HAL Id: tel-00401651
https://tel.archives-ouvertes.fr/tel-00401651
Submitted on 3 Jul 2009
HAL is a multi-disciplinary open access
archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés.
Abdenour Mokrane
To cite this version:
Abdenour Mokrane. Représentation de collections de documents textuels : application à la caractéris-tique thémacaractéris-tique. Interface homme-machine [cs.HC]. Université Montpellier II - Sciences et Techniques du Languedoc, 2006. Français. �tel-00401651�
T H E S E
pour obtenir le grade de
DOCTEUR DE L'UNIVERSITE MONTPELLIER II
Discipline : INFORMATIQUE Formation Doctorale : INFORMATIQUE
Ecole Doctorale : I2S
présentée et soutenue publiquement
par
M. Abdenour MOKRANE
Le 17 Novembre 2006
Titre :
Représentation de collections de documents textuels :
application à la caractérisation thématique
JURY
M.Bernard DOUSSET, Professeur, Univ. Toulouse III , Rapporteur
M. David William PEARSON, Professeur, Univ. St Etienne , Rapporteur
Mme. Danièle HERIN, Professeur, Univ. Montpellier II , Examinatrice
M. Pascal PONCELET, Professeur, Ecole des Mines d’Alès , Directeur de thèse
A mes parents et ma femme, A ma famille, A tous mes amis, …
Je tiens à exprimer ma profonde gratitude à Pascal Poncelet, professeur à l’Ecole des Mines d’Alès, directeur adjoint du LGI2P, qui a su diriger ces travaux de thèse, je le remercie vivement pour la qualité de son encadrement, ses orientations et tous ses précieux conseils. Tout au long de ces années de thèse, j’ai pu apprécier tant son dynamisme que sa rigueur scientifique. Je lui exprime toute ma reconnaissance. Je tiens à exprimer également toute ma reconnaissance à Gérard Dray, maître assistant à l’école des Mines d’Alès pour son soutien constant tout au long de ces travaux de thèse. Je le remercie vivement pour la qualité de ses apports et son encadrement. Je tiens à lui exprimer également ma profonde gratitude.
Je remercie vivement Monsieur Bernard Dousset, professeur à l’Université Toulouse III et Monsieur David William Pearson, professeur à l’Université de Saint Etienne, qui m’ont fait l’honneur d’être rapporteurs de cette thèse. Je les remercie pour leurs remarques et conseils pour l’amélioration du manuscrit.
Je suis très honoré que Madame Danièle Hérin, professeur à l’Université Montpellier II, ait accepté d’examiner ce travail et de faire partie de mon jury. Je lui exprime mes vifs remerciements.
Je remercie également l’ensemble des chercheurs et collègues du LGI2P, notamment Michel Plantié et Rachid Arezki pour leurs collaborations, sans oublier Sylvie Cruvellier, Françoise Armand et le personnel de l’EMA qui m’ont permis de mener, dans de bonnes conditions, mes travaux de thèse.
Je voudrais exprimer également mes vifs remerciements à mes collègues de l’Antenne Universitaire de Blois, pour leur accueil chaleureux en tant qu’ATER, ce qui m’a permis de terminer la rédaction de ce manuscrit dans les meilleures conditions, particulièrement Arnaud Giacometti et Jean Yves Antoine, professeurs à l’Université de Tours, pour leurs nombreux conseils et soutien.
Ma famille à qui je dois bien plus que des remerciements. Je pense en particulier à mes parents qui m’ont permis de faire des études persévérées et m’ont appris la valeur du savoir. Je pense également à ma femme qui m’a soutenu et supporté plus que de raisons des horaires de travail pour le moins extravagants.
Enfin, toute ma reconnaissance et mes remerciements pour tous ceux qui m’ont soutenu et participé de près ou de loin à ces travaux.
CHAPITRE I – INTRODUCTION…..………..………….…9
1. PRINCIPALES CONTRIBUTIONS... 11
1.1. Modéliser l’information pour extraire la connaissance ...12
1.2. Extraire et visualiser les connaissances des thématiques ...12
1.3. Le système IC-DOC ...13
2. ORGANISATION DU MEMOIRE ... 13
CHAPITRE II – PROBLEMATIQUE ET ETAT DE L’ART………….…15
1. PROBLEMATIQUE ... 17
2. LE PROCESSUS D’EXTRACTION DE CONNAISSANCES ... 18
3. LE PRETRAITEMENT DES DOCUMENTS... 22
3.1. Approche morphosyntaxique et lemmatisation ...22
4. LA REPRESENTATION DES DOCUMENTS... 24
4.1. Représentations vectorielles ...25
4.2. Représentations basées sur les associations de termes ...29
5. LA FOUILLE DE DONNEES... 33
6. DISCUSSION... 35
CHAPITRE III – MODELE DE REPRESENTATION…..…….…………38
1. VERS UN MODELE DE REPRESENTATION ... 39
1.1. Définitions préliminaires ...39
1.2. Principe général de représentation ...44
1.3. Algorithmes ...49
2. PARTAGE DE CONTEXTES... 53
2.1. Définitions préliminaires ...53
CHAPITRE IV – LE SYSTEME IC-DOC….………....………...….61
1. LE SYSTEME IC-DOC ... 62
1.1. Prétraitement des documents ...64
1.2. Modélisation des documents ...65
1.3. Fouille de données...65
1.4. Interprétation et visualisation ...66
2. IDENTIFICATION DE CLUSTERS DE THEMATIQUES ... 67
2.1. Classification non supervisée : une introduction ...67
2.1.1. Principes de base ...67
2.1.2. Notions de proximité, similarité, dissimilarité, distance...69
2.1.3. Méthodes de clustering ...71
2.1.4. Mesures de validité...74
2.2. Clustering dans IC-DOC...75
2.3. Expérimentations ...76
3. CARTOGRAPHIE ET VISUALISATION DE CONNAISSANCES TEXTUELLES ... 81
3.1. Objectifs des outils de cartographie et de visualisation ...81
3.2. Cartographie visuelle dans IC-DOC ...81
3.3. Application ...83
4. CONCLUSION ... 88
CHAPITRE V – CONCLUSIONS ET PERSPECTIVES….…………..…90
1. CONTRIBUTIONS ... 91
2. PERSPECTIVES... 92
2.1. D’autres approches de clustering ...92
2.2. Prise en compte de l’aspect dynamique ...92
2.3. Partage de connaissances...95
Figure 1. Les différentes phases du processus d’Extraction ... 20
Figure 2. Le processus d’extraction de connaissances ... 21
Figure 3. Exemple de représentation conceptuelle du mot « interview »... 28
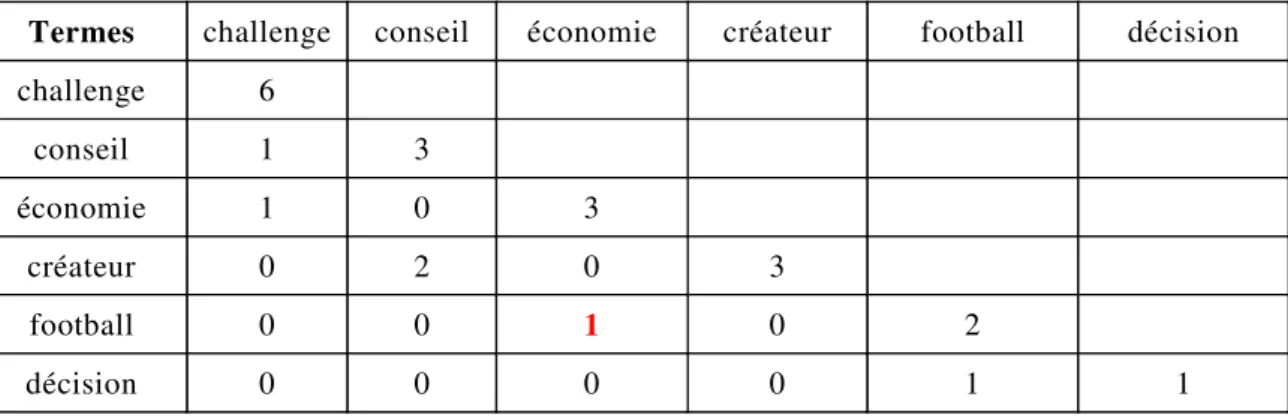
Figure 4. Illustration de la matrice MATCO………..………46
Figure 5. Exemple de graphe de cooccurrences... 46
Figure 6. Matrice MATCO de l’exemple 8 ... 48
Figure 7. Illustration de la matrice RMATCO de E sur E………...…..……49
