Profiles Semantics and Matchings Flexibility for Resources Access
9
0
0
Texte intégral
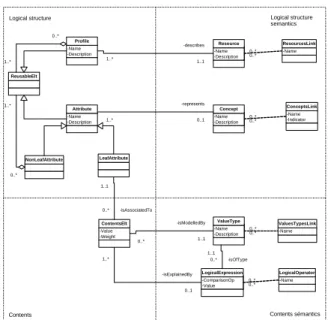
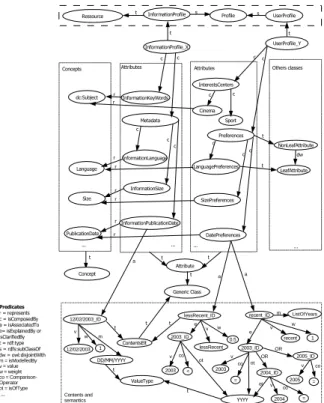
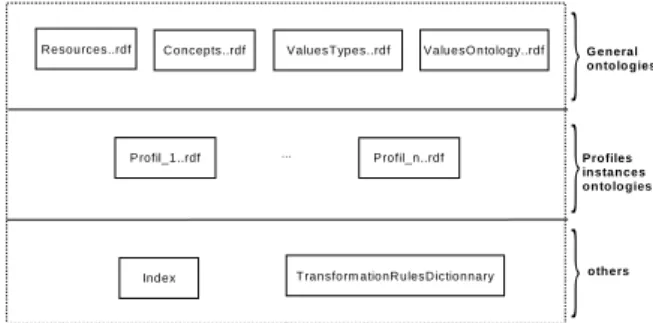
Figure

Documents relatifs