uewey
HD28 .M414 MIT LIBRARIES 39080 009278786^
The
Context Interchange
Network
Prototype
AdilDaruwala ChengGoh
Scott Hoftneister KarimHussein StuartMadnick Michael SiegelWP
#3797 February 1995The
Sloan School ofManagement
MassachusettsInstitute ofTechnology
Cambridge,
MA
02139The
Context Interchange
Network
Prototype*
Adil Daruwala ChengGoh
ScottHofmeister Karim Hussein StuartMadnick MichaelSiegelSloan
WP
#3797 CISLWP
#95-01IFSRC
WP
#308-95 February 1995MASSACHUSE'iTSINSTITUTE
OFTECHNOLOGY
MAY
2 6 1995LIBRARIES
The
SloanSchool ofManagement
Massachusetts InstituteofTechnology
Cambridge,
MA
02139services that will
be
offeredby
theCIN.
In Section 3,we
examine
the architecture ofCIN
and
describe themajor
components and
their functionality.We
consider itsuse
inproviding semantic
interoperability as well as itsapplication to context
management.
In Section 4,we
present details of theCIN
implementation
focusingon
the conflict detection,and
conversion-basedquery
optimization. In Section 5,we
presentour
strategy for introducing this technology into existing applications as a"middleware"
service. In Section6,we
examine
related research areasand
futureplans fortheimplementation.1.1
The Need
forContext
InterchangeThe need
for the context interchangenetwork
is exemplifiedby
the traditionalapproach
tohandling disparate contextasshown
in Figure 1.Numerous
sourcesand
receiversmay
existon
anetwork
butboth
the stored dataand
the receivers(e.g., applications)
have
implicitpreconceivedassumptions
aboutthemeaning
of the data. Traditionally conversions routines are introduced eitheron
the sourceside (e.g., source Si provides conversion xi2 for information sent to receiver R2)
or
on
the receiver side (e.g., receiver Ri provides conversion X21 for informationfrom
source Si)and
insome
instanceson
both
sides . Clearly thisapproach
scales poorlysincethe total
number
ofconversions isproportional to theproduct
of the
number
of sourcesand
thenumber
of receivers (i.e. n^). In addition thereis
no
facility to explain differences in themeaning
ofdatafrom
different sourcesas
knowledge
about themeaning
ofdata isembedded
in conversioncode.The
CIN
approach, as depicted in Figure 2, allows for the explicit representation of sourceand
receiver contextknowledge and
uses this information alongwith
contextmediation
services to automaticallydetermine
thesemantic
conflictsbetween
sourcesand
receiversand
to apply theappropriateconversions.As
willbe
discussed later thisapproach
is scalableand
evolutionarywith
changes
in contextknowledge.
Conversion X12
may
have existed but the requirements of Rimay
have changed. Thus, X2i translatestheoutputofX12intothenew^ form.Information Highway Context Mediation Services Receivers ^»—»^ ^1 *
^vl^^
I.I \w-ortax/Figure1: TraditionalApproachto
HandlingDisparate Contexts
Context Definitions Figure2:Context InterchangeApproach
2
An
Example
Scenario
Using
Context Interchange
Network
As
an
example
of thisapproach
we
describe the following scenario inwhich
an
executive ofan
investment bank, is attempting to compile historical informationon
Daimler-Benz
forameeting
ofthebank's investment advisory committee.2.1 Traditional
Approach
She
startsup
theData
Extraction Software, aPowerbuilder
applicationwith
access to several relational databases,
and
proceeds
to enterDAIMLER-BENZ
AG
as thecompany
name. She needs
tocompile
historical data forthepast fiscalyear, thus she enters
12/31/93
as the FiscalYear
End
dateand
selects theWorldscope
financial data service since sheismost
familiarwith it,and
proceedsto select the
NET-INCOME,
SALES, and
CURRENT-OUTSTANDING-SHARES
data fieldsl
She
notices that theCOMPANY-NAME
and
theLATEST-
ANNUAL-FINANCIAL-DATA
fieldshave been
pre-selectedby
the application,and
remembers
that the application usesthem
forgraphing
the selected dataelements.
She
then clicks theQuery
button to extract the necessary information(Figure 3).
She
makes
a note ofthe extracted data asreported in thelower halfof theData
ExtractionSoftwarewindow.
Notethatthe typefaceconvention that
we
vkrilluseinthispaperisthat attributenameswillbeinall
UPPERCASE,
conceptswillberepresented in small-caps courier, meta-attributeswillbein plaincourier,valuesofmeta-attributeswillbein [bracketed].through
CIN
(Figure 5) is identical to that reported directlyby
theWorldscope
dataservice earlier(Figure3).
She
thenchanges
the data source to Disclosure.She immediately
notices thatthough
she hasselected Disclosure as the datasource, the application accepts theWorldscope
naming
convention
DAIMLER-BENZ
AG
as thecompany
name,
and
that it reports the data fieldsnames
in Worldscope's context.She
selects theNET-INCOME,
SALES, and
CURRENT-OUTSTANDING-SHARES
fields,and
proceeds toextractthedata (Figure 6).She
notices that the datanow
reportedby
Disclosure (Figure 6) is verydifferentfrom
thatreported directlyby
Disclosure earlier(Figure 4).She
also notices thatthe data
now
reportedby
Disclosure
(Figure 6) relates closely to the dataextracted
from
theWorldscope
data service (Figures 3and
5).The
use of theCIN
allowed
the analyst toexamine
information in acommon,
familiar context (i.e.,Worldscope
)and
tomeaningfully
compare
informationfrom
other contexts (i.e.. Disclosure). Thiswas
all possiblewithoutchanging
the existing application (i.e..Data
Extraction Software). In theremainder
of this paper,we
describehow
theCIN
makes
this possible.1" Contex! InterchangeNchiroric
CONTEXT INTERCHANGE
NETWORK
TJ...