Figure 8. Un exemple de graphe ... 54
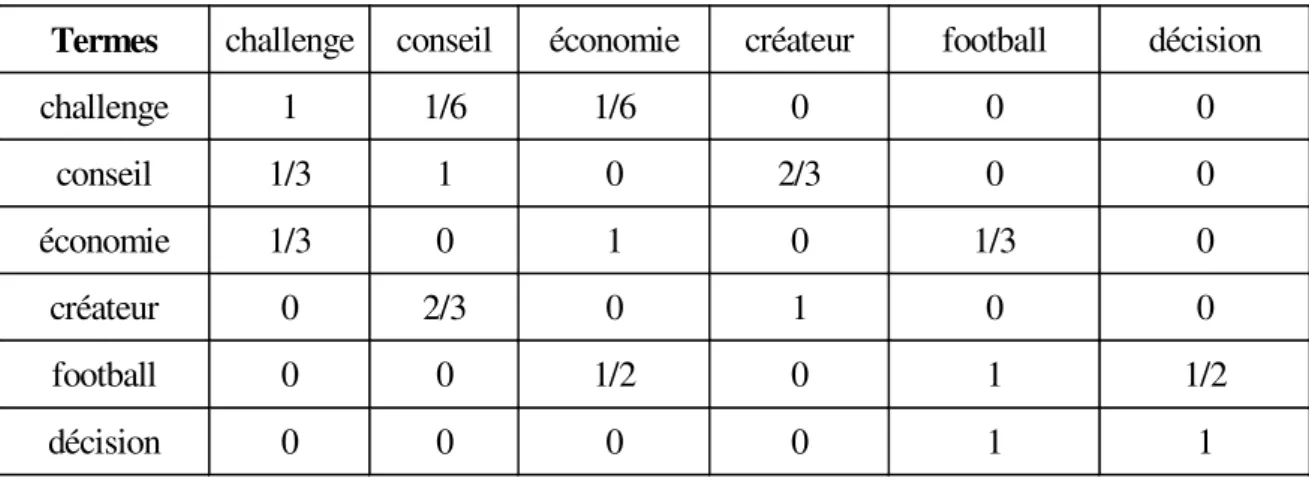
Figure 9. La matrice MatR1………....57
Figure 10. La matrice MatR2 ……….…58
Figure 11. Architecture générale du système IC-DOC ... 63
Figure 12. Un exemple d’étiquetage et de lemmatisation ... 65
Figure 13. Exemple d'interprétation des données analysées ... 66
Figure 14. Illustration du processus de classification non supervisée... 68
Figure 15. Exemple d’application du k-means... 73
Figure 16. Module de fouille... 76
Figure 17. Compositions des collections de documents ... 77
Figure 18. Résultats des expérimentations ... 78
Figure 19. Précisions par thématiques... 79
Figure 20. Contenu de la collection de documents…..………...……..……79
Figure 24. Les cooccurrences contextuelles pertinentes ... 83
Figure 25. Choix et représentation des termes de l’ensemble RTC... 85
Figure 26. Environnement et carte d’information du contenu global ... 87
Figure 27. Carte d’information autour du thème santé ... 87
Figure 28. Auto-organisation de la carte autour du thème jeu... 88
L’explosion du nombre d’informations accessibles et de documents disponibles rend les utilisateurs (entreprises, organismes ou individus) submergés. En effet, ces utilisateurs ne sont plus capables d’analyser ou d’appréhender ces informations dans leur globalité, notamment sur Internet où les informations sont le plus souvent sous formes textuelles [Zan 2005, Clo&al 2006]. Le problème aujourd’hui n’est plus d’accéder aux informations mais de caractériser ces dernières et déterminer l’information utile. Bien entendu, en fonction des besoins de l’utilisateur cette information pourra être utilisée de différentes manières : filtrage de documents, classification de documents, etc.
Il est évident cependant que l’un des éléments clés pour répondre à ces applications est d’être capable d’offrir rapidement l’information enfouie dans les documents. Cette dernière, par exemple, pourra permettre d’affecter un document dans la classe appropriée mais surtout elle offre à l’utilisateur un élément déterminant pour l’aider à prendre ses décisions.
De nombreux travaux de recherche s’intéressent depuis plusieurs années à la mise en œuvre de modèles et systèmes capables d’analyser les contenus textuels, de les organiser et de les représenter automatiquement [Poi 2003, Iha&al 2004, Naz 2004, Dou&Kar 2005, Clo&al 2006]. Il s’agit là d’un des objectifs principaux des approches d’extraction de connaissances à partir de données textuelles [Poi 2003, Zan 2005]. Traditionnellement ce processus est composé de trois phases principales (une présentation détaillée du processus est proposée dans le chapitre II) :
• La première phase a pour but de prétraiter les documents et de les représenter.
• La seconde phase consiste à extraire, à partir de ces représentations, des connaissances en appliquant des techniques de fouille de données.
• La troisième phase se focalise sur les résultats obtenus et cherche à valider la connaissance acquise en fonction des connaissances préalables du domaine.
Une condition sine qua non de la réussite d’un processus d’extraction est de réussir la première étape qui occupe généralement 80% du temps. En effet, cette étape nécessite beaucoup de travail et l’un des éléments clé est sans doute la représentation des documents. Obtenir cette représentation est une tâche difficile car nous sommes confrontés au dilemme suivant : Il faut d’une part être le plus
exhaustif possible (la connaissance acquise sera extraite de cette représentation) mais cette dernière doit également être la plus concise possible pour pouvoir être utilisable par les techniques de fouille de données de la seconde étape.
Pour extraire la connaissance de ces représentations, il existe à l’heure actuelle de très nombreux algorithmes de fouille de données adaptés à différents domaines d’applications (nous reviendrons sur ces techniques au cours du mémoire). Ainsi, à l’issue de ces deux étapes, l’utilisateur final se retrouve confronté avec la connaissance enfouie. Avant de pouvoir prendre une décision, il doit vérifier d’une part que la connaissance est réellement représentative de sa collection de documents et surtout il doit repérer la connaissance qui lui sera réellement utile. Par exemple, savoir que dans 95% des documents qui abordent le langage Java, le terme objet est fortement corrélé à Java est une connaissance mais pas réellement utile. Pour l’aider, il est là aussi indispensable de lui proposer des outils adaptés.
1.
Principales contributions
Dans le cadre de ce mémoire, nous nous intéressons à des collections de documents qui abordent des thématiques différentes. Notre problématique s’inscrit complètement dans le cadre d’un processus d’extraction de connaissances à partir de documents textuels car nous souhaitons mettre à la disposition de l’utilisateur des outils pour lui permettre d’extraire automatiquement des informations sur les différentes thématiques abordées. Nous souhaitons également mettre à sa disposition des mécanismes lui offrant la possibilité de « résumer » les contenus. Avec de tels outils il devient alors possible de répondre à des applications aussi diverses que :
• Des cartes de connaissances offrant la possibilité d’accéder au contenu général des documents. Elles offrent également la possibilité de naviguer entre les différentes connaissances.
• Avoir une information générale sur le contenu. Très souvent, dans un premier temps, les utilisateurs ne cherchent pas quelque chose de précis et préfère avoir un aperçu général du contenu des documents. Une bonne méthode pour aider l’utilisateur est de lui offrir un aperçu général des documents de la même manière qu’il le ferait avec une table des matières. • Classification de documents. En connaissant les différents groupes de
classer automatiquement des documents mais également de les filtrer en fonction de l’intérêt de l’utilisateur.
