L'évaluation de l'imprévisibilité du patron de scores à l'échelle homogène : extension du concept de consistance interne
Texte intégral
Figure



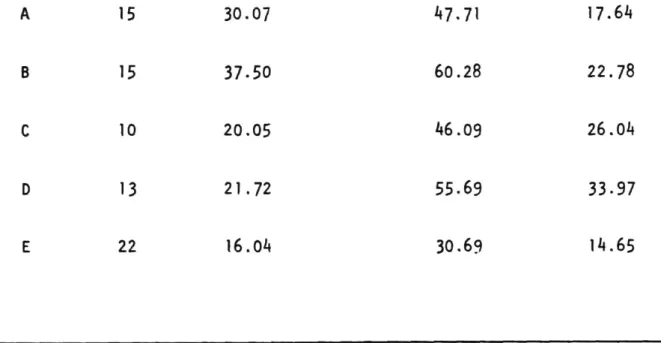

Documents relatifs
Les connaissances phonologiques et plus particulièrement la conscience phonémique associées à l’acquisition des premières connaissances alphabétiques (connaissance des
La feuille de route du Gouvernement sur l’innovation est en cours de déploiement, sous l’égide du Conseil de l’innovation : structuration de la stratégie
Les moyens consacrés à la vie étudiante sont en hausse de 134 M € par rapport à 2020, dont plus de 80 M € seront consacrés aux bourses sur critères sociaux (avec en
→ Des outils innovants avec les Campus connectés pour fournir des solutions d’accès aux études supérieures dans tous les territoires, les classes préparatoires “Talents
Pour arriver à cette conclusion, Brillouin se fonde sur sa résolution du paradoxe du « démon de Maxwell », qu’il développe dans son livre. Le paradoxe de Maxwell consiste
This point of view is defined as the negentropy principle of information, and it leads directly to a generalisation of the second principle of thermodynamics,
Concernant la chaleur provenant du Soleil, il esquisse une théorie de l’effet de serre en affirmant que l’atmosphère est plus transparente au rayonnement solaire
He thereby obtained the first confirmation that, in the lower layers of the atmosphere, the spectra of solar radiation and radiation emitted by the earth’s surface
