA et P A.
Cadre Sémantique Modêle discrétionnaire
S :Sujets user : S → U
S : Ensemble de sessions ou de sujets U : Ensemble d’utilisateur
user : fonction qui permet
d’associer un utilisateur à une session, c’est-à-dire à un sujet.
O : Objets O : Objets
A : Modes d’accès lire, écrire, executer
A = S × O × A : Accès A = S × O × A
P ⊆ A × O
P : ensemble des permissions ρ : Paramètre de sécurité ρrbac= (U, R, ≤R)
R :ensemble des rôles,
≤R : relation d’ordre partiel sur R
≤R⊆ R × R
Σ: Ensemble des états σ : Un état σ ∈ Σ
σ = (m, user, U A, P A, roles) Λ : Σ → ℘(A): Accès courants d’un état Λ(σ) = m accès courant de σ
Υ : Σ → SF :Fonctions de sécurité Υ(σ) = {user, U A, P A, role}
U A ⊆ U × R :affectation d’utilisateurs aux rôles P A ⊆ P × R:affectation de permission aux rôles roles : S → ℘(R): roles actif d’un sujet.
Ω: Prédicat de sécurité Ω: prédicat de sécurité ∀s ∈ S roles(s) ⊆ ER(s, U A) ER(s, U A) = {r ∈ R | ∃r0 r ≤Rr0
∧(user(s), r0) ∈ U A
P [ρ] = (S, O, A, Σ, Ω): P [ρ] = (S, O, A, Σrbac, Ωrbac)
Politique de contrôle d’accès
Table 1.4: Modèle RBAC
– roles qui définit l’ensemble des rôles actifs d’un sujet à un instant donnée. RBAC impose que les rôles actifs associés à un sujet, c’est-à-dire à une session, appartiennent à l’en-semble des rôles "autorisés" pour l’utilisateur qui a lancé cette session. Ainsi le prédicat de sécurité Ωrbac respect la propriéte suivante :
∀s ∈ roles(s) ⊆ ER(s, U A), ER(s, U A) = {r ∈ R | ∃r0r ≤Rr0∧ (user(s), r0) ∈ U A}
Il est important de noter que la propriété indique qu’un sujet peut activer un rôle qui n’est pas en relation avec son utilisateur suivant UA, grâce à l’ordre partiel ≤R.
En pratique pour mettre en ouvre un modèle RBAC, il faut bien définir les rôles, cette définition peut être faite en se basant sur les données des services RH d’une entreprise. En effet, un rôle
peut être créé sur la base du service et du lieu de travail d’un employé. Cette approche permet de générer une matrice qui fait l’attribution automatique des droits d’accès pour un nouvel employé. Comme exemple, si un infirmier est affecté dans le service de chirurgie dans un nouvel hôpital, il se voit automatiquement attribuer les droits d’infirmier en chirurgie qui vont lui permettre de jouer pleinement son rôle.
Extensions du modele RBAC Il existe de nombreuses extensions faites sur le modèle RBAC. Nous allons donner un exemple d’extension du modèle RBAC qui introduit la notion de risque et de délégation c’est le Risk-RBAC ( [6]).
Il est important d’introduire une relation d’ordre en fonction de l’importance des objets et de la dangerosité des actions sur ces objets. Ainsi une évolution du modèle RBAC a été faite dans l’article Risk Analysis in Access Control Systems [6] pour introduire la notion de risque dans RBAC. Le modèle RBACR est défini comme RBAC en y ajoutant la fonction de sécurité RF
et un ensemble de niveaux de confiance C.
RF est une fonction d’analyse de risque. Le principe est d’affecter un niveau de confiance à un utilisateur u ∈ U noté CNF (u) : U → C. Et pour tous les rôles on calcule le niveau minimum de confiance noté MLC(R) : R → C. la valeur du risque relatif à un utilisateur u et un rôle R noté rv(u, R) et est comprise entre 0 et 1 et est calculée de la manière qui suit :
rv(u, R) = 0, si CN F (u) ≥ M LC(R) 1 −M LC(R)CN F (u), sinon
Dans cet article, la notion de délégation et du risque relatif à cette délégation y sont introduits. Cette notion désigne le risque engendré sur les objets de u1 si u1 délégue son rôle à u2, ce
risque est noté par del_rv(u1, u2) et il est calculé comme suit :
del_rv(u1, u2) = 0, si CN F (u1) ≥ CN F (u2) 1 −CN F (u1) CN F (u2), sinon Concepts alternatifs
Il existe plusieurs autres molèles de contrôle d’accès qui répondent à une diversité de besoins en terme de sécurité. Nous pouvons en cité quelques un :
– OrBAC (Organization-Based Access Control) [2] : le modèle de contrôle d’accès basé sur l’organisation est un modèle RBAC avec l’introduction des concepts de vue, d’activité et d’organisation. Cela a pour objectif de définir une politique de contrôle d’accès indé-pendante de son implantation. Pour se faire, OrBAC fait une abstraction des sujets en rôle, des actions en activité et des objets en vue.