Au cours de ce mémoire nous nous intéresserons à ce type d’applications. Ainsi, nous considérons les problèmes suivants : étant donné une collection de documents multithématiques, nous souhaitons trouver un modèle de représentation adapté. Via ce modèle notre problème est d’extraire de la manière la plus automatique possible les différentes thématiques et d’offrir des mécanismes pour naviguer dans les connaissances apprises.
1.1.
Modéliser l’information pour extraire la connaissance
Nous verrons, au cours de ce mémoire, que nous proposons un nouveau modèle de représentation de collections de documents. Les travaux antérieurs ont montré qu’une approche basée sur la cooccurrence de termes était efficace pour aider à résumer le contenu des documents [Zan 2005, Iha&al 2004]. Cependant, elle souffre de certaines lacunes liées principalement aux choix de l’utilisateur sur les fréquences d’occurrences de termes ou sur le contexte dans lequel ces termes apparaissent. Nous verrons en particulier que via la fréquence de nombreuses informations sur les relations entre termes qui pourraient être utiles sont éliminées dès le début du processus. Pour résoudre ces problèmes, nous proposons un nouveau critère appelé « partage de contextes ». Intuitivement l’idée de ce critère est la suivante « l’ami de mon ami est mon ami ». Alors que le critère de cooccurrence a tendance à ne regrouper que des termes qui apparaissent ensemble dans un même contexte. Le partage de contextes offre la possibilité de regrouper des termes appartenant à des contextes différents mais qui possèdent des termes communs.
Sur ce principe, nous proposons une approche de modélisation de documents qui débute à l’issue de la phase de prétraitements et qui offre en sortie à la fois les termes en cooccurrences et ceux qui partagent les mêmes contextes.
1.2.
Extraire et visualiser les connaissances des thématiques
Nous proposons également, à partir de ces représentations de documents, d’extraire et de regrouper automatiquement les thématiques des différents documents. Les poids des thématiques dans les collections de documents ne sont pas forcément équilibrés, i.e. le nombre de documents portant sur chacune des
thématiques n’est pas forcément le même, nous verrons que l’approche proposée n’est pas conditionnée par les proportions de documents portant sur chacune des thématiques. Nous proposons également à l’utilisateur de visualiser les connaissances extraites via des cartes dynamiques d’informations. Nous montrerons comment ces dernières, couplées à l’identification de groupes de thématiques, aident l’utilisateur dans ses tâches de consultation documentaire.
1.3.
Le système IC-DOC
Pour valider nos propositions, les différents algorithmes proposés ont été intégrés dans un système appelé IC-DOC (Information Characterization from Document Collections) dont l’objectif est de proposer un environnement d’extraction de connaissances pour des données textuelles issues de thématiques différentes. Nous montrerons comment ce système a été étendu pour extraire des groupes de thématiques et faciliter la navigation dans les connaissances.
2.
Organisation du mémoire
Dans le chapitre II, nous revenons plus en détail sur les problématiques étudiées dans le cadre de notre travail. Notre problématique s’inscrivant dans un contexte d’extraction de connaissances à partir de documents, nous présenterons le processus général. Nous nous focaliserons sur trois aspects de ce processus : les étapes de prétraitements, la modélisation des documents et la phase d’extraction. Même si notre objectif principal n’est pas de proposer une nouvelle approche de prétraitements de documents, il est indispensable de connaître les différentes approches existantes de manière à effectuer les choix les plus pertinents lors du développement d’un système d’extraction. Le second point concerne plus particulièrement la problématique abordée dans cette thèse. Aussi nous décrirons les principales approches existantes. Enfin, au cours de la phase d’extraction, nous proposerons un rapide survol des techniques de fouille de données et montrerons comment elles peuvent être utilisées pour traiter des données textuelles. Nous concluons ce chapitre par une discussion au cours de laquelle nous reviendrons sur les limites des approches traditionnelles de représentation des documents. Le chapitre III présente notre nouveau modèle de représentation de collections de documents. Nous exposons notre proposition basée à la fois sur les notions d’association de termes et sur la notion de partage de contextes entre les différents termes d’une collection de documents. Au cours de ce chapitre, nous présenterons les deux principales phases de notre approche. Enfin, comme dans le chapitre
précédent nous concluons via une discussion sur les avantages de notre approche par rapport aux approches classiques proposées dans le chapitre II.
Le modèle que nous avons défini est intégré dans un système d’extraction de connaissances appelé IC-DOC que nous présenterons dans le chapitre IV. Après avoir présenté l’architecture générale du système et de ces principaux composants, nous montrerons deux domaines d’application et d’utilisation d’IC-DOC. Le premier domaine concerne l’identification de groupes de clusters de thématiques différentes. Avant de présenter les expérimentations menées nous proposons un aperçu des approches de clustering. La seconde application offre à l’utilisateur une cartographie des connaissances extraites de l’ensemble de documents.
Enfin, le chapitre V conclut ce mémoire en revenant sur les principales propositions et en présentant un certain nombre de perspectives associées.
Le mémoire comporte également une annexe présentant des extraits de documents utilisés pour illustrer les différents concepts ou définitions.
Chapitre II – Problématique et Etat de l’Art
1. PROBLEMATIQUE ... 17
2. LE PROCESSUS D’EXTRACTION DE CONNAISSANCES ... 18
3. LE PRETRAITEMENT DES DOCUMENTS... 22
3.1. Approche morphosyntaxique et lemmatisation ...22
4. LA REPRESENTATION DES DOCUMENTS... 24
4.1. Représentations vectorielles ...25
4.2. Représentations basées sur les associations de termes ...29
5. LA FOUILLE DE DONNEES... 33
Pour pouvoir faire face aux grandes quantités de données textuelles disponibles, il est indispensable d’offrir à l’utilisateur final de nouvelles approches qui vont lui permettre d’appréhender, de la manière la plus aisée possible, les éléments significatifs contenus dans ces documents. Les travaux sur l’analyse de documents textuels ont été largement étudiés par des communautés comme par exemple celle du traitement automatique du langage naturel. Cependant, récemment de nouveaux travaux connus sous le nom d’extraction de connaissances à partir de données textuelles sont apparus pour offrir à l’utilisateur, à partir d’un ensemble de documents, les connaissances qui pourront être actionnables. Pour l’utilisateur final, le résultat escompté est d’avoir, par exemple, une classification automatique des documents, (e.g. comment gérer automatiquement les nombreux mails qui arrivent tous les jours ?), d’obtenir un résumé ou un aperçu des documents (e.g. quels sont les éléments importants qui sont contenus dans les textes ? est-il possible en quelques lignes ou via un schéma d’obtenir les principales connaissances associées à des textes ?) ou encore de regrouper ensemble et de manière automatique les informations qui parlent des mêmes thématiques (e.g. comment regrouper d’un côté les informations qui abordent le problème de l’économie du football et de l’autre la création d’entreprises sachant que l’utilisateur s’intéresse régulièrement aux deux thématiques ?). L’objectif du processus d’extraction de connaissances est justement d’essayer de répondre à ces différents problèmes. Notre travail s’inscrit dans ce contexte.
Le chapitre est organisé de la manière suivante. Dans la section 1, nous revenons plus en détail sur la problématique étudiée. Dans la section 2, nous présentons les éléments significatifs du processus d’extraction de connaissances à partir de textes. Le traitement de données de type textuel nécessite d’effectuer des prétraitements sur les documents de manière à pouvoir les manipuler ou les analyser. Même si notre problématique n’est pas liée à cette étape nous présentons les principales approches dans la mesure où elles sont utilisées dans le système IC-DOC que nous présenterons dans le chapitre IV. De la même manière, nous présenterons quelques unes des approches d’analyse qui sont particulièrement adaptées à notre contexte. Notre proposition étant principalement accès sur la définition d’un nouveau modèle de représentation des collections de documents manipulés, nous insisterons sur les principales approches existantes à l’heure actuelle. Enfin dans la section 6, nous concluons ce chapitre par une discussion sur les différents modèles de représentation ainsi que sur leurs limites.
1.
