Decentralized Teaching and Learning in Cooperative
Multiagent Systems
by
Shayegan Omidshafiei
S.M., Massachusetts Institute of Technology (2015)
B.A.Sc., University of Toronto (2012)
Submitted to the Department of Aeronautics and Astronautics
in partial fulfillment of the requirements for the degree of
Doctor of Philosophy
at the
MASSACHUSETTS INSTITUTE OF TECHNOLOGY
September 2018
@
Massachusetts Institute of Technology 2018. All rights reserved.
Signature redacted
A uthor ...
...
(
Department of Aeronautics and Astronautics
August 23, 2016Certified by...Signature
redacted
Jonathan P. How
R. C. Maclaurin Professor of Aeronautics and Astronautics, MIT
Certified by.
Certified by.
Signature red acted
ThesisSupervisor
...
.. .. .. .. s.
..
Christopher Amato
Assistant Professor, Nortii astern University
...
Signature redacted
.
--Sertac Karaman
C. S. Draper Assistant Professor of Aeronautics and Astronputics, MIT
Accepted by...
Signature redacted
Hamsa Balakrishnan
ksAc-HUES INSTITUTE
OF TECHNOLOGY
Associate Professor of Aeronautics and Astronautics
I I
1Chair,
Graduate Program Committee
ULC
U19
Z1
LIBRARIES
ARCHIVES
MITLibraries
77 Massachusetts Avenue Cambridge, MA 02139 http://Iibraries.mit.edu/ask
DISCLAIMER NOTICE
Due to the condition of the original material, there are unavoidable
flaws in this reproduction. We have made every effort possible to
provide you with the best copy available.
Thank you.
The images contained in this document are of the
best quality available.
Decentralized Teaching and Learning in Cooperative
Multiagent Systems
by
Shayegan Omidshafiei
Submitted to the Department of Aeronautics and Astronautics on August 23, 2018, in partial fulfillment of the
requirements for the degree of Doctor of Philosophy
Abstract
Cooperative multiagent decision making is a ubiquitous problem with many real-world
applications, including organization of driverless car fleets [1, 2], target surveillance
[31,
and warehouse automation [4-6]. The unifying challenge in these real-world settings is the presence of domain stochasticity (due to noisy sensors and actuators) and partial observability (due to local perspectives of agents), which can obfuscate the underlying state. In many practical applications, it is desirable for teams of agents to be capable of executing well-coordinated policies despite these uncertainty challenges.
The core assumption of standard multiagent planning approaches is knowledge of an accurate, high-fidelity environment model. In practice, models may be unavailable or inaccurate. In the former case, models necessary for planning-based approaches must be generated or learned (which may be difficult and/or expensive). In the latter, execution of policies optimized for incorrect models may have dire economic and/or social consequences for systems deployed in the real world. While many works have introduced learning (rather than planning) approaches for multiagent systems, few address the partially observable setting, and even fewer do so in a scalable manner deployable to real-world settings, such as multi-robot systems that face collections of tasks [7J.
The primary objective of this thesis is to develop technologies for scalable learning-based coordination in multiagent settings. Specifically, this thesis introduces methods for hierarchical learning of models and policies that enable multiagent coordination with more realistic sensors, execution in settings where underlying environment contexts may be non-unique or non-stationary, and acceleration of cooperative learning using inter-agent advice exchange. The algorithms developed are demonstrated in a variety of hardware and simulation settings, including those with complex sensory inputs and realistic dynamics and/or learning objectives, extending beyond the usual task-specific performance objectives to meta-learning (learning to learn) and multitask learning objectives.
Thesis Supervisor: Jonathan P. How
Acknowledgments
1800 days: a rough count of my time as a graduate student at MIT. The small details
of what I did on each of those days are mostly forgotten - and likely unimportant. Of
course, many papers were written, experiments run, and hardware demos conducted; yet they all seem far less important than the many professional and personal interactions
I was lucky to take part in over these 1800 days. This thesis was made possible mainly
due to these interactions with my mentors, peers, friends, and family, who not only supported me, but also inspired me throughout these years. I owe a lot to them all.
First, the biggest thanks goes to my advisor, Professor Jonathan How. Jon has been an incredible mentor, providing insightful feedback with an uncanny ability to pinpoint areas of improvement, critical weaknesses to address, and strengths to highlight in my work. He was patient and supportive through the numerous twists and turns of my research over the last few years. Jon, thank you for your invaluable guidance and support. It truly means a lot and I look forward to many years of continued collaboration with you in the future.
I'd also like to extend a special thanks to my thesis committee members, Professor
Christopher Amato, Professor Sertac Karaman, and my thesis proposal evaluator Dr. Ali-akbar Agha-mohammadi. These three gentlemen were among my first senior
mentors at MIT - Chris and Ali postdocs in our lab at the time, and Sertac the
instructor of the first graduate course I took at MIT. My respect for them has only grown over these last five years, and I consider them lifelong advisors and friends. Many thanks, also, to my thesis readers Dr. Kasra Khosoussi and Dr. Golnaz Habibi, whose feedback was crucial through the writing of this thesis. A note of thanks, especially, to Kasra for his continued friendship and witty conversations that kept us energized through the longer days.
Over the last five years, I've been incredibly lucky to meet a large number of bright researchers at MIT, who continue to impress me each day, and with whom I share the most fond memories. Brett, Michael, and Shih-Yuan, thanks for the many (many many) hours spent working on hardware demos together, even when they were at
times not directly a part of your own research. More importantly, thanks for the fun and unforgettable banter that made even the toughest days enjoyable. Thanks to my recent close collaborator, Dong-Ki. When I first spoke with you last year, I noted a rare creative research spark and excitement that immediately stood out. You're
now well on your way to being a fantastic researcher and student of science - looking
forward to hearing of your continued success! Steven and Jason, thanks for being great friends and fun travel companions to the many conferences we went to throughout the years. Special thanks also to ACL alum, Miao, with whom I've collaborated frequently these past few years. Many thanks also to our lab alum, Kemal, Jack, Trevor, Mark, Luke, and everyone else for making me feel at home when I first joined the lab.
My wonderful parents, Saied and Sara, made a lifetime of sacrifices to support and
encourage me, including giving me opportunities not available in our home country by emigrating to Canada. I'm not sure where I would be without them. Thank you for everything. As I wrap up my studies, my sister Goli begins hers as an undergraduate. Goli, to say I am proud of you would be an understatement. I'm excited to hear of your inevitable future successes!
Most importantly, I'd like to thank my wonderful girlfriend Leanne. While it may seem an exaggeration to readers of this thesis, I have to say this work is as much Leanne's as it is mine. A great many hours of support, sacrifice, and endless encouragement from Leanne have made these years fly by. Seemingly a lifetime ago, in the acknowledgments of a different thesis, I thanked you for being there for me, for being someone I look forward to seeing each day after work, and for being the one who made me feel at home in Boston; all of these still stand today, just to the n-th degree. I'm so incredibly excited for the next chapter of our lives together in Paris! Special thanks also to Leanne's amazing parents and family for all the years of support.
