SemEval-2012 Task 2 : measuring degrees of relational similarity
Texte intégral
Figure

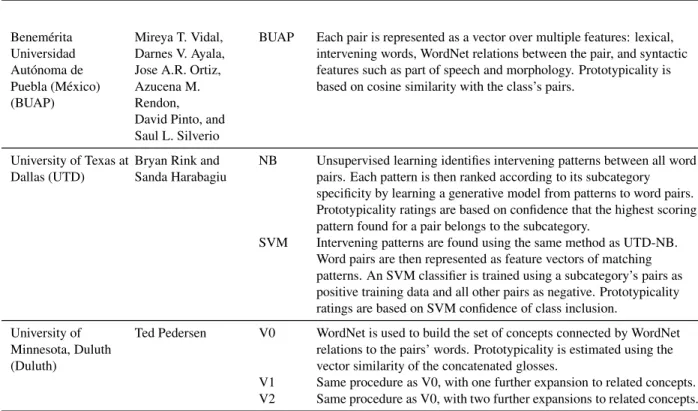

Documents relatifs
We consider that examples are drawn following some dis- tribution and that each example is then submitted to a masking process, according to some ambiguity level p, and results in
In connection with all this, another problem arises: to use the developed method of comparative evaluation of algorithms for calculating distances between sequences for a
We compared query profiles having variable proportions of matching phenotypes to subject database profiles using both pairwise and groupwise Jaccard (edge-based) and Resnik
We had both collected detailed ethnographic information on how relational transformations take place; respectively, during mortuary rituals of the Owa in the
385 rue de la bibliotheque – B.P. In this paper, we present a similarity measure between be- havioural interfaces of Web services. This measure computes the differ- ence value
We propose a two step bootstrapping architecture of integrating relational databases with the Semantic Web by first generating a “database- derived putative ontology” and
We use causal footprints as an abstract representation of the behavior captured by a process model, since they allow us to compare models defined in both formal modeling langua-
Under a closer investigation we can see that the user- given annotations provide a similar information – they say how particular schema fragments should be stored to enable