Problématique
Nous avons vu, dans le chapitre précédent, que pour pouvoir aider l’utilisateur final à traiter, de la manière la plus automatique possible, les grandes quantités de documents textuels disponibles aujourd’hui, il devient indispensable de proposer de nouvelles approches qui lui offrent un « aperçu » ou une « caractérisation » des différents contenus textuels. Bien entendu cet « aperçu » peut être décrit de différentes manières. Par exemple, en lui proposant de regrouper ensemble tous les documents qui abordent les mêmes thématiques, nous offrons, aux travers des différents groupes obtenus, une première étape pour faciliter la compréhension des textes manipulés. Une autre manière de résumer les documents est de « cartographier » les connaissances contenues dans les documents, i.e. d’extraire des informations représentatives du contenu, pour par exemple regrouper des éléments (termes, associations, etc.) sur chacune des thématiques abordées par les documents afin de les représenter de manière intelligible. Au travers de ces deux exemples, nous voyons que l’un des problèmes cruciaux à résoudre est : quelle connaissance conserver ? En effet, une condition sine qua non pour permettre de regrouper des documents est d’être capable d’extraire une connaissance commune entre les différents documents. De la même manière, pour extraire et cartographier les éléments importants caractérisant une collection de documents, il est indispensable de se préoccuper de ce que l’on souhaite représenter et de la nature des relations textuelles enfouies dans les documents. S’il y a trop peu d’éléments, il est clair que la représentation sera inutile car clairement pas suffisamment représentative. Inversement, si un trop grand nombre d’informations est proposé à l’utilisateur, il ne sera pas à même de les appréhender et se retrouvera confronté à son problème initial mais dans un autre contexte : comment trouver ce qui est important dans ce qui est proposé ?
Le premier problème que nous abordons dans ce mémoire concerne les connaissances à retenir. En d’autres termes, notre problème peut être décrit de la manière suivante :
Soit un ensemble de documents D = {D1, D2, …, Dn} où chaque document Di est
lui-même composé d’une liste de termes ordonnés T = {T1, T2, … Tm}. Soit M un
modèle de représentation de l’ensemble des documents. La problématique de la représentation des documents consiste à rechercher le modèle M tel que :
• M possède suffisamment d’informations pour représenter le contenu des collections de documents. En d’autres termes, il faut garantir que M conserve les éléments les plus représentatifs des différents contenus
textuels, par exemple ceux du contenu global ou ceux d’une thématique spécifique.
• M doit cependant être suffisamment réduit pour pouvoir appliquer des traitements et des algorithmes de fouille de données.
De manière à illustrer cette problématique, considérons les trois documents suivants : D1= « Java est un langage de programmation objet.», D2= « Java est le plus utilisé dans les Ecoles d’Ingénieurs.», D3= « La programmation objet fait référence au langage Java. », D4 « « Le football professionnel a pris aujourd’hui deux décisions importantes. ». Une première analyse rapide de ces documents montre que certains termes (« un, de, le, les, la, au ») ne sont pas utiles et ne peuvent pas servir à représenter ces documents. En poursuivant ces analyses, nous pouvons transformer nos documents en : « Java langage programmation objet.», « Java utiliser Ecole Ingénieur.», «programmation objet référence langage Java. ». A partir de ces documents transformés, notre problème consiste donc à trouver le modèle M qui soit suffisamment représentatif pour exprimer, par exemple, qu’il existe des rapports entre « java et langage » ou « java et objet ».
Cependant l’obtention d’un modèle de représentation des documents laisse en suspens la question suivante : quid des thématiques des documents ? En effet, quelque soit le modèle de représentation trouvé, il est indispensable de montrer que celui-ci peut effectivement aider l’utilisateur final. La seconde problématique consiste donc, à partir du modèle M, à montrer que nous sommes à même soit de regrouper ensemble les informations (éléments cohérents extraits des textes et représentatifs du contenu) qui abordent les mêmes thématiques soit de visualiser la connaissance associée au contenu. Ainsi dans notre exemple précédent, nous devons être à même de montrer que la collection aborde à la fois la thématique de « programmation en java » et de « l’économie du football ».
Enfin, si nous sommes capables de proposer un modèle M et si nous pouvons extraire des connaissances représentatives des différentes thématiques, le dernier problème est d’offrir à l’utilisateur une plateforme intégrant tous ces aspects. Bien entendu, nous souhaitons que cette plateforme soit la plus automatique possible.
2.
Le processus d’Extraction de Connaissances
Motivés par des problèmes d'Aide à la Décision, les chercheurs de différentes communautés (Intelligence Artificielle, Statistiques, Bases de Données, Interface Homme Machine) se sont intéressés à la conception et au développement d'une
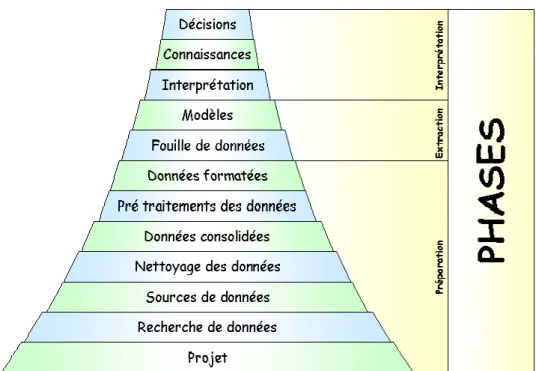
nouvelle génération d'outils permettant d'extraire automatiquement de la connaissance de grandes bases de données. Ces outils, techniques et approches sont le sujet d'un thème de recherche connu sous le nom d’Extraction de Connaissances dans les Bases de données (Knowledge Discovery in Databases). Ce dernier est défini comme un processus non trivial qui consiste à identifier, dans les données, des schémas ou modèles nouveaux, valides par rapport aux connaissances du domaine, potentiellement utiles et surtout compréhensibles et utilisables [Fay&al 1996]. Ce processus, décrit dans la Figure 1, comprend globalement trois phases :
• Préparation des données : L’objectif de cette phase consiste à sélectionner uniquement les données potentiellement utiles dans la base. L’ensemble des données est ensuite soumis à des prétraitements, afin de les transformer et de gérer des données manquantes ou invalides. L’étape suivante dans cette phase consiste à formater ces données pour les rendre compréhensibles aux algorithmes de fouille de données (opérations de transformation et réduction).
• Extraction : En appliquant des techniques de fouille de données, l’objectif est de mettre en évidence des caractéristiques ou des modèles contenus implicitement dans les données.
• Interprétation des résultats : Le but de cette dernière phase est d’interpréter la connaissance extraite lors de l’étape précédente, pour la rendre lisible et compréhensible par l’utilisateur et permettre ainsi de l’intégrer dans le processus de décision.
Figure 1. Les différentes phases du processus d’Extraction
Ce processus est utilisé couramment dans des applications de compagnies d'assurance, compagnies bancaires (crédit, prédiction du marché, détection de
fraudes), marketing (comportement des consommateurs, « mailing »
personnalisé), recherche médicale (aide au diagnostic, au traitement, surveillance de population sensible), réseaux de communication (détection de situations alarmantes, prédiction d'incidents), analyse de données spatiales, etc.
Ce processus général est bien sûr adapté aux différents types de données manipulées. Ainsi dans le cas des données textuelles, le terme extraction de connaissances à partir de bases de données textuelles (Knowledge Discovery in Textual Databases) ou Fouille de Textes (Text Mining) est apparu au milieu des années quatre vingt dix [Fel&Dag 1995, Fel&al 1998, Hea 1999] avec pour objectif « de trouver des relations intéressantes impossibles ou difficiles à détecter par une analyse séquentielle de l'information » [Kod 2000].
Le processus d’extraction à partir de textes est illustré dans la Figure 2 et est assez similaire au précédent. Nous y retrouvons les phases traditionnelles :
• Phase I : Prétraitements et transformations des textes. Cette phase fait appel à des techniques de prétraitements des textes : nettoyage des textes,
suppression des mots peu informatifs, et/ou normalisation. En outre, étant donné qu’il n’est pas possible de traiter les documents dans leur globalité, la transformation offre une représentation réduite des différents documents.