Thanks everyone for these wonderful 1800 days!
This work was funded by The Boeing Company, ONR MURI Grant N000141110688, BRC Grant N000141712072, and the MIT-IBM Watson AI Lab initiative.
All life is problem solving.
Karl Popper
But they are useless. They can only give you answers.
Contents
List of Figures List of Tables 1 Introduction 1.1 O verview. . . . . 1.2 Problem Statement . . . .1.2.1 Learning & Integration of Complex Sensor Models in Multiagent
Decision Making Frameworks . . . .
1.2.2 Multiagent Multitask Learning . . . .
1.2.3 Accelerating Multiagent Learning by Learning to Teach
1.2.4 Sum m ary . . . .
1.3 Literature Review . . . .
1.3.1 Multiagent Formalisms . . . .
1.3.2 Decision Making under Uncertainty . . . .
1.3.3 Multiagent Reinforcement Learning . . . .
1.3.4 Transfer and Multitask Learning . . . .
1.3.5 Hierarchies and Abstractions . . . .
1.3.6 Skill Transfer via Teaching . . . .
1.4 Thesis Contributions & Structure . . . .
1.4.1 Contribution 1: Embedding Complex Observation Models into
Multiagent Decision Making Frameworks . . . .
1.4.2 Contribution 2: Multitask Multiagent Reinforcement Learning
13 15 17 17 18 . . . . 19 . . . . 19 . . . . 20 . . . . 20 . . . . 21 . . . . 21 . . . . 22 . . . . 23 . . . . 24 25 . . . . 26 . . . . 28 29 30
1.4.3 Contribution 3: Learning to Teach in Cooperative Multiagent
Reinforcement Learning . . . . 30
1.4.4 Contribution 4: Hardware and High-fidelity Simulation Demon-strations . . . . 31
1.4.5 Thesis Structure . . . . 31
2 Background 35 2.1 Markovian Formalism. . . . . 35
2.1.1 Markov Decision Process . . . . 35
2.1.2 Partially Observable Markov Decision Process . . . . 36
2.1.3 Decentralized Partially Observable Markov Decision Process . 36 2.1.4 Decentralized Partially Observable Semi-Markov Decision Process 37 2.2 Reinforcement Learning . . . . 40
2.3 Multiagent RL . . . . 41
2.4 Multitask Learning . . . . 42
2.5 Multitask Multiagent RL . . . . 42
2.6 Sum m ary . . . . 44
3 Learning and Embedding Semantic-level Macro-Observations in Dec-POSMDPs 45 3.1 Introduction . . . . 45
3.1.1 Macro-observations . . . . 46
3.2 Sequential Classification Filtering Problem . . . . 47
3.2.1 Problem Definition . . . . 48
3.2.2 Challenges and Limitations . . . . 50
3.3 Learning Semantic Macro-Observations using a Hierarchical Bayesian A pproach . . . . 51 3.3.1 Processing Pipeline . . . . 55 3.4 Experim ents . . . . 56 3.4.1 Simulated Experiments . . . . 56 3.4.2 Hardware Experiments . . . . . . 59 10
3.5 Sum m ary . . . .. . . . . . 64
4 Kernel-based Dec-POMDP and Dec-POSMDP Policies over Contin-uous Observation Spaces 4.1 Introduction . . . .. . . . . 4.2 Learning Finite State Automata Policies ... 4.2.1 Sampling Distribution Degeneracy . . . . 4.2.2 Maximal Entropy Injection . . . . 4.3 Kernel-based Policy Learning . . . . 4.3.1 Stochastic Kernel-Based Finite State Automata . 4.3.2 Algorithm for Learning SK-FSA Policies . . . . . 4.4 Experim ents . . . . 4.4.1 Evaluating Maximal Entropy-Injection . . . . 4.4.2 Experiments in Continuous Observation Domain . 4.5 Sum m ary . . . . 5 Multitask Multiagent Reinforcement Learning 5.1 Introduction . . . . 5.2 Approach Phase I: Single-Task MARL . . . . 5.2.1 Hysteretic Deep Recurrent Q-Networks . . . . 5.2.2 Concurrent Experience Replay Trajectories (CERTs) . . 5.3 Approach Phase II: Multitask MARL . . . . 5.4 Evaluation . . . . 5.4.1 Task Specialization using Dec-HDRQN . . . . 5.4.2 Overview of Domains . . . . 5.4.3 Single-task Learning Results . . . . 5.4.4 Sensitivity of Dec-HDRQN to Hysteretic Learning Rate . 5.4.5 Multitasking using Distilled Dec-HDRQN . . . . 5.5 Sum m ary . . . . 65 . . . . 65 . . . . 66 . . . . 68 . . . . 69 . . . . 70 . . . . 70 . . . . 73 . . . . 77 . . . . 77 . . . . 78 . . . . 83 85 85 86 87 87 91 92 92 92 93 95 96 97
6 Learning to Teach in Cooperative Multiagent Reinforcement
Learn-ing 99
6.1 Introduction . . . . 99
6.1.1 Approach Overview ... ... 100
6.2 Meta-Learning Perspective of Cooperative Learning and Teaching . . 100
6.2.1 M eta-learning . . . . 101 6.2.2 Learning to Teach as a Meta-learning Problem . . . . 101
6.3 LeCTR: Algorithm for Learning to Coordinate and Teach Reinforcement 102
6.3.1 Meta-actions: What type of advice is exchanged? . . . . 103 6.3.2 Meta-observations: What inputs are used for advising decisions? 105