– T-RBAC (Temporal Role Bsae Access Control) a été développé par ELISA BERTINO et ANDREA BONATTI [7]. Le modèle T-RBAC permet de règler les problèmes des rôles qui dependent du temps.
– (RelBAC Relation-Based Access Control) [4] : le modèles de contrôle d’accès basé sur les relations entre les sujets. Ce modèle a un grand avenir dans les modes des reseaux sociaux via internet.
La connaissance des différents modèles de contrôle d’accès qui sont implémentés dans chaque système informatique est un atout non négligeable pour les administrateurs de sécurité, car cette connaissance aide dans la définition de procédure d’audit et des validations des droits d’accès.
1.4
Processus d’audit et de validation des droits d’accès.
Dans un système informatique, la mise en place d’une politique de sécurité et des dispositifs de gouvernance ne suffisent pas pour garantir un bon niveau de sécurité et une réponse aux besoins de gestion des risques relatifs aux métiers.
Ainsi pour maintenir le niveau de sécurité à un niveau acceptable, il est important de mettre en place une stratégie de contrôle qui va intégrer l’ensemble des facteurs qui entre en jeu dans la structure de l’entreprise, dans le métier, et le contrôle d’accès.
Sur ce plan de contrôle, on retrouve un ensemble de processus d’audit et de validation de droits d’accès. Le processus d’audit des droits d’accès est une manière d’avoir des photographies permanentes des accès courants. L’action d’audit est souvent très ponctuelle dans l’entreprise or cette action peut ou doit être associée à l’action de monitorage des droits d’accès et d’une action de validation permanente.
De ce fait, l’audit des droits d’accès peut être défini comme étant des actions d’analyse des droits d’accès et de leurs validations. Il aboutit généralement à un constat qui révèle la cohé-rence des droits d’accès vis-à-vis de la politique de sécurité.
En général, le processus de cette validation d’un droit d’accès est une procédure administrative et fait appel à des composants de l’entreprise qui ne sont pas dans le métier de la sécurité informatique. Ce processus est décrit souvent sous la forme d’un protocole.
La mise en place d’un processus de validation doit prendre en compte certains paramètres dont les plus importants sont :
– L’identification des référentielles des sources de données personnelles aux différentes populations (interne, externe, clients, visiteurs, etc.) et ces référentielles doivent être très fiable.
– La définition des règles de séparation des pouvoirs en conformité avec le règlement du secteur d’activité.
– L’identification et la formalisation de la gestion du cycle de vie des droits d’accès (arrivée, départ, mutation d’une entité).
– Engagement fort de la direction et du ménagement dans l’élaboration du processus de validation.
Dans la gestion des identités le CLUSIF démontre que ce processus de validation est établi sous forme de workflow. De plus, on y fait l’illustration du cas de référencement d’un nouvel utilisateur qui arrive dans une entreprise. Les actions identifiées sont :
– embauche dans une entrepise ⇒ Référencement dans le systeme de gestion de la paye. – attribution d’un bureau ⇒ Référencement dans la base du service logistique,
– attribution d’un numéro de téléphone ⇒ Réferencement dans la base théléphonique, – attribution d’un ordinateur, d’un identifiant et d’un mot de passe ⇒ Réferecement dans
le systeme bureautique.
– attribution d’un badge pour accès au locaux ⇒ Réferencement dans le système de gestion des badges,
– droits d’accès sur une application ⇒ Réferencement dans la base de l’application. – etc.
L’ajout d’un nouvel utilisateur montre qu’un worklfow de validation des droits d’accès doit prendre en compte le plan organisationnel d’entreprise. Il est donc important de disposer d’une bonne description de tous les utilisateurs, de leurs tâches et de leurs unités d’affectation au sein de l’entreprise.
Pour accompagner les entreprises dans la gestion du contrôle d’accès, des normes ont été créées. Nous pouvons citer :
– La norme ISO/CEI 27002 [8] est une norme publiée en 2005 par l’ISO4. On y présente un ensemble de mesures ou des règles de bonnes pratiques destinées ont la sécurité informatique. Dans le chapitre 11, la version ISO/27002 :2005 et le chapitre 9 de la version ISO/27002 :2013, ISO donne les mesures pour le contrôle d’accès sur les systèmes d’information. Ainsi, la manière d’assurer la protection des systèmes réseau, de détecter les activités non autorisées y est décrite et, également des conseils d’utilisation d’appareil mobile y sont fournis.
Cette norme indique également les différents niveaux de responsabilité des utilisateurs et comment ils doivent, en conséquence, gérer leurs informations d’authentification. Les bases sont fournies aux administrateurs pour écrire des politiques de sécurité dédiés au contrôle d’accès.
