Computational aspects of prospect theory with asset pricing applications
15
0
0
Texte intégral
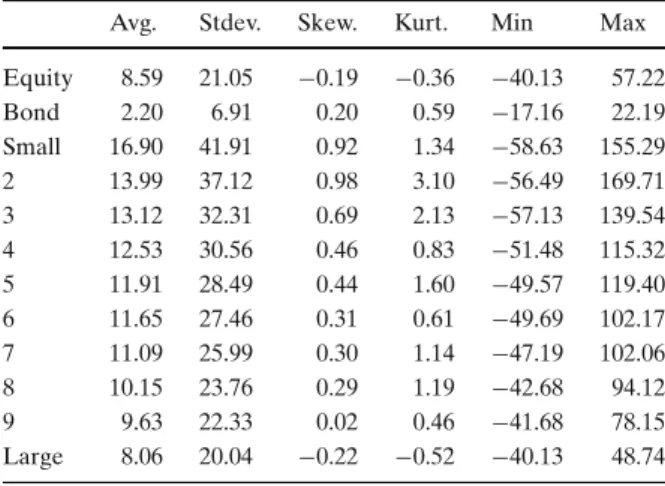
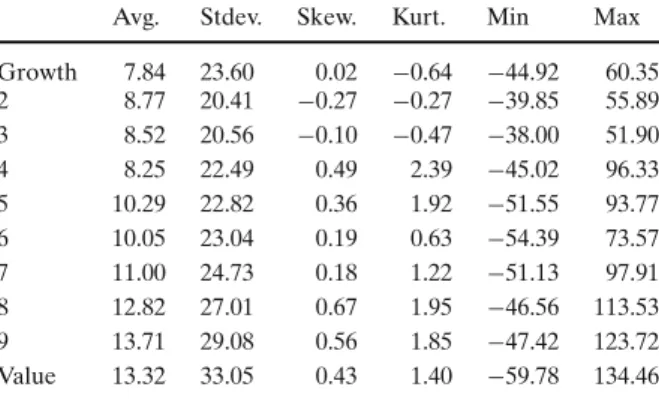
Figure

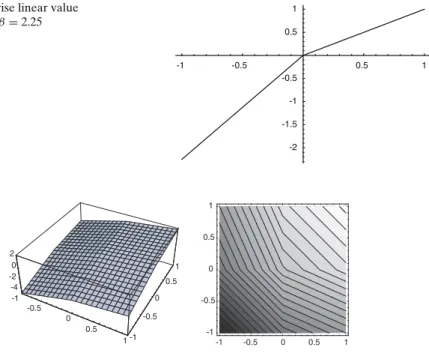
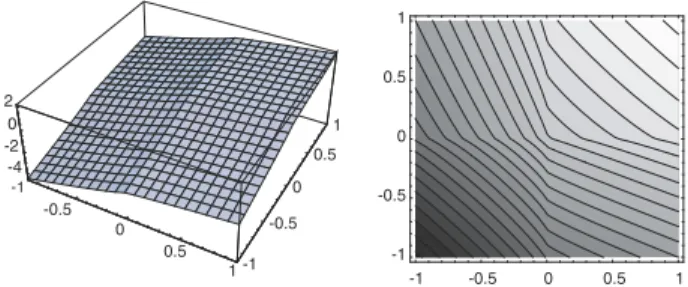
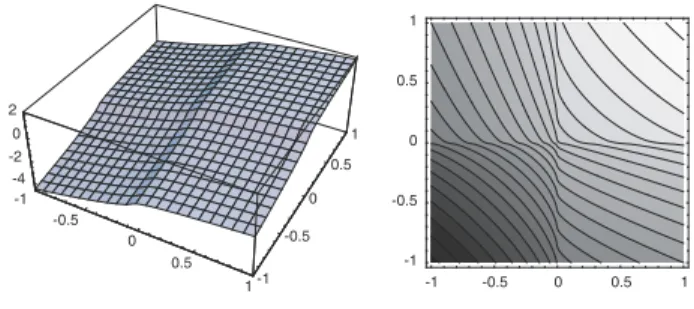
+4
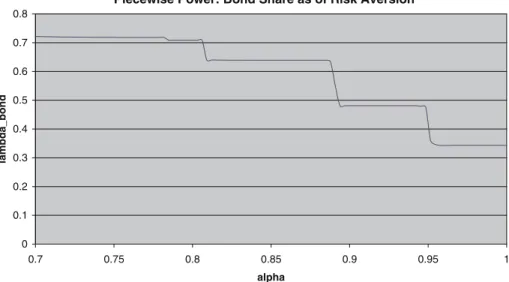
Documents relatifs