-m
Data Extraction Softwarei
OAJMIfHBlKZAG
AvaJabla OalaElc»enti
COMPANY^lAUt IEL£PHONE CUSIP-HO
TICKERSYMBOL
LATESTANNUAL -nNANOALOAl
CURRENT-OUTSTANDINGSHARI; COUUOH-EQUirY
NET INCOME
SALES ,
TOTALASSETS ^
Ssiectod DalaEtc
COMPANY^iAME lATESTANNUAL^HANOAL-DAT A CURRENT-OUTSTANDING SHARES HEIINCOME SALES g°° BBS LURREHUJUTSIANDIHU SHARES 46&00.0O0 NET(NCOME 34€.577 SALES 56.26e.l&8
Context InterchangeNetwork
CONTEXT INTERCHANGE
NETWORK
KftftC*wifcWC60Nw (MMn0ftv<MMMH jOwSWOCWWK((#fl\*ipillltApf0mHm^ll%
31
[Pata Extraction Software)
Cwwirltoiw: jbAiMLlRbeNZAG
fiMMlYMHCMt f12/31/93 3
M
A«aArf)fa Dal«(tewtnli
COMPANY-NAME TELEPHONE IICXERSYMBOL LATEStANNUAL^IHANClAL4)ATA CURRENT OUTSTANDING-SHARES NETINCOME SALES COMPANY-HAHE LATESTANNUAL-FINAMOAL«AI A CURRENT-OUTSTANDiNG-SHAnES NET-INCOME S/U^S »«> I
CUHRfNTOUTSIAMOIHG SHARES
46^32/SO
NETmCOMt
349,431
SALES
se.2eales
Figure5: ContextInterchangeNetwork
-WorldscopeData
Figure6: ContextInterchangeNetwork
Shared Ontologies
Conversion
Libraries Contexi
Management
Application
Context
Definition
Source
Receiver
Figure7: ContextInterchangeNetworkArchitecture
3.
The
Context Interchange
Network
Architecture
In this section
we
present ahigh
levelview
of the architecture of the currentimplementation
asshown
in Figure 7,by examining
thecomponents and
functionality ofthe
system
for a single sourceand
single receiver. It is importantto note that there are
two
major
uses of this network. First, is toguarantee
semantic interoperability fornew
or existing receiverapplications asexemplifiedby
theexample
in Section 2.The
second
use is for themanagement
of contexts, as described below. For simplicity,we
refer toany
source (e.g., database, datafeed, application
program
output) or receiver (e.g., application, consolidateddatabase) as a node inthe
CIN.
3.1
Context
Mediation
In the
Context
InterchangeNetwork
every data sourcemust
specify a contextdefinition
which
describes the kinds ofdata that it cansupply
(e.g.,COMPANY-NAME,
SALES,
NET-PROFIT)
and
all associated context information (e.g.,currency,
scale-factor,
date-conventions).
Receiversmust
specify asimilar context definition
which
will contain a list of the kinds of data that the receiverwould
be
interested in seeingand
the associated context information. Typicallyit is expected thatagiven receiver'scontextdefinition willbe
similar,ifnot identical, to the context definition of their favorite data source (usuallytheir local data services). In the
example
shown
inSection2,the receiver'scontextwas
chosen
tobe
identical to theWorldscope
database.Integral to the context definitions is
what
we
call a shared ontology.The
sharedontology
essentially provides a standardvocabulary
inwhich
to express thecontext definitions.
The
vocabulary
consists oftwo
parts.The
first is agiven database. In
our
currentimplementation
the shared ontology is intendedto cover the different kinds of data that
might appear
in a financial application.The
second
important fimctionality of the ontology is to describe the contextualinformation
about
the data. In Section 4we
will describe inmore
detail exactlyhow
thisisimplemented.
The
context mediator intercepts all requests for datamade
by
the receiver, ittranslates the
query
from
the receiver to the source context, poses thequery
tothesource database capturing the data returned,
and
finallythedata isconvertedinto receiver context.
The
final stage of converting the data into the receivercontext is
perhaps
themost
complex,
and
involves consulting a library ofconversion functions
which
enables the contextmediator
to convertfrom
one
context(e.g., currencyordateconventions) toanother.
3.2
Context
Management
The
Context
Management
Application allows the user to interactwith
thevarious source
and
receiver context definitions.The
contextmanager
providesthe followingservices to theuser:
1) Retrieval ofthe context ofa given
node
(i.e.,source or receiver.)2)
Updating
ofthe contextinformation for apre-existing node. 3) Entering the contextfor anode which
isnew
to the network.4)
Comparing
contexts fortwo
differentnodes
toproduce
a list ofpotentialconflicts.
5)
Comparing
individual attributefrom
thesame
or differentnodes
toproduce
a listof potentialconflicts.6)
Browsing
ofthe shared ontologyto learnmore
about thedomain
(e.g., financial)and
potential sources of useful information.As
willbecome
clear, several of theabove
services relyon
thesame
underlyingmechanism
as isused
by
the contextmediator
inproviding
forsemantic
interoperability. In particular, the
comparing
of contexts to see the potentialconflicts is exactly
what
isdone
assoon
as a receiver chooses a particular datasource. In order to
determine
which
conflicts actually occur it is necessary toexamine
thequery
used. In the next sectionwe
will describe in detailhow we
Client
/Receiver
Query Attribute ConverterM
QueryL^
Queryt
DataSource&Receivercontext ID's
ConflictDetector Attribute Map Conflict Table
it
QueryProcessing Controller Optimizer (pre-processconversion) Library of Conversion Functions Data SharedOntology Library of Local Context , Definitions Data Data ConverterJ
Source
/Server
DBMS
Figure8: ContextMediator
OPre-encoded I I
information I I
Procedures
4.
CIN
Implementation
At
thecore of the Context InterchangeNetwork
is theability to representcontextknowledge, perform
conflict detection,and
provide context transformingquery
processing.Tliese capabilities aredepicted inFigure 8.
The
context representation isprovided
by
the sharedontology
(i.e., the set ofcommon
concepts)and
the local contexts (i.e., the definition of a node's contextand
themapping
of that context to concepts in the shared ontology). Conflictdetection is
determined
by
the conflict detectorwhich
provides asoutput
theattribute
map and
the conflict table.The
context-basedquery
processingis controlledby
the query processingcontrollerthat
makes
requests for the attributemap
and
the conflict tableand
accessesand
applies the necessary conversion.
The
controller callson
the attribute converter,data converter,
and
optimizer toprovide
data to the receiver in the required context. In theremainder
ofthis sectionwe
examine
thekey
functionality of theCIN,
context representation,conflictdetection,and
query
processing.The
crux ofour
effort todo
Context Interchange involvesour
specification ofwhat
constitutes "contextknowledge" and
how
it is representedand
made
available tothe context mediator for conflict detectionand
transformation. Thisspecification
determines both
thepower
and
the inherent limitations ofour
current approach.
As
a starting pointfor this discussionconsider Figure 9which
shows
the sourceand
receivercontextsfrom
theexample
in Section 2.Shown
in thisdiagram
is the local context for the receiver (i.e.,whom
prefers theWorldscope
context), the local context for the data source (i.e., the context for Disclosure), a shared ontology ofconcepts,and
themappings between
the local contextand
concepts in the shared ontology.Each
of thesecomponents
of contextknowledge
representationwillbedescribed inthis section.4.1.1
Defining
Local ContextsIn
our
currentimplementation
it ispossible toattach contextual information only to the fields or attributes ofa givennode
(i.e., source or receiver's view).The
form
ofcontextual information thatwe
may
encode
is meta-dataand
is assertedby
stating values for meta-attributes.An
example
of meta-data thatmight be
found
in traditional database dictionaries iswhether
thenumber
forSALES
isstored in thesource data as astring, a float,or
an
integer.However,
we
aremore
concerned with semantic
information that is notfound
in traditional data dictionaries. For example, the interpretation ofSALES
(see Figure 9) thatcomes
from
knowing
itsscale-factor
orcurrency.