– Cobit5 [9] est une norme proposée par l’ISACA6 pour fournir une orientation aux entre-prises et aux institutions gouvernementales dans la gestion de la sécurité informatique, la gestion des risques, le pilotage d’activités d’audits, etc. Cobit propose également des mesures pour évaluer la gestion et l’audite du contrôle d’accès.
– La TCSEC7 [10] est une norme qui a été définie par le département de la défense des États-Unis pour fournir un cadre d’évaluation des systèmes informatiques. Cette norme donne également la description des différentes implémentations des modèles de contrôle d’accès.
Le pragmatisme militaires fait que la structure de cette norme est sous la forme d’une liste de critères, de définitions et de hiérarchisation de l’information. On y trouve également des outils d’analyse et d’évaluation.
On constate que l’adoption d’une norme permet aux entreprises d’avoir un cadre de référence de bonnes pratiques, mais cela ne permet pas d’automatiser la gestion du contrôle d’accès. Les administrateurs de sécurité ont besoin d’outils pour les aider dans leurs tâches.
Il existe plusieurs entreprises œuvrant dans la sécurité informatique qui propose des outils de gestion des droits d’accès sous un label plus générique qui est la gestion des identités et des habilitations. Dans la section qui suit, nous en présentons quelques uns qui peuvent être d’une aide précieuse pour les administrateurs de sécurité informatique.
1.5
Outils de gestion des droits d’accès
Il existe plusieurs applications pour la gestion des droits d’accès dans le marché de la sécurité informatique. Elles sont caractérisées principalement par le fait qu’elles soient en majorité dédiées à un écosystème particulier. De plus, les constructeurs d’équipements ou de systèmes informatiques créent leurs propres outils de gestion de contrôle d’accès qui ne sont pas, en général, compatibles avec d’autres systèmes. Ci-après nous citons quelques outils.
1.5.1 SetACL Studio
Cet outil a été développé par une entreprise allemande du nom de Helge Klein GmbH qui porte le nom de son fondateur Heige Kein.
SETACL gère les permissions des utilisateurs et pemet de faire des audits sur les droits d’accès. Il fait tout ce que les outils intégrés à Windows peuvent faire, et bien plus encore. Il est intrinsèquement automatisable et programmable par scripts. La version SETACL COM offre toutes les fonctionnalités d’un langage de programmation compatible COM8 (C#, Visual
5. Cobit : Control Objectives for Information and related Technology, en français Objectifs de contrôle de l’Information et des Technologies Associées
6. ISACA : Information Systems Audit and Control Association 7. TCSEC : Trusted Computer System Evaluation Criteria 8. COM : Component Object Model est un standard de Microsoft
Basic, C++, Delphi, PowerShell, VBScript, etc). De plus, tous les objets sont pris en charge, à savoir les fichiers, les processus, les registres et les services.
Figure 1.1: Caputure d’écr an t de SetA CL Studi o
1.5.2 Windows Identity Foundation
Cet outil aide les développeurs .NET à construire des applications qui extériorisent l’authen-tification des utilisateurs de l’application, l’amélioration de la productivité des développeurs, le renforcement de la sécurité des applications. Les développeurs peuvent profiter d’une plus grande productivité, en utilisant un modèle d’identité unique simplifié et qui est basé sur des jetons d’identités. Ils peuvent créer des applications plus sécurisées avec un modèle d’accès mono-utilisateur. Ils introduisent, ainsi, des implémentations personnalisées et, permettant aux utilisateurs finaux d’y accéder en toute sécurité via des applications logicielles ou sur sur des servics en nuagique. Enfin, ils peuvent profiter de plus de souplesse dans le développement d’applications grâce à l’interopérabilité intégrée qui permet aux utilisateurs, applications, sys-tèmes et autres ressources de communiquer via des jetons d’identité.
Windows Identity Foundation permet de développer des outils de gestion des droits d’accès et cela pour toutes les entités du système d’exploitation Windows (application, service, registre, etc.).
1.5.3 IBM Security Identity and Access Assurance
Le logiciel IBM Security Identity and Access Assurance propose une solution complète pour assurer la gestion des identités et des accès, ainsi que la vérification de la conformité des utilisateurs. Anciennement connu sous le nom de IBM Tivoli Identity and Access Assurance, qui regroupe quatre logiciels IBM qui administre, sécurise et surveille l’accès aux ressources par les utilisateurs. IBM Security Identity and Access Assurance est une solution qui gère les droits d’accès de plusieurs systèmes d’exploitation, et d’équipements réseau ; de plus la gestion des droits d’accès prend en charge plusieurs applications et services tels que les SGBD et les applications métier.
Cet outil est multiplateforme ; cela lui confère un atout certain. Seulement le prix de la solution et les coûts de formation pour son utilisation sont énormes ; donc très peu compétitif au niveau des PME.
