Ministère de l’Enseignement Supérieur et de la Recherche Scientifique
Université Ferhat Abbas-Sétif
Algérie
________________________________________________________
THÈSE
Présentée à la Faculté de Technologie
Département d’Électronique
Pour l’obtention du diplôme de
Doctorat en Sciences
Spécialité : Électronique
Par
Mr. Hacine Gharbi Abdenour
Thème
Sélection de paramètres acoustiques pertinents pour la
reconnaissance de la parole
Soutenue le 09 Décembre 2012 devant le jury composé de :
Mr. Ameur Zagadi Prof. à l’Université Ferhat Abbas, Sétif Président du jury
Mr. Tayeb Mohamadi Prof. à l’Université Ferhat Abbas, Sétif Rapporteur
Mr. Rachid Harba Prof. à l’Université d'Orléans, France Co-Rapporteur
Mr. Olivier Alata Prof. à l’Université de Saint-Etienne, France Examinateur
Mr. Mohamed Debyeche Prof. à l’Université USTHB, Alger Examinateur
Mr. Philippe Ravier M.C (HDR). à l’Université d'Orléans, France Examinateur
Résumé
L’objectif de cette thèse est de proposer des solutions et améliorations de performance à certains problèmes de sélection des paramètres acoustiques pertinents dans le cadre de la reconnaissance de la parole. Ainsi, notre première contribution consiste à proposer une nouvelle méthode de sélection de paramètres pertinents fondée sur un développement exact de la redondance entre une caractéristique et les caractéristiques précédemment sélectionnées par un algorithme de recherche séquentielle ascendante. Le problème de l’estimation des densités de probabilités d’ordre supérieur est résolu par la troncature du développement théorique de cette redondance à des ordres acceptables. En outre, nous avons proposé un critère d’arrêt qui permet de fixer le nombre de caractéristiques sélectionnées en fonction de l’information mutuelle approximée à l’itération j de l’algorithme de recherche.
Cependant l’estimation de l’information mutuelle est difficile puisque sa définition dépend des densités de probabilités des variables (paramètres) dans lesquelles le type de ces distributions est inconnu et leurs estimations sont effectuées sur un ensemble d’échantillons finis. Une approche pour l’estimation de ces distributions est basée sur la méthode de l’histogramme. Cette méthode exige un bon choix du nombre de bins (cellules de l’histogramme). Ainsi, on a proposé également une nouvelle formule de calcul du nombre de bins permettant de minimiser le biais de l’estimateur de l’entropie et de l’information mutuelle. Ce nouvel estimateur a été validé sur des données simulées et des données de parole. Plus particulièrement cet estimateur a été appliqué dans la sélection des paramètres MFCC statiques et dynamiques les plus pertinents pour une tâche de reconnaissance des mots connectés de la base Aurora2.
ص
ن فد ا وھ ر ا هذھ لو حار ا و ءاد ا ت ض ل! " ر #ا ا ز تا و% ا ا ر طإ م)! ا * + فر ا . ھ * و ا ن ! , رط حار ا ةد د. / ر # تاز 0 , ا ا * + 1 ر ل ق د رار! ن ةز و ا ز # ا تا ةر , زراو# ط او يد+ % ث . !" ر د, 5! / /ا ط او ل ا .رد ا ن ت ع ط ا ا 7 % رظ ا اذ رار! ا ت .رد * إ و , . ك ذ * إ 1: ر ا ، ار ف و < يذ ا د د دد+ ا ز ةر # ا تا /د و ا ا د ر, ا رار! ا (j) ث ا زراو# . نأ ر > ر د, و ا د ا ب % ، ن/ @ ر * + د لاود 5! /ا / ت ا +و فور ر > و A ءار.إ م تار د, ا * + ن +و . ت + ةدود . , رط ر د, هذھ لاود ا د * + جرد ا ا . ذھ ه ا , رط ب ط اد . ار # دد ةد +أ جرد ا ا . ، و C ر ا ةد د. 7 % ب دد+ يذ ا ةد + ا ل , < ن ر د, Dط# ا /ا و و و ا د ا . م د!D ا ن ا اذھ ر د, و * + د ا ت ط ! ة ت ط و م)! ا . صو%# ا A.و * + ق ط م د اذھ ا ر د, ر #ا ط0 و ا MFCC ا ! د او ! ر5! ا ا * + فر ا % ا م ر ا ةد+ , ا ت Aurora2 .Abstract
The objective of this thesis is to propose solutions and performance improvements to certain problems of relevant acoustic features selection in the framework of the speech recognition. Thus, our first contribution consists in proposing a new method of relevant feature selection based on an exact development of the redundancy between a feature and the feature previously selected using Forward search algorithm. The estimation problem of the higher order probability densities is solved by the truncation of the theoretical development of this redundancy up to acceptable orders. Moreover, we proposed a stopping criterion which allows fixing the number of features selected according to the mutual information approximated at the iteration J of the search algorithm.
However, the mutual information estimation is difficult since its definition depends on the probability densities of the variables (features) in which the type of these distributions is unknown and their estimates are carried out on a finite sample set. An approach for the estimate of these distributions is based on the histogram method. This method requires a good choice of the bin number (cells of the histogram). Thus, we also proposed a new formula of computation of bin number that allows minimizing the estimator bias of the entropy and mutual information. This new estimator was validated on simulated data and speech data. More particularly, this estimator was applied in the selection of the static and dynamic MFCC parameters that were the most relevant for a recognition task of the connected words of the Aurora2 base.
___________________________________________________________________________ Mots-clés: reconnaissance de la parole, paramètres acoustiques, coefficients MFCC, Modèles de
Markov Cachés (MMC), entropie, information mutuelle, histogramme, nombre de bins, sélection des paramètres, pertinence, redondance, biais.
Table des matières
Résumé...i
Table des matières...ii
INTRODUCTION GENERALE...1
CHAPITRE I DESCRIPTION D’UN SYSTEME DE RECONNAISSANCE DE LA PAROLE ... 5
I.1 Introduction ... 5
I.2 Application de la reconnaissance de la parole ... 5
I.3 Difficultés de la reconnaissance de la parole ... 6
I.3.1 La redondance ... 7
I.3.2 Variabilité ... 7
I.3.3 Continuité et coarticulation ... 7
I.3.4 Conditions d’enregistrement ... 8
I.4 Approches de la reconnaissance de la parole ... 8
I.4.1 Approche globale ... 9
I.4.2 Approche analytique ... 10
I.4.3 Approche statistique ... 10
I.5 système de RAP fondé sur les modèles HMM ... 12
I.5.1 Analyse acoustique ... 13
I.5.2 Les modèles acoustiques HMM ... 19
I.6 Conclusion ... 25
CHAPITRE II REDUCTION DE LA DIMENSIONNALITE ... 27
II.1 Position du problème ... 27
II.2 Sélection de caractéristiques ... 29
II.2.1 Etat de l’art ... 29
II.2.2 Procédure de recherche ... 30
II.2.3 Évaluation des caractéristiques ... 31
II.2.4 Critère d’arrêt ... 33
II.2.5 Procédure de validation ... 34
II.3 Les bases de la théorie de l’information ... 34
II.3.1 L’entropie de Shannon ... 34
II.3.2 L’entropie relative ... 36
II.3.3 L’information mutuelle ... 37
II.3.4 L’Information Mutuelle Multivariée (IMV) ... 39
II.4 Méthodes de sélection fondées sur l’information mutuelle ... 41
II.4.1 Méthode proposée (TMI) ... 46
II.5 Conclusion ... 48
CHAPITRE III ESTIMATION DE L’ENTROPIE ET DE L’INFORMATION MUTUELLE ... 50
III.1 Introduction ... 50
III.2 Estimation de l’entropie et de l’information mutuelle des variables continues ... 51
