Multivariate Temporal Dictionary Learning for EEG
Texte intégral
Figure
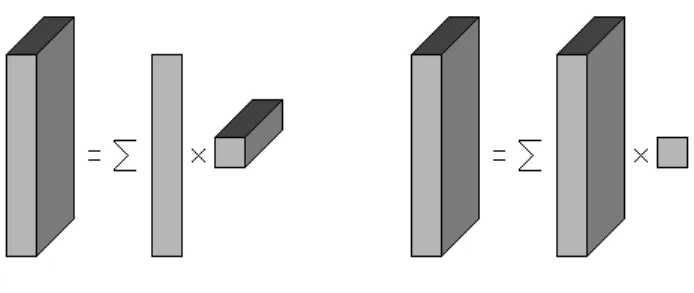

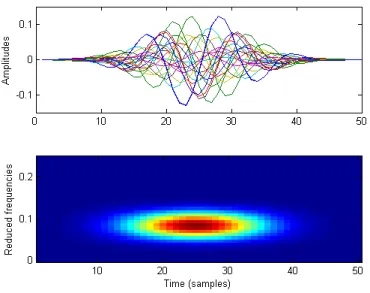
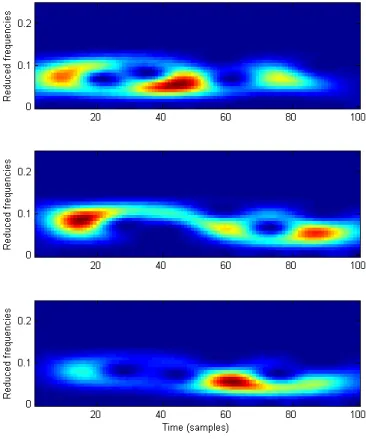

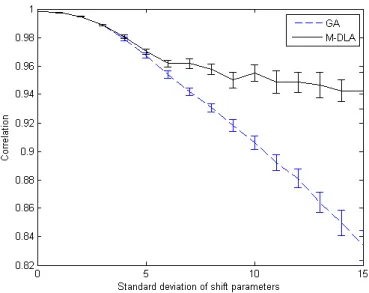
Documents relatifs
On appelle onde matérielle une onde qui se propage dans un milieu en le déformant (onde sonore dans l'air atmosphérique, par exemple.); la propagation de l'onde est due,
ILLIAD project: Sustainable, local or localised, innovative food chains – application to apricot production.. International Symposium on Apricot Breeding and Culture, Jun
45 Department of Physics, Duke University, Durham NC, United States of America 46 SUPA - School of Physics and Astronomy, University of Edinburgh, Edinburgh, United Kingdom. 47
Pour autant, il ne le fait pas apparaître afin de se préserver des marges d’action, des possibles permettant aux parents d’adhérer au projet d’aide par exemple, ou au collègue
dividend shares earn excess pre-tax returns roughly ec^ual to twenty j^ercent of their dividends Stock dividend shares yield a much snaller excess return, if. any» However,
• A sparse scattering network architecture, illustrated in Figure 1, where the classification is performed over a sparse code computed with a single learned dictionary of
Average performance of the sparsest approximation using a general dictionary. CMLA Report n.2008-13, accepted with minor modifi- cations in Comptes Rendus de l’Acad´emie des
Supplementary Materials: The following are available online at http://www.mdpi.com/2218-273X/10/11/1471/s1 , Figure S1: Representative ion chromatograms of ceramides and