1.5.4 SAM Jupiter
SAM Jupiter est développé par Beta Systems Software AG qui est une entreprise très impor-tante dans le marché des logiciels de gestion des identités.
SAM Jupiter permet d’assurer une transparence dans les traitements relatifs à la gestion des identités, et contribue à la gestion du contrôle d’accès. Les utilisateurs peuvent suivre précisément les tâches d’administration préalablement exécutées dans SAM Jupiter, afin de savoir quelle personne a approuvé ou a accordé les autorisations d’accès, et sur quelle base un utilisateur spécifique s’est vu allouer ses droits d’accès.
SAM Jupiter est principalement basé sur une analyse du fichier log des événements du système d’exploitation. Il est supporté par les systèmes d’exploitation Linux et Wimdows. Il est moins complet que IBM Security Identity and Access Assurance, mais jumelé avec d’autres outils, il peut être très puissant.
1.5.5 LinID
LinID est la seule suite logicielle de gestion d’identité "Open Source", qui permet de gagner en efficacité et en sécurité dans la gestion des données d’identité, d’accès et d’habilitation. Cette suite est développée par l’entreprise LinAGORA, une entreprise française qui oeuvre dans le monde de l’open source.
LinID est principalement utilisé dans l’environnement Windows où est déployé un domaine actice directory.
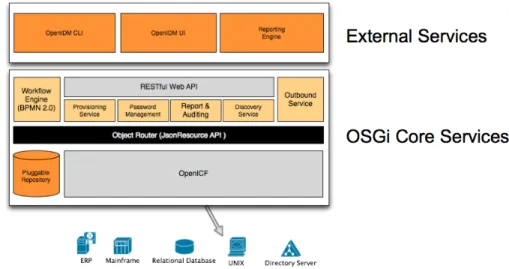
1.5.6 OpenIDM
OpenIDM permet aux entreprises d’automatiser la gestion du cycle de vie de l’identité de l’utilisateur en temps réel, y compris la gestion des comptes utilisateurs et des privilèges d’accès aux applications. Léger et agile, OpenIDM a été conçu pour aider les entreprises à assurer la conformité aux politiques et aux exigences réglementaires dans l’ensemble des entreprises, Cloud, réseaux sociaux et mobiles. ForgeRock est la structure qui a porté le projet d’OpenIDM.
OpenIDM est fait en java et il gère les systèmes Windows et Linux. De plus, son architec-ture client-serveur permet une souplesse dans son déploiement. Il est basé sur un outil de provisioning nommé OpenICF qui est un framework que l’on peut utiliser avec java et .NET principalement.
1.5.7 Quest One Identity
Membre de la suite de Quest Software de l’entreprise DELL, Quest One Identity assure le contrôle des accès et l’administration des identités et améliore, en plus, la vérification de conformité en consolidant l’automatisation et la génération de rapports.
Quest One vous permet de trouver rapidement et facilement les comptes et les utilisateurs qui possèdent des droits d’accès inadaptés. Quest One Identity permet effectuer une décou-verte approfondie des environnements Active Directory et accéder à la gouvernance de toute l’entreprise.
Il fonctionne sous Windows et est optimisé pour une architecture basée sur Active directory de Windows.
1.5.8 Étude comparative
Le caractère commun des outils cités plus haut est que les politiques de sécurités sont sta-tiques et, en plus, l’initiative d’audits et de validations des droits d’accès est du ressort des administrateurs de sécurité souvent suite aux résultats de l’analyse des journaux après une alerte de sécurité. D’où la nécessité de bâtir des outils qui disposent d’une intelligence de validation faisant intervenir le moins possible l’humain. De plus, ces outils devront avoir une base théorique et formelle.
Dans l’état de l’art, on peut trouver des travaux allant dans le sens d’implémenter un outil de validation automatique des droits d’accès en se basant sur une théorie et un formalisme mathématique. Nous avons retenu de présenter un modèle de gestion des droits d’accès basé sur UML9 qui est le plus proche de notre approche dans la réalisation d’un outil de gestion et d’audit des droits d’accès.
1.6
Modèle UML pour la gestion du contrôle d’accès.
UML (langage de modélisation unifié [11] est comme sont nom l’indique un langage de mo-délisation basé sur plusieurs types de diagrammes et qui a eu un grand succès dans le génie logiciel avec l’orienté objet.
Il est évidant que le l’aura de UML dans le domaine de l’industrie du logiciel et dans le monde accadémique a inspiré plus d’un à utiliser cette technologie dans les domaines de la sécurité informatique et plus particulièrement dans le domaine de la gestion du contrôle d’accès. Plusieurs modèles de contrôle d’accès sont décrits sous forme de diagrammes UML. De plus, le succès de UML combiné au succès du modèle RBAC ont fait que dans la littérature ce couple est très pressant.