6.3.3 Advising protocol: How is advice exchanged and used? . . . . 106
6.3.4 Meta-rewards: How is advice impact measured? . . . .
6.3.5 Meta-training Protocol . . . .
6.4 Evaluation . . . .
6.4.1 Architecture and hyperparameters . . . .
6.4.2 Empirical validation of Remark 2 . . . .
6.4.3 Comparisons to existing teaching approaches . . . .
6.4.4 Meta-reward comparisons . . . .
6.4.5 Teaching for transfer learning . . . .
6.4.6 Teaching heterogeneous teammates . . . .
6.4.7 Effect of communication cost on advice exchange . . . . .
6.5 Sum m ary . . . .
7 Conclusion
7.1 Summary of Contributions . . . .
7.2 Future W ork . . . .
7.2.1 Online MT-MARL and Inter-agent Transfer . . . . 7.2.2 Hierarchical Teaching and Multitask Learning Extensions .
7.2.3 Extending LeCTR to n-agent Case . . . .
Bibliography 107 109 110 110 .. 111 .. 111 113 114 115 115 116 119 119 121 121 . 122 122 123 12
List of Figures
3-1 Real-time onboard macro-observations. . . . . 47
3-2 Motivating macro-observation example with 3 classes. . . . . 48
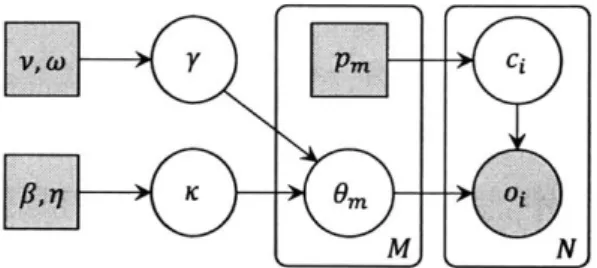
3-3 The HBNI model. . . . . 51
3-4 Inference of high-level noise parameters K, y. . . . . 55
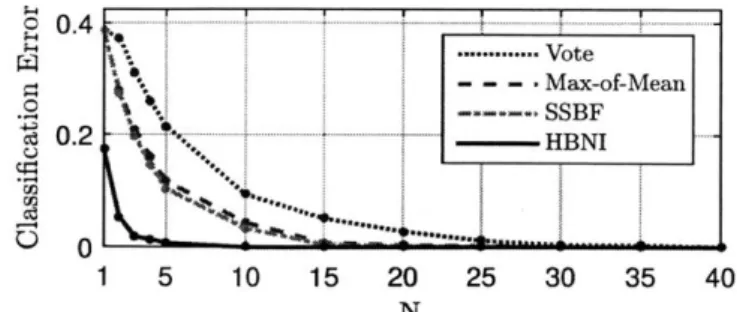
3-5 Sequential classification filtering for the example outlined in Fig. 3-2. 57 3-6 Filtering error for varying observation lengths N. . . . . 59
3-7 Quadrotor platform for perception-based multiagent coordination. . 60 3-8 Comparison of training and test images in domains with varying lighting conditions. . . . . 61
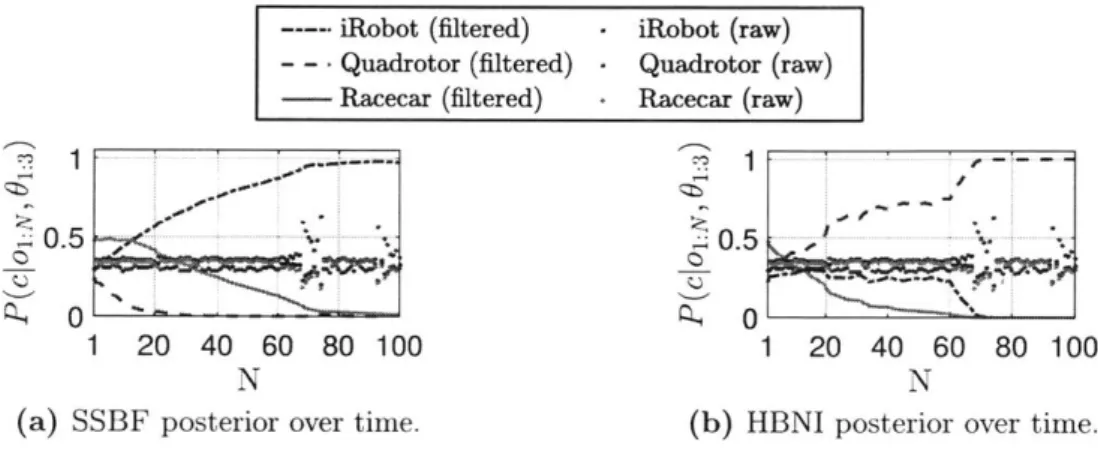
3-9 Comparison of SSBF and HBNI filtering, recorded on a moving quadrotor. 61 3-10 HBNI-based filtered macro-observations onboard a moving quadrotor. 62 3-11 Health-aware multi-quadrotor disaster relief domain. . . . . 63
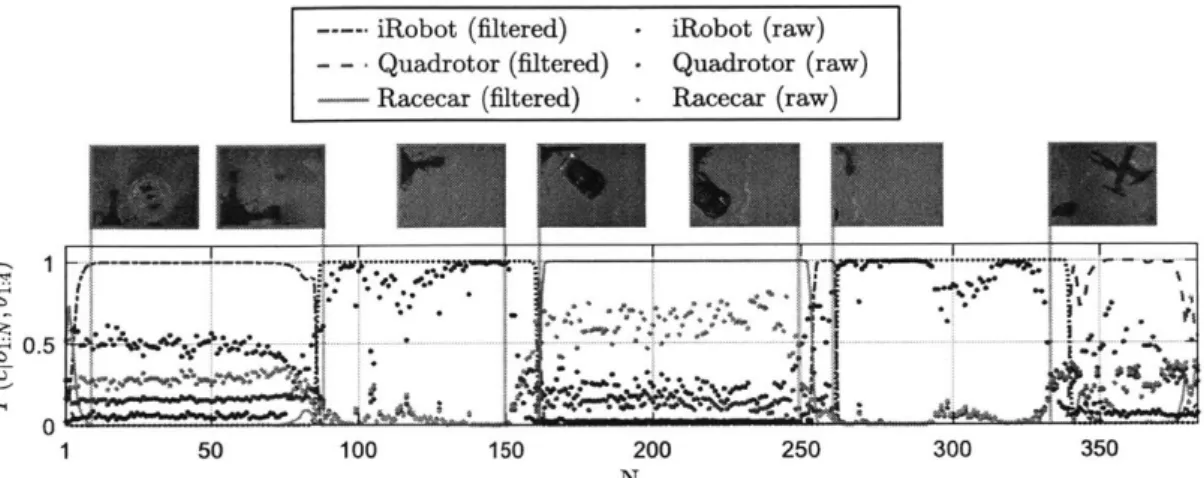
4-1 Overview of continuous-observation decision making using SK-FSAs. . 72 4-2 Comparison of search acceleration approaches for NAMO domain. . . 77
4-3 Continuous-observation nuclear contamination domain overview and corresponding discrete policy results. . . . . 79
4-4 Comparison of discrete and continuous policy search approaches. . . . 80
4-5 Visualization of an N, = 6 node SK-FSA policy transition functions. 82 5-1 Concurrent training samples for MARL. . . . . 89
5-3 Multiagent Single-target (MAST) domain results for Dec-DRQN and
Dec-HDRQN, with 2 agents. . . . . 94
5-4 Task specialization for MAMT domain with n = 2 agents. . . . . 95
5-5 Performance advantage of hysteresis visualized. . . . . 96
5-6 Dec-HDRQN sensitivity to learning rate
3.