• Phase II : Sélection et réduction des données. Cette phase est généralement regroupée avec la première et a pour but soit de réduire réellement le volume des contenus textuels, soit de minimiser l’espace de recherche (e.g. dans le cas d’une représentation des documents basée sur les vecteurs par exemple, C.f. Section 4).
• Phase III : Utilisation d’algorithmes de fouille de données. • Phase IV : Analyse, interprétation et validation des résultats.
Dans les sections suivantes nous présentons plus en détail les principales approches de prétraitements dans la mesure où elles seront utilisées dans le système que nous proposons dans le chapitre IV. Nous nous focaliserons ensuite sur les principales approches, proches de notre problématique, de représentation de documents afin de mieux en étudier leurs limites. Enfin nous proposerons un aperçu des principales approches de fouille de données particulièrement utilisées aujourd’hui pour analyser des collections de documents.
Figure 2. Le processus d’extraction de connaissances à partir de documents textuels
3.
Le prétraitement des documents
Les données textuelles sont une forme particulière de données complexes. Elles ne sont pas délimitées, structurées et étiquetées sémantiquement de façon explicite. En conséquence ces données nécessitent un traitement préalable. De manière générale, l’objectif de ce prétraitement est de minimiser l’espace de recherche. En effet, même si les capacités des ordinateurs évoluent constamment, il n’est malheureusement pas possible de traiter les documents dans leur intégralité. En fonction des différentes thématiques de recherche, cet objectif est mené de différentes manières. Par exemple, les approches issues du traitement automatique du langage naturel offriront des techniques pour obtenir les différents composants d’une phrase, pour désambiguïser, pour associer du sens aux termes manipulés, etc. D’un autre côté les approches plus statistiques se focaliseront sur des techniques plus globales en recherchant par exemple les préfixes de mots communs.
Il est important de noter que quelque soit la technique utilisée, elle est souvent couplée à une approche plus classique basée sur la suppression de mots ou termes appartenant à une liste (e.g. bad words, liste noire, etc.). Cette approche offre en outre l’avantage d’éliminer des mots qui ne seraient pas utiles dans le cadre d’une analyse donnée. Par exemple, l’auxiliaire être et avoir sont souvent utilisés et ne caractérisent pas le contenu des documents, donc peuvent être éliminés du traitement. 1
Dans la suite de cette section, nous nous intéressons aux approches basées sur un étiquetage morphosyntaxique. Cependant cette étape n’est pas suffisante et elle est généralement suivie d’une étape de « lemmatisation ».
3.1.
Approche morphosyntaxique et lemmatisation
L'étiquetage morphosyntaxique correspond à la préparation des textes pour la phase de modélisation du contenu. Il comprend une analyse morphologique et une analyse syntaxique [Cha 1984, Bri 1992]. Notons que ces deux analyses sont précédées par certains prétraitements (traitement des ponctuations, majuscules, codages et formats). Une analyse morphologique peut être considérée comme un automate qui traite isolément chaque forme d’un texte en lui associant des traits informationnels (ou propriétés) [Fay&al 1991]. L’analyse syntaxique permet de segmenter les textes en propositions. Chaque proposition est formée de couples
1 Ceci est généralement utilisé dans les approches statistiques. Toutefois dans certains
(entrée lexicale, catégorie). Les seules ambiguïtés qui demeurent sont internes à une catégorie. Les résultats de l’analyse des propositions sont des arborescences de structures syntaxiques attestées par la langue [Hab&al 1997]. Au final, l'étiquetage morphosyntaxique associe à chaque mot d'une phrase sa catégorie morphologique (genre, nombre) et syntaxique (nom, adjectif, verbe, etc.).
Exemple 1 :
Soit le document D1= « Java est un langage de programmation objet.», une analyse morphosyntaxique de ce document donne :
« java – nom commun féminin singulier », « est – verbe indicatif présent 3ème personne du singulier », « un – article indéfini masculin singulier »,
« langage – nom commun masculin singulier », « de – préposition », « programmation – nom commun féminin singulier », « objet – nom commun masculin singulier », « . – ponctuation forte (fin de phrase) ». Plusieurs étiqueteurs, ou « taggers », existent à l'heure actuelle, pour le français ou l'anglais notamment, et atteignent des performances qui dépassent les 90% de correction (i.e. le quotient du nombre de mots correctement étiquetés sur le nombre total de mots étiquetés). Un état de l’art sur l’analyse morphosyntaxique est disponible dans [Par&Raj 2000].
Dans la suite de cette section, nous présentons la lemmatisation qui est généralement couplée à l’analyse morphosyntaxique.
Dans le langage naturel, il existe une grande redondance dans les marques morphologiques. Par exemple, dans la morphologie des adjectifs, rien ne correspond en oral aux marques écrites du féminin. En effet, la règle écrite de passage du masculin au féminin consiste à ajouter un « e ». Par exemple, dans « enfoui/enfouie », le « e » ne se prononce pas à l’oral. De la même manière, le pluriel des syntagmes nominaux, « le scientifique européen » s’écrit « les scientifiques européens » au pluriel. Il y a plus d’économie des marques en oral qu’en écrit. Pour remédier au problème des redondances dans les marques morphologiques, il serait intéressant de regrouper, par exemple, les formes singulier/pluriel sous une forme unique.
La lemmatisation permet le regroupement des formes morphologiques d’une même unité linguistique en une seule unité appelé lemme. Elle réduit ainsi des mots en entités premières, appelées lemmes ou formes canoniques. Par exemple « journal » est la forme canonique de « journal » et « journaux ». Le lemme est
l'infinitif pour les verbes, la forme masculine singulière pour les noms, etc. La lemmatisation permet de réfléchir en fonction du sens des mots en faisant abstraction de leurs formes. Elle permet d’analyser le contenu d’une collection de documents, sans avoir à rentrer l'ensemble de ses variantes pour chacun des mots contenus dans les documents.
Exemple 2 :
Considérons le document de l’Exemple 1, les différents lemmes associés sont les suivants :
« java », « être », « un », « langage », « de », « programmation », « objet ». Il existe également une autre catégorie d’algorithmes ou techniques proches de la lemmatisation. Il s’agit des algorithmes de « stemming » (appelé déssuffixation en français). Ces algorithmes ne sont pas couplés généralement à l’analyse morphosyntaxique. Ils associent plusieurs mots ayant le même radical, i.e. enlever les suffixes des mots pour ne conserver que la partie racine, en s’aidant de règles et de listes d’exceptions. Les algorithmes de « stemming » les plus connus sont ceux de Lovins [Lov 1968] et de Porter [Por 1980]. Par exemple, le stem des mots « manger » et « mangeable » est « mang ».
Exemple 3 :
Les stems associés au document de l’Exemple 1, sont les suivants : « jav », « est », « un », « langag », « de », « programm », « objet ».
4.
La représentation des documents
Il existe dans la littérature de nombreux modèles de représentation de documents textuels. Nous pouvons citer, par exemple, l’utilisation de vecteurs dont les composantes représentent des termes [Sal 1973, Sal 1989], des matrices de distribution de termes ou de relations entre termes [Bes&al 2001, Lan&Lit 1991]. Dans le cadre de notre problématique, nous nous intéressons aux modèles utilisant les mots ou les termes comme unité de représentation. En effet, ces derniers ont la réputation d’être simples et efficaces. Ils existent cependant certains travaux qui utilisent la phrase (ou un segment de texte) comme unité de représentation [Sch&al 1995, Tze&Har 1993, Fuh&Buc 1991]. L’argumentation en faveur de ces modèles réside dans le fait que la phrase est plus informative que le mot. Cette dernière offre également l’avantage de conserver les positions des
mots. Cependant, les expériences menées ont montré que les résultats n’étaient pas meilleurs [Car&al 2001] et que surtout ces approches sont très difficiles à mettre en œuvre. En conséquence, en utilisant les phrases comme des unités de représentation, les connaissances syntaxiques sont conservées mais les connaissances statistiques sont dégradées à cause du trop grand nombre de combinaisons possibles [Car&al 2001, Lew 1992a].
L’objectif de la suite de cette section est d’étudier les différents modèles de représentation de textes largement utilisés dans la littérature. Pour chacun des modèles nous analysons les critères pris en considération pour la représentation des différents termes.