Ainsi, dans [12] Gilles Goncalves et de Fred Hémery introduisent une modélisation très perti-nente du modèle RBAC. En effet, dans ce travail, on trouve une méthodologie d’implémenta-tion du modèle RBAC, qui va de la définid’implémenta-tion des rôles à la mise en place de la stratégie de gestion.
Un des travaux sur la gestion des droits d’accès qui nous interpelle particulièrement est celui de David Basin et de Jürgen Doser [13] où ils décrivent un modèle basé sur UML permettant de faire une description des spécificités de sécurité d’un système d’information et donne un outil pour générer, automatiquement, une architecture de sécurité intégrant ces spécificités. L’idée de base est de prendre un modèle d’un système et d’y ajouter un modèle de sécurité pour engendrer un nouveau modèle appelé modèle de transformation. Ce dernier permet de transformer l’infrastructure existante en y ajoutant une surcouche sécuritaire et respectant des spécifications de sécurité.
En utilisant UML, l’approche du Model Driven Security est de subdiviser le contrôle d’accès en deux types de décision :
– Une décision déclarative : cette partie représente toutes les décisions d’accès qui ne dépendent que d’information statique.
– Une décision programmée : cette partie représente toutes les décisions d’accès qui dé-pendent d’information dynamique satisfaisant les contraintes d’autorisations pour les différents états du système.
Cette approche est basée sur modèlisation UML de RBAC, et de la programmation par contrainte que fournit UML via son le langage OCL.
Ainsi on définit une représentation des relations de modèle RBAC avec le diagramme de classe de la figure1.3.
La figure1.3 représente les décisions déclaratives et la partie programmée qui est une instan-ciation de ce diagramme de classe à laquelle on applique les contraintes liées à chaque objet. On a alors un test à faire sur chaque décision de contrôle d’accès en vérifiant que pour chaque décision déclarative, la contrainte qui lui est associée est respectée.
Ce modèle est très intéressant dans la gestion des droits d’accès durant la phase de conception d’un système donné. Cependant, dans un écosystème hétérogène où l’on n’a pas la maitrise des différents systèmes, il est préférable de disposer d’un outil qui fait abstraction des différents systèmes et qui, grâce à la description de la politique de sécurité, pourra récupérer l’ensemble des droits d’accès et en faire l’analyse de conformité.
Figure 1.3: SecureUML Méamodel
1.7
Gestion sémantique des droits d’accès : AMO
Le Web 2.0 a entrainé une émergence des applications Web dans le monde de l’entreprise. Cette révolution a permis le développement de plusieurs plates-formes pour la collaboration, le télétravail et les réseaux sociaux. Ainsi, les wikis, les blogues, les forums et d’autres outils de partage de contenu sont devenus incontournables pour une entreprise numérique. La parti-cularité de ces systèmes est qu’ils sont faits pour être conçus et déployés par des personnes qui ne sont pas dans le domaine de la conception d’applications web. Car, pour les créer, on utilise d’autres applications Web de gestion de contenues qui sont connues sous le nom de CMS10. Comme tous systèmes informatiques, la problématique de la gestion des droits d’accès est à considérer pour assurer la sécurité de ces outils.
C’est dans ce cadre que [14] a défini une ontologie pour la gestion sémantique des droits d’accès au contenu avec l’utilisation d’une ontologie nommée AMO (Access Management Ontologiy). Sans rentrer dans les détails sur les ontologies que nous allons développer dans le chapitre suivant, nous allons vous présenter AMO.
L’idée qui est à la base de AMO est de fournir un mécanisme de gestion des droits d’accès dans les systèmes de gestion de contenu qui reposent sur des serveurs web sémantiques. Ce mécanisme est réalusé grâce à une ontologie qui décrit des classes et des propriétés permettant d’annoter les objets (pages web, article, images, etc.) sur lesquels le contrôle d’accès sera réalisé.
Les systèmes de gestions de contenu étant différents de la gestion des droits d’accès, AMO permet de définir des concepts génériques et un ensemble de propriétés pour être en mesure d’annoter des ressources sans que cela ait un impact sur le type système de gestion de contenu utilisé.
Ainsi, en identifiant les principes que partagent tous les systèmes de gestion de contenu, AMO utilise les entités suivantes :
– Les agents : ces derniers sont associés aux utilisateurs, groupes d’utilisateurs, services qui interagissent avec le système.
– Les roles. Dans le cas de systèmes d’édition collaborative tels que les wikis ou les CMS, il s’agit des rôles d’invité, de contributeur, d’administrateur. On peut retrouver d’autres rôles suivant le type de système.
– Les actions autorisés : les actions qui peuvent être réalisé sur une ressource sont la création, la lecture, la modification et la destruction de contenu, la modification des droits d’accès, la modification de la liste des agents autorisés sur une ressource et la modification du type d’accès défini pour une ressource.