. . . . 965-7 MT-MARL performance of proposed approach vs. simultaneous learning. 97 5-8 Multitask performance on MAMT domain. . . . . 98
6-1 Signal flows in meta-learning to teach. . . . . 102
6-2 Repeated game results for learning to teach. . . . . 112
6-3 State-based learning to teach domain overviews. . . . . 112
6-4 Hallway game results for learning to teach. . . . . 112
6-5 Room game results for learning to teach. . . . . 113
6-6 Hallway game, impact of communication cost c on advice exchange.. 115
List of Tables
... ... .-''. , , - -, - - -11,11-1-1-111.1- 1 1- - - 11- 1-1-11--l-II-I-II - -1-1 "-1- - - - - 1-1- 11----"-,--,,,7-"" -. f
Chapter 1
Introduction
1.1
Overview
Many real-world problems involve multiple agents with partial observability and limited
communication [7, 8]. Prevalent examples include networking problems, multi-robot
exploration, and surveillance [9-191. While low-cost robotics platforms and sensors have increased the affordability of multiagent systems, derivation of policies dictating agent decisions remains a challenge due to complex inter-agent and agent-environment interactions. Hand-crafting accurate environment models necessary for policy search in
these domains is especially difficult due to these interactions [7]. This thesis, instead,
focuses on learning-based approaches for multiagent decision making.
The general multiagent decision making problem involves a set of agents in a shared environment, wherein each agent seeks to maximize its local return given streaming local observations [20]. This thesis considers the fully cooperative setting, where a team of agents collects data from the environment, then decides a sequence of local actions to execute to maximize a cumulative shared reward. Autonomous decision making, even in the single-agent setting, is a formidable challenge due to actuation and sensor uncertainties that obfuscate the underlying state. In the multiagent case, decision making is even more challenging as the local viewpoints of agents cause them to perceive the environment as non-stationary due to teammates' concurrent
coordination remains challenging due to the partial observability of agents.
In many practical situations the domain models necessary for policy optimization are unavailable. This necessitates solving of the multiagent learning problem, where underlying models are assumed unknown and agents must instead learn these models and/or associated optimal policies by interacting with the environment. Intelligent agents must, therefore, effectively extract knowledge from past experiences for learning, with the underlying objective being to improve team-wide performance. Critically, learning must be conducted in a stable manner that is robust against destabilization or drop in performance due to the exploratory actions of teammates. This thesis focuses on approaches for learning models and/or policies that enable multiagent coordination in domains with more realistic and complex observation models/sensors, decision making in multitask settings where underlying environment contexts may be non-unique or non-stationary, and communication-based peer-to-peer advising to accelerate team learning.
The subsequent sections describe and provide motivations for the problem scenarios
targeted in this thesis (Section 1.2), review existing literature and gaps (Section 1.3),
and outline the thesis contributions (Section 1.4).
1.2
Problem Statement
The objective of this thesis is to develop learning-based approaches necessary for application of multiagent decision making to problems of real-world scale. Specifically, the thesis introduces approaches addressing the following problems: (i) How to integrate complex sensors (specifically, vision-based and continuous observation models) into the multiagent decision making pipeline? (ii) How to learn to coordinate in multitask settings with latent contextual information that agents must infer during the given mission? (iii) How to learn communication policies that use peer-to-peer advising to accelerate learning and improve team-wide performance. The following sections provide motivations for each of these open problems.
18
1.2.1
Learning & Integration of Complex Sensor Models in
Multiagent Decision Making Frameworks
For autonomous execution of multiagent missions, it is desirable for agents to in-fer contextual information extending beyond the topological data typically used for navigation missions 1221. While use of semantic maps and qualitative environment
representations has been recently explored for intelligent mission execution 123-271,
limited work has been conducted on using complex vision-based sensors for semantic-level multiagent decision making in stochastic domains. The key challenge is that embedding of heuristic labeling rules and rigid, hand-tuned observation models [28] into the planning pipeline is failure-prone and such models require excessive expert knowledge to accurately represent the underlying environment. Moreover, applica-tion of existing scalable multiagent coordinaapplica-tion frameworks, such as hierarchical approaches [291, typically involves observation space discretization, resulting in loss of valuable sensor information that could otherwise be used to better inform the decision making policies. As real-world robot observation processes are highly complex, a core contribution of the thesis is to introduce algorithms for learning and embedding a) semantic-level probabilistic observation processes and b) continuous-observation models in the decision loop, hence addressing the above limitations.
1.2.2
Multiagent Multitask Learning
Learning specialized policies for individual missions (hereafter called tasks) can some-times be severely problematic: not only do agents have to store a distinct policy for each task, but in practice face scenarios where the identity of the task is often not explicitly known. This thesis addresses this problem by developing an approach for multitask multiagent learning, where agents learn a coordinated policy that generalizes well across all tasks. While existing works have addressed learning in single-agent fully-observable multitask settings [30], this thesis addresses the multiagent multi-task setting under partial observability, where concurrent teammate learning requires
1.2.3
Accelerating Multiagent Learning by Learning to Teach
In cooperative Multiagent Reinforcement Learning (MARL), agents learn to maximize a joint reward while interacting in a shared environment. Recent works in cooper-ative MARL have shown that adding a communication mechanism between agents
significantly improves overall team performance in tasks [31-341. This thesis builds on
these results by adopting communication mechanisms to enable peer-to-peer teaching during the learning process. The form of "teaching" considered in this thesis involves communicating recommended actions from one agent to another. The main benefit of peer-to-peer teaching is that it can accelerate learning even without relying on the existence of "expert" teachers. Key issues must be addressed, however, to enable teaching in multiagent systems: agents must learn both when and what to teach. Moreover, despite coordinating in a shared environment, social artificially intelligent
(AI) agents may be independent learners (i.e., using decentralized processors/learning
algorithms) with privacy constraints (e.g., robots from distinct corporations that cannot share full policies). Thus, another issue to resolve is to learn how to teach under these constraints. Due to their theoretical and practical importance for future multiagent learning systems, these learning to teach issues are addressed as part of the contributions of this thesis.
1.2.4
Summary
In summary, this thesis targets several core problems related to multiagent coordi-nation, with particular focus on learning-based approaches for observation models, multitasking, and communication-based teaching in teams of cooperative independent learners. The frameworks and algorithms introduced in this thesis are evaluated on a variety of hardware and simulated domains. Resolution of the the targeted problems is necessary for principled application of multiagent decision making to real-world settings of interest.
1.3
Literature Review
This section summarizes works related to the problem settings considered and ap-proaches introduced in this thesis.
1.3.1
Multiagent Formalisms
An important challenge for multiagent coordination is to determine the communication architecture best-suited for a given mission. Centralized planning architectures [35-391 rely on full information sharing through an assumed low-latency and high-reliance network. These frameworks, however, have difficulty handling communication in-frastructure failures or scenarios where agents can only communicate with nearby neighbors.
