Approche hybride pour la reconnaissance de la parole
Texte intégral
Figure



Documents relatifs
Taken together, the results of both experimental conditions suggest that older adults require more resources to recognize speech, leaving less resources available for the tactile
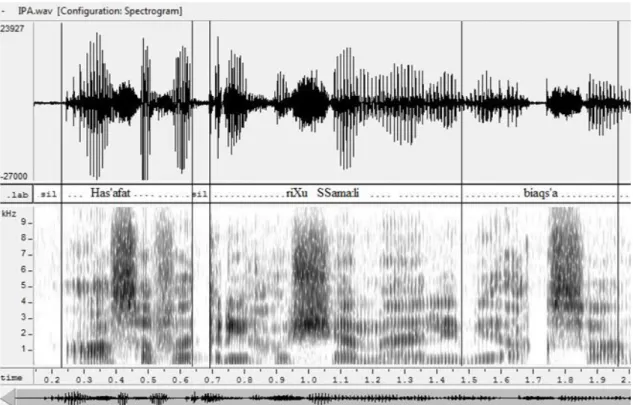
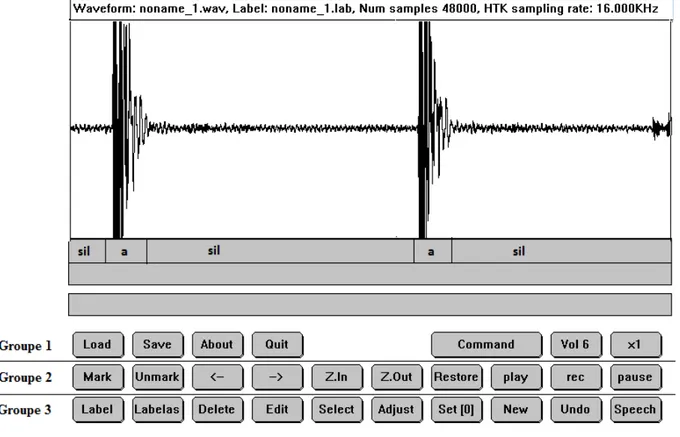
L'expérience qui nous a fourni le présent exemple part de la syllabe 'cri' du mot "écrite", saisi dans l'enregistrement d'une conférence. Dans une certaine mesure, la
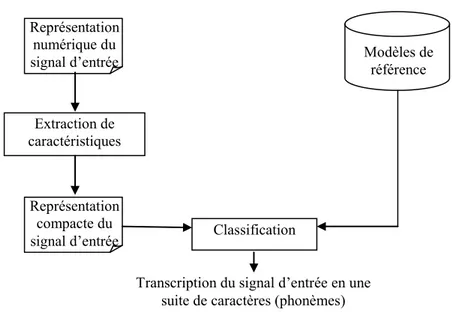
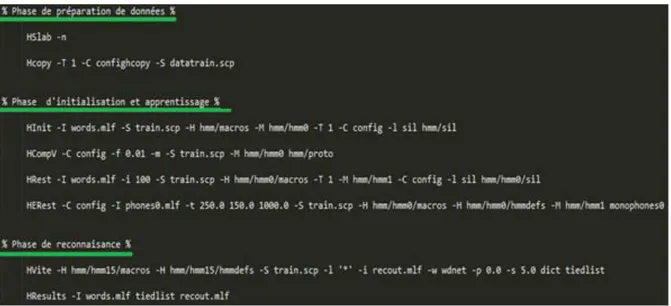
Les principaux composants utilisés pour le développement d’un tel système de reconnaissance sont les principales sources de connaissances (corpus de parole, corpus de texte,
1. Création de modèles dont les probabilités de transition sont équiprobables. La moyenne et l’écart-type de l’ensemble des observations sont calculés et affectés
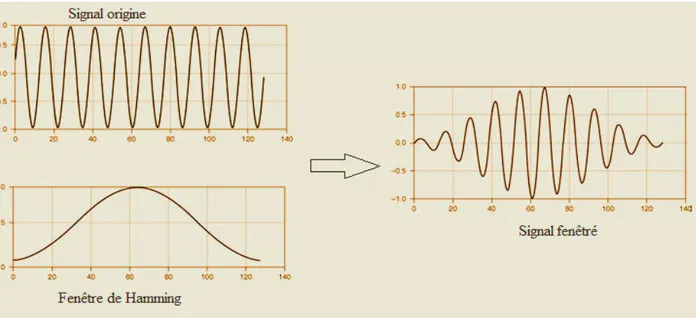
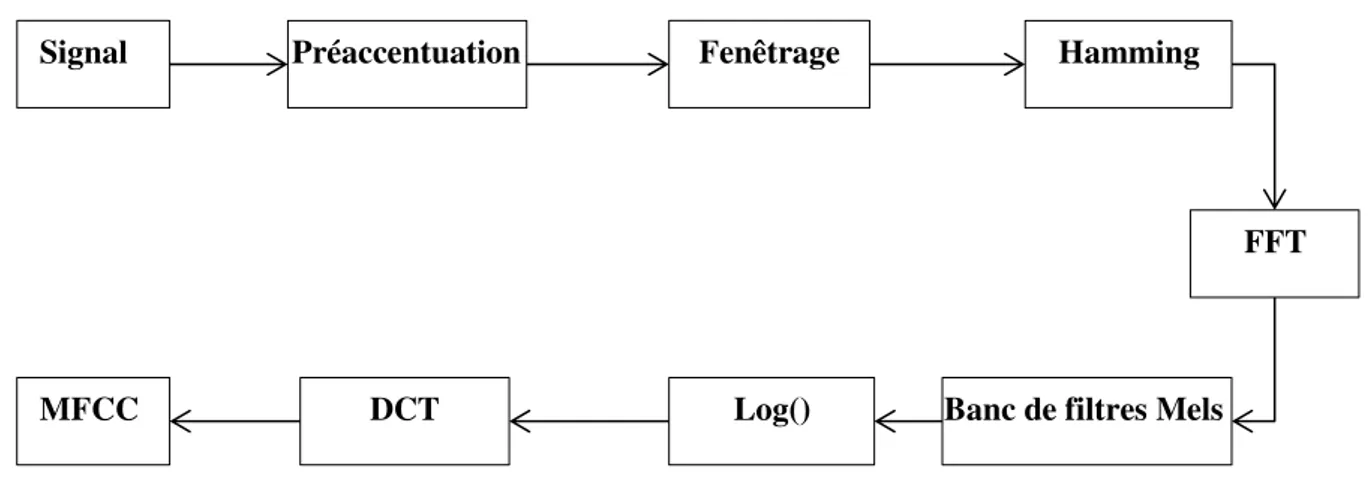
La phase de segmentation est très importante puis que les traitements ultérieurs (description et classification) sont fortement lies au résultat de segmentation. En effet,
Chapitre III : Réalisation Le premier tableau concerne la classification des attributs par chaque Agent Classifieur avant la communication et la collaboration entre eux ; d’après
Segmentation parole/musique pour la transcription automatique de parole continue ` THESE pr´esent´ee et soutenue publiquement le 13 Novembre 2007 pour l’obtention du...
En exploitant les données du corpus de la parole continue, nous avons proposé, dans cette thèse, deux algorithmes de segmentation automatique de la parole continue et dé- veloppé