In addition there aremore
complex
types of meta-data, forexample whether
the value given in a data source forNET-INCOME
includes orexcludes extra-ordinary expenses (i.e. one-timecosts like refinancing apension).We
make
such
assertionsby
giving values for meta-attributeson
certain attributes. Forexample,
in the receiver contextshown
in Figure 9, theNET-INCOME
field has a value of [US$] for themeta-attribute
currency
which
means
that for the receiver thenumbers
thatappear
in the
NET-
INCOME
fieldshould
representnumbers
ofUS
dollars. In Section4.1.4
we
examine
the range ofapproaches
for assigning meta-attribute values. In the nexttwo
subsectionswe
examine
the roleand
structure of theshared
ontologyand
themapping
between
the local contextand
theontology.4.1.2
The
Shared
Ontology
The
shared
ontology provides
severalimportant
representations. First, thecommon
concepts are represented so that disparate local contextscan
be
mapped
to these conceptsand
contextcomparison
may
be
done
in acommon
language. Secondly, the ontology provides a representation for meta-attributes
(i.e.,
shown
as links). Finally, the sharedontology
provides the identity forcommon
conversion
functions^ thatmay
be
used
totransform
context differences.The
specific shared ontology constructed for thisimplementation
is^ Theability torepresentboth
common
conversionfunctionsand thosethatmay
bespecific toagiven contextisconsideredin thisimplementation. Localconversionfunctions
may
beidentified in localcontextdefinitions. Forsimplicity,conversionfunction representationisnotshowninthen vo
r
o n n O 3 Xa
o 3a
3O
c
o
(Do
O
3
f* (DX
(0o
o
(0c
-^ (D t-^a financial reporting ontology
and
was
developed based
on
theexamination
ofmore
than eight financial data sources butwith
particularemphasis
on
theinformation
represented in Disclosure,Worldscope
and Compustat.
It is important to note that theCIN
is inno
way
limited to the financialdomain.
Itmay
be used
inany
domain
where
there is sufficient contextknowledge
to providea shared ontologyand
localcontext definitions.Because
of the largenumber
of concepts thatmight
be associatedwith
a givendomain,
the shared ontology is defined as ataxonomy
of concepts. In addition,because
the shared ontology is designed for use in context interchange it isvery
useful to
make
the distinctionbetween
Data
Objectsand
RealWorld
Concepts
and
Objects.The
ovalson
left side of the tree (asshown
in Figure 9) representclasses ofdata objects (e.g.. Sales,
Company-Name,
orName
-of-Country)and
the rectangleson
the right side of the tree the represent classes ofmostly
abstractentities (e.g.. Modifiers, Organizations, Relations,
Scale
-Factors).As
shown
inFigure9and
described later, the lefthand
sideprovides the set ofconcepts formapping
the attributes defined in the local context's, while the right-hand-sideprovides concepts for defining meta-attributes
and
their values. Linksbetween
the data objects
and
therealworld
concepts areused
torepresent meta-attributesand
can
be
read as "NUMBER
has ameta-attributeof Scale Factor"We
have
found
thisapproach
to structuring the shared ontology beneficial inboth
simplifying itsdevelopment
and
using it for context interchange.One
persistentand
frequently confusing aspect of thisdichotomy
arisesfrom
thequestion of
what
informationbelongson
which
side ofthetaxonomy,
the rightor the left? Fortunately this isnotan
either/ordecisionand
theanswer
canbe
both,although it will not often
be
so.An
example
when
thismight
happen
involvesthe useof currency types. Clearly currency is
an
appropriatemeta-attributeand
thus
we
need
to represent the different currencies as "realworld
concepts"and
thus
belonging
to the right side of the tree.However,
theremay
also exist a financialdatabase
which
containsamong
other things a field dedicated to holding thenames
of currencies. In order toencode
a context definition for thisdatabase
itwould
be
necessary to assign aconcept
to this attributeand
a perfectly appropriate conceptmight be currency-name
(subclass of name).Thus
inthis
example
we
have nodes
on
both sidesofthetaxonomy
with "currency" astheir
key
descriptive element.However,
it is important to note that thesetwo
nodes
do
not duplicate thesame
information, thecurrency
node on
the righthand
side represents the set of abstract conceptswhich
are the currencies of international tradewhich
thenode currency -name
on
the lefthand
siderepresents the set of data objects
which
are thenames
of the currencies of international trade.The
distinction is subtle but important.A
similarexample
might
be
that of the conceptcompany
which
was
the set ofcompanies and
COMPANY -NAME
which
is thesetofcompany
names.
This distinction
between
objectsand
their representations is defensibleand
indeed
desirableon
itsown
merits.A
frequentproblem
inknowledge
representation is the careless
mixing
of representationswith
objects.Some
dataobjects
such
as thenumber
ofemployees
or net profitdo
nothave
easilyidentifiable objects
which
theyrepresentand
some
objectssuch
ascompanies
orpeople
to not easily convert tounambiguous
representations. In addition whilecompany
names
may
have
maximum
lengths orpunctuation
conventions,companies
do
not,and
whilecompanies
may
have
presidents or net incomes,company
names
certainlydo
not.While
this distinctionmay
seem
clear intheory, in practicein large
taxonomies
it iseasy to gethopelesslyconfused
about
what
exactlycertainnamed
concepts exactly represent[Woods,
1985].Another
major
piece of theshared ontology
involves the relation ofmeta-attributes to the
concept taxonomy.
Meta-attributes are similar tobinary
predicates
and
relatetwo
classes of things.From
Figure 9,one
can see thaton
theconcept numberthe meta-attribute
scale-factor
isdefined whileon
money-amounts
the meta-attributescurrency
is specified. Valuescan be
specified formeta-attributes attached to a given conceptfor all the meta-attributes defined
on
that
concept
oron any
concept
which
isan
ancestor of that concept.Thus
looking at the
diagram
we
canseethat theconceptshare-amounts
could specify avalueforthe meta-attributes
scale- factor
whilethe conceptnet-income
couldspecify a value for the meta-attributes
scale-factor
and
currency.
It isimportant
to note that while in theorywe
could specify a meta-attribute valueanywhere
from
the root conceptto the leaf, inour implementation
we
only allow leafnodes
to attach to attributesand
specify thevalues of meta-attributes.4.1.3
Mapping
LocalContext
to theShared
Ontology
The
local context definition contains attributesand
meta-attributes thatmust
be
mapped
toconcepts inthe shared ontology.The
local contextencodes
what
kindofinformation iscontained in thegiven field, these correspond to concepts inthe
data object portion of the shared ontology. For
example,
the attribute calledCURRENT-SHARES-OUTSTANDING
in the sourcecan
be
pairedwith
theattribute
CURRENT-OUTSTANDING-SHARES
inthe receiver because theyhave
been
linked tothesame
concept,SHARES
-OUTSTANDING.