Distributed architectures [40-42] use local communication for consensus of agent
policies, and can be considered a middle-ground between centralized and decentralized decision making as they do not assume perfect communication with a central planning node. Auction-based distributed algorithms [43] enable robustness to communication failures and have been extended to support asynchronous task allocation [44]. Asyn-chronous decision making can be more practical in real-time settings as it enables instantaneous transitions between executed tasks, as opposed to approaches that require transitional delays to ensure team synchronization given variable-duration tasks.
Other promising works on multiagent coordination focus on single-step problems (e.g., task allocation). A hierarchical decomposition approach to task allocation for
homogeneous agents has been proposed in
[451,
where partitioning is done based onlocal communication groups formed by neighboring agents. A hierarchical approach is also presented in [46], which exploits the locality and sparsity of tasks to partition the joint problem into a set of independent sub-problems. Relevant work in hierarchical planning is presented in [471, where regression planning is used to seek a set of high-level actions (with tight integration to motion models) that ensure the agent has
high probability of reaching its goal state. Their work targets planning under partial observability, handling uncertainty by operating in belief space, but in contrast to this thesis is focused on single-agent domains.
It is sometimes unreasonable for an agent to communicate all information to its teammates, or even to a central planning node. Decentralized planning and learning architectures enable the decision making team to adapt to dynamically-changing network infrastructures by modeling communications as actions with associated costs. Multiagent learning agents may be broadly dichotomized into two classes: Joint Action Learners (JALs) and Independent Learners (ILs) [481. JALs observe actions taken by all agents, whereas ILs only observe local actions. As observability of joint actions is a strong assumption in partially observable domains, ILs are sometimes more practical, despite leading to a more challenging problem to be solved [48].
1.3.2
Decision Making under Uncertainty
Real-world applications are typically subject to multiple sources of uncertainty, for instance due to stochastic action outcomes, noisy sensory information, or imperfect communication between agents. Uncertainty sources can be broadly categorized as
aleatoric (due to inherent stochasticity in the world - which can be modeled but not
always resolved) or epistemic (due to resolvable lack of knowledge or poor assumptions
made in imperfect models of the world)
1491.
Real-world agents must execute theirpolicies robustly and ensure a well-coordinated policy despite complications arising from both of these uncertainty sources.
A natural way to consider an uncertain domain is through the formalism of
the Partially Observable Markov Decision Process (POMDP) [50], which extends Markov Decision Processes (MDPs) to embed noisy sensor models providing partial observations of the latent state. Until recent years, the complexity of POMDPs limited their applicability to small planning problems; a variety of algorithmic improvements have significantly grown the size of problems for which solutions can be obtained
[51-561.
A general representation of the multiagent coordination problem is the
Decentral-22
ized Partially Observable Markov Decision Process (Dec-POMDP) [57]. Dec-POMDPs have a broad set of applications including networking problems, multi-robot explo-ration, and surveillance [9-131. Many works have considered scalable Dec-POMDP
planning approaches, for instance 1581, which exploits independence between agents
to allow scalable planning with dozens of agents. A large number of existing ap-proaches typically rely on completely discrete domains and are not scalable for large (or continuous) state or observation spaces. By contrast, several of the algorithms introduced in this thesis directly apply to domains with underlying continuous states and observation spaces.
1.3.3
Multiagent Reinforcement Learning
The planning literature typically assumes knowledge of explicit distributions (over transitions, observations, and/or environments), or black-box simulation capabilities to sample a model of the world at planning time. If this knowledge is not available, existing multiagent POMDP techniques cannot be directly applied. Instead, solution approaches must learn approximations of these missing distributions based on agent experiences (i.e., executed actions and received observations/rewards). This data-driven coordination process may be modeled as a multiagent reinforcement learning (MARL) problem. A taxonomy of MARL approaches is presented in [20]. Partially observable MARL has received limited attention until recently. Works include
model-free gradient-ascent based methods
159,
601, simulator-supported methods to improvepolicies using a series of linear programs [61], and model-based approaches where agents learn in an interleaved fashion to reduce destabilization caused by concurrent
learning 1621. Recent scalable methods use Expectation Maximization to learn finite
state controller (FSC) policies [63-651, and include approaches for coordination under partial observability developed concurrently with this thesis [31, 33, 661.
Several of the approaches introduced in this thesis are closely related to independent learning (IL) algorithms that learn action-values (Q-values), as their representational power is more conducive to transfer between tasks, in contrast to policy tables or
of these methods is presented in [211, where the most straightforward approach is Decentralized (or independent) Q-learning [67], which has some empirical success [211. Distributed Q-learning [681 is an optimal algorithm for deterministic domains; this approach involves updating Q-value only when they are guaranteed to increase, and updating policies only when their corresponding actions are no longer greedy with respect to Q-values. Policy Hill Climbing using the Win-or-Learn Fast heuristic is conducted in [69] to decrease (increase) each agent's learning rate when it performs well (poorly).
Frequency Maximum Q-Value heuristics [701 bias action selection towards those consistently achieving max rewards. Hysteretic Q-learning [71] addresses miscoordina-tion using cautious optimism to stabilize policies while teammates explore. This thesis extends the hysteretic approach to the multitask multiagent reinforcement learning setting, due to its good track record of empirical success [21, 72, 73] leads this thesis to extend it to the multitask multiagent reinforcement learning setting. A means of stabilizing use of experience replay buffers for the centralized multiagent learning case was introduced by [661. Architectures for learning communication policies in Dec-POMDP RL are considered in [311, where the best performance is demonstrated using a centralized learning approach with inter-agent backpropagation and parameter sharing; they also evaluate a model combining Decentralized Q-learning with Deep
Recurrent Q-Networks
1741,
which they call Reinforced Inter-Agent Learning. Giventhe decentralized nature of this latter model (called Dec-DRQN herein for clarity), several empirical evaluations are conducted against it in this thesis.
1.3.4
Transfer and Multitask Learning
Surveys of transfer and multitask RL are provided in [751 and 1761; the majority of
these works almost exclusively target single-agent, fully-observable settings. First and second-order statistics are used in [771 to compute a prioritized sweeping metric for multitask reinforcement learning (MTRL), enabling an agent to maximize lifetime reward over task sequences. An MDP policy similarity metric is introduced in [78], and used to learn a policy library that generalizes well to tasks within a shared
domain. Transfer learning for MDPs is treated in
[79]
by learning a Dirichlet ProcessMixture Model over source MDPs, used as an informative prior for a target MDP; their approach is extended to multiagent MDPs by learning characteristic agent roles
[80]. An MDP clustering approach is introduced in [811, which alleviates negative
transfer in MTRL; their work also proves reduction of sample complexity of exploration due to information transfer. Parallel transfer to accelerate multiagent learning using inter-agent knowledge sharing is introduced in [821. Recent work extends the notion of neural network distillation [301 to Deep Q-Networks (DQNs) [83] for single-agent, fully-observable MTRL, first learning a set of specialized teacher DQNs, then distilling teachers to a single multitask network [84]. The efficacy of the distillation technique for single-agent MDPs with large state spaces leads this thesis to extend it to the multitask multiagent reinforcement learning (MT-MARL) problem setting.