4.1.
Représentations vectorielles
Les modèles vectoriels sont largement utilisés pour la représentation de textes. Le modèle vectoriel standard et le modèle Latent Semantic Indexing sont les plus utilisés et implémentés. Nous détaillons ces derniers dans la suite de cette section.
Le modèle standard MS « sacs de mots »
Dans le cadre du modèle vectoriel standard (MS), les textes sont considérés comme des « sacs de mots » [Sal 1971a, Sal 1971b, Sal&McG 1983]. L’idée principale est de transformer les différents documents d’une base documentaire en vecteurs où chacun des éléments d’un vecteur de texte représente des unités textuelles ou tout simplement des mots appelés aussi « termes d’indexation ». Plusieurs travaux utilisent les mots comme termes d’indexation [Dum&al 1998, Aas&Eik 1999, Apt&al 1994, Lew 1992b]. Un mot est considéré comme étant une suite de caractères encadrés par des caractères de ponctuation ou appartenant à un dictionnaire spécifique. Des outils, basés sur des approches linguistiques, statistiques ou mixtes sont utilisés pour l’identification des différentes unités textuelles.
Dans le modèle vectoriel standard, les composantes d’un vecteur représentant un texte sont fonction de l’occurrence des mots dans le texte. Ce modèle a été initialement introduit par Gérard Salton [Sal&Les 1965, Sal 1971a] dans l’objectif d’implémenter un système de recherche d’informations. L’implémentation la plus connu de ce modèle est le système de recherche documentaire SMART. L’évolution de ce système est décrite dans [Sal 1991]. Dans ce modèle les composantes des vecteurs représentent des termes considérés comme les plus discriminants. Dans le cadre du modèle vectoriel standard, ces termes sont
sélectionnés en fonction de leurs fréquences d’apparition dans les documents et en fonction du nombre de documents contenant ces termes.
Soit C une collection de documents textuels, Di un document de C, soit t le nombre
de termes d’indexation et T = {T1,…, Tj,…,Tt} l’ensemble de ces derniers. Dans le
modèle vectoriel standard, le document Di est représenté par un vecteur Vi. La
collection de textes peut être ainsi représentée par une matrice dont les colonnes représentent les termes d’indexation et les lignes représentent les documents de cette collection.
Vi = (W1,..., Wj,...Wt),
où Wj est le poids d’un terme Tj dans le document Di et j = 1..t.
Le poids donné à un terme d’indexation dans un document est calculé en fonction de la fréquence d’occurrence du terme TF (Term Frequency) dans le document et du nombre de documents contenant le terme IDF (Inverse Document Frequency). Les calculs des poids et les pondérations accordés à un document D ont fait l’objet de nombreuses études [Sin 1997, Lee 1995, Buc&al 1992, Sal&Buc 1988].
Le modèle LSI/PLSI
Le modèle Latent Semantic Indexing (LSI) découle du modèle vectoriel standard. Il tente de prendre en considération la structure sémantique des termes pour la représentation des documents. Dans ce modèle, les documents sont représentés dans un espace réduit de termes d’indexation [Dee&al 1990, Sch&al 1995, Lan&al 1998]. Les techniques LSI utilisent, dans un premier temps, une matrice M (documents × unités linguistiques), dans laquelle chaque élément Wij est une
pondération en fonction du nombre d'occurrences du terme Tj dans le document
Di. Soit n le nombre de documents de la collection et t le nombre des termes
d’indexation. La matrice M peut être représenté comme suit.
=
=
nt 2 n 1 n ij t 2 22 21 t 1 12 11 n 2 1W
W
W
W
W
W
W
W
W
W
d
d
d
M
...
...
...
...
...
...
...
Une décomposition en valeurs singulières (SVD) de la matrice M est ensuite effectuée. Après cette décomposition, seuls les k premiers vecteurs propres sont intégrés, les axes factoriels correspondant aux plus grandes valeurs propres sont conservés en application du théorème de Eckart et Young [Dee&al 1990]. Ce théorème montre qu'il s'agit dans ce cas des axes permettant un ajustement dans un espace de dimension réduite minimisant la perte d'information. Dans LSI, la valeur représentée dans la matrice sur laquelle est appliquée la décomposition est définie comme étant le produit du poids local du terme, i.e. poids du terme dans le document, et du poids global du terme, i.e. poids du terme dans la collection de documents. Cette valeur peut aussi correspondre à la fréquence d'un terme donné dans un document donné. Ces valeurs ne sont que des pondérations proches de TF/IDF [Dee&al 1990, Lan&al 1998].
Hoffmann a proposé un modèle probabiliste du Latent Semantic Indexing (PLSI). Il considère l'hypothèse que les documents sont associés à un certain nombre de sens (Latents) et que les termes correspondent à l'expression de ces sens [Hof 1999]. De façon probabiliste, notant W l'ensemble des mots, D l'ensemble des documents, tel que : W = {W1,…,Wt} et D = {D1,…,Dn}, la probabilité de la paire
observée (d
∈
D, w∈
W) est donnée par la formule suivante :)
d
(
p
)
d
|
w
(
p
)
w
,
d
(
p
=
Cette probabilité est calculée en utilisant un algorithme de type Expectation-Maximization (EM) [Dem&al 1977]. Les dimensions de l'espace réduit du modèle LSI correspondent ici aux sens du modèle PLSI.
Représentations conceptuelles et basées thésaurus
Ils existent des approches utilisant les concepts pour la représentation des textes tel que Word Category Map ou des modèles issus de la méthode LSI [Koh&al 2000, Dee&al 1990, Lio&al 2004]. Ces méthodes dépendent de la distribution des probabilités des mots au sein du jeu d’apprentissage, en conséquence les données du jeu ont une influence sur la génération de l’espace des concepts. J. Chauché [Cha 1990] a proposé un nouveau modèle vectoriel de représentation de textes. Au lieu de définir un espace vectoriel dont chaque dimension représente un terme d’indexation, l’ensemble des termes est projeté sur un ensemble fini de concepts extraits d’un thesaurus. Cette représentation permet une factorisation des termes par regroupement de leurs champs sémantiques. Par exemple, deux synonymes
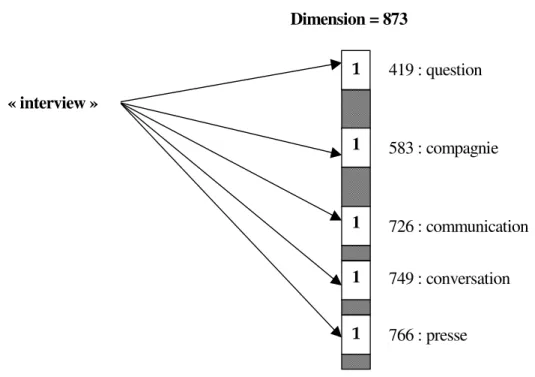
partageront un ensemble de mêmes concepts. L’auteur utilise, pour des documents français, un thésaurus composé de 873 concepts hiérarchisés en 4 niveaux. Rappelons qu’un thésaurus permet uniquement d’explorer, à partir d’un concept, les mots qui s’y rattachent et inversement.
Par exemple, le mot « interview » défini par les concepts 419 (question), 583 (compagnie) et 726 (communication), 749 (conversation) et 766 (presse) du thésaurus, sera représenté par un vecteur de dimension 873 dont toutes les composantes sont nulles sauf celles associées aux concepts 419, 583, 726, 749 et 766 qui seront identiques (C.f. Figure 3). Le thésaurus est donc défini comme un
ensemble de couples de L × R873 avec L l’ensemble des lemmes du thésaurus. Les
dimensions de l’espace vectoriel ne sont pas associées à des termes d’indexation mais à des concepts.
1 1 1 1 1 726 : communication 419 : question 749 : conversation 583 : compagnie « interview » 766 : presse Dimension = 873
Figure 3. Exemple de représentation conceptuelle du mot « interview »
Après l’extraction de l’ensemble des lemmes d’un texte, une association est réalisée entre les lemmes et le vecteur qui leur est associé au sein du thésaurus. Ensuite, pour chaque texte un vecteur conceptuel est calculé en fonction de la moyenne normalisée des lemmes qu’il contient [Jai&al 2005].