The
additionofanew
node
into the Context InterchangeNetwork
would
require thateach
attributebe
pairedwith
a concept in the shared ontology.'* Foreach
attribute they
would
begin
at the rootnode and
traverse apath
to the appropriate leafnode
inthe tree,note that only the leafnodes
are valid concepts to attach to attributes.The
principleguiding
the design of thisnetwork
ofconcepts is that thetraversal process
should be
user friendly. Thismeans
that ateach
level thereshould
be
a reasonably smallnumber
ofbranches (i.e., less than five)and
that the choices are sufficiently distinct that there is only a smallprobability of
going
down
the"wrong"
path
formore
than a couple levels.At
^ In the currentimplementation
we
do notallownew
conceptsor links tobe introduced to thesharedontologyby anode. Laterimplementationswillconsider
how
tomake theontology more extensiblefornew
conceptsandmeta-attributes.any
time, a usermay
consult the associated RealWorld
Concepts
to help clarifythe
meaning
of a dataobject.The
meta-attributes in the local context are definedby
the links to the realworld
objects.
These
linksmay
be
appliedanywhere
in thetaxonomy and
thus the meta-attributes for a concept are the collection of links for itand
the parent concepts.4.1.4
Assignment
of Meta-AttributeValues
In this section
we
examine
the three categories of meta-attributevalue
assignmentsand
present thosethat aresupported
inthe current implementation.The
three categories are:Independent:
The
value ofsuch
a meta-attribute is amember
ofsome
class ofobjects,
and
isknown
at the time the context is entered. For example, all theSALES
figuresforthe receivershown
inFigure9 arerepresentedthousands
ofUS
dollars.Closed
Data Dependency:
In this case the value ofa meta-attribute attached to agiven attribute is
dependent
on
the value ofdata in another attribute(s) in thesame
record. For instance, the currency value forNET-SALES,
TOTAL-ASSETS, and
NET-INCOME
for the source in Figure 9 isdetermined
by
the location of the incorporation of thecompany
(e.g.,Daimler
Benz
ofGermany
has netsales in
German
marks,Sony
ofJapan
has net sales inJapanese Yen).Open
Data Dependency:
Same
asimmediately above
exceptthat thevalue of the meta-attributemight be
dependent
on
the value of data associatedwith
an
attribute(s)
which
may
be
in another record or sets of records (e.g., different relations in thesame
orother sources).As
an
example
considerthe caseabove
except thatthe countryof the corporateheadquarters is notincluded as a fieldin the
same
recordwith
net salesbut instead is located insome
othersource^The
extent towhich
we
support
these threemechanisms
in thisimplementation
isas follows:
Independent: Fully supported.
Closed
Data
Dependency:
Partially supported.Although
we
support
thisform
of meta-attribute,
we
limit fornow
the nature of the relationshipbetween
the meta-attributeand
the datawhich
itisdependent
upon.The
userisallowed to^ Note that
we
donot need toinclude the case of a meta-attribute dependent on the valueofanother meta-attribute sinceeither the originalmeta-attribute is a constant or is dependent on
someattribute. Thusthe valueof thesecondmeta-attributeiseitherahanction ofa constantand
thus a constant or the composition of two functions applied to a piece of data and thus
constitutingsomeformofdatadependency. In thisanalysis
we
ignore thepossibilityof acyclicdependencyof meta-attributes.
state rules of the form: if
ATTRIBUTE relation
[constant] then setmeta-attribute equal to constant.
The
relationcan
be
any
of themore
common
binary predicates: equal, not equal, greater than, less than, etc.
Thus
forexample
a valid rulewould
be, ifthe fieldCOUNTRY^
is equal to"Germany"
thenthe
currency
meta-attribute associated withnet-profit
would
be
set toGerman-marks.
Laterwe
plan to loosenthis constrainton
expressiveness.Open
Data Dependency:
Not
currently supported.Given
the notion of linkingone
piece of data to another it is not difficult, conceptually, toexpand
that tolinkages outside the current record.
However,
from
apragmatic point ofview
once
one
allowsexternal linkages thenumber
of different kindsof linksgrows
from
a handful to being almostunbounded.
Potentiallyone
can conceiveof anumber
of external linkages that couldbe determined
automaticallyalthough
itis not
immediately
apparenthow
comprehensive
or useful this listwould
be.Itis clear,
however,
that inmany
casesitwould
be
incumbent
upon
the user toidentify
and
definewhich
linkages theywere
interested in using,and
while
thiscertainly isnotintractableit ishighly ambitious.As
an
example
of a closed datadependency
we
direct the reader againback
to Figure9. All the currenciesin theDisclosure database arein thebase currency of thecompany,
thus all financial figures forFrench
companies
are in Francs, forGermany
companies
they are inMarks,
etc.The
way
that this is actuallyencoded
isby
attaching anumber
ofmeta-attributesettings to eachattributeeachwith
a closed datadependency.
Thus
forNET-SALES,
forexample,
we
would
have
thefollowing rules:currency=[US$] if LCX:-OF-INCORP="USA"
cur rency=[Marks] if LOC-OF-INCORP="Germany"
currency=[Francs] if LOC-OF-INCORP="France"
currency=[Pounds] if
LOC-OF-INCORP="UK"
The
taxonomic
representationdoes
allow for the user toview
and
make
assignments
for related families of concepts.Thus
if the userknows
that in agiven databaseall of the
money amount
figures are inUS
dollarsor that all datesare in
European
format then it willbe
possible to state this factabout
thehigh
level concept
and have
itbe
inheritedby
all itsdescendant
attributes. Similarlywhen
viewing
the context for a data source or data receiver thesystem
will report meta-attribute assigrunents at the highest level that it can.Thus
itmay
be
thatwhen
entering the context of a given data source the user will individuallyassert that all the financial attributes are in
US
dollarsbecause
shedoes
not see the pattern.However,
when
the context is displayed it willshow
thatallMoney-Amounts
have
the meta-attributecurrencysetto [US$].4.1.5
Underlying
Representation System:LOOM
The
system
thatwe
use forimplementing
theabove
taxonomy
is a generalpurpose taxonomic
knowledge
representationsystem
calledLOOM
[MacGregor,
" Thiswould
mean
country oflocation of theheadquartersofthecompany.1991],
which
isimplemented
in LISP.LOOM
isdesigned
to allow for the representation of a great variety of concepts, entities,and
relationshipsbetween
them.