1.3.5
Hierarchies and Abstractions
Scalable planning techniques exploit problem decomposition, task hierarchy, and action abstraction to efficiently compute a coordination policy.
Macro-actions (MAs), or temporally-extended actions, have provided increased scalability in single-agent MDPs [851 and POMDPs [86-881. The options framework
[85] integrates discrete-time MAs in MDPs, resulting in a discrete-time semi-MDP
(SMDP), a framework in which durations between action transitions are random variables [89, 90]. Works such as [911 considered parallelization of temporally-extended actions for single agents (managing parallel processes) and multiple agents (acting in parallel). This work also formalized the notion of decision epochs, timesteps at which decision making is conducted in durative action processes, enabling treatment of asynchronous actions in settings with observable states. In this thesis, a specific type of such decision epochs are used to allow asynchronous decision making in partially observable settings.
Usage of durative actions in partially observable settings was considered in [92], resulting in the Partially Observable semi-MDP (POSMDP), where primitive noisy
POSMDP-related models. For example, planning with MAs in POMDPs is considered in
1931,
where belief simplex discretization on a uniform grid is used for MA-reward calculation using reinforcement learning. Further work on single-agent MA-based planning was conducted in [871, where multi-modal belief updates using a modified Kalman Filter (similar to a Gaussian sum filter) were used in conjunction with a forward search algorithm for efficient policy search.Recent research efforts have integrated MAs into mulitagent planning under stochas-ticity [29, 94-971, resulting in Decentralized Partially Observable Semi-Markov Ob-servation Processes (Dec-POSMDPs). In multiagent planning with MAs, decision
making occurs in a hierarchical manner. A high-level policy designates an MA to each agent and the selected MA executes a chain of low-level control commands to accomplish a task. The Dec-POSMDP provides an extension of the options framework
[85] to multiagent domains while formally addressing the lack of synchronization
between agents. Integration of MAs into Dec-POMDPs enables problems of unprece-dented size to be solved by treating low-level actions and observations within MAs. Recent work has focused on Dec-POSMDP policy search for discrete observation spaces, resulting in several algorithms: Masked Monte Carlo Search (MMCS) [95j, MacDec-POMDP Heuristic Search (MDHS) [941, and Graph-based Direct Cross En-tropy method (G-DICE) [961. These algorithms use finite state controllers (FSCs) for policy representation, wherein the underlying graph-based policy structure enables their application to infinite-horizon domains. This thesis introduces several key ex-tensions to these works, specifically by embedding vision-based perception into the
Dec-POSMDP framework, and by introducing an algorithm for continuous observation policy learning in Dec-POSMDPs.
1.3.6
Skill Transfer via Teaching
Effective diffusion of knowledge has been studied in many fields, including inverse
rein-forcement learning [98], apprenticeship learning
1991,
and learning from demonstration[1001, wherein students discern and emulate key demonstrated behaviors. Works on
curriculum learning [101] are also related, particularly automated curriculum learning
26
[102]. Though the automated curriculum learning approach focuses on single student supervised/unsupervised learning [102], it highlights interesting measures of learning progress also used in this thesis. Several works meta-learn active learning policies for supervised learning [103-1061. In meta-learning, the primary objective is to learn to learn (e.g., to modify the underlying learning algorithm to accelerate learning in never-before-seen tasks). One of the thesis contributions also uses meta-learning, but in the regime of MARL, where agents must learn to advise teammates without destabilizing coordination.
The advising approach introduced in this thesis may be broadly classified under paradigm of machine teaching, where the objective is to find an optimal training set D to efficiently teach concept 0 to a student learner [1071. Machine teaching performance measures include the cardinality of D (smaller preferred) or rate of student learning (faster preferred). This thesis focuses on the cooperative setting where a pair of agents have incentive to exchange advice V with one another to accelerate learning of a joint policy 0. Readers interested in machine teaching theory and applications are referred to [108].
In the closely related field of action advising for single-agent RL, a student receives action suggestions from a teacher to accelerate its learning [109]. The teacher is typically assumed an expert who always advises the optimal action for the student.
These works typically use the state importance value Ip(s, d) = maxa
Qp(s,
a)-Q(s, &)to decide when to send advice, where p = ( for student-initiated advising, p = 9
for teacher-initiated advising, Q, is the corresponding action-value function, s is the
student state, and & is the student's intended action if known (or the worst-case action
otherwise). Ip(s, &) estimates the performance difference of best/intended student
actions in state s.
In student-initiated teaching approaches [110], the student decides when to request advice using heuristics based on Im(s, d). The Ask Important heuristic [111 requests
advice whenever It(s, &) > k, while Ask Uncertain requests when I®(s, a) < k
[1101, where k is a threshold parameter. In teacher-initiated approaches [109], the
7rq and/or action-value function Qg: Early Advising advises until advice budget depletion, Importance Advising does so when Iq(s, a) _ k [109], Early Correcting when 7r(s) 4 7ff(s) [1111, and Correct Important when I(s) > k and 7re(s) 7 ir5(s)
[1091. Q-Teaching learns when to advise by rewarding the teacher Iq(s,ei) when advising occurs 11121.
While most works on information transfer target single-agent settings, several exist for MARL. These include imitation learning of expert demonstrations [113], cooperative inverse reinforcement learning with a human and robot player [1141, and transfer to parallel learners in tasks with (assumed) similar value functions 182]. To
the best of the author's knowledge, AdHocVisit and AdHocTD 11151 are the only
action advising methods that do not assume expert teachers; in their work, teaching agents always advise the action they would have personally taken in the student's state, using state visit counts as a heuristic to decide when to exchange advise.
This thesis introduces a principled approach for learning what it means to be an effective advisor in a multiagent team, which has not been considered before. There are additional complexities in this new paradigm (that learns both execution and advising policies), which constrain the size of the problems that can be considered compared to prior multiagent papers. While approaches for learning to communicate
[31, 1161 are related, their agents learn communication policies for better final
execu-tion/ coordination, not for advising/improving learning. Thus, the two approaches are disparate and may even be combined.
1.4
Thesis Contributions & Structure
This section summarizes the key thesis contributions and overall structure.
28
1.4.1
Contribution 1: Embedding Complex Observation
Mod-els into Multiagent Decision Making Frameworks
A probabilistic formulation for learning of generative semantic-level observation
pro-cesses is introduced in this contribution, including principled embedding of these processes into a multiagent decision making framework [117, 118]. This formulation enables agents to learn a generative observation process that can be used for train-ing of a coordination policy over highly complex sensory inputs (e.g., vision-based classification).