– Les types d0acc`esaux ressources : une ressource peut être publique (les utilisateurs ont
accès en lecture et écriture), privée (seuls les agents autorisés ont accès en lecture et écriture) ou semi-privée (accès libre en lecture, accès en écriture uniquement pour les agents autorisés).
– Les actions autorisées pour un agent sur une ressource dépendent du role de l’agent et/ou du type d’accès défini pour la ressource.
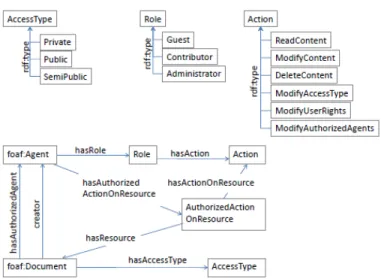
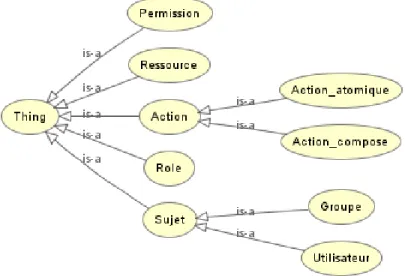
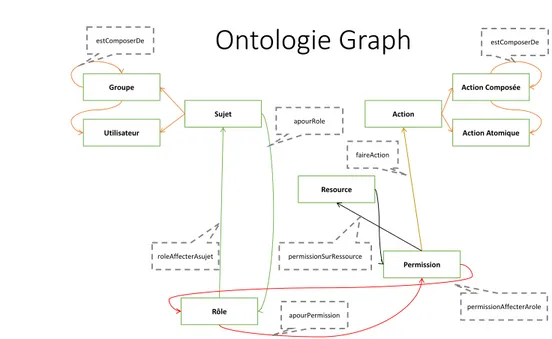
Cela permet de construire une ontologie qui a comme métaclasses Role, Action et AccessT ype et chaque métaclasse est défini comme suit :
– Role composé des classes Administrator, Contributor et Guest.
– Action est la métaclasse de ReadContent, ModifyContent, DeleteContent, ModifyUser-Rights, ModifyAccessType et ModifyAuthorizedAgents.
– AccessT ype est la métaclasse des classes Private, Public et SemiPublic.
De plus les classes Document, Agent et la sous-classe AuthorizedActionOnResource de la classe Action permettent de compléter l’ontologie et de définir les propriétés suivantes :
– creator et hasAuthorizedAgent : associent un agent à un document ; – hasRole : associe un rôle à un agent ;
– hasActionOnResource : associe une action à un rôle ; – hasAccessType : associe un type d’accès à un document ;
– hasAuthorizedActionOnResource : associe une instance de AuthorizedActionOnResource à un agent.
Figure 1.4: Ontologie AMO
– hasDocument et hasAction : associent à une instance de AuthorizedActionOnResource respectivement un document et une action.
Ainsi, dans la figure1.4 on peut voir une représentation de l’ontologie AMO.
AMO permet de détacher l’annotation du contrôle d’accès sur les ressources vers l’ontologie en définissant une stratégie de contrôle et cela de façons déclaratives sous forme de règles. Comme exemple de règles, on a :
– un membre d’un groupe hérite du ou des rôle(s) attribués à son groupe ; – le créateur d’une ressource est un agent de cette ressource ;
Avec un système de requêtes permettant d’interroger l’otologie, on peut, avant chaque accès, vérifier la validité de la règle qui est appliquée à une ressource. Ainsi, on construit un système contrôle d’accès grâce à AMO.
AMO est utilisé par le wiki sémantique SweetWiki [15] que les auteurs de [14] ont développé pour illustrer l’intégration aux technologies du web sémantique. AMO peut être déployé sur la plupart des CMS qui sont orientés dans les web sémantiques.
Cette approche permet d’introduire une formalisation de la gestion des droits d’accès. Elle est limitée, car elle se restreint au web sémantique. Mais c’est une approche qui est innovatrice dans la mesure ou elle intègre l’idée d’abstraction pour généraliser la gestion des droits d’accès dans les systèmes de gestion de contenu.
1.8
Conclusion
Dans ce chapitre nous avons décrit les besoins qu’ont les administrateurs en sécurité informa-tique sur la gestion des droits d’accès et les problèmes liés à l’attribution des droits d’accès. Nous avons également mis en relief des descriptions informelle et formelle du contrôle d’accès, qui facilite la compréhension des différents processus d’audit et de validation des droits d’accès qui nous a permis de vous présenter quelques outils et approches qui existent dans le marché informatique.
Cette revue globale du contrôle d’accès dans la sécurité informatique représente un point de départ pour positionner nos travaux et entamer la partie suivante où l’on présente notre modèle de gestion basé sur les ontologies.