However,
we
use only a small fraction of thepower
thatLOOM
provides inour
current implementation.Our
reasoning in choosingsuch
a vastsystem
was
tohave
themaximal
expressive capabilities atour disposaland
then tolater redesign thesystem
for efficiencyby removing
all the features thatwere
not importantorthatwe
did not use.In
LOOM
and
the description logicsview
of things, theworld
consists ofa setofentities
which
canbe
either abstractor concreteand
consists ofall the things thatthe user is interested in reasoning about.
These
entities are thenbroken
up
into various subsetswhich
are called concepts.Thus
inknowledge
representationsystems
it is crucialwhen
reasoningabout
concepts to alsobe
aware
ofwhat
exactly is the setofentities that the concept denotes.
The
lastpiece of theLOOM
view
of theworld
iswhat
are called roles. Roles aretwo
place predicatesand
thus are true for
some
setofordered pairs ofentitiesand
false for all other pairs.In
our implementation
meta-attributes areimplemented
inLOOM
as roles.The
following is asample
ofLOOM
code
that isused
to represent the localcontext forthe receiverinFigure9 (i.e.,the
Worldscope
context):(defconcept WrldScp-Annual-Fin-Attributes :is-primitive Db-Attribute)
(tellm (:about WrldScpAF Worldscope-Relation (:filled-by has-attribute 'WrldScpAF-CompanyName 'WrldScpAF-LatestAnnualDate 'WrldScpAF -CurrentOutstandingShares 'WrldScpAF-Netlncome 'WrldScpAF-Sales 'WrldScpAF-TotalAssets) ) )
(defconcept
WrldScpAF-CompanyName
:is-primitive Company-Name)(defconcept WrldScpAF-LatestAnnualDate : is-primitive Latest-Annual-Date)
(defconcept WrldScpAF-CurrentOutstandingShares :is-primitive
Shares -Outstanding)
(defconcept WrldScpAF-Netlncome : is-primitive
(:and Net-Income
(:filled-by scale-factor times-1000) ) )
(defconcept WrIdScpAF-Sales : is-primitive
( :and Sales
(:filled-by scale-factor times-1000)))
It is
important
to note thatsome
of the local context is inheritedfrom
parentconcepts. For example,
currency
= [US$] is inheritedforWorldscope
money
amounts
(e.g., SALES).4.2 Conflict Detection
Although
LOOM
provides a greatmany
services to the user, unfortunately conflict detectionbetween
differing context definitions is notamong
them,
therefore
we
have
built aLISP
program
that interactswith
LOOM
toperform
conflict detection
and
produces
the attributemap
and
the conflict table asshown
inFigure8
and
described in thissection.4.2.1 Attribute
Maps
The
attributemap
is essentially a table thatpairs attributesfrom
one
node
with
attributes
from
another node. For theexample
of Section 2 the attributemap
would
be
as followslast line in the table
simply
states that the scale factoron
theSALES
and
NET-INCOME
attribute is 10^3 in the source databaseand
only 1 forthe receiverand
that those scale factor settings are notdependent
on
anything elseand
thusthe predicate is
always
true. For theNET-INCOME
requestedon
Daimler-Benz
of
Germany,
thefirstand
fourth linesof thetableare used.Fortunately the generation of this table, in principle, is also reasonably simple.
For
any two
attributeswhich
have been
paired in a attributemap we
go
to theconcept in the
taxonomy
towhich
theyhave been
linkedand
compare
how
thesource
and
receiverspecify their meta-attribute settings. If the settings disagreeand
the settings of the values are"independent"
as discussed in Section 4.1.4 thenwe
place a simple entry in the table (similar to the last line in the tableabove). If the setting of the meta-attribute value uses a closed data
dependency
then thecondition isplaced in thepredicate line.
4.3
Context-Based
Query
Processing
In this section
we
describehow
aquery
from
the receiver are resolved in thereceiver's context.
The components
ofthis process areshown
in thebottom
halfofFigure 8beginningwiththe
Query
ProcessingController .4.3.1
Query
Processing Controller(QPC)
This
module
controls all othercomponents
of thequery
processing engine aswell as
provides an
interface to external data sourcesand
receivers.The
controller maintains the state of execution of a query. This state includes
node
names, passwords,
and
execution states. It also retrieves essential informationfrom
the conflict detector regarding conflictsbetween
nodes
in theform
of aconflicttable
and an
attributemap.
4.3.2
Query
Optimization
The
optimizer is a Selinger-style [Selinger, 1979]query
optimizer(implemented
in
C++
with
toolsfrom
[Corporation, 1993]) that generatesan
optimalquery
execution plan givenan
SQL
statement, a conflict tableand
an
attributemap.
Queries
that are directedthrough
theQPC
aredecomposed
into the primitiveoperators (e.g. selection filters, joins, projections).
Furthermore, conversion
operators are generated for each conflict in the conflict table that relates to the active query.The
context-basedquery
optimizerdetermines
the location of selectionsand
joins (i.e. conventionalquery
optimization),and
incorporatesconversion filters into the
query
plan (i.e. conversion-based optimization).Each
operator,
has
two
distinct sets of properties, physicaland
logical properties. Physical properties include thecostofthe operatorand
the applicablealgorithms toimplement
the operators. Logical properties describe the logical effect of theoperator
on
adata set.Conversion
operators are inserted intotheplan to assurelogical consistency(e.g., join attributesmust
be
in thesame
context, selection constantsand
attributesmust
have
thesame
contextand
output
datamust
be
in the receiver context).Hence,
ifa conflict existson
the attributeSALES
thenno
operator canbe
appliedon
SALES
without
a conversion ofSALES
data.The
identity of conversionfunctions are
provided
in the conflict table.Also
identified is the existence ofinverse conversion function.
A
conversion function {Fn) (i.e., thesource-to-receiverconversion function) has
an
inverse (Fn'^) if theinverse function{Fn'^
can
be used
to transform a predicate in the receiver'squery
into the contextexpected
by
the source (i.e., receiver-to-source conversion).The
presence of inverse conversions willbe
shown
tobe
very important in the optimization of process.The
optimal execution is generatedby
exhausting all possiblecombinations
of operator nodes in the plan. All plans that are not logically consistentwith
the originalquery
arepruned.
Appropriate
physical algorithms areattempted
for each operatorofthe planand
the resultingcosts arecalculated.The
optimalplanisselected
from
the possible planson
acostminimizing
basis.The
optimizer isimplemented
inC++
and
is extensible tohandle
additionaloperators
and
changes
to cost functions.Each
node
in the optimizercan
have
multiple algorithms associatedwith
it as well as separate costsbased
on
those algorithms.An
illustrativeexample,
based
on
the scenario described in Section 2, ofquery
optimization is described below.The
user requests current shares outstanding,sales
and
netincome
information for theGerman
company
Daimler-Benz
AG
from
the Disclosure database generatingthe followingSQL
statement:Select
COMPANY-NAME,
CURRENT-SHARES-OUTSTANDING,
SALES,
NET-INCOME
From
DisclosureWhere
COMPANY-NAME="DAIMLER-BENZ
AG"
And DATE=1
2/31/93Both
theNET-INCOME
and
SALES
attributes are represented inGerman
Marks
in the Disclosure databaseand
they alsohave
a scale factor of 1000.The
datareceiver prefers her sales
and
netincome
figures tobe
inUS
Dollarswith
a scalefactor of 1.
