Deep video-to-video transformations for accessibility applications
Texte intégral
Figure
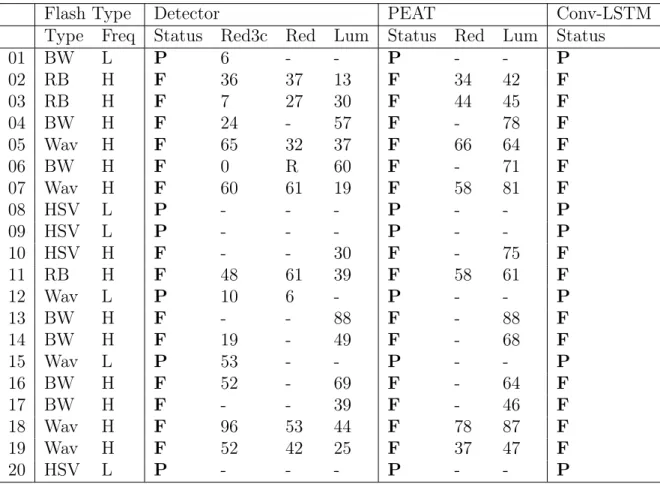

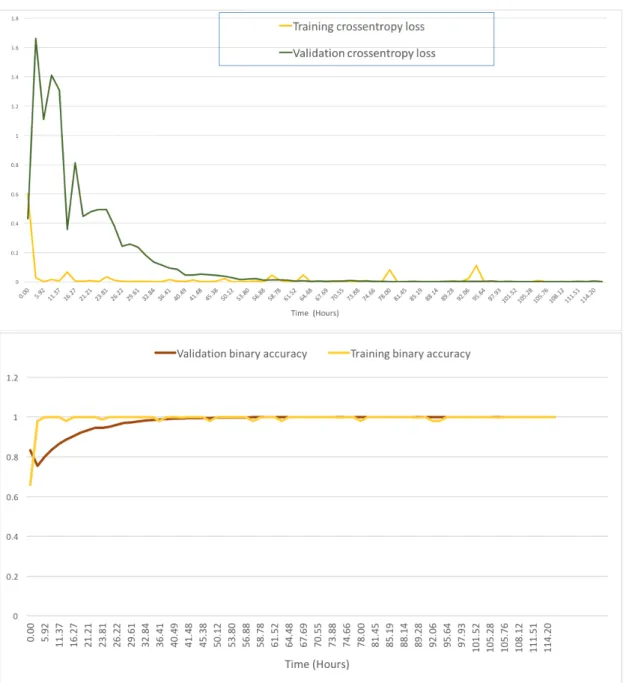
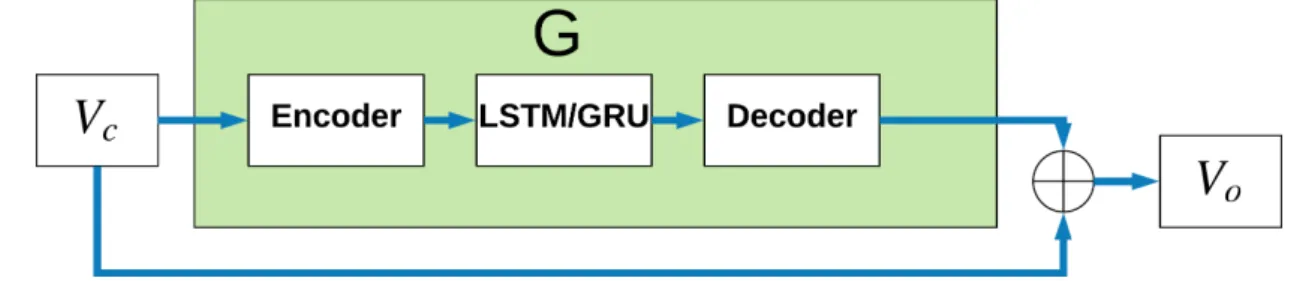
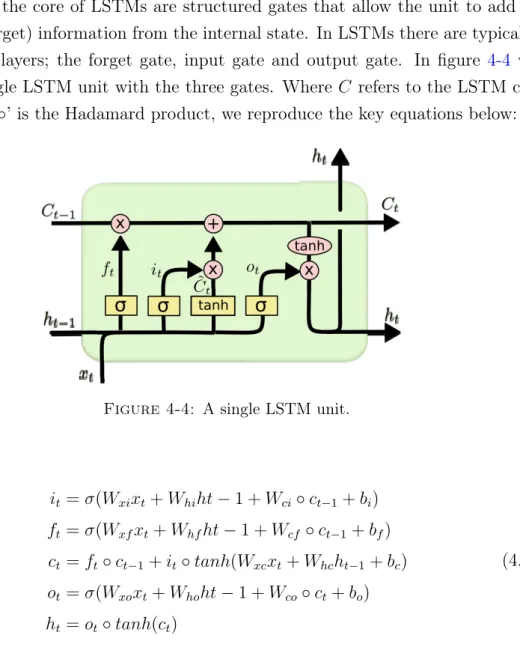
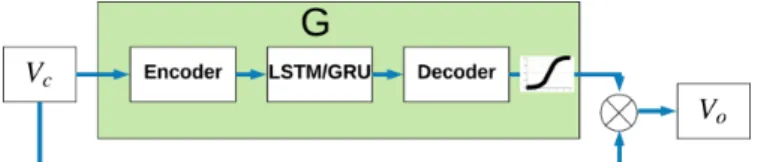
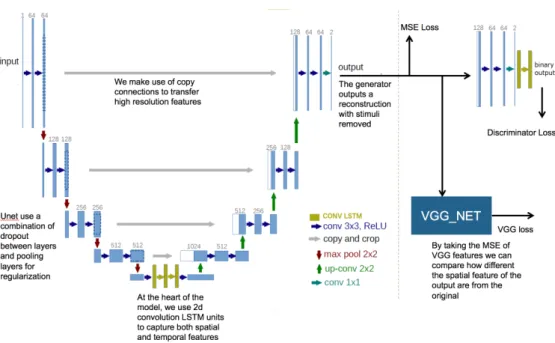

