HAL Id: tel-00457239
https://tel.archives-ouvertes.fr/tel-00457239
Submitted on 16 Feb 2010
HAL is a multi-disciplinary open access
archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés.
Luc Jaulin
To cite this version:
Luc Jaulin. Le calcul ensembliste par analyse par intervalles et ses applications. Modélisation et simulation. Université d’Angers, 2000. �tel-00457239�
1 Présentation générale 5 1.1 Curriculum vitae . . . 5 1.1.1 Etat civil . . . 5 1.1.2 Formation et diplômes . . . 5 1.1.3 Postes occupés . . . 6 1.2 Présentation de ma thèse . . . 6 1.3 Activités de recherche . . . 7 1.3.1 Coencadrement de thèses . . . 7
1.3.2 Collab orations scienti ques . . . 8
1.3.3 Comité de lecture de revues internationales . . . 9
1.3.4 Activités administratives . . . 9
1.4 Activités denseignement . . . 10
1.5 Présentation du document de recherche . . . 10
1.6 Liste des pub lications . . . 12
2 Lapproche ensembliste 15 2.1 Introduction . . . 15
2.2 Motivations . . . 15
2.2.1 Représentation dune variab le incertaine . . . 16
2.2.2 Recouvrement dun espace de recherche . . . 19 1
2.3 Opérations sur les ensemb les . . . 19
2.3.1 Les opérations étendues . . . 20
2.3.2 Les opérations ensemb listes pures . . . 20
2.3.3 Pessimisme dû aux occurrences multiples . . . 21
2.4 Représentation des ensemb les . . . 22
2.4.1 Di¤érents types de représentation . . . 22
2.4.2 Distances entre compacts . . . 24
2.5 Approximation du calcul ensemb liste . . . 24
2.6 Les sous-pavages . . . 25
2.6.1 Pavés . . . 25
2.6.2 Pavages et sous-pavages . . . 26
2.6.3 Représentation b inaire dun sous-pavage régulier . . . 28
2.6.4 Opérations sur les sous-pavages réguliers . . . 28
2.7 Algorithmes ensemb listes . . . 30
2.8 Conclusion . . . 31
3 Analyse par intervalles 33 3.1 Introduction . . . 33
3.2 Calcul par intervalles . . . 35
3.3 Fonction dinclusion . . . 35
3.4 Test dinclusion . . . 38
3.5 Réduction dun pavé sous une contrainte . . . 41
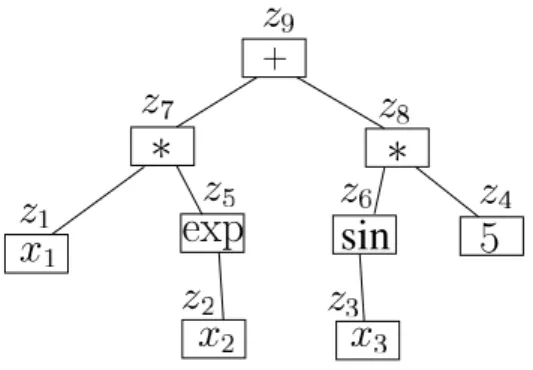
3.5.1 Principe de la réduction . . . 42
3.5.2 Arb re dune fonction terme acyclique réelle . . . 43
3.5.3 Opérations élémentaires sur les arbres des fonctions acycliques . . . 45
3.5.4 Algorithme de propagation-rétropropagation . . . 46
3.7 Linéarisation extérieure . . . 52
3.8 Conclusion . . . 55
4 Mise en oeuvre du calcul ensembliste 57 4.1 Introduction . . . 57
4.2 Inversion ensemb liste . . . 58
4.3 Image ensemb liste . . . 60
4.4 Calcul du pavé enveloppe dun ensemb le . . . 63
4.5 Algorithme de minimisation glob ale . . . 67
4.6 Conclusion . . . 69
5 Application à la localisation dun robot 71 5.1 Introduction . . . 71
5.2 Estimateur ensemb liste . . . 72
5.3 Application à la localisation statique dun rob ot . . . 73
5.4 Ob servateur ensemb liste . . . 77
5.4.1 Ob servateur ensemb liste causal . . . 78
5.4.2 Ob servateur ensemb liste non causal . . . 79
5.5 Application à la localisation dynamique du rob ot . . . 80
5.6 Conclusion . . . 81 6 Conclusions et perspectives 83
Présentation générale
Dans ce chapitre, sont rassemblés quelques renseignements administratifs concernant ma formation, les postes que jai occupés, mes activités de recherche et mes publications. La description scienti que de mes recherches, dont une présentation est donnée au paragraphe 1.5, ne débute quau chapitre 2. En annexe, sont jointes seize publications signi catives publiées, acceptées ou soumises.