Furthermore,
the receiverand
source differon
thenaming
convention
used
forcompany names
(i.e. receiver:"DAIMLER-BENZ
AG",
source:
"DAIMLER
BENZ
CORP").
Figure 10
shows two
ofthequery
trees generatedby
the optimizer.The
trees arenon-dependent
sequential treeswith
data flowingfrom
thebottom
(i.e. data atthe source) to the top (i.e.
output
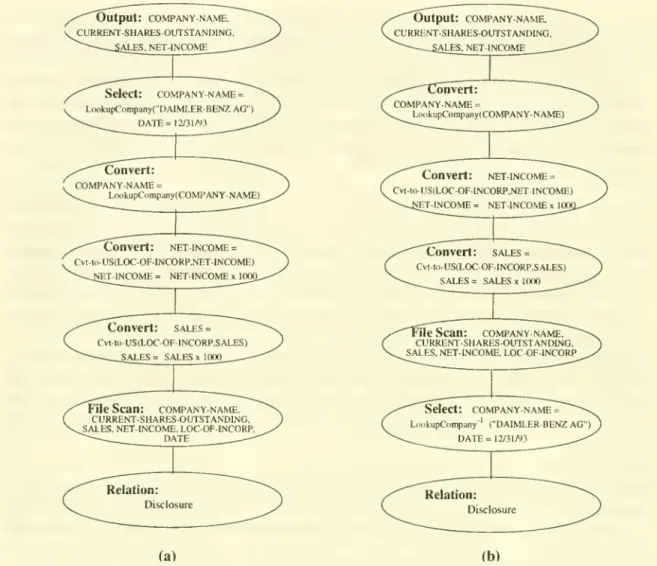
to the receiver). Figure 10(a) depicts asuboptimal
execution plan for thequery
described above.The
Relation
node
signifies the relation Disclosure
on
disk.The
FileScan
node
retrieves relevantattributes
from
Disclosure.The
relevant attributes include: all attributes presentinthe
output
list ,all attributes inthepredicate of theSQL
statement (e.g.,DATE)
as well as
any
attributes required for a conversion function (e.g.,LOC-OF-INCORP
todetermine
the currency).The
tree then incorporates threeConvert
nodes, for the attributes
COMPANY-NAME,
NET-INCOME
and SALES,
that ensure that outputto the receiverhasbeen
converted to hercontext.The
Selectnode
isan
operator that filters out the records for thecompany
Daimler-Benz
and
for the 1993 fiscal year.The
Output node
is the finalnode
in thequery
treeand
signifies the presentation of the results ofthequery
to the user.Hence,
thetree in Figure 10(a) describes the process of reading all data
from
the Disclosurerelation, convertingall the data
and
thenfiltering outthosedata ofinterest tothereceiver.
In Figure 10(b)
shows
an
optimal plan.At
thebottom
ofthe tree is a Relationnode
indicating the Disclosure relation as in Figure 10(a).However,
the Selectnode
precedes the FileScan
node
in thisquery
treeand
containsan
inverseconversion function applied tothe valueofthe
COMPANY-NAME
attribute (i.e.,converting to the Disclosurecontext).
The
selection filter cannow
be
applied asthe data is being
scanned
by
the FileScan
operation atminimal
extra cost (ascompared
to a cost proportional to the size of the relation).The
COMPANY-NAME
must
be
convertedfrom
the source context to the receiver context beforeoutput
tothe receiver.The
query
tree in Figure 10(b) clearlyhas lower cost thanthe tree in Figure 10(a) because the
number
of recordson which
conversions areperformed
is significantlyreduced
by
placing the Selectnode
before the conversions.More
complex
queries arehandled
in a similarmanner.
Joinsbetween two
sources necessitate transformations to the context of either source or another
common
contextbeforejoinattributes canbe compared.
All threetechniques areattempted
and
themost
efficient ischosen based
on
the size of thetwo
source relationsand
the attributesrequired in thequery
output.Output: COMPANY-NAME. CURRENT-SHARES-OUTSTANDING, SALES,NET-INCOME Select: company-name= LookupCompany("DAIMLER-BENZ AG" ) DATE=12/31/93 COMPANY-NAME= LookupCompaiiy(COMPANY-NAME) Convert: net-income= Cvl-to-USaOC-OF-INCORP,NET-INCOME) JJET-INCOME= NET-INCOMEx 100(L, Convert: sales= Cvt-to-US(LOC-OF-INCORP.SALES) SALES= SALESX1000
FileScan: company-name,
CURRENT-SHARES-OUTSTANDING,
^SALES,NET-INCOME,LOC-OF-INCORP
DATE Relation: Disclosure Output: COMPANY-NAME, CURRENT-SHARES-OUTSTANDING, SALES.NET-INCOME ^onvert: COMPANY-NAME= LodkupCompanytCOMP/VNY-NAME) Convert: net-income Cvl-to-US(LOC-0F-lNCORP,NET-INCOME) ET-INCOME= NET-INCOMExI Convert: sales= Cvl-lo-US(LOC-OF-lNCORP,SALES) sales= SALESX1000
FileScan: company-name.
CURRENT-SHARES-OUTSTANDING,
SALES,NET-INCOME.LOC-OF-INCORP
Select: company-name=
LiiokupCompany' ("DAIMLER-BENZAG")
DATE=12/31/93
Relation: Disclosure
(a) (b)
Figure10: PossibleExecutionPlans(a)sub-optimal,(b)optimal.
4.3.3
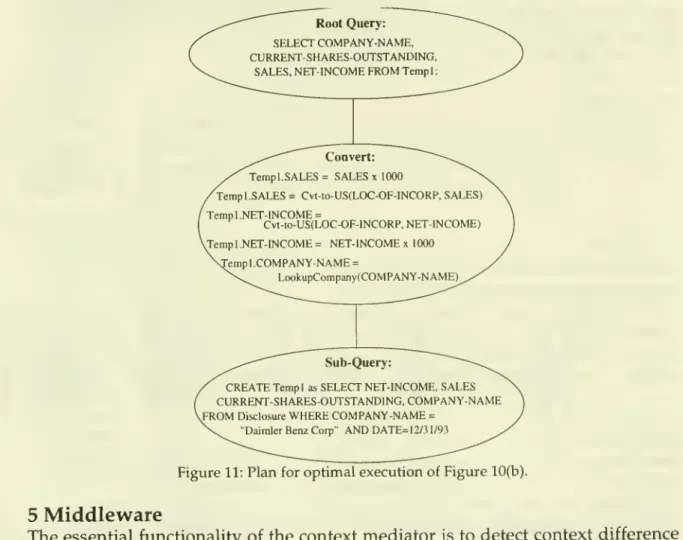
Data
Retrievaland
Conversion
The
execution plan representation in the optimizer is genericand
does
notcorrespond
to a specificquery
language. In the data retrieval stage, the plangenerated
by
the optimizer is transferred intoSQL.