III.3 Estimation de l’entropie et de l'IM par la méthode d’histogramme ... 52
III.3.1 Estimation de l’entropie par la méthode d’histogramme ... 53
III.3.2 Estimation de l’information mutuelle par la méthode d’histogramme ... 54
III.3.3 Formules du choix de nombre de bins ... 55
III.4 Méthodes ... 56
III.4.1 Nouvelle estimation de l’entropie ... 56
III.4.2 Nouvelle estimation de l’information mutuelle ... 58
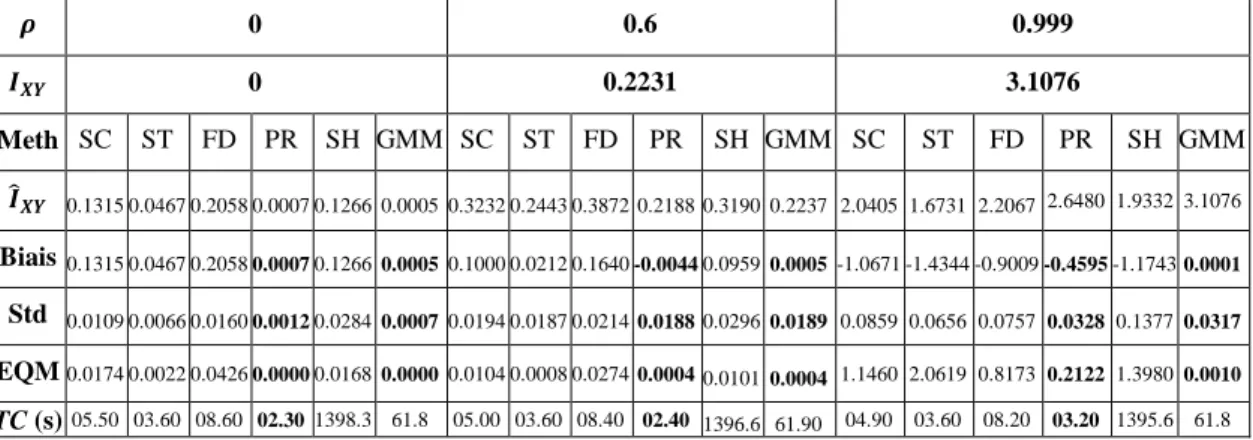
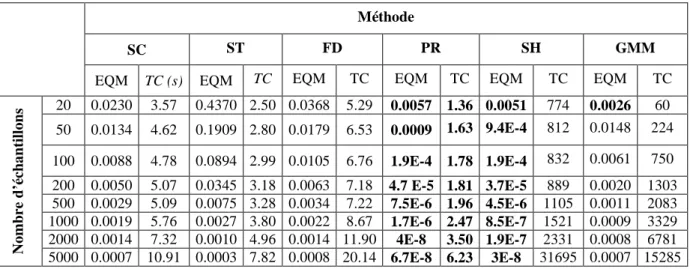
III.5 Simulations et résultats ... 61
III.5.1 Estimation de l’entropie et de l'IM des variables simulées ... 61
III.5.2 Sélection des variables pertinentes appliquées sur des données simulées ... 71
CHAPITRE IV SELECTION DES PARAMETRES ACOUSTIQUES POUR LA RECONNAISSANCE DE LA
PAROLE ... 84
IV.1 Introduction ... 84
IV.2 Résultats expérimentaux du système de référence ... 85
IV.2.1 Base de données AURORA2 ... 85
IV.2.2 Système de référence sous plate forme HTK ... 87
IV.3 Sélection des paramètres acoustiques ... 90
IV.3.1 Sélection des paramètres MFCC ... 92
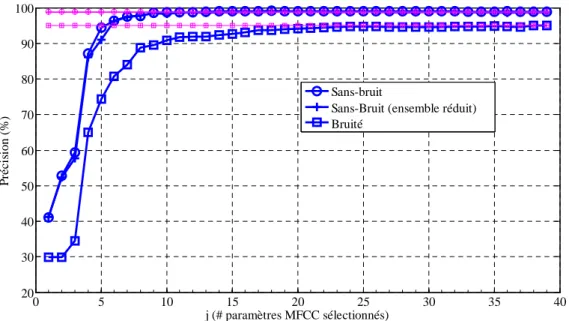
IV.3.2 Estimation du nombre optimal de paramètres pertinents ... 95
IV.4 Conclusion ... 101
Conclusion et perspectives...103
Annexe A : Analyse par prédiction linéaire...105
Annexe B : Mise en œuvre d’un système de reconnaissance des mots connectés sous HTK 107 Liste des figures………..113
Liste des t.ableaux…..……….115
Liste des acronymes…..………..116
INTRODUCTION GENERALE
La parole comme un moyen de dialogue homme-machine efficace, a donné naissance à plusieurs travaux de recherche dans le domaine de la Reconnaissance Automatique de la Parole (RAP). Un système de RAP est un système qui a la capacité de détecter à partir du signal vocal la parole et de l’analyser dans le but de transcrire ce signal en une chaîne de mots ou phonèmes représentant ce que la personne a prononcé. Ces propriétés offrent une grande variété d’applications comme l’aide aux handicapés, la messagerie vocale, les services vocaux dans les téléphones portables (”name dialing”, numérotation automatique, reconnaissance de commandes vocales), la production de documents écrits par dictée, etc.
Cependant le signal de parole est l’un des signaux les plus complexes à caractériser ce qui rend difficile la tâche d’un système RAP. Cette complexité du signal de parole provient de la combinaison de plusieurs facteurs, la redondance du signal acoustique, la grande variabilité inter et intra-locuteur, les effets de la coarticulation en parole continue et les conditions d’enregistrement. Pour surmonter ces difficultés, de nombreuses méthodes et modèles mathématiques ont été développés, parmi lesquels on peut citer : la comparaison dynamique, les réseaux de neurones, les machines à vecteurs supports (Support Vector Machine SVM), les modèles de Markov stochastiques et en particulier les modèles de Markov cachés (Hidden Markov Models HMM).
Ces méthodes et modèles travaillent à partir d’une information extraite du signal de parole considérée comme pertinente. Cette extraction est effectuée par une analyse acoustique qui conduit à rassembler cette information sous le terme de vecteur de paramètres acoustiques dont la dimension et la nature sont déterminants pour accéder à de bonnes performances des systèmes de RAP. Les différents types de paramètres acoustiques couramment cités dans la littérature sont les coefficients : LPC, LSF, MSG, LPCC, LFCC, PLP, MFCC, etc. Généralement, les coefficients MFCC sont les paramètres acoustiques (caractéristiques) les plus utilisés dans les systèmes RAP [1].
Cependant, des travaux de recherche ont permis d’étudier l’amélioration des performances des systèmes de RAP en combinant les coefficients MFCC avec d’autres types de paramètres acoustiques tels que : LPCC, PLP, énergie, ondelettes [2] [3]. De plus d’autres travaux ont montré une amélioration de performances en intégrant les coefficients différentiels de premier ordre (appelés aussi delta ∆) et deuxième ordre (appelés delta-delta ∆∆) issus des coefficients
MFCC initiaux (statiques) [4] [5]. Ces coefficients différentiels référés comme des paramètres dynamiques fournissent une information utile sur la trajectoire temporelle du signal de parole.
Cette démarche a cependant pour effet de doubler ou tripler la dimension des vecteurs acoustiques [6] [7]. On peut penser qu'accroître le nombre de paramètres pertinents pourrait améliorer la précision de la reconnaissance. Dans les faits, cette idée se heurte à un problème connu sous le terme de "malédiction de la dimensionnalité" [8]. En effet, l'augmentation du nombre de paramètres se fait au prix d'un accroissement exponentiel du nombre d'échantillons constituant la base de données utilisée pour l'apprentissage du système de reconnaissance. En conséquence, lorsque la base de données est de taille finie et figée, les performances viennent même à se détériorer avec l'accroissement du nombre de paramètres. De plus, cette augmentation exige une quantité de ressources importante qui n’est pas en adéquation avec celle disponible dans les systèmes de RAP embarqués sur les téléphones (notamment reconnaissance des mots isolés ou connectés) [7].
Il est donc nécessaire, si l'on veut concevoir un système acceptable en termes de précision, coût de calcul, et d'encombrement mémoire, de limiter le nombre de paramètres en sélectionnant les plus pertinents susceptibles de modéliser le mieux possible les données pour la tâche de reconnaissance. Il faut donc être capable, pour résoudre ce problème, de trouver les caractéristiques les plus informatives possibles pour la RAP tout en limitant leur nombre. Les travaux de recherche peuvent alors s’orienter selon deux axes :
• Un axe de recherche, dans un ensemble donné de paramètres, des paramètres les plus pertinents et de leur nombre optimal, par l'application d'un critère de sélection des paramètres les plus pertinents.
• Un axe de recherche d’une méthode de transformation d’un ensemble de paramètres acoustiques en un autre ensemble contenant un maximum d’information puisque l'algorithme développé dans le premier axe se charge ensuite de ne conserver qu'un nombre limité de paramètres acoustiques.
L’objectif de cette thèse est de proposer des solutions et améliorations de performance à certains problèmes de sélection des paramètres pertinents dans le cadre de la reconnaissance de la parole (premier point précédent). Les résultats obtenus permettent ainsi de travailler sur de nouvelles méthodes de transformation de paramètres (deuxième point précédent, cependant non traité dans cette thèse).
Sur le plan théorique, on s’est intéressé aux aspects théoriques de l’information mutuelle qui est un outil issu de la théorie de l’information. Cet outil permet de renseigner sur la pertinence qu'a une séquence de données à réaliser une tâche de classification spécifiée. L’idée est d’appliquer cet outil pour la sélection des paramètres pertinents du signal de parole.