1.1 Curriculum vitae
1.1.1 Etat civil
Nom : Jaulin
Prénoms : Luc Jean François Date et lieu de naissance : 15 mars 1967 à Nevers Nationalité : Française
Adresse : L2S, Supélec, Plateau de Moulon, 91192, Gif-sur Yvette Téléphone : 01 69 85 17 59 (travail) ; 01 43 36 74 18 (domicile) Télécopieur : 01 69 41 30 60
Adresse électronique : [email protected]
1.1.2 Formation et diplômes
1990-94 Jai préparé ma thèse de Doctorat en Sciences (Automatique et Traitement du Signal) au Laboratoire des Signaux et Systèmes (CNRS-Supélec, Université de Paris-Sud), sous la responsabilité dEric Walter. Je lai soutenue le 14 février 1994 devant un jury composé de P. Bertrand (président), D. Meizel et R. Moore (rapporteurs), J.
Richalet, J. Vignes et E. Walter (examinateurs). Jai obtenu la mention très honorable avec félicitations. Le sujet en était : Solution globale et garantie de problèmes ensemblistes ; applications à lestimation non-linéaire et à la commande robuste.
1990 DEA Automatique et Traitement du Signal de lUniversité de Paris-Sud, stage au centre de Recherche en Physique de lEnvironnement, CNET-CNRS. Sujet : Restitution de latténuation dune cellule de pluie par une technique variationnelle.
1984-90 Ingénieur ESIEA (Informatique, Electronique et Automatique). 1984 Baccalauréat série E.
1.1.3 Postes occupés
Depuis Septembre 1998 : Jai obtenu pour deux ans une délégation de lUniversité dAngers vers le CNRS. Ma demande a été motivée par lécriture dun livre sur mon thème de recherche et la volonté de passer mon habilitation à diriger des recherches. Jai été accueilli au LSS-CNRS dans léquipe de E. Walter.
Septembre 1994 - Août 1998 : Maître de Conférences en 61ième section.
Enseigne-ment en Physique (plus particulièreEnseigne-ment : Automatique, Electronique, Electrotechnique et Thermodynamique) à la Faculté des Sciences de lUniversité dAngers. Laboratoire de recherche : LISA.
1992-1993 : Service national : VSNA enseignement en Mathématiques, Physique, Chi-mie, Informatique et Sport au lycée Européen de Manille (Philippines).
1.2 Présentation de ma thèse
Ma thèse de doctorat [Jau94], soutenue le 10 février 1994 en Automatique et Traitement du Signal, a été encadrée par E. Walter au LSS. Le sujet en était Solution globale et garantie de problèmes ensemblistes ; application à lestimation non-linéaire et à la commande robuste. Elle a donné lieu aux publications [JW92], [JW93b], [JW93e], [JW93a], [JW93c], [JW93d], [WJ94], [JW94] et [JW96b].
Le sujet initial de ma thèse était lutilisation doutils nouveaux pour traiter des problèmes destimation à erreurs bornées de façon globale et garantie. Très rapidement, jai proposé dutiliser une approche basée sur lanalyse par intervalles. En bref, lanalyse par inter-valles peut être présentée comme un outil numérique, encore assez con dentiel dans la communauté de lautomatique, qui permet la résolution rigoureuse dune grande classe
de problèmes non-linéaires. Comme ceux-ci sont très présents en automatique et que les méthodes formelles sont souvent incapables de les résoudre, E. Walter et moi-même avons pensé quelle avait sa place dans notre communauté. Ma thèse sest alors réorientée vers lapplication de cet outil pour la résolution de problèmes ensemblistes en automatique. Je lai ainsi appliqué pour résoudre des problèmes de stabilité, de commande robuste, destimation de régions de con ance et doptimisation globale.