Chapitre 2
Modèle de gestion basé sur le concept
des ontologies.
2.1
Introduction
Dans ce chapitre, nous allons mettre en relief le choix des ontologies pour faire la validation automatique des droits d’accès. Pour ce faire, il est important de connaitre la définition et la description d’une ontologie avant d’en concevoir une qui va servir comme base pour bâtir un outil de validation de droit d’accès.
Ainsi, nous allons motiver notre choix sur l’utilisation des ontologies ; par la suite nous pré-senterons les différents langages utilisés dans la définition des ontologies ; pour finir par la définition les concepts du domaine du contrôle d’accès et de la création d’un ontologie qui va nous servir à implémenter notre prototype logiciel de gestion et de validation des droits d’accès.
2.2
Pourquoi une ontologie
Le choix de l’utilisation d’une ontologie pour développer un outil de gestion et de validation des droits d’accès est motivé par la place qu’occupent les ontologies dans l’informatique en général et l’informatique décisionnelle en particulier. De ce fait, les ontologies représentent une brique essentielle dans l’architecture de notre logiciel.
2.2.1 Définition d’une ontologie
Les ontologies, à l’origine d’une branche de la philosophie qui s’intéresse à la nature et à l’organisation de la réalité, correspondent à ce qu’Aristote appelait la Philosophie première, c’est à dire la partie de la métaphysique qui s’intéresse à l’être en tant qu’être, par opposition aux philosophies secondes qui s’intéressent à l’étude des manifestations de l’être (Garf, 1996).
En informatique, la littérature fournit plusieurs de définitions du mot ontologie. Ces définitions, dans leur diversité, offrent des points de vue à la fois différents et complémentaires. Cependant, une définifion qui fait autorité a été faite par Greber et s’énonce comme suit : "Une ontologie est la spécification d’une conceptualisation. [...] Une conceptualisation est une vue abstraite et simplifiée du monde que l’on veut représenter".
Pour nous, l’ontologie se définit comme étant un ensemble de termes hiérarchiquement struc-turés, conçu afin de décrire un domaine qui peut être utilisé comme un squelette de base pour les bases de connaissances.
Une ontologie est basée sur la logique descriptive, or, cette dernière est un langage de représen-tation de connaissance qui peut être utilisée pour représenter la connaissance terminologique d’un domaine d’application d’une manière formelle et structurée.
Notre objectif étant de faire une représentation du contrôle d’accès en informatique donc, naturellement, l’utilisation d’une ontologie est justifiée.
2.2.2 Les constituantes d’une ontologie
Une ontologie est composée d’un ensemble structuré de concepts d’un domaine bien déterminé. Elle est structurée comme un dictionnaire formel qui définit les concepts par leurs relations sémantiques et de subsomption. Ainsi, une ontologie est composée de :
– Classes qui énumèrent l’ensemble des concepts d’un domaine ;
– Attributs qui décrivent les caractéristiques et les propriétés d’une classe. On parle parfois de rôles.
– Facettes qui sont des restrictions sur les attributs.
– Instances qui constituent une base de connaissances. Ils sont les vrais individus ou don-nées réels de l’ontologie.
2.2.3 Langages des ontologies Historiques
Pour la création et la manipulation des ontologies, il existe plusieurs langages de spécification spécialisés ; nous pouvons citer :
– OKBC (Open Knowledge Base Connectivity - 1997) [16] : API permettant d’accéder à des bases de connaissance ;
– KIF (Knowledge Interchange Format - 1998) [17] : langage destiné à faciliter des échanges de savoirs entre systèmes informatiques hétérogènes.
– Loom : langage de représentation des connaissances dont le but avoué est de « permettre la construction d’applications intelligentes » ;
– DAML-ONT (DARPA Agent Markup Language Ontology - 2000) [18] : fondé sur XML, résulte d !un effort du DARPA (Defense Advanced Research Projects Agency) pour l’ex-pression de classes plus complexes que le permet RDF-S ;
– RDF/RDF-S (Resource Description Framework) : RDF est un modèle de graphe destiné à décrire de façon formelle les ressources Web et leurs métadonnées, de façon à permettre le traitement automatique de telles descriptions. RDF-S fournit des éléments de bases pour la définition d’ontologies ou vocabulaires destinés à structurer des ressources RDF. [19]
– OWL (Web Ontology Language) [20] est un langage de description d’ontologies conçu pour la publication et le partage d’ontologies sur le Web sémantique.
Langage OWL
Dans le cadre de notre projet, nous nous sommes particulièrement intéressé au langage OWL [20]. Ce dernier est inspiré de DAML (US DARPA Agent Markup Language) projet Américain et OIL (Ontology Inference Layer) projet Européen.
Comme RDF, OWL est un langage XML, ce qui lui confère un caractère d’universalité syn-taxique ; de plus il permet :
– une représentation très riche des connaissances : propriétés, classes avec identité, équi-valence, contraire, cardinalité, symétrie, transitivité, etc.