Ainsi, notre première contribution consiste à proposer une nouvelle méthode de sélection de paramètres acoustiques pertinents fondée sur un développement exact de la redondance entre une caractéristique et les caractéristiques précédemment sélectionnées par un algorithme de recherche séquentielle ascendante (algorithme "greedy forward" dit glouton direct). Cette redondance se fonde sur l’estimation des densités de probabilités jointes dont le coût de calcul augmente avec la dimension. Ce problème est résolu par la troncature du développement théorique de cette redondance à des ordres acceptables. De plus, un critère d’arrêt de la procédure de sélection permet de fixer le nombre de caractéristiques sélectionnées en fonction de l’information mutuelle approximée à une itération j. Nous avons validé cette approche sur les paramètres MFCC extraits des données parole de la base Aurora2 utilisée dans la RAP. Cette contribution s’est traduite par un article de conférence [9].
Cependant l’estimation de l’information mutuelle est difficile puisque sa définition dépend des densités de probabilité des variables (paramètres) dans lesquelles le type de ces distributions est inconnu et leurs estimations sont effectuées sur un ensemble d’échantillons finis. Une approche pour l’estimation de ces distributions est fondée sur la méthode de l’histogramme. Cette méthode exige un bon choix du nombre de bins (cellules de l’histogramme). Ainsi, nous avons proposé une nouvelle formule de calcul du nombre de bins permettant de minimiser le biais de l’estimateur de l’entropie et de l’information mutuelle.
Ce nouvel estimateur a été validé sur des données simulées et des données de parole. Plus particulièrement cet estimateur a été appliqué dans la sélection des paramètres MFCC statiques et dynamiques les plus pertinents pour une tâche de reconnaissance des mots connectés de la base Aurora2. Ce travail a été concrétisé par la publication d’un article dans la revue « Pattern Recognition Letters » [10]. Ensuite cet estimateur a été appliqué dans la sélection des paramètres acoustiques de différents types (MFCC, PLP, LPCC).
Le manuscrit contient quatre chapitres :
Le premier chapitre donne des généralités sur les systèmes de reconnaissance automatique de la parole et plus particulièrement ceux basés sur les modèles HMM. Les différentes étapes fonctionnelles de tels systèmes sont décrites comme : l’analyse acoustique, l’apprentissage des modèles HMM, le décodage acoustique.
Dans le deuxième chapitre, les différentes méthodes de réduction de la dimensionnalité sont présentées. Les techniques de sélection des paramètres pertinents fondées sur le critère de maximisation de l’information mutuelle sont détaillées.
Le chapitre 3 qui est le cœur de la thèse présente nos contributions théoriques sur la sélection des paramètres pertinents ainsi que sur l’estimation de l’information mutuelle. Des résultats de plusieurs expériences de simulations sont exposés à la fin du chapitre.
Dans le chapitre 4, une application du nouvel estimateur de l’information mutuelle dans la sélection des paramètres MFCC statiques et dynamiques est présentée. Les performances des paramètres sélectionnés sont évaluées par la mesure de la précision d’un système de référence pour la reconnaissance des mots connectés de la base Aurora2. Ainsi une grande partie de ce chapitre est consacrée à la description du système de référence et la base de données parole Aurora2. Les résultats et leurs interprétations sont exposés à la fin du chapitre.
Enfin une conclusion générale résume les différents travaux effectués ainsi que les perspectives qui permettront d’élargir et de poursuivre l’étude menée dans cette thèse.
CHAPITRE I
DESCRIPTION D’UN SYSTEME DE RECONNAISSANCE DE
LA PAROLE
I.1 I
NTRODUCTIONLa parole est l'un des moyens les plus directs d’échange de l’information, utilisés par l’homme. Cet avantage a donné naissance à plusieurs travaux de recherche dont l’objectif est la conception des systèmes permettant de reconnaître la séquence des mots parlés.
Un système de Reconnaissance Automatique de la Parole (RAP) est un système qui a la capacité de détecter la parole et de l’analyser dans le but de générer une chaîne de mots ou phonèmes représentant ce que la personne a prononcé. Cette analyse se fonde sur l’extraction des paramètres descriptifs de la parole. Cependant le signal parole ne contient pas seulement des informations sur le texte parlé mais aussi des informations sur le locuteur, la langue, les émotions dont leur extraction n’est pas l’objectif de la RAP. Cette thèse s’intéresse à une étape primordiale de la RAP, en l'occurrence la sélection des paramètres descriptifs pertinents pour la tâche de reconnaissance des mots parlés. Avant d’aborder cette étape, nous allons décrire dans ce chapitre les principes généraux et les problèmes de la RAP, ainsi que les différentes étapes constituant un tel système (le lecteur trouvera plus de détails dans [11] [12] [1] [13].
I.2 A
PPLICATION DE LA RECONNAISSANCE DE LA PAROLELes avantages que l’on attend de la reconnaissance de la parole sont multiples. Elle libère complètement l’usage de la vue et des mains (contrairement à l’écran et au clavier), et laisse l’utilisateur libre de ses mouvements. La vitesse de transmission des informations est supérieure, dans la RAP à celle que permet l’usage du clavier. Enfin tout le monde ou presque sait parler, alors que peu de gens sont à l’abri des fautes de frappe et d’orthographe.
Ces avantages sont à l'origine d’une grande variété d’applications comme :
• L’aide aux handicapés.
• La messagerie.
• L’avionique.
• La commande de machines ou de robots.
• L’accès à distance : téléphone, internet.
• La dictée vocale.
Toutes ces applications bénéficient de l’évolution technologique qui se traduit par l’apparition de composants intégrés spécialisés (en traitement du signal pour la programmation dynamique) et du développement des techniques et des méthodes algorithmiques de plus en plus performantes.
Enfin l’insertion d’un système RAP dans son environnement réel d’utilisation dépend de son contexte d’application et de ses conditions d’utilisation ce qui peut vite rendre le dispositif très complexe. Un système RAP peut être décrit selon quatre grands axes graduant cette complexité :
La dépendance du locuteur (système optimisé pour un locuteur bien particulier) ou l'indépendance du locuteur (système pouvant reconnaître n'importe quel locuteur).
Le mode d’élocution : mots isolés, mots connectés, mots-clés, parole continue lue ou parole continue spontanée.
La complexité du langage autorisé : taille du vocabulaire et difficulté de la grammaire.
La robustesse aux conditions d’enregistrement : systèmes nécessitant de la parole de bonne qualité ou fonctionnement en milieu bruité.
Tout système correspond à un compromis entre ces axes, choisi en fonction du but à atteindre. Les systèmes réalisés de la RAP sont conçus pour des applications spécifiques. Cela conduit à une restriction de l’univers du dialogue homme-machine. En effet, la conception de systèmes capables de comprendre la langue orale dans son intégralité est pour l’instant beaucoup trop complexe.
I.3 D
IFFICULTES DE LA RECONNAISSANCE DE LA PAROLELe signal de parole est l’un des signaux les plus complexes à caractériser et analyser car sujet à une grande variabilité. Cette complexité est liée à la production du signal de parole, ainsi qu’à l’aspect technologique.
Le signal de parole varie non seulement avec les sons prononcés, mais également avec le locuteur, l’âge, les émotions, la santé, l’environnement.
De plus, la mesure du signal de parole est fortement influencée par la fonction de transfert du système de reconnaissance (les appareils d’acquisition et de transmission), ainsi que par le milieu ambiant.
principalement la redondance du signal acoustique, la grande variabilité intra et inter-locuteurs, les effets de la coarticulation en parole continue, ainsi que les conditions d’enregistrement.
I.3.1 LA REDONDANCE
Le signal vocal présente un caractère redondant. Il contient plusieurs types d’information : les sons, la syntaxe et la sémantique de la phrase, l’identité du locuteur et son état émotionnel. Bien que cette redondance assure une certaine résistance du message au bruit, elle rend l'extraction des informations pertinentes pour la RAP plus délicate de part la multimodalité des sources d'information.
I.3.2 VARIABILITE
Le signal vocal de deux prononciations à contenu phonétique égal est différent pour un même locuteur (variabilité intralocuteur) ou pour des locuteurs différents (variabilité interlocuteur).
En effet, lorsque la même personne prononce deux fois le même énoncé, on constate des variations sensibles sur le signal vocal causées par :
• L’état physique, par exemple, la fatigue ou le rhume.
• Les conditions psychologiques, comme le stress.
• Les émotions du locuteur.
• Le rythme lié à la durée des phonèmes (façon dont s’exprime le locuteur) et l’amplitude (voix normale, voix chuchotée, voix criée).
Cependant la variabilité interlocuteur est a priori la plus importante. Elle s'explique par :
• Les différences physiologiques entre locuteurs.
• Les habitudes acquises en fonction du milieu social et géographique comme les accents régionaux.
Cette variabilité rend très difficile la définition d’invariants et complique la tâche de reconnaissance. Ainsi, il faut pouvoir séparer ce qui caractérise les phonèmes, de l’aspect particulier à chaque locuteur.
I.3.3 CONTINUITE ET COARTICULATION
La production d’un son est fortement influencée par le son qui le précède et qui le suit en raison de l’anticipation du geste articulatoire. La localisation correcte d’un segment de parole isolé de son contexte est parfois impossible. Évidement la reconnaissance des mots isolés bien séparés par un silence est plus facile que la reconnaissance des mots connectés. En effet, dans
ce dernier cas, non seulement la frontière entre mots n’est plus connue mais, de plus, les mots deviennent fortement articulés.