Operator
nodes
below
aConvert
operator are transformed intoan
SQL
subquery,and
results are storedin
temporary
tables (see Figure 11).Conversion
routines are applied to thetemporary
tablesand
subsequent
queries areperformed
on
thetemporary
tables.The
finalRoot
Query
returnsdata tothe receiver.The
contextmediator supports
threeforms
ofconversion
functions.These
functions include:mathematical
functionsimplemented
in C-I-+;lookup
functions
implemented
asSQL
queries;complex
functions requiring interactionwith
the context repository.Figure 11
shows
theSQL
execution plan generatedfrom
thequery
trees inFigure 10.Data
flowsfrom
thebottom
(the data source) to the top (data receiver) in thetree
shown
inFigure 11.The
bottom
node
in Figure 11 isan
SQL
query
tobe
sentto the Disclosure database, the results of
which
are stored intemporary
storage.Tempi,
under
the control ofthequery
processingcontroller.Note
thatthequery
hasbeen modified
by
the conversion of the constant"DAIMLER-BENZ
AG"
to"DAIMLER
BENZ
CORP"
through
the use of the inverse conversion functionLookupCompany-^O.
The
conversionson
COMPANY-NAME,
SALES
and
NET-INCOME''
areperformed
on
data inTempi
. Finally, after all conflictshave
been
resolved
an
SQL
query
isapplied toTempi
to retrievetheattributes requestedby
the user.
RootQuery: SELECTCOMPANY-NAME,
CURRENT-SHARES-OUTSTANDING, SALES,NET-INCOMEFROMTempi,
Convert: Templ.SALES= SALESx1000
'Templ.SALES= Cvt-to-US(LOC-OF-INCORP,SALES) Temp1.NET-INCOME=
Cvt-to-US(LOC-OF-INCORP,NET-INCOME)
\Temp1.NET-INCOME= NET-INCOMEx1000
[empICOMPANY-NAME=
LookupCompany(COMPANY-NAME)
Sub-Query:
CREATETempi asSELECTNET-INCOME,SALES
CURRENT-SHARES-OUTSTANDING,COMPANY-NAME VFROMDisclosureWHERECOMPANY-NAME=
"DaimlerBenzCorp" ANDDATE=12/3 1/93
Figure11:PlanforoptimalexecutionofFigure 10(b).
5
Middleware
The
essential functionality of the contextmediator
is todetect context differencebetween
sourceand
receiver, transform queries accordingly,and
apply
all necessary conversionsto the output.Most
applications, previouslyimplemented and
currentlybeing implemented,
did nothave
provisions for context mediation.An
example
ofsuch an
application isshown
in Figure 12. Thiscorresponds
to theData
ExtractionAppUcation
described in Section 2with
the Client Receiver Applicationsbeing
^Note that conversion of the scale factor in
SALES
andNET-INCOME
could have been performed by adding the function to the target list of the subquery (i.e.CREATE
Tempi
asSELECT
NET-INCOME*1000,SALES
*1000 ... ). However,ourcurrentimplementation does nottakeadvantageofttiisfeaturein
SQL
.implemented
usingPowerbuilder
and
the SourceDatabase
Management
System
being
two
Oracle servers,one
holding theWorldscope
databaseand
the other holding the Disclosure database.One
ofour
goals is tobe
able to incorporate contextmediator
capabilities intosuch
a situation in a non-intrusiveway,
that is,without
requiringany change
tothe existing applications or the servers. Besides the
obvious
benefits ofsuch
an
approach, thatis eliminating the laboreffortof convertingexisting software, it isoften a practical necessity
because
either the receiverenvironment
or sourceenvironment
(sometimes
both)may
be
outside the receiver's control (i.e.,controlled
by
other organizations or unrelated parts ofyour
own
organization).Thus,
changes
many
notbe
allowed.A. Initialstate
~7L
Client
B.Inclusion ofContext Mediator Middleware
The
contextmediator
hasbeen
implemented
inC++
and Loom.
The
Loom
portion handles the context repository
and
conflictdetectionmechanisms
for thecontext mediator.
The
C++
portion includes thequery
parser, the conversionbased
optimizerand
aquery
execution unit.5.2
Open
Database
Connectivity(ODBC)
The
contextmediator
engine is intended to provide seamless contextconversionbetween
applicationsand
databases.Hence,
the mediator uses theODBC/API
(Open
Database
Connectivity/ApplicationProgramming
Interface) [Microsoft,1994]
which
isan
accepted industry standard.The
ODBC/API
includes a largeamount
of function specifications that fallunder
threemain
categories: (a)Connection
Setup, (b)Query
Submission
and
(c)Data
Retrieval. Receiver contextis
determined during
connection setupand
is a function of the clientapplicationand
the user.The
query
submissionstage isessentially unalteredfrom
any
other application,however,
internally, queries are redirected to the contextmediator
rather thanthe source specified
by
the user. Finallydata returned in theretrievalstagewill
have been
modified tocomply
withthe receiver'scontext.5.3
Legacy
and
othernon-ODBC
SourcesIn reality, a
tremendous
amount
of current data is innon-ODBC
sources, often referred to as "legacy systems".These
arenon-ODBC
for several possible reasons: (1) they pre-datemodern
relational database technology (e.g.,IBM
IMS)
and
/orbased
on
some
proprietary technology, (2) they arenot designed to allow for direct databasequery
access, eitherdue
to oversight, different goals, or as aform
of protection,and
only allow accessthrough an
interactive user interface (e.g.,many
onlineservices), or (3) theyhave chosen
to support another standardAPI
otherthanODBC.
Oftenseveral ofthesereasons applysimultaneously.To
dealwith
these situations,we
have used
variouscommercial
tools [Corporation, 1993] todevelop
ODB-adapter
middleware.
These
aresometimes
referred to as"wrappers"
or "screen scrapers",we
will use theterm
"connectivity
middleware."
Referring to Figure 14b, there isan
additional layerof
middleware between
the contextmediator
and
the source.The
connectivitymiddleware
presentsan
ODBC
interface to the contextmediator but
presents aspecialized interface tothe source,as exemplifiedbelow.