– de faire un raisonnement sur ces connaissances en s’appuyant sur la logique descriptive (LD).
Ce dernier point est un aspect très important dans le choix du langage OWL. En effet, la logique descriptive a fait ses preuves dans la représentation des politiques des sécurités en informatique, elle fournit un support très riche et satisfait aux conditions suivantes :
– l’expressivité ; – la clarté ; – la lisiblé ;
– la non embiguité ; – et l’extenciblité.
Un document OWL est une ontologie :
– Qui peut avoir un identificateur unique représenté par un URI (Uniform Resource Iden-tifier) ;
– qui contient :
– des faits qui sont des descriptions d’individus ;
– Un documment a la forme suivante :
ontologie ::= Ontology()[ontologieID]{directive}directive ::= axiomekf ait – L’ontologie OWL la plus simple que l’on peut écrire est :
ontology() – Notons, que OWL comprend les 2 classes pré-définies :
– owl : T hing : correspondant à > – owl : Nothing : correspondant à ⊥.
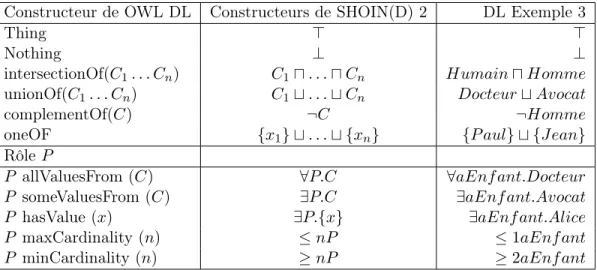
Exemple : La phrase "Un docteur est une personne qui peut avoir des enfants." se traduit en LD et en OWL par :
LD :
P ersonne u ∀aEnf ant.(Docteur t ∃aEnf ant.Docteur). OWL : <owl:Class> <owl:intersectionOf rdf:parseType="collection"> <owl:Class rdf:about="#Personne"/> <owl:Restriction> <owl:onProperty rdf:resource="#aEnfant"/> <owl:toClass> <owl:unionOf rdf:parseType="collection"> <owl:Class rdf:about="#Docteur"/> <owl:Restriction> <owl:onProperty rdf:resource="#aEnfant"/> <owl:hasClass rdf:resource="#Docteur"/> </owl:Restriction> </owl:unionOf> </owl:toClass> </owl:Restriction> </owl:intersectionOf> </owl:Class>
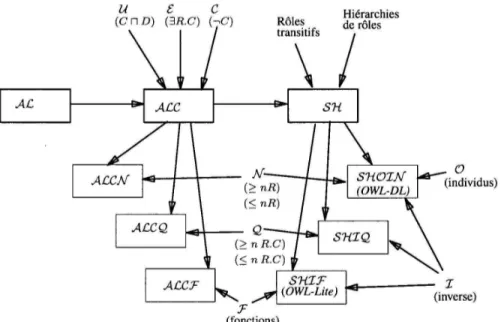
Owl se décline en trois sous langages que sont : 1. OWL-Lite.
OWL-Lite correspond à la famille SHIF(D) [21] de la logique descriptive. Il se caractérise par les attributs suivants :
– expressivité limitée à des hiérarchies de classification et de fonctionnalités de contraintes simples de cardinalité 0 ou 1 (relations fonctionnelles).
Exemple : OWL-Lite ne permet pas d’exprimer : "une personne a une seule adresse, mais peut avoir un ou plusieurs prénoms".
2. OWL-DL.
OWL-DL correspond à la famille SHOIN(D) [21] de la logique descriptive et il a comme particularité :
– d’être une logique de description d’où le DL ;
– expressivité élevée : contient tout OWL avec certaines restrictions ; – raisonnements :
– pouvant être faits dans une logique descriptive ; – plus lents que dans OWL-Lite ;
– complétude du calcul : toutes les inférences sont assurées d’être prises en compte ;
– décidabilité : tous les calculs des formules OWL-DL sont évaluées et se ter-minent en un temps fini ;
3. OWL-Full.
OWL-Full comprend tout OWL-DL avec en plus tout RDF et il se caractérise par : – une expressivité maximale ;
– une compatibilité complète avec RDF/RDF-S ; – des raisonnements souvent :
– très complexes ; – très lents ; – incomplets ; – indécidables.
Pour notre prototype de gestion et de validation nous utiliseront OWL-DL ;
2.2.4 Langage OWL-DL
OWL-DL est basé sur la logique descriptive en particulier SHOIN(D) [21]. D pour Data pro-perty.
D’une manière générale les éléments fondamentaux de la logique descriptive sont :
– les éléments du monde réel sont représentés par des concepts, des rôles et des individus. – les concepts et rôle possédent une description structurée à laquelle est associée une