I.3.4 CONDITIONS D’ENREGISTREMENT
L’enregistrement du signal de parole dans de mauvaises conditions rend difficile l’extraction des informations pertinentes indispensables pour la reconnaissance des mots contenus dans ce signal. En effet, les perturbations apportées par le microphone (selon le type, la distance, l’orientation) et l’environnement (bruit, réverbération) compliquent beaucoup le problème de la reconnaissance.
Pour illustrer l'ensemble de ces difficultés, un système de RAP doit, en définitive, être capable de décider "qu’un [a] prononcé par un adulte masculin est plus proche d’un [a] prononcé par un enfant, dans un mot différent, dans un environnement différent et avec un autre microphone, que d’un [o] prononcé dans la même phrase par le même adulte masculin" [12].
I.4 A
PPROCHES DE LA RECONNAISSANCE DE LA PAROLELe principe général d’un système de RAP peut être décrit par la figure (I.1) :
La suite de mots prononcés M est convertie en un signal acoustique S par l’appareil phonatoire. Ensuite le signal acoustique est transformé en une séquence de vecteurs acoustiques ou d’observations O (chaque vecteur est un ensemble de paramètres acoustiques). Finalement le module de décodage consiste à associer à la séquence d’observations O une séquence de mots reconnus M’.
Un système RAP transcrit la séquence d’observations O en une séquence de mots M’ en se basant sur le module d’analyse acoustique et celui de décodage.
Le problème de la RAP est généralement abordé selon deux approches que l’on peut opposer du point de vue de la démarche : l’approche globale et l’approche analytique [6]. La première considère un mot où une phrase en tant que forme globale à identifier en le comparant avec des références enregistrées. La deuxième, utilisée pour la parole continue,
Séquence d’observations O Message M suite de mots Production du signal parole Signal acoustique S Acquisition du signal Décodage Message M’
suite de mots reconnus
Figure.I.1 : Principe de la reconnaissance de la parole
Analyse acoustique
cherche à analyser une phrase en une chaîne d’unités élémentaires en procédant à un décodage acoustico-phonétique exploité par des modules de niveau linguistique.
Cependant, les systèmes RAP en majorité utilisent des méthodes statistiques à base de modèles de Markov. Ces méthodes sont hybrides (globale et analytique).
I.4.1 APPROCHE GLOBALE
L’approche globale considère l’énoncé entier comme une seule unité indépendamment de la langue. Elle consiste ainsi à abstraire totalement les phénomènes linguistiques et ne retenir que l’aspect acoustique de la parole. Cette approche est destinée généralement pour la reconnaissance des mots isolés séparés par au moins 200 ms (voir figure I.2) ou enchaînés, appartenant à des vocabulaires réduits.
Dans les systèmes de reconnaissance globale, une phase d’apprentissage est nécessaire, pendant laquelle l’utilisateur prononce la liste des mots du vocabulaire de son application. Pour chacun des mots prononcés, une analyse acoustique est effectuée permettant d’extraire les informations pertinentes sous forme de vecteurs de paramètres acoustiques. Le résultat est stocké ensuite en mémoire. Donc, les méthodes globales mettent en jeu une ou plusieurs images de références acoustiques (R1,...,Rn), a priori pour chaque mot.
Lors de la phase de reconnaissance, lorsque l’utilisateur prononce un mot T, la même analyse est effectuée : l’image acoustique du mot à reconnaître est alors comparée à toutes celles des mots de référence du vocabulaire au sens d’un indice de ressemblance D :
= max ( , ) (I. 1) Le mot ressemblant le plus au mot prononcé est alors reconnu.
Généralement, on rencontre deux problèmes : le premier est relatif à la durée d’un mot qui est variable d’une prononciation à l’autre, et le deuxième aux déformations qui ne sont pas linéaires en fonction du temps. Ces problèmes peuvent être résolus en appliquant un algorithme classique de la programmation dynamique appelé alignement temporel dynamique (Dynamic Time Warping DTW ). Ce type d’algorithme permet sous certaines conditions d’obtenir une solution optimale à un problème de minimisation d’un certain critère d’erreur
Analyseur acoustique T t1,t2,...,ti Comparaison D(T, Rr,) Dictionnaire (R1,R2,...,Rn) Réponse
Figure.I.2 : Reconnaissance de mots isolés Signal
sans devoir considérer toutes les solutions possibles. Dans le cas de la RAP, cet algorithme consiste à chercher le meilleur alignement temporel qui minimise la distance entre la représentation d’un mot de référence et la représentation d’un mot inconnu.
Dans le cas de grand vocabulaire ou de la parole naturelle continue, cette approche devient insuffisante et il est alors nécessaire d’adopter une nouvelle approche.
I.4.2 APPROCHE ANALYTIQUE
L’approche analytique cherche à trouver des solutions au problème de la reconnaissance de la parole continue ainsi qu’au problème du traitement de grands vocabulaires. Cette approche consiste à segmenter le signal vocal en constituants élémentaires (mot, phonème, biphone, triphone, syllabe), puis à identifier ces derniers, et enfin à reconstituer la phrase prononcée par étapes successives en exploitant des modules d'ordre linguistique (niveaux lexical, syntaxique ou sémantique). Ces constituants élémentaires peuvent être des phonèmes, des biphones, triphones ou des syllabes. Le processus de la reconnaissance de la parole dans une telle méthode peut être décomposé en deux opérations :
1. Représentation du message (signal vocal) sous la forme d’une suite de segments de parole, c’est la segmentation.
2. Interprétation des segments trouvés en termes d’unités phonétiques, c’est l’identification.
I.4.3 APPROCHE STATISTIQUE
L’approche statistique se fonde sur une formalisation statistique simple issue de la théorie de l'information permettant de décomposer le problème de la reconnaissance de la parole continue (figure I.3) [1].
Cette approche est construite sur le principe de fonctionnement des méthodes globales (avec phase d'apprentissage et de reconnaissance) mais avec l’exploitation des niveaux linguistiques. Ainsi une analyse acoustique est nécessaire pour convertir tout signal vocal en une suite de vecteurs acoustiques. Ces vecteurs sont considérés comme des observations dans la phase d’apprentissage des modèles statistiques et dans la phase de reconnaissance qui effectue une classification de chaque observation (par un index d’état dans le cas de la modélisation Markovienne).
On considère O une suite d'observations acoustiques résultant d’une analyse acoustique d’un signal de parole représentant une séquence de mots prononcés M. L'approche statistique consiste à chercher la séquence de mots la plus probable parmi toutes les séquences de mots possibles EM sachant les observations O. Ainsi, la séquence de mots optimale est celle qui maximise la probabilité a posteriori ( / ).
= argmax ∈"# ( / ) (I. 2)
Selon la règle de Bayes, l’équation (I.2) peut être écrite comme suit : = argmax
∈"#
( / ) ( )
( ) (I. 3) Puisque P(O) ne dépend pas de M, alors l’équation (I.3) est équivalente à :
= argmax
∈"# ( / ) ( ) (I. 4)
où:
• ( / ) est la probabilité d’observer la séquence des vecteurs acoustiques O étant
donnée la suite de mots M. Cette probabilité appelée vraisemblance est donnée par un modèle acoustique (figure I.3).
• ( ), la probabilité a priori d’observer la séquence de mots M indépendamment de
la séquence d’observations O, est estimée par un modèle de langage (figure I.3). Ce modèle exige des contraintes sur la syntaxe de la séquence des mots.
Les systèmes actuels de RAP continue exploitent la modélisation statistique du signal de parole par des Modèles de Markov Cachés HMM. La modélisation Markovienne tient compte non seulement de la non linéarité temporelle du signal de parole mais aussi de sa variabilité acoustique.
D’autres techniques ont été également développées pour la réalisation des systèmes RAP, parmi lesquelles, on peut citer : les réseaux de neurones, les machines à vecteurs supports (Support Vector Machine SVM), les réseaux bayésiens, les modèles hybrides obtenus par combinaison des réseaux de neurones et des modèles HMM [1].
P(O/M) P(M) Signal parole Modèle de langage Modèles acoustique Décodage: Recherche de argmax ∈"# ( / ) ( ) Analyse acoustique O=o1,o2,…,oT
Suite de mots reconnus
Transcription orthographique Corpus texte Apprentissage Décodage (Reconnaissance) Corpus de parole (signal) Analyse acoustique Apprentissage HMM Dictionnaire (lexique) Modèles acoustiques Analyse acoustique Décodeur Echantillons de parole Modèle De langage Transcription orthographique
Figure.I.4 : Synoptique du système de reconnaissance de la parole incluant la procédure d’apprentissage et le décodage
Dans notre travail, nous nous sommes intéressés aux systèmes RAP à base des modèles HMM. Les différents éléments constituant ces systèmes sont décrits dans la section suivante.
