Ontogénèse et spécificité de la voix humaine
Texte intégral
Figure
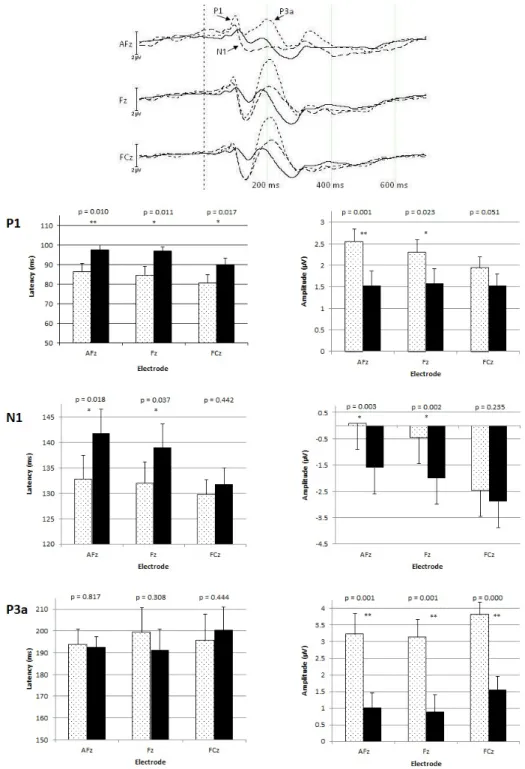
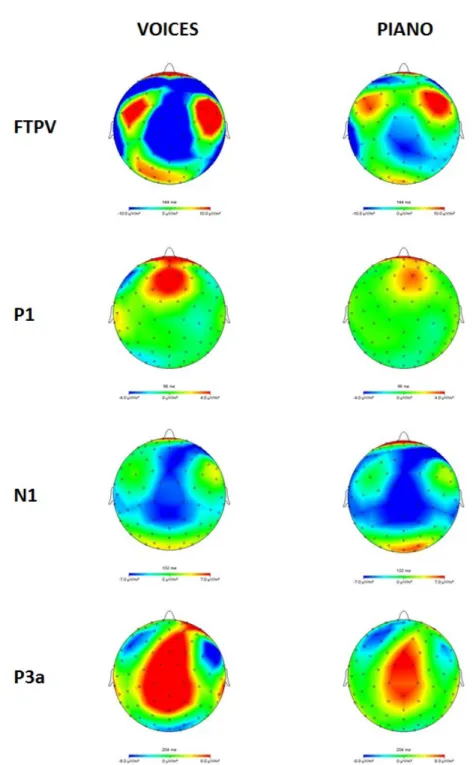
Outline
Documents relatifs
Le fait de porter la discussion à un niveau plus personnel a permis à toutes les personnes impliquées de mieux comprendre l’importance de notre revendication la plus cruciale, à
D’autres peuvent déjà s’appliquer dans un cadre clinique, de l’objectivation d’un comportement vocal dans le cadre d’un bilan de voix au suivi
Dans les différentes espèces, les fibres musculaires sont classées en plusieurs types en fonction de leurs propriétés contractiles et métaboliques.. Ces propriétés sont acquises
9, le narrateur évoque les odeurs caractéristiques des maisons : « tenez, autre chose, rien qu’à l’odeur chacun sait, les yeux fermés, à quelle maison il a affaire », sur
Le violoniste joue du
Deux stratégies sont envisageables (et actuellement explo- rées) pour essayer d’identifier ces gènes : l’analyse comparative globale des chromosomes et génomes de Pri- mates
complètement vocalisé ; au contraire un texte arabe usuel ne peut être lu correctement que par celui qui le comprend, une forme telle que <• " t -.
Ces considérations nouvelles pour l’époque ouvrent tout un champ