Specifically, this contribution is a formalization of macro-observation processes within Dec-POSMDPs, with a focus on the ubiquitous perception-based decision making problem encountered in robotics. A hierarchical Bayesian macro-observation framework is introduced, using statistical modeling of observation noise for probabilistic classification in settings where noise-agnostic methods are shown to fail. The resulting data-driven approach avoids hand-tuning of observation models and produces statistical information necessary for Dec-POSMDP solvers to compute a policy. Hardware results for real-time semantic labeling on a moving quadrotor are presented, with accurate inference in settings with high perception noise. The processing pipeline is executed onboard each quadrotor at approximately 20 frames per second. The macro-observation process is integrated into Dec-POSMDPs, with demonstration of associated semantic-level decision making policies executed on a quadrotor team in a perception-based health-aware disaster relief mission.
The key benefits of the contribution are elimination of the training-time computa-tional overhead associated with forward inference of lower-level observation processes, and enabling support of continuous observation models in the Dec-POSMDP frame-work.
1.4.2
Contribution 2: Multitask Multiagent Reinforcement
Learning
A framework for multitask multiagent reinforcement learning is introduced in this
contribution [1191. One of the key limiting assumptions in related multiagent works is the existence of a single, well-defined environmental context (with static state transition/observation models). This contribution addresses this restrictive assumption
by introducing an approach wherein agents first learn a well-coordinated policy without
explicit knowledge of underlying models. Subsequently, learned policies are unified into a single joint policy that performs well across several (rather than a single) environmental context. The key benefit of the approach is that it enables application of policies to more realistic settings where policies generalize across multiple related tasks, using a completely data-driven back end.
The primary benefit of the overall contribution is introduction of an MT-MARL approach targeting sample-efficient and stable learning. The resulting framework enables coordinated multiagent learning under partial observability. The approach makes no assumptions about communication capabilities and is fully decentralized during learning and execution.
1.4.3
Contribution 3: Learning to Teach in Cooperative
Mul-tiagent Reinforcement Learning
A framework and algorithm for peer-to-peer teaching in cooperative multiagent
rein-forcement learning is introduced in this contribution [1201. The algorithm, Learning to Coordinate and Teach Reinforcement (LeCTR), trains advising policies by using student agents' learning progress as a reward for teaching agents. Agents using LeCTR learn to assume the role of a teacher or student at the appropriate moments, exchanging action advice to accelerate the entire learning process. The introduced algorithm supports teaching heterogeneous teammates, advising under communication constraints, and learns both what and when to advise. LeCTR is demonstrated to
30
outperform the overall performance and rate of learning of prior teaching methods on multiple benchmark domains. The key benefit of the introduced approach is that it can accelerate multiagent learning even without relying on the existence of "expert" teachers.
1.4.4
Contribution 4: Hardware and High-fidelity Simulation
Demonstrations
As the primary objective of this thesis is to enable multiagent coordination in large-scale domains, hardware and high-fidelity simulated demonstration are used to empirically verify the developed approaches. Hardware experiments include evaluation of developed approaches on multi-robot fleets in the Aerospace Controls Laboratory at MIT. Hardware testbeds include the onboard perception and computation capabilities necessary to demonstrate that the developed technologies are deployable to real-world systems. In situations where simulations are more amenable to large-scale
experimentation, the simulation platforms developed involve complex sensory inputs, and/or interesting multiagent interactions, and/or consider meta-objectives extending beyond the single-task policy performance measures typically considered in previous works.
1.4.5
Thesis Structure
The remaining chapters of this thesis are structured as follows:
* Chapter 2 introduces preliminary frameworks and notations for multiagent coordination in Markovian and semi-Markovian settings.
" Chapter 3 introduces an approach for learning semantic-level macro-observations,
then embedding them into the Dec-POSMDP framework (Contributions 1 and
4).
using Probabilistic Macro-observations", Shayegan Omidshafiei, Shih-Yuan Liu, Michael Everett, Brett T. Lopez, Christopher Amato, Miao Liu, Jonathan P. How, John Vian, in the IEEE International Conference on Robotics and
Automation (ICRA), 2017 [1171.
" Chapter 4 introduces a Dec-POSMDP algorithm enabling hierarchical multiagent
coordination in continuous observation spaces (Contributions 1 and 4).
The technical content of this chapter is based on the following work led by the thesis author: "Scalable Accelerated Decentralized Multi-robot Policy Search in Continuous Observation Spaces", Shayegan Omidshafiei, Christopher Am-ato, Miao Liu, Michael Everett, Jonathan P. How, John Vian, in the IEEE International Conference on Robotics and Automation (ICRA), 2017 [118, 1211.
" Chapter 5 introduces a two-phase approach for multitask multiagent
reinforce-ment learning, first focusing on stabilizing coordination in single tasks, then on combining task-specialized policies into a single multitask policy (Contributions
2 and 4).
The technical content of this chapter is based on the following work led by the thesis author: "Deep Decentralized Multi-task Multi-Agent Reinforcement Learn-ing under Partial Observability", Shayegan Omidshafiei, Jason Pazis, Christopher Amato, Jonathan P. How, in the International Conference on Machine Learning
(ICML), 2017 [119].
" Chapter 6 introduces a framework and algorithm for communicative peer-to-peer
teaching in cooperative multiagent reinforcement learning (Contributions 3 and
4).
The technical content of this chapter is based on the following work led by the thesis author: "Learning to Teach in Cooperative Multiagent Reinforce-ment Learning", Shayegan Omidshafiei, Dong-Ki Kim, Miao Liu, Matthew Riemer, Gerald Tesauro, Matthew Riemer, Christopher Amato, Murray Camp-bell, Jonathan P. How, in the Lifelong Learning: A Reinforcement Learning
Approach Workshop at the Federated Artificial Intelligence Meeting (FAIM),
2018 [1201.
9 Chapter 7 summarizes the thesis contributions and outlines directions for future work.
34
Chapter 2
Background
Given the general problem setting of interest and contributions outlined in Chapter 1, this chapter provides the technical formulation for the decentralized cooperative multiagent learning under partial observability problem. The remaining sections first introduce the single agent decision making problem, then formalize the partially observable setting, then conclude by extending these formulations to single task and multitask multiagent decision making variants.
2.1
Markovian Formalism
2.1.1
Markov Decision Process
Single-agent decision making under full observability is formalized using Markov
Decision Processes (MDPs) [122], defined as tuple (S, A, T, R, -y). At timestep t, the
agent with state s E S executes action a E A using policy 7r(ajs), receives reward
rt = R(s) E- R, and transitions to state s'
c
S with probability P(s'Is, a) = T(s, a, s').Denoting discounted return from timestep t onwards as R = l''-rt, with
horizon H and discount factor -y E [0, 1), the action-value (or Q-value) is defined as
Q"(s,
a) = E,[RtIst = s, at a]. The agent's optimal policy 7r* then maximizes the2.1.2
Partially Observable Markov Decision Process
Agents in partially observable domains receive observations of the latent state. Such domains are formalized as Partially Observable Markov Decision Processes (POMDPs),
defined as (S, A, T, R, Q, 0, -y) [501. After each transition, the agent observes o E Q
with probability P(ols', a) = 0(o, s', a). Due to noisy observations, POMDP policies
typically map observation histories to actions.