Autres modèles vectoriels
Ils existent d’autres modèles vectoriels de représentation de textes, appelés modèles probabilistes. Des modèles particuliers, développés spécifiquement pour la recherche documentaire, utilisent des pondérations justifiées sur des bases probabilistes dépendantes des requêtes (une requête est formée d’un ensemble de mots clés pour effectuer une recherche documentaire). La représentation finale de chaque document est un vecteur dont chaque composante est une pondération associée à un terme.
Les modèles probabilistes de recherche documentaire sont par exemple présentés dans [Spa&al 1998]. Ces modèles ont également l'avantage d'éviter le problème de la haute dimensionnalité de la requête. Nous pouvons citer, par exemple, le modèle probabiliste de représentation de Robertson et Spark-Jones développé pour la recherche documentaire [Rob&Spa 1976]. Il repose sur le principe d'ordre des probabilités (Probability Ranking Principle) [Rob 1977] pour présenter les documents retournés aux utilisateurs. Nous pouvons également citer, comme modèle probabiliste, Okapi, qui prend en considération la distribution des fréquences des termes dans les documents [Rob&al 1981, Rob&al 1994]. Ce modèle a été testé avec succès pour les campagnes TREC. L’hypothèse faite par les auteurs est qu'un terme est relié à un thème (i.e. un document parle ou ne parle pas de ce thème). Le document parlant du thème peut utiliser un certain nombre de fois le terme correspondant ou ne pas l'utiliser. Réciproquement, un document ne parlant pas du thème peut néanmoins utiliser le terme associé. Dans ce modèle la distribution des fréquences des termes dans les documents est un mélange de deux distributions : la première pour les documents parlant du thème et la seconde pour les autres documents. L'hypothèse retenue est que ces deux distributions suivent des lois de Poisson [Rob&Wal 1994].
4.2.
Représentations basées sur les associations de termes
Nous avons présenté dans la section précédente divers modèles de représentations vectorielles de textes. Ces modèles exploitent essentiellement la structure explicite des documents (les mots). Certains d’entre eux tentent de prendre en considération les dépendances qui peuvent exister entre les mots par des modèles statistiques ou des transformations stochastiques en partant des informations sur l’occurrence des mots dans les documents (TF) ou en documents (IDF). L’origine de ces approches est issue de la Sémantique Distributionnelle (SD) qui est fondée sur l’hypothèse suivante : « La sémantique des éléments textuelles est déterminée par leurs distributions dans les textes ». En effet, elle suppose l'existence
d'une forte corrélation entre les caractéristiques distributionnelles observables des mots et leurs sens. Ainsi, la sémantique d’un mot est reliée à l'ensemble des contextes dans lesquels apparaît ce dernier [Har 1988, Har&al 1989]. Notons que la sémantique distributionnelle hérite de la théorie de Firth « The basic assumption of the theory of analysis by levels is that any text can be regarded as a constituent of a context of situation, ………, You shall know a word by the company it keeps » [Fir 1957] qui peut se résumer par « le sens d’un mot peut être donné par ses voisins ».
Les modèles qui prennent en compte les dépendances entre les mots n’effectuent pas une analyse préalable de la distribution des associations des termes dans les collections de documents. Ils utilisent des techniques statistiques, linguistiques ou mixtes. Ainsi, les approches linguistiques cherchent à dégager le lexique des documents puis étudient les différentes dépendances morphologiques et syntaxiques des mots dans les phrases [Chu&Han 1989, Paz 1999]. L'analyse des documents par des méthodes statistiques est plus récente et fait suite aux travaux d’Estoup et de Zipf [Leb 1998]. Elle se base sur l'application de méthodes quantitatives aux éléments linguistiques. Avant d’exposer les modèles existants dans la littérature, nous précisons la notion d’association de termes.
Association de termes
En raison des difficultés de représentation des connaissances textuelles par des modèles symboliques structurés tel que les « frames » et les modèles logiques, des méthodes plus adaptées aux applications exploitant des collections de documents sont nécessaires. Ces méthodes ont suscité un intérêt particulier ces dernières années. Nous nous intéressons particulièrement dans la suite de cette section aux modèles de représentation basés sur la notion d’association de termes.
D’une manière générale, dans la littérature, la cooccurrence (appelée également association ou co-citation) de termes est définie de la manière suivante :
Définition 1 (Cooccurrence de termes)
Soient deux termes T1 et T2. Une cooccurrence entre les termes T1 et T2 est
définie comme étant l’apparition commune des deux termes dans un même contexte. Elle correspond à deux termes qui apparaissent ensemble dans un même segment de texte.
En fonction des modèles un segment de texte peut être une fenêtre de mots, une phrase ou un paragraphe.
Le modèle DSIR
Le modèle de représentation de textes Distributional Semantic for Information Retrieval (DSIR) [Raj&al 2000, Bes&al 2001] est basé sur les cooccurrences des mots dans les collections de documents. Les contextes des unités linguistiques sont des éléments essentiels du modèle DSIR car ils constituent le support principal pour la dérivation des représentations des mots. Ces dernières sont obtenues à partir des fréquences de cooccurrences entre l’ensemble des mots d’une base documentaire et les termes d'indexation de cette dernière. Dans ce contexte, un mot (unité linguistique) Ui est représenté par un vecteur de poids associés aux
fréquences de cooccurrences de ce mot avec l’ensemble des termes d'indexation T. Ce vecteur est appelé profil de cooccurrences de Ui par rapport à T. Notons que
dans le modèle DSIR un contexte de cooccurrence correspond à une phrase.
Soit Wij le poids associé à la fréquence de cooccurrence de Ui avec un terme
d’indexation Tj et t = |T|. Ui est représenté par un vecteur VCOi :
VCOi = (Wi1,…,Wij, …,Wit)
Ainsi, une collection de documents est représentée par une matrice M de cooccurrences (unités linguistiques × termes d’indexation).
Soit U l’ensemble des mots de la collection et n le nombre de ces mots. Soit T l’ensemble des termes d’indexation et t le nombre de ces derniers. La matrice M est définie comme suit.
=
=
nt 2 n 1 n ij t 2 22 21 t 1 12 11 n 2 1W
W
W
W
W
W
W
W
W
W
d
d
d
M
...
...
...
...
...
...
...
U
U
U
Le modèle DSIR utilise une fonction de représentation d’un document à partir de la matrice de distribution des unités linguistiques. Dans ce cas, il s’agit de la matrice M. Dans un premier temps, un document est représenté par un vecteur V d’occurrence suivant le modèle vectoriel standard. Puis ce vecteur est transformé via la matrice M par une multiplication du vecteur V par M. Cette représentation
prend en considération la distribution des cocitations de mots et intègre des connaissances syntaxiques dans la phase de sélection des cooccurrences. En effet, les cooccurrences des mots sont prises entre les gouverneurs des groupes syntaxiques ou les constituants d’un même groupe syntaxique. Une étape de filtrage syntaxique est donc nécessaire avant toute représentation de textes.
Divers modèles basés sur l’analyse des cooccurrences
La notion de cooccurrences a été utilisée dans divers autres modèles pour accomplir des tâches variées, notamment dans les systèmes de recherche d’informations basés sur l’expansion de requêtes [Les 1969, Rij 1977, Buz&al 2001]. Ces travaux reposent sur l’hypothèse suivante : si un terme d'indexation est utile pour la discrimination des documents pertinents par rapport aux documents non pertinents, alors tout terme d'indexation étroitement associé est aussi susceptible d'être utile pour cette discrimination.