I.5
SYSTEME DERAP
FONDE SUR LES MODELESHMM
L’hypothèse fondamentale des modèles HMM est que le signal vocal peut être caractérisé par un processus aléatoire paramétrique dont ses paramètres peuvent être déterminés avec précision par une méthode bien définie. La méthode HMM fournit une manière de reconnaître la parole, naturelle et très fiable pour une large gamme d’applications et intègre facilement les niveaux lexical et syntaxique [13].
Les différentes étapes d’un système de reconnaissance de la parole fondé sur les HMM sont représentées sur la figure (I.4). La ligne pointillée marque une séparation entre le processus d’apprentissage et le processus de reconnaissance. Les principaux composants utilisés pour le développement d’un tel système de reconnaissance sont les principales sources de connaissances (corpus de parole, corpus de texte, et lexiques de prononciations), le dispositif de paramétrisation acoustique (analyse acoustique), les modèles acoustiques et de langage dont les paramètres sont estimés durant la phase d’apprentissage, et le décodeur qui utilise ces modèles pour reconnaître la séquence de mots prononcés.
Les modèles acoustiques représentent les éléments à reconnaître : mots, ou unités phonétiques. Ces modèles sont usuellement développés à partir de grands corpus de données acoustiques et de textes. Ainsi, l’entraînement de ces modèles exige une définition des unités lexicales de base utilisées et un dictionnaire de prononciation décrivant la liste des mots qui pourront être reconnus.
Le modèle de langage fournit les informations syntaxiques pour la reconnaissance de la séquence de mots la plus probable.
Au centre de ce synoptique se trouve l’apprentissage par HMM qui est l’une des approches les plus utilisées dans les systèmes de RAP.
Lors de la reconnaissance, après l’analyse acoustique, un décodage est effectué et le système de reconnaissance fournit en sortie la séquence de mots la plus probable étant donné le modèle de langage et les modèles HMM.
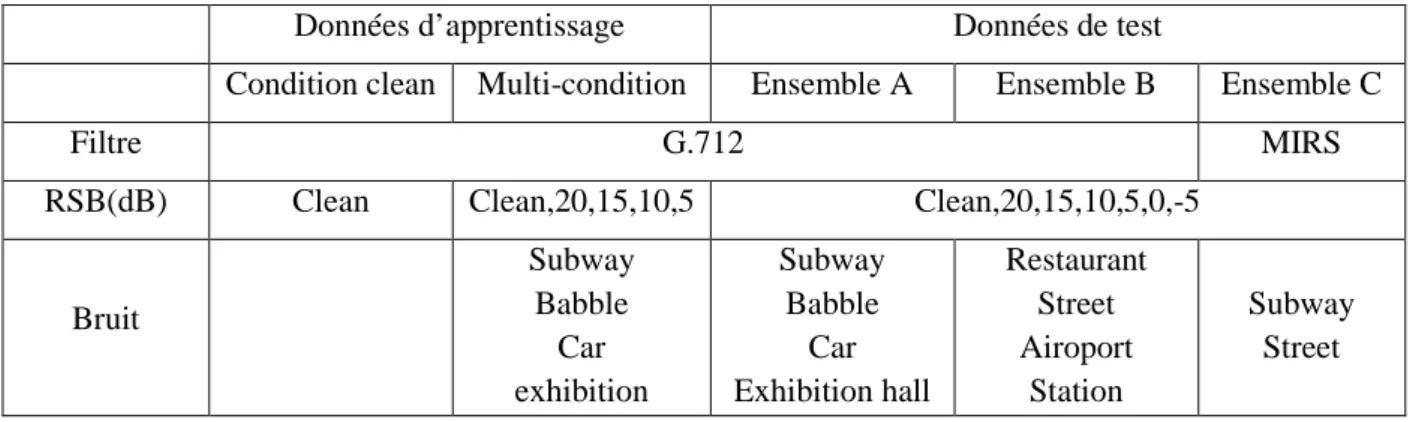
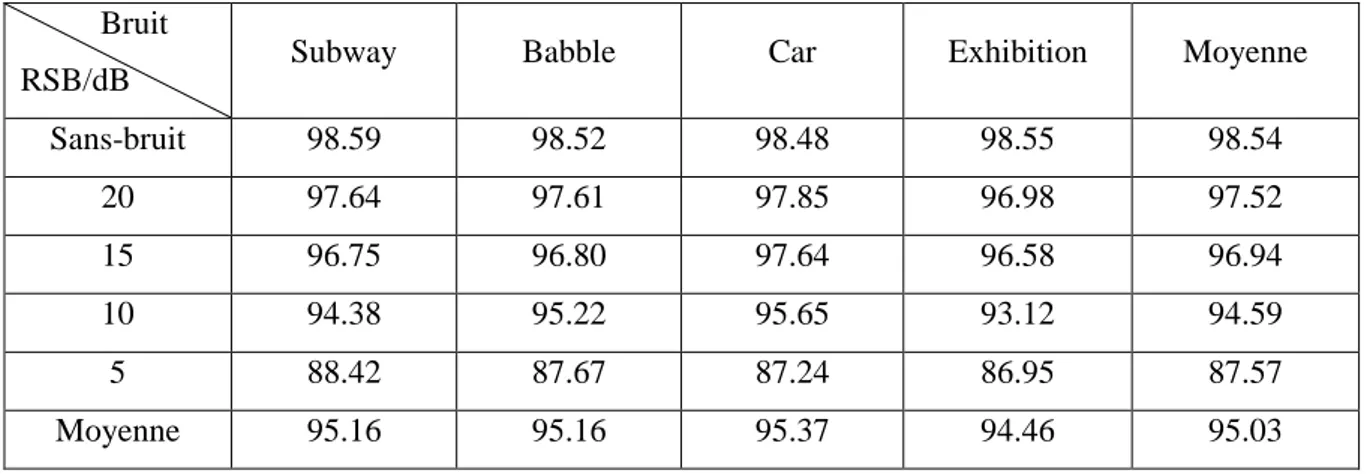
Dans notre travail, nous avons proposé le système de reconnaissance des chiffres présenté dans [14] pour comparer les performances des paramètres acoustiques utilisés originalement dans ce système avec celles des paramètres acoustiques fournis par un algorithme de sélection. Ce système de référence est implémenté sous plate-forme HTK (Hidden Markov Model Toolkit, ou "boîte à outils de modèles de Markov cachés") [15] et évalué sur la base de données Aurora2 distribuée par ELRA [16]. Cette base conçue pour évaluer les performances des systèmes RAP dans différentes conditions de bruit, est utilisée pour sélectionner des paramètres acoustiques pertinents dans deux environnements: bruité et non bruité. La description détaillée de ce système de référence ainsi que ses performances sur la base Aurora2 seront abordés dans le chapitre IV.
Dans les sous-sections suivantes, nous détaillons brièvement l’étape d’analyse acoustique ainsi que les modèles HMM et leur mise en œuvre dans les systèmes RAP en utilisant la boîte à outils HTK. Au cours de ces étapes on introduit les grandes lignes de nos contributions, ainsi que le schéma synoptique des différentes étapes de notre système de reconnaissance.
I.5.1 ANALYSE ACOUSTIQUE
Le signal vocal transporte plusieurs informations comme le message linguistique, l’identité du locuteur, ainsi que ses émotions, la langue adoptée, etc. Un système RAP consiste à récupérer seulement le message linguistique indépendamment des autres informations. Dans un tel système, l’analyse acoustique consiste à extraire du signal vocal un ensemble de paramètres pertinents dans le but de réduire la redondance du signal vocal pour une tâche de reconnaissance de la parole. Le nombre de ces paramètres doit rester raisonnable, afin d’éviter la nécessité d’un grand espace mémoire ce qui accroît le coût de calcul dans le module de décodage. Ces paramètres doivent être discriminants en rendant les sons de base facilement séparables. Ils doivent être robustes au bruit.
Le calcul des paramètres acoustiques est réalisé par une chaîne de prétraitement selon les étapes suivantes (figure I.5) :
1. Filtrage et échantillonnage : le signal vocal est filtré puis échantillonné à une fréquence donnée. Cette fréquence est typiquement de 8 kHz pour la parole de qualité téléphonique et de 16 à 20 kHz pour la parole de bonne qualité [6].