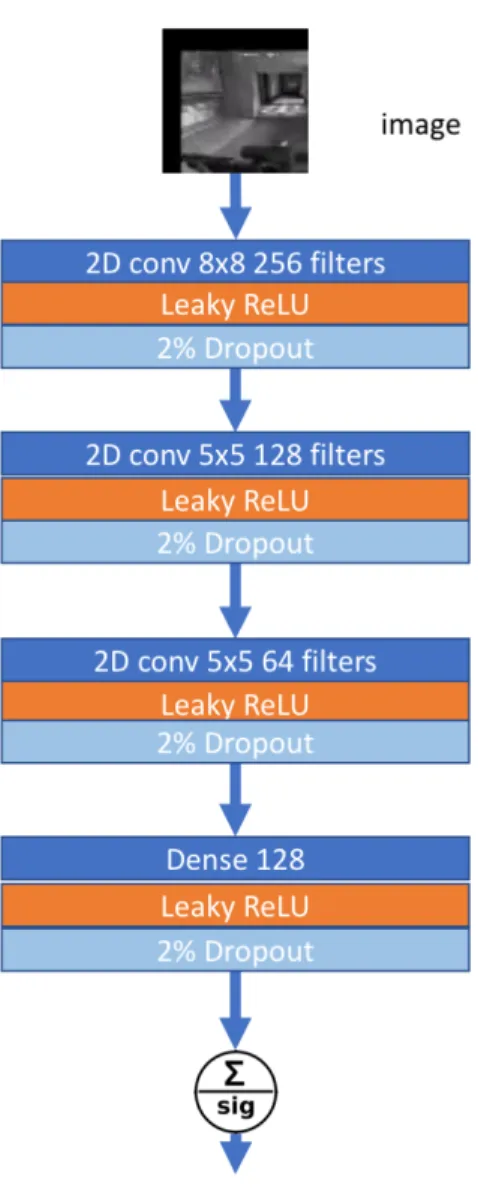

Documents relatifs
The article discusses the experience of using machine learning method (decision trees) for the automatic identification of the left ventricle region on ultrasound images of the
Therefore, smart recommender systems that accelerate content access with personalized suggestions closely matching user interests can considerably improve the mobile media
therefore allowing for the sharing of resources and teachers; (ii) The ability for leading teachers to provide classes to students across the globe; (iii)
This schedule-like layout provides the video previews with temporal context, supporting situations where users might prefer finding a video by navigating the program over a key-
des dispositifs et des perspectives heuristiques liés au numérique dans le domaine des Sciences humaines et sociales.”.. Manifeste des Digital
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
These initiatives are driven by such factors as the considerable impact of the Improvisation Technologies CD-ROM by William Forsythe, the interest of artists and the public to the
In practice, RPCA via L+S decomposition is suitable for video processing tasks in which (1) the observed video can be viewed as the sum of a low-rank clean video without