The Worldscope
dataused
in theexample
of Section 2 is actually available inseveral forms,
we
have used
two
forms: (1) aCD-ROM
of quarterlyupdated
datawhich
was
loaded into an Oraclerelational databaseand
(2) continuallyupdated
data is available asan
online servicewhich
can onlybe
accessedthrough an
ASCII
textmenu
selection interface (e.g.,you
are asked, "Please entercompany
name",
aname
such
as"Daimler-Benz"
is entered,and
then a fixed format textreport isdisplayed
such
as"NET
INCOME
346,577,SALES
56,268,168" etc.)The Worldscope
connectivitymiddleware
thatwe
have
constructed allows us to use either source in exactly thesame
manner,
asODBC
sources, although there are differences inspeed, cost,and
updatenessofthedata.5.4 Future
needs
of theInformation
SuperHighway
The
topic of the "hiformationSuperHighway",
or itscurrentform
as the Internet, has received considerable attention ingovernment,
business,academic,
and
media
circles.Although
amajor
point of interest has focusedon
the rapidlyincreasing
number
of users,sometimes
estimated as 20 millionand
growing,
an
even
more
important
issue is the millions of information resources that willbe
accessible.
Today,
when
peopletalkabout "surfing the 'net", theyare usually referring to useof the
World
Wide
Web
(WWW)
through
some
user friendly interface,such
asMosaic
or Netscape. This type of activity can be effective for casualusage
and
requires significant
human
intervention for navigation (i.e., locating theappropriate sources)
and
interpretation (i.e., readingand
understanding
theinformation found.)
On
the otherhand,
let us consider the opportunityand
challengesposed
by
exploiting these global information resources in
an
integratedmanner.
Let usassume
that informationfrom
the various stockexchanges
(possiblywith
adelayed
transmission for regulatory purposes)and
weather
servicesaround
theworld
are accessible. (Note:They
can
be
adapted
for useby
techniques described in Section5.3 without requiringany change
to the source.)You
might
want
toknow
the current value ofyour
international investments,which
might
require access to multiple
exchanges
bothin theUSA
(e.g.,NYSE,
NASDAQ,
etc.)and
overseas(London,
Tokyo,
etc.)You
might
want
toknow
where
are the bestski conditions at resorts
around
the world.To
manually
accessand
interpret thenumerous
information sources relevant to thesequestionswould
rapidlybecome
impractical. Furthermore, it is highly unlikely that all these sources
would
have
the
same
context giventheirautonomous
and
geographically dispersed nature.The
three-tiermiddleware approach
provides theopportunity
to introduce contextmediation
services intosuch
an
environment
inan
incremental,evolutionary,
and
non-intrusive (orminimally
intrusive)maimer.
Such
serviceswill
be
crucial to the effective, efficient,and
correct use of information resourcesmade
availablethrough
theInformationSuperHighway.
6.
Conclusions
In this
paper
we
have
describedan implementation
of aContext
InterchangeNetwork
tosupport
semanticinteroperabilityamong
heterogeneous sourcesand
receivers.
The
CIN
utilizes a declarativeapproach
to contextknowledge
(i.e.,rather
than
embedded
in code,manuals,
or theminds
of users). Itsupports
automatic detection of semantic conflicts
and
where
possible the translation of the conflicts to providethe receiverwithmeaningful
information (i.e., data in thereceivercontext).
The
CIN
also supports the explication of data context;allowing forintelligentinformation browsing.The development
of this prototype hasprovided
considerable insight intoimportant
research areas. First, there is atremendous
requirement
for designmethodologies
and knowledge
acquisition tools for thedevelopment and
maintenance
of shared ontologiesand
local context definitions.Our
current ontologywas
developed
to supportthe integration ofeightfinancialdata sourcesand
assuch
was
developed, for themost
part, in abottom-up
approach.Data
objects
were
constructed to allow formapping
of the three databases currentlyused
in the implementation. Realworld
conceptswere added
tosupport
meta-attributes.Some
additional conceptswere added
tosupport understanding
of data structuresand
further explication. Thisproved
tobe
avery timeconsuming
process
without
an
apparent optimal strategy. Current effortare being spenton
developing
a user interface to support defining, browsing,and
editing the localcontext
knowledge,
the sharedontologyand
mappings
between
the local contextdefinitions
and
theshared ontology.Second, the
implementation
needs
tobe extended
tosupport
more
complex
context
knowledge and
conflict reconciliation.The examples
in thepaper
oversimplify the current capabilities but at thesame
timewe
are studying theneed
for theability to betterrepresentboth derived (e.g.,eamings-per-share)and
combined
(e.g., address, date) dataand
to reconcile differencesbetween
these types. Part of this process includes current efforts indeveloping
acommon
theory forcontextdefinition, ontologiesand
databases.Thirdly, the current
query
optimizerworks
mostly
on
compile-time conflictknowledge.
As
shown
in [Siegel&
Madnick,
1991],many
of the contextconflictscan
onlybe determined
at run-time,some
of the capabilities todo
run-timecontextchecking
have been
incorporatedbut further analysis of theoptimization process isneeded
tofully supportthis capability.Finally,
we
aredeveloping toolsand methodologies
to supportsystem
evolutionand
scalability (e.g., the use of multiple shared ontologies).These approaches
will
have
significantimpact
on
the ability for currentand
future InformationSuper
Highways
to delivermeaningful
informationexchange
among
multitudesof disparatesources
and
receivers.7.
References
[1]
Corporation,
O. E. (1993).OEC
Toolkit 1.1.InOpen
Environment
Corporation.[2]
Goh,
C,
Madnick,
S.,&
Siegel,M.
(1994). Context Interchange:Overcoming
the Challenges of Large-Scale Interoperable Database Systems in a
Dynamic
Environment. In Internationaland
Knowledge
Management
(Ed.), Gaithersbury,Maryland
[3]
MacGregor,
R. (1991).Using
aDescription ClassifiertoEnhance
Deductive
Inference. ProceedingsofSeventh
IEEE
Conference onAI
Applications, (pp. 141-147)Miami,
Florida.[4] Microsoft (1994). Microsoft's
ODBC
2.0: Programmer's Referenceand
SDK
Guide. InMicrosoftPress.
[5] Selinger, P., et. al. (1979). Access Path Selection in a Relational
Database
Management
System.
Proceedings ofthe 1979ACM-SIGMOD
International Conferenceon theManagement
ofData, (pp. 23-34) Boston,MA.
[6] Siegel,
M.
&
Madnick,
S. (1991).A
Metadata
Approach
toResolving
Semantic
Conflicts. Proceedings ofthe 17th International Conference on Very LargeDatabases, Barcelona, Spain.
[7]
Woods,
W.
A. (1985).What's
in a Link:Foundations
forSemantic
Networks.
In Readings in KnowledgeRepresentation.Los
Altos, California:Morgan
Kaufmann
Publiser's Inc.MIT LIBRARIES
39080 00927 8786