2. Préaccentuation : le signal échantillonné sest ensuite pré-accentué afin de relever les hautes fréquences qui sont moins énergétiques que les basses fréquences. Cette étape consiste à faire passer le signal sn dans un filtre numérique à réponse impulsionnelle finie
de premier ordre donné comme suit [13] :
'(() = 1 − * (+ ,-. 0.9 ≤ * ≤ 1 (I.5) Ainsi, le signal préaccentué sa est lié au signal se par la formule suivante :
23(4) = 25(4) − * 25(4 − 1) (I.6) 3. Segmentation : les méthodes du traitement de signal utilisées dans l’analyse du signal vocal opèrent sur des signaux stationnaires, alors que le signal vocal est un signal non stationnaire. Afin de remédier à ce problème, l’analyse de ce signal est effectuée sur des trames successives de parole, de durée relativement courte sur lesquelles le signal peut en général être considéré comme quasi stationnaire [1]. Dans cette étape de segmentation, le signal préaccentué est ainsi découpé en trames de N échantillons de parole. En général N est fixé de telle manière à ce que chaque trame corresponde à environ 20 à 30 ms de parole. Deux trames successives sont séparées de M échantillons correspondant à une période de l’ordre de la centi-seconde.
4. Fenêtrage : la segmentation du signal en trames produit des discontinuités aux frontières des trames. Dans le domaine spectral, ces discontinuités se manifestent par des lobes secondaires. Ces effets sont réduits en multipliant les échantillons {sa(n)}n=0…N−1de la
trame par une fenêtre de pondération {w(n)}n=0…N−1telle que la fenêtre de Hamming [17].
s(n)=w(n). sa(n) (I.7)
avec w(4) = 0.54 − 0.46 cos ;2< =
+ > ≤ 4 ≤ ? − 1@
5. Analyse à court terme : chaque trame fenêtrée du signal est ensuite convertie en un vecteur acoustique constitué d’un ensemble réduit de paramètres.
Signal analogique Filtrage et échantillonnage se Préaccentuation Analyse acoustique à court terme (MFCC, PLP, LPCC,…)
Figure.I.5 : Prétraitement acoustique du signal vocal
Segmentation en trame sa
Fenêtrage s
Différentes méthodes coexistent pour la transformation d'une trame fenêtrée de signal en un vecteur acoustique [18] :
• Les méthodes paramétriques qui se basent sur un modèle de production tel que le codage par prédiction linéaire LPC (Linear Prediction Coding), LPCC (Linear Prediction Cepstral Coefficients).
• Les méthodes non paramétriques telles que le taux de passage par zéro, la fréquence fondamental (pitch), la transformée de Fourier discrète, l'énergie du signal, les sorties d'un banc de filtres numériques et la transformée en ondelettes.
• Les méthodes fondées sur un modèle de perception tel que MFCC (Mel Frequency Cepstral Coefficients) et PLP (Perceptual Linear Prediction) [19].
Des études comparatives entre différents types de paramètres acoustiques ont été effectuées, pour déterminer ceux qui représentent mieux le signal vocal.
Dans [20], une étude comparative classique a été effectuée entre plusieurs représentations du signal vocal: cepstre en sortie d'un banc de filtres en échelle Mel (MFCC) ou en échelle linéaire (LFCC), coefficients de prédiction linéaire (LPC) ou de réflexion (RC), cepstre calculé à partir des coefficients auto-régressifs (LPCC). Ces représentations ont été appliquées dans un système de reconnaissance fondé sur un alignement DTW entre un mot de test et des mots de référence. Dans cette étude, les MFCC donnent les meilleurs résultats, ce qui montre plus généralement l'intérêt d'un pré-traitement par banc de filtres, d'une échelle fréquentielle non linéaire, et de la représentation cepstrale [6].
Dans [21], une analyse acoustique par LPC appliquée dans un système de reconnaissance fondé sur les modèles HMM discrets, a donné de meilleurs résultats qu’une analyse par un banc de filtre ou par transformée de Fourier. En revanche, dans [22], le prétraitement perceptif des coefficients PLP a amélioré les résultats de l'analyse par prédiction linéaire.
Dans [23], les paramètres MFCC, LPCC et pseudo-coefficients cepstraux obtenus à partir de deux modèles, ont été comparés sur un système de reconnaissance des mots isolés par les HMM pour diverses conditions d’enregistrements. Dans les conditions normales, les MFCC sont plus performants par rapport aux LPCC et présentent un écart très faible par rapport aux coefficients basés sur des modèles d’audition, alors que, selon [24], les PLP et MFCC donnent des résultats comparables.
Dans [25], des expériences ont montré que les coefficients MSG (Modulation SpectroGram) sont plutôt plus performants avec un classificateur réseau de neurones qu’avec un système standard HTK basé sur les GMM (Gaussian Mixture Model) ; mais dans ce dernier système, les performances des coefficients MSG sont inférieures à celles des paramètres MFCC.
Dans une étude de Furui [26] [4]; il est montré que la prise en compte de l’évolution est possible par l'introduction d’une information sur la dynamique temporelle du signal en utilisant, en plus des paramètres initiaux, des coefficients différentiels du premier ordre issus des coefficients cepstraux ou de l'énergie. Dans [5] les auteurs ont montré que les coefficients différentiels du second ordre peuvent contribuer à l'amélioration des systèmes d'identification phonétique, ainsi que leur intérêt pour de la parole bruitée et soumise à l'effet Lombard.
En se basant sur les résultats de recherche décrits précédemment, nous avons retenu dans notre travail les coefficients MFCC, PLP, LPCC ainsi que leurs paramètres différentiels de premier et deuxième ordre pour sélectionner parmi ces paramètres, ceux les plus pertinents. Cette pertinence est validée à partir du système de référence qui est fondé originalement sur les paramètres MFCC, ainsi que leurs paramètres différentiels. Ces coefficients ont des particularités que nous nous proposons de décrire dans les paragraphes suivants. En revanche, les coefficients PLP et LPCC sont décrits dans l’annexe A.
I.5.1.1 Les coefficients cepstraux
Le signal vocal résulte de la convolution de la source par le conduit vocal. Dans le domaine spectral, cette convolution devient un produit qui rend difficile la séparation de la contribution de la source et celle du conduit. Ce problème peut être surmonté par l’analyse cepstrale par passage dans le domaine log-spectral [27]. En pratique, le cepstre réel d’un signal numérique s(n) estimé sur une fenêtre d’analyse de N échantillons, est obtenu comme suit [1]:
A(4) BBC DEEEEF G(H) IJK| | DEEEEEEF MN |G(H)| BBCDEEEEEEF cepstre OP
Les coefficients cepstraux sont donnés par :
.(4) = ∑ + MN (
UVW |G(X)|)
-YZ[\
] ^N_ 4 = 0, 1, … , ? − 1 (I.8)
Ce type de calcul des coefficients cepstraux n’est pas utilisé en reconnaissance de la parole [1] du fait du calcul important de la FFT et de la FFT inverse [28]. En revanche, les coefficients cepstraux utilisés peuvent être obtenus à partir des coefficients de la prédiction linéaire ou des énergies d’un banc de filtres. Ainsi, les paramètres LPCC (Linear Prediction Cepstral Coefficients) sont calculés à partir d’une analyse par prédiction linéaire (voir annexe A). Si a0=1, {ai}i=1:p sont les coefficients de cette analyse, estimés sur une trame du signal, les
d premiers coefficients cepstraux Cksont calculés récursivement par :
ab = − b− c(d − e)d ab+f f 1 ≤ d ≤ g b+
fV
Un liftrage est effectué pour augmenter la robustesse des coefficients cepstraux [29]. Ce liftrage consiste à multiplier des coefficients cepstraux par une fenêtre de poids W(k) pour être moins sensible au canal de transmission et au locuteur [5]:
∀ d ∈ 1, M i(d) = 1 +M2 . sin m<. dM n (I. 10) où L est le nombre de coefficients.
Les coefficients MFCC (Mel Frequency Cepstral Coefficients) sont les paramètres les plus utilisés dans les systèmes de la reconnaissance de la parole. L’analyse MFCC consiste à exploiter les propriétés du système auditif humain par la transformation de l'échelle linéaire des fréquences en échelle Mel (voir figure I.6). Cette dernière échelle est codée au travers d’un banc de 15 à 24 filtres triangulaires espacés linéairement jusqu’à 1 KHz, puis espacés logarithmiquement jusqu’aux fréquences maximales. La conversion de l’échelle linéaire en échelle Mel est donnée par:
-o = 2595 oN W;1 +psWWqr> (I. 11) Sur une trame d’analyse du signal, les coefficients MFCC sont calculés à partir des
énergies issues d'un banc de filtres triangulaires en échelle de fréquence Mel [1]. Les d premiers coefficients cepstraux (en général d est choisi entre 10 et 15) Ck peuvent être
calculés directement en appliquant la transformée en cosinus discrète sur le logarithme des énergies Ei sortant d'un banc de M filtres:
ab = c log(uf) . .NA v<d(e −12)w d = 0, … , g ≤ fV
(I. 12) La transformée en cosinus discrète permet de fournir des coefficients peu corrélés [30]. Le coefficient C0 représente la somme des énergies. Généralement, ce coefficient n’est pas utilisé.
