Predicting query performance and explaining results to assist Linked Data consumption
Texte intégral
Figure
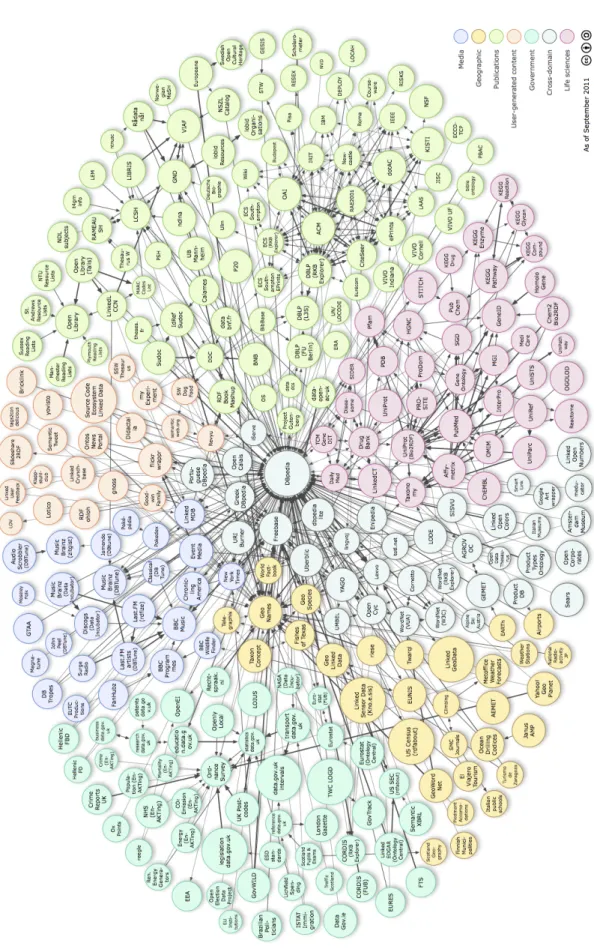
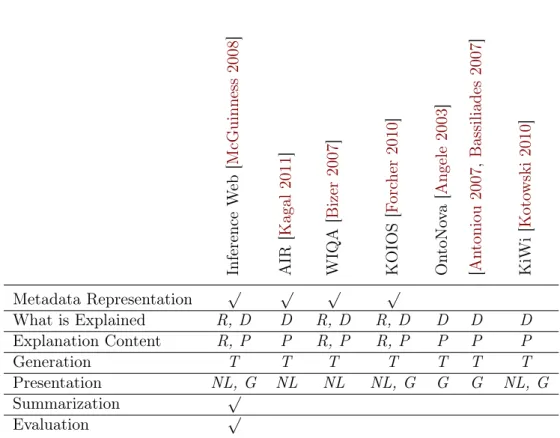
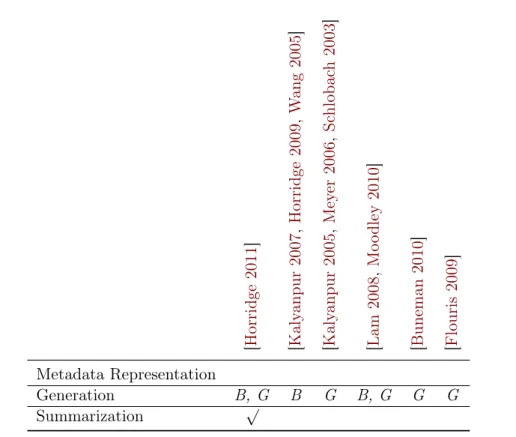

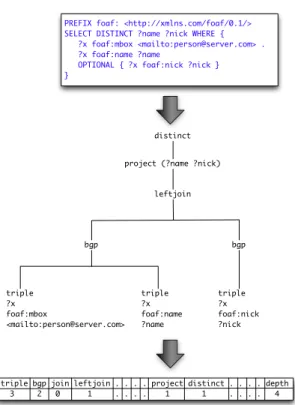
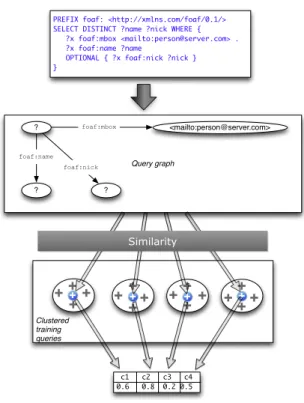



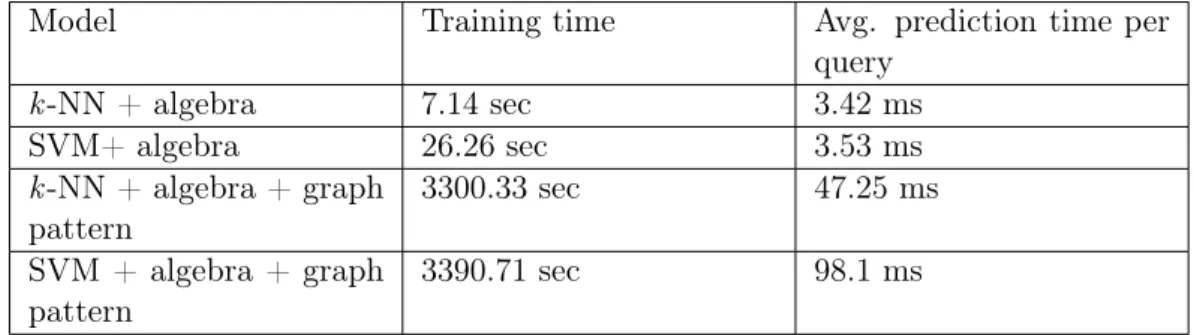
Documents relatifs
Visualization techniques used in GRAPHIUM facilitate the understanding of trends and patterns between the performance exhibited by these engines during the execution of tasks
Here we show how Linked Data can be used in an Inductive Logic Programming process, where they provide background knowledge for finding hypotheses regarding the unrevealed
The two chosen vocabularies are the OPMV (Open Provenance Model Vocabulary) [12], a lightweight imple- mentation of the community Open Provenance Model [8], and the
Bizer and Schultz [7] proposed a SPARQL-like mapping lan- guage called R2R, which is designed to publish expressive, named executable mappings on the Web, and to flexible combine
In addition to merely comparing our implementations of IndIR, CombIR, and CombQuadIR among each other, we also compare these implementations with existing data structures that can
This ability to incorporate semantic information is especially important in domains with rich semantic context, and allows SSDM to capture semantic nuances that are missed by
keywords (city) and formats (RDF - SPARQL, Turtle, JSON-LD, etc.) LDCP could there- fore support loading and querying of dataset metadata from DCAT-AP enabled catalogs and even
Client Cost The results for the average cpu usage across the duration of the query evaluation of all clients that sent queries to the server in our main experiment can be seen in