2.1.3
Decentralized Partially Observable Markov Decision
Pro-cess
The Decentralized Partially Observable Markov Decision Process (Dec-POMDP) is
a multiagent decision making framework, defined as (1, S, A, T, R, Q, 0, 7)
[7];
I isa set of n agents, S is the state space, A = xiAW is the joint action space, and
Q = xiQ(') is the joint observation space [57].' Each agent i executes action aW E A(,
where joint action a - (a('),. . ., a(n)) causes environment state s E S to transition to
s' E S with probability P(s'Is, a) = T(s, a, s'). At each timestep, each agent receives
observation oW c QW, with joint observation probability P(os', a) = 0(o, s', a),
where o = (o(),..., o(')). Let local observation history at timestep t be o5( =
( ,... , where E Ot Single-agent policy r(' : i-* A( conducts
action selection, and the joint policy is denoted ir = (ir(l),.. ., 7r(")). For simplicity,
many works consider only pure joint policies, as finite-horizon Dec-POMDPs have at least one pure joint optimal policy [123]. It may sometimes be desirable to use a recurrent policy representation (e.g., recurrent neural network) to compute an internal state ht that compresses the observation history, or even to explicitly compute a belief state (probability distribution over states); with abuse of notation, several thesis chapters use ht to refer to all such variations of compressed internal states/observation histories.
The team then receives reward rt = R(st, at), the objective being to maximize joint
'Generic parameter p of the i-th agent is denoted as p('), joint parameter of the team as p, and joint parameter at timestep t as pt.
value, V(s; 0) = E[E, yrtIso = s], with discount factor -y E [0, 1). Let action-value
function Q()(o(i), a('; h(')) denote agent i's expected value for executing action a(') given a new local observation o() and internal state 0, and using its policy thereafter.
The vector of action-values given agent i's new observation o(') is denoted Q(o(); h(0)).
2.1.4
Decentralized Partially Observable Semi-Markov
Deci-sion Process
The Decentralized Partially Observable Semi-Markov Decision Process (Dec-POSMDP) addresses scalability issues of Dec-POMDPs by incorporating belief-space macro
actions, or skills, into the framework [291.
Definition 1. The Dec-POSMDP is defined below:
SI= {1, 2, ... , n} is the set of heterogeneous agents.
S3(1) X B3(2
) X ... X J3(n) X Xe is the underlying belief space, where B() is the set
of belief milestones of the i-th agent's MAs and x' E Xe is the environment state.
]I = 1(1) x f(2) .. xf(n) is joint independent MA space, where f(') is the set
of MAs for the i-th agent. 7r {r),.., (n)} is the team's joint MA.
Q
n'
is the set of all joint MA-observations (detailed below)." P(b', Xe', kIb, xe; ir) is the high-level transition model under MAs -r, from (b, xe)
to (b', se'), where b is the joint belief.
" RT(b, x'; 7r) is the generalized reward of taking a joint MA 7r at (b, Xe).
" P(6eIb, x') is the joint observation likelihood, where the observation is
6-{
e* i), -e(2),..., e(")}.Agents involved in both Dec-POMDPs and Dec-POSMDPs operate in belief space, the space of probability distributions over states. Solving a Dec-POSMDP results in a hierarchical decision making policy, where a macro-action (MA) 7r() is first selected by each agent i E I, and low-level (primitive) actions are conducted within the MA until an E-neighborhood of the MA's belief milestone 69"' is reached. This neighborhood
defines a goal belief node for the MA, denoted B9"' = {b :
lIb
-I9Ka'|
< E}. Each MAencapsulate a low-level POMDP involving primitive actions a a and observations o 4.
Let Xe be the high-level or macro-environment state space, a finite set describing the
state space extraneous to agent states (e.g., an object in the domain). An observation of the macro-environment state xe E Xe is denoted as the macro-observation oe(i). Upon completion of its MA, each agent makes macro-observation oe(i) and calculates
its final belief state, bf This macro-observation and final belief are jointly denoted
a = (oe(i), bf(0)
The history of executed MAs and received high-level observations is denoted as the MA-history,
= {00" 0r ,1 ) ,1 7r . .. , ked, 7rki, P } (2.1)
The transition probability P(b', e', klb, Xe; -) from (b, Xe) to (b', Xe') under joint MA
tr in k timesteps is [961,
P(b', e k~bo, 0, ok; t) = P(x, bk Ibo, x, oe; 7r)
PI [p l_1, o%; ir(bkl))P(by k-_ 1, bk-I; 7r(bk_1)Px7_k, bki_
x',
bo; tr(bo))].~e
bk-(2.2)
The generalized team reward for a discrete-time Dec-POSMDP during execution of
joint MA 7r is defined [96],
R (b, xe; tr) = E [ R(xt, x', at)P(xo) = b, x' x= ; 7r (2.3)
E y t
38
where T = mini mint{t : b( E B(),oal} is the timestep at which agent i completes
its current MA, 7r('). Note that T is itself a random variable, since MA completion
times are also non-deterministic. Thus, the expectation in (2.3) is taken over MA completion durations as well. In practice, sampling-based approaches are used to estimate this expectation.
MA selection is dictated by the joint high-level policy, ( ) { ,..., 0(n)}. Each
agent's high-level policy O(W maps its MA-history &k to a subsequent MA 7r(') to be
executed. The joint value under policy
4
is,V k(b, Xe) = E [ gtk R'(bt , ;t)Ibo, x'; (2.4)
lk=0
R'(b, x; -7r) +
>
Ik ( P(b', X, Oe', klb, Xe;, r)V'5(b', xe').k=1 b',xe',oe'
The optimal joint high-level policy is then,
= argmax VO(b, Xe). (2.5)
To summarize, the Dec-POSMDP is a hierarchical decision making process which
involves finding a joint high-level policy q# dictating the MA r() each agent i E I
conducts based on its history of executed MAs and received high-level observations.
Within each MA, the agent executes low-level actions at and perceives low-level
observations o(. Therefore, the Dec-POSMDP is an abstraction of the Dec-POMDP process which treats the problem at the high macro-action level to significantly increase planning scalability. Readers are referred to [29] for more details on Dec-POSMDPs.
So far, most works that use hierarchical abstractions to increase scalability of
Dec-POMDPs have focused on the action space [29, 95, 124] - no similar work targeting
observation space scalability has been conducted. Further, the scope of the large body of work on Dec-POMDPs has primarily been within the artificial intelligence perspective, with limited focus on traditional robotics applications [7]. While the strength of Dec-POMDPs and Dec-POSMDPs comes from principled treatment of