Il est remplacé par le logarithme de l'énergie totale E0 calculée et normalisée sur la trame
I.5.1.2 Coefficients différentiels
Généralement les coefficients MFCC sont désignés comme des paramètres statiques, puisqu'ils contiennent seulement l'information sur une trame donnée. Afin d'améliorer la représentation de la trame, il est souvent proposé d’introduire de nouveaux paramètres dans le vecteur des paramètres. Furui [26] [4] a proposé l'utilisation des paramètres dynamiques qui présentent l'information de transition spectrale dans le signal vocal. En particulier, il a proposé des coefficients différentiels du premier ordre appelés aussi coefficients delta, issus des coefficients cepstraux ou de l'énergie. Soit Ck(t) le coefficient cepstral d'indice k de la trame t, alors le coefficient différentiel ∆Ck(t) correspondant est calculé sur 2n∆ trames d'analyse par l’estimation de la pente de la régression linéaire du coefficient Ck à l’instant t [15]: ∆ab(y) =∑ e ab(y + e) fV=∆ fV+=∆ 2. ∑fV=∆ ez fV+=∆ (I. 13) Le coefficient delta de l'énergie ∆E0 est calculé de la même façon.
Les coefficients différentiels du second ordre ∆∆ (delta-delta ou d’accélération) sont calculés de la même manière à partir des coefficients du premier ordre. Ces coefficients ont contribué eux aussi à l'amélioration des performances des systèmes RAP. Néanmoins, cette amélioration peut être négligeable comparée à celle des coefficients delta [31] [32].
Dans un système fondé sur l’analyse cepstrale, il est souvent utile de ne garder que les douze premiers paramètres MFCC auxquels on adjoint généralement le logarithme de l’énergie normalisée, ainsi que leurs coefficients différentiels du premier et deuxième ordre. L’ensemble constitue un vecteur de 39 paramètres.
Cependant l’ajout des paramètres différentiels demande plus de temps de calcul et plus d’espace mémoire ainsi que plus de nombre d'échantillons constituant la base de données utilisée pour l'apprentissage, ce qui devient critique pour les systèmes embarqués [7]. Une solution à ces problèmes est de limiter le nombre de paramètres en sélectionnant les plus pertinents susceptibles de modéliser le mieux possible les données pour la tâche de reconnaissance. Dans notre travail de thèse, nous nous sommes intéressés à cette solution en utilisant un outil de mesure de pertinence fondé sur la théorie d’information.
I.5.2 LES MODELES ACOUSTIQUES HMM
Les modèles de Markov cachés (Hidden Markov Models ou HMM) ont connu une grande importance depuis leur introduction en traitement de la parole [33] [34]. La plupart des systèmes de RAP utilisent les HMM pour modéliser les mots ou les unités élémentaires de la parole tels que les phonèmes, les syllabes. De nombreux travaux de recherches ont montré l’efficacité de ces modèles en reconnaissance de la parole continue ou isolée, indépendamment du locuteur pour de petits et grands vocabulaires. Ils sont utilisés avec des modèles de phonèmes indépendants où dépendant du contexte [28]. Les HMM supposent que le phénomène modélisé est un processus aléatoire et inobservable qui génère des émissions elles-mêmes aléatoires [6]. Ainsi, un HMM résulte de l’association de deux processus stochastiques : un processus interne, non observable Q(t) et un processus observable O(t), d’où le nom de modèle caché.
Dans le cas de la parole, la chaîne interne Q(t) est une chaîne de Markov qui est supposée être à chaque instant t dans un état qt où la fonction aléatoire correspondante émet un segment
élémentaire de l’onde acoustique observée représenté par un vecteur de paramètres ot
(exemple des paramètres MFCC) extraits par une analyse acoustique [1]. Idéalement, il faudrait pouvoir associer à chaque phrase possible un modèle. Ceci est irréalisable en pratique car le nombre de modèles serait beaucoup trop élevé. Des sous-unités lexicales comme le mot, la syllabe, ou le phonème sont utilisées afin de réduire le nombre de paramètres à entraîner durant une phase d’apprentissage. En particulier, dans les systèmes de reconnaissance de parole continue à grand vocabulaire, il n'est pas raisonnable d’associer un modèle pour chaque mot, et l'utilisation d'unités acoustiques sous-lexicales devient ainsi indispensable. Par contre dans les systèmes de reconnaissance à petit vocabulaire, la modélisation par mot est très efficace [35].
A chacune de ces unités lexicales, est associé un modèle de Markov caché constitué d’un nombre fini d’états prédéterminés [28]. La reconnaissance de la parole revient à choisir le
HMM capable après avoir été entraîné, d’avoir la plus grande probabilité d’émettre la séquence d’observations (vecteurs acoustiques) correspondante au signal d’entrée.
I.5.2.1 Fonctionnement d’un HMM
Un modèle de Markov est un automate probabiliste d'états finis décrit par un ensemble de nœuds (ou états) reliés entre eux par des arcs de transitions. Cet automate est contrôlé par deux processus stochastiques. Le premier commence sur l’état initial du HMM et se déplace ensuite d'état en état à chaque instant t (1 ≤ y ≤ ), en respectant les transitions autorisées par la topologie de l’automate. Le deuxième génère après chaque changement d’état à l’instant t une observation ot. À chaque état i (1 ≤ e ≤ ?) est associée une distribution de
probabilité bi(o) et à chaque transition de l'état i à l'état j est associée une probabilité de
transition aij [36].
La distribution de probabilité bi(o) représente la probabilité d'émission sur l'état i de
l'observation o. Ainsi, si l'ensemble des observations possibles est un alphabet fini, alors la classe de distribution de probabilité est discrète et le HMM est dit discret. Si les observations sont définies dans un espace continu Rd, alors la classe de distribution de probabilité est continue et le HMM est dit continu (voir figure I.7).
La mise en œuvre d’un HMM en reconnaissance de la parole nécessite de résoudre certains problèmes et de poser un ensemble d’hypothèses simplificatrices. Les trois problèmes principaux sont [1]]:
1. Le choix des paramètres du modèle : quelle topologie utiliser pour définir un modèle (nombre d’états, transitions, loi de probabilité d’émission) ?
2. L’apprentissage : étant donné un ensemble de J séquences d’observations Oj associées à
chacun des Modèles de Markov Mj, comment estimer les paramètres λj de ces modèles afin
de maximiser la vraisemblance de la suite d’observations Oj.
maxλ { ( U\ U, } λ~) (I. 14) ann a12 q=1 q=2 q=N a11 a 22 a2n a1n q=. GMM b1(o) b2(o)
où λ représente l’ensemble des paramètres de tous les modèles λ~.
3. La reconnaissance : étant donnée une séquence d’observation X, et un ensemble de HMM, quelle est la séquence de ces modèles qui maximise la probabilité de générer X ? Les différentes hypothèses simplificatrices pour résoudre ces problèmes peuvent être résumées comme suit [1]:
o Le signal de parole est généré par une suite d’états, chaque état est géré par une loi de probabilité. Chaque unité lexicale élémentaire (phone, diphone, triphone, mot) est associée à un modèle de Markov et la concaténation de tels modèles permet d’obtenir des mots ou des phrases.
o La probabilité que le modèle de Markov soit dans l’état i au temps t ne dépend que de l’état du modèle au temps t-1. Cette condition conduit à un modèle de Markov de premier ordre appelé chaîne simple de Markov:
(•€\•€+ •€+z… •W) ≅ (•€\•€+ ) (I. 15) o La chaîne e de Markov est stationnaire:
(•€ = X\•€+ = e) ≅ (•€‚ƒ= X\•€‚ƒ+ = e) ∀ „ (I. 16)
= fU
où fU est la probabilité de transition de l'état i à l'état j.
o La probabilité qu’un vecteur soit émis au temps t dépend uniquement de l’état au temps t:
(N€\•W• … •€, N … N€+ ) ≅ (N€\•€) (I. 17) o Les HMM utilisés pour représenter la parole sont, la plupart du temps, des modèles "gauche-droit" qui ne permettent pas de "retour en arrière". L'automate probabiliste correspondant ne contient pas de transition entre les états i et j de telle sorte que:
e > X ⇒ fU = 0 (I. 18) o Dans le cas d’un HMM continu, la distribution de probabilité d’émettre l’observation o sachant que le processus markovien est dans l’état j, est représentée par un modèle de mélange de k gaussiennes (GMM Gaussian Mixture Model) ayant la forme suivante: ‰U(N€) = c .f Š(2<)‹Œ∑• Œexp m− 1 2 (N€− Žf)•. ∑•+ . (N€− Žf)n b fV (I. 19) Žf et ∑• représentent la moyenne et la matrice de covariance de la iième gaussienne, ci
est le poids ou la probabilité a priori de la iième gaussienne vérifiant la condition : ∑ .bfV f=1.
|∑•| est le déterminant de la matrice ∑•.
Ainsi, compte tenu des détails présentés ci-dessus, un modèle HMM du premier ordre à N états est défini par la connaissance des paramètres λ={Π , A, B}:
- L’ensemble Π={πi, 1 ≤ i ≤ N} des probabilités initiales πi , probabilité d’être dans l’état i à l’instant initial.