Cependant, l'expansion de requêtes par l'utilisation de modèles de cooccurrences n'a pas apporté les améliorations espérées. En particulier, H.J. Peat et P. Willett [Pea&Wil 1991] montrent que ces modèles ne sont pas particulièrement adaptés à la recherche documentaire. Dans [Sch&Ped 1994], les auteurs proposent une méthode assez proche de celle de DSIR. La construction d'un thesaurus automatique est effectuée en calculant les similarités entre termes par leurs profils de cooccurrences. Dans [Qiu&Fre 1993, Qiu&Fre 1995], les auteurs proposent la notion de « Similarity Thesaurus » en calculant la similarité « terme × terme » par la comparaison des profils de leurs distributions dans les documents. Ce thesaurus est alors utilisé pour faire une expansion des requêtes en calculant, à chaque fois, les termes les plus proches de la requête dans son ensemble (et non seulement de chaque terme de la requête). Cette dernière est représentée par le vecteur moyen des profils de distribution des termes qu'elle contient dans la collection de documents. [Dag&al 1997, Dag&al 1999] proposent d'estimer la probabilité de cooccurrence de deux mots U1 et U2, lorsque ces derniers n'apparaissent pas
ensemble dans un même contexte dans le corpus. Cette opération est réalisée par une combinaison des estimations de cooccurrences entre U2 et les mots les plus
proches d’U1 (la proximité étant calculée par une mesure de similarité spécifique).
Il existe également d’autres approches de représentation de textes proches des modèles présentés dans cette section, il s’agit des modèles basés sur les graphes. Nous pouvons citer les travaux de A. Lelu [Lel 2003] qui utilise des éléments de la théorie des graphes pour la représentation et la comparaison de textes. Le langage UNL (Universal Networking Langage) est un formalisme permettant de représenter la sémantique de chaque document par un graphe. Les informations écrites en
langage naturel sont converties en UNL puis traduites dans des langages cibles [Uch&Zhu 2005a, Uch&Zhu 2005b].
5.
La fouille de données
Dans cette section, nous revenons sur l’une des étapes principales du processus d’extraction de connaissances à partir de documents textuels : La fouille de données, et nous présentons quelques unes des techniques existantes. Même s’il existe de nombreuses techniques de fouille de données disponibles à l’heure actuelle2, les travaux de recherche autour des documents ont particulièrement
abordé les approches suivantes :
• La recherche de règles d'association : Le problème de la recherche de règles d'association introduit par R. Agrawal et al. en 1993 [Agr&al 1993], est souvent appelé « problème du panier de la ménagère » (Market Basket Problem) car les transactions opérées par les clients d'un magasin et dont la trace est stockée représentent une application typique pour le processus de découverte de connaissances. Dans un tel contexte, une règle d'association peut être par exemple : « 85% des clients qui achètent du beurre et du café achètent aussi du lait ». La recherche de règles couvre un large champ d'applications telles que la conception de catalogues en ligne dans un contexte de e-commerce, la promotion de ventes, le suivi de clientèle, la gestion des stocks, etc. Dans le cas de données de type textuel, les approches de règles d’association sont utilisées généralement pour rechercher des corrélations entre termes de documents [Fel&Hir 1998]. Par exemple, en considérant que l’on dispose d’un ensemble de documents réécrits sous la forme {identification du document, ensemble de mots clés}, l’objectif est d’abord de rechercher les mots fréquemment corrélés entre eux puis de générer les règles d’associations.
• La recherche de motifs séquentiels : En 1996, la problématique de la recherche de règles d'association est étendue pour détecter des comportements typiques dans le temps et le concept de motifs séquentiels est introduit [Agr&Sri 1995]. La recherche de tels motifs consiste à extraire des ensembles d'objets couramment associés sur une période de temps spécifiée. Il est alors possible d'extraire des relations
2 Plus de 27 techniques différentes sont répertoriées dans (http://www.kdnuggets.com) et
temporelles comme par exemple « 36% des clients qui achètent une télévision, achètent un lecteur de DVD dans les deux ans qui suivent et un Home-Cinéma 6 mois après » ou « 30% des abonnés d'une vidéothèque qui ont emprunté Marius, empruntent Fanny un mois plus tard, puis César quelques semaines après ». La problématique de l'extraction de motifs séquentiels est en fait une extension de celle des règles d'association. En effet la prise en compte du temps dans les enregistrements à étudier permet une plus grande précision dans les résultats, mais implique aussi un plus grand nombre de calculs et de contraintes. Ce problème posé à l'origine par l'industrie de la vente au détail, intéresse à présent des domaines aussi variés que les télécommunications (détection de fraudes), la médecine (identification de symptômes précédant les maladies) ou encore les domaines financiers. Par rapport aux règles d’association, les motifs offrent dans le traitement des textes de conserver l’ordre d’apparition des différents termes. En appliquant des algorithmes de recherche de motifs, nous obtenons alors non plus des corrélations entre termes de documents mais plutôt des corrélations de succession de termes. Par exemple, dans [Len&al 1997], les auteurs proposent d’utiliser des algorithmes de motifs séquentiels pour extraire des tendances dans des documents.
• La classification : Elle consiste à analyser de nouvelles données et à les affecter, en fonction de leurs caractéristiques ou attributs, à telle ou telle classe prédéfinie. Les techniques de classification sont, par exemple, utilisées pour déterminer, pour une banque, si un prêt peut être accordé, en fonction de la classe d'appartenance d'un client. La classification est très utilisée pour traiter des données de type textuel car il existe de nombreux domaines d’applications (classification automatique de documents, de mails, de news, etc.). Ces dernières années des approches particulièrement efficaces ont été proposées. Un état de l’art de ces approches est proposé dans [Ber 2003] et [Seb 2006]. La classification peut également bénéficier d’autres approches de fouille de données. Ainsi, dans [Wan&al 1999], les auteurs proposent d’effectuer une classification à partir des résultats obtenus via des algorithmes d’extraction de règles et S. Jaillet propose de classifier à partir de motifs séquentiels [Jai 2005].
• Le clustering : Le problème du clustering (appelé aussi classification non supervisée ou segmentation) consiste à regrouper des enregistrements qui semblent similaires dans une même classe. Il est complémentaire à
celui de la classification car le but ici est de rechercher les différentes classes possibles d'appartenance en fonction des différents attributs ou critères qui caractérisent les données. Les applications concernées incluent notamment la segmentation de marché, la segmentation démographique (pour identifier par exemple des caractéristiques communes entre populations), etc. Dans le cas de documents textuels, le clustering est particulièrement utilisé pour regrouper des documents en fonction de leur contenu. Nous revenons plus en détail sur ces aspects dans le chapitre IV en proposant une présentation des principes généraux.
6.
Discussion
Dans ce chapitre, nous avons présenté les problématiques étudiées ainsi que les différents travaux existants autour de ces problématiques. Dans cette discussion, nous revenons tout d’abord sur le processus d’extraction de connaissances à partir de documents textuels en examinant son adéquation par rapport à nos problématiques. Nous revenons ensuite sur les problèmes de modélisation des documents.
Par rapport aux problématiques générales que nous abordons, le premier constat est que ce travail s’inscrit dans le cadre d’un processus d’extraction de connaissances à partir des données textuelles. En effet, nous souhaitons aider l’utilisateur à mieux appréhender les contenus de l’ensemble de documents dont il dispose (cet objectif est également partagé par celui du processus). Les conséquences sont nombreuses comme nous avons pu le voir tout au long de ce chapitre : nous ne pouvons pas manipuler tous les documents dans leur intégralité, nous avons besoin de modéliser les « éléments » réellement caractéristiques de documents, nous avons besoin d’utiliser des algorithmes de fouille de données pour obtenir la connaissance, etc. Parmi les travaux existants autour du processus, nous avons choisi d’en décrire plus particulièrement trois : le prétraitement, la modélisation et la fouille. Ces choix n’ont pas été fait au hasard. En ce qui concerne le premier point, nous avons pu constater dans la section 3 que les approches morphosyntaxiques suivies d’une lemmatisation étaient très efficace à l’heure actuelle, le problème réside dans le choix de méthodes pertinentes. Nous reviendrons sur cet aspect dans le système IC-DOC que nous proposons au chapitre IV. En ce qui concerne la fouille de données, il existe de nombreuses méthodes qui sont plus ou moins adaptées en fonction des buts visés. Par exemple, si nous souhaitons classer automatiquement des documents, les travaux menés autour de la classification ont montré qu’ils étaient