- La matrice de transition A de taille N×N d’éléments aij.
- L’ensemble de distributions de probabilités d’émission B={‰f(N), 1 ≤ i ≤ N} : ‰f(N) est la probabilité d’émettre l’observation o sachant que le processus markovien est dans l’état i.
Différent critères sont proposés pour l’estimation de ces paramètres, comme le critère du maximum de vraisemblance (Maximum Likelihood Estimation ou MLE), le critère MAP (Maximum A Posteriori) et MMI (Maximum Mutual Information). Cependant la mise en œuvre de ces deux derniers est généralement plus difficile [6]. Par contre le critère du maximum de vraisemblance MLE est souvent utilisé pour l’apprentissage car il est moins coûteux en temps de calcul. Ainsi dans les paragraphes suivants, on décrit brièvement l’algorithme de Baum-Welch réalisant le critère MLE.
I.5.2.2 Phase d'apprentissage par critère MLE
Le critère MLE consiste à chercher le meilleur ensemble de paramètre λ qui maximise la probabilité d’émission de la séquence d’observations U par le modèle U :
maxλ { ( U/ U,
} UV
λ~)
Cependant cette maximisation n’a pas une solution analytique, mais pratiquement les formules de Baum-Welch permettent une réestimation itérative des paramètres aij et ‰f(N) en
appliquant ce critère [37]. En partant d’une estimation initiale λW, on réestime les paramètres du nouvel ensemble des paramètres λ . Ensuite on effectue des itérations pour obtenir de meilleurs ré-estimations :
( /λ‘‚ ) ≥ ( /λ‘) ≥ ⋯ ≥ ( /λz) ≥ (λ ) ≥ ” /λW• (I. 20)
Pratiquement la convergence de cet algorithme nécessite une bonne initialisation des paramètres des modèles et un nombre élevé de données d’apprentissage. Cette initialisation peut être effectuée par l’algorithme de Viterbi utilisé dans le décodage.
Les formules de Baum-Welch pour la réestimation des paramètres du modèle sont données directement sans démonstration (le lecteur trouve plus de détails sur ces formules dans [1]
chaque distribution de probabilités d’émission ‰b d’un état k est une Gaussienne multivariée de moyenne µk et de covariance ∑–. Ces formules peuvent être généralisées au cas d’une distribution d’un mélange de lois de Gauss.
La moyenne Žb est donnée par [1]:
Žb= ∑ —€(d). N€ ˜
€V
∑ —˜€V €(d) (I. 21)
γt(i) = P(qt=i\O,
λ
) est la probabilité que l’état à l’instant t soit à l’état i sachantl’observation O et le modèle
λ
. La covariance ∑– est donnée par :∑–=∑ —€(d). (N€− Žb)
˜
€V . (N€− Žb)•
∑ —˜€V €(d) (I. 22)
La probabilité de transition aij est donnée comme suit :
fU =∑ ™€(e, X) ˜
€V
∑ —˜€V €(e) (I. 23)
avec ™€(e, X) = (•€ = e, •€‚ = X \ ,
λ
).Les probabilités γ et ξ sont données comme suit :
—€(e) = (N … N€, •€ = e\ š). (N( \š)€‚ … N˜ \•€ = e, š)= ∑ **€(e) ›€(e) €(e) ›€(e) fV (I. 24) ™€(e, X) = (•€ = e, •( \š)€‚ = X\Ο, š)=∑ ∑*€(e) *fU ‰U(N€‚ )›€‚ (X) €(e) fU ‰U(N€‚ )›€‚ (X) UV fV (I. 25)
où *€(e) = (N … N€, •€ = e\ š) et ›€(e) = (N€‚ … N˜ •€= e, š).
α et β s’obtiennent par récurrence par la méthode appelée forward-backward : *€‚ (X) = •c *€(e) fV fUž ‰U(N€‚ ) (I. 26) ›€(e) = •c fU fV ‰U(N€‚ ) ›€‚ (X)ž (I. 27)
Ces paramètres sont recalculés itérativement en utilisant l’algorithme EM. En pratique, l’apprentissage des modèles s’effectue comme suit [1][3]:
1. Création de modèles dont les probabilités de transition sont équiprobables. La moyenne et l’écart-type de l’ensemble des observations sont calculés et affectés à chaque état.
2. En utilisant les formules de réestimation ci-dessus, on obtient une première approximation pour les probabilités de transition et pour les paramètres des lois de Gauss.
Après un certain nombre d’itérations, les paramètres des gaussiennes pour chaque état sont estimés.
Afin d’obtenir un modèle plus précis, il est nécessaire d’augmenter le nombre de gaussiennes pour chaque état à condition de disposer de suffisamment d’exemples d’apprentissage [1].
I.5.2.3 Phase de reconnaissance
A). Reconnaissance de mots isolésConsidérant V mots d’un vocabulaire dont chaque mot Wi est modélisé par un modèle Mi,
la reconnaissance d’un mot inconnu appartenant au vocabulaire revient à chercher le meilleur modèle permettant de générer la meilleure séquence d’états Q=( q1,q2,…,qT) qui peut générer
la séquence d’observations O=(o1,o2,…,oT) correspondant à la prononciation du mot inconnu.
Une solution consiste à évaluer le maximum P(O\M,Q) pour chaque séquence d’états possibles Q, avec :
( \ , Ÿ) = <W{ ¡OP ¡.
˜ €V
‰ ¡(N€) (I. 28)
Le nombre de séquences d’états possible est très grand, de l’ordre de T.NT. Ainsi, cette solution est inapplicable en général. Une autre solution basée sur une variante stochastique de la programmation dynamique appelée l’algorithme de Viterbi [1] [13], permet de trouver la séquence optimale d’états avec une complexité de calcul limitée à T.N2.
Cet algorithme consiste à construire de façon itérative la meilleure séquence d’états à partir d’un tableau T×N contenant les valeurs δt(i) définissant la vraisemblance du meilleur chemin fini à l’état i au temps t. La valeur δt(i) peut être calculée par récurrence :
Initialisation : δ0(i)=πi, probabilité d’être dans l’état i à l’instant initial Récursion :
δ£(i) = arg max~ (δ£+ (e) fU) ‰f(N€) (I. 29)
Terminaison : P = arg maxfδC(e), cette valeur détermine la vraisemblance donnée par la formule (I.29).
B) Reconnaissance de la parole continue
Dans la reconnaissance de la parole continue, on ne connait pas le nombre de mots qui composent une phrase, ni les frontières de chaque mot. Cette difficulté peut être résolue en effectuant une transition du dernier état d’un mot vers le premier état d’un des mots du
vocabulaire. Ainsi, une modification de l’algorithme de reconnaissance des mots isolés est nécessaire.
L’algorithme de Viterbi devient [1][3]:
Initialisation : ¥Wb = <fb, k désignant l’un des mots du vocabulaire. Récursion:
Etat non initial du mot k : ¥€b(e) = maxU(¥€+b (e). fUb ) . ‰f(N€), Etat initial du mot k:
¥€ (e) = max (maxU (¥€+b (e). fUb ) ,
max¦ (¥€+¦ ”état¨inal(o)• . ( ¦\ b))) . ‰f(N€)
Terminaison : = arg maxb(¥˜b(e)) .
La terminaison indique seulement le dernier état qui maximise la séquence ; afin de retrouver la séquence de modèles, deux solutions peuvent être envisagées. La première consiste à mémoriser dans le tableau des δ l’état qui avait contribué à calculer le maximum. Ainsi, à la dernière trame, il suffit de revenir en arrière à partir de l’état qui maximise ¥˜b(e) pour retrouver la séquence optimale d’états et la séquence de mots. La seconde consiste à mémoriser dans ¥˜b(e) la séquence de mots qui a permis d’arriver à l’état i du modèle k à l’instant t.
A la fin de la reconnaissance, on obtient non seulement la séquence de mots prononcés mais aussi les frontières de chaque mot [1].
Dans l’annexe B, nous décrivons la mise en œuvre pratique d’un système de reconnaissance de mots connectés sous la plateforme HTK. Plus particulièrement ce système se base sur les modèles HMM associées aux modèles GMM.
I.6 C
ONCLUSIONLe signal acoustique de la parole présente une grande variabilité qui complique la tâche des systèmes RAP. Cette complexité provient de la combinaison de plusieurs facteurs, comme la redondance du signal acoustique, la grande variabilité intra et inter-locuteurs, les effets de la coarticulation en parole continue, ainsi que les conditions d’enregistrement. Pour surmonter ces problèmes, différentes approches sont envisagées pour la reconnaissance de la parole telles que les méthodes analytiques, globales et les méthodes statistiques. Actuellement la majorité des systèmes RAP sont construits selon la méthode statistique en utilisant les modèles de Markov cachés HMM. Ainsi, dans ce chapitre, nous avons décrit brièvement le principe de fonctionnement des systèmes RAP basés sur les modèles HMM ainsi que leur mise en œuvre pratique.