Il semblerait quavec E. Walter, nous soyons les premiers de la communauté des automati-ciens à avoir utilisé le calcul par intervalles pour résoudre des problèmes destimation et de commande. Depuis, dautres chercheurs nous ont suivi dans cette voie comme la montré le congrès ayant pour sujet Applications of Interval Analysis to Systems and Control, qui a eu lieu à Girone, en février 1999.
Pendant cette thèse, jai introduit, les notions fondamentales dinversion ensembliste, de sous-pavages et de test dinclusion. Mes travaux se trouvent maintenant référencées et/ou utilisées par beaucoup dautres chercheurs.
² En estimation et observation : G. Chen, J. Wang et L.S. Shieh [CWS97] ; A.L. Dontchev, M. P. Polis ; V. M. Veliov ([DPV99]) ; J. P. Norton [Nor96] ; F. J. Rivas, S. T. Kolaczkowski, F. J. Beltran et D. B. Mclurgh [RKBM98].
² En automatique et robotique : A. Piazzi, G. Marro et Visioli [PM96], [PV98], [PV99] ; J. Yang et W. Wang [YW99] ; Garlo¤ et Zettler [ZG98], [Gar99] ; Y. Ohta [Oht99] ; Candev [Can96].
1.3 Activités de recherche
Juste après ma thèse, jai été nommé comme maître de conférences à la Faculté des Sciences de lUniversité dAngers. Le laboratoire de recherche, auquel je me suis rattaché, est le LISA (Laboratoire dIngénierie et des Systèmes Automatisés). Jy ai poursuivi ma recherche, dans la continuité de mon travail de thèse, avec un intérêt plus particulier pour les systèmes à événements discrets. Je suis resté quatre années à Angers puis jai obtenu, voici un an, une délégation vers le CNRS au LSS (Laboratoire des Signaux et Systèmes).
1.3.1 Coencadrement de thèses
Pendant ces cinq dernières années post-doctorales, jai coencadré trois doctorants1 qui ont
soutenu leur thèse :
² Olivier Didrit a préparé sa thèse [Did97] au LSS intitulée Analyse par inter-valles pour lautomatique ; résolution globale et garantie de problèmes non linéaires en robotique et en commande robuste. Son directeur de thèse était E. Walter et son travail a donné lieu aux publications [DJW95],[DJW97] et [JWD96]. Olivier a soutenu le 30 juin 1997 et occupe actuellement un poste dingénieur à Canal +. Nous continuons à collaborer puisque O. Didrit, M. Kie¤er, E. Walter et moi-même sommes actuellement en phase de rédaction dun livre sur les applications de lanalyse par intervalles à des problèmes dAutomatique. Ce livre doit être prêt en septembre 2000 et paraîtra chez Springer-Verlag.
² Olivier Lévêque a préparé sa thèse [L´98] à lHEUDIASYC de lUniversité de Technologie de Compiègne et son travail a donné lieu aux publications [LJMW97] et [JWLM99]. Son sujet de thèse était Méthodes ensemblistes pour la localisation de véhicules et son directeur de thèse était D. Meizel. Il a soutenu le 14 janvier 1998 et est actuellement ingénieur chez ALSTOM Belgium à Charleroi où il travaille sur la localisation des voitures sur un réseau ferré.
² Michel Kie¤er a préparé au LSS une thèse [Kie99] intitulée Estimation ensem-bliste par analyse par intervalles ; application à la localisation dun véhicule, sous la direction dE. Walter. Michel a soutenu sa thèse le 18 janvier 1999 et son tra-vail a donné lieu aux publications [JKWM98], [KJW98], [KJW99], [KJWM99d] et [KJWM99b], [KJWM99a] et [KJWM99c]. Depuis Septembre 1999, il est Maître de Conférences à lUniversité dOrsay.
Je coencadre actuellement Isabelle Braems qui prépare sa thèse, sous la direction dE. Walter, depuis septembre 1999 au LSS, toujours sur le domaine du calcul par intervalles. Elle vient de soutenir brillamment son stage de DEA [Bra99] sur le sujet : Estimation non-linéaire robuste et garantie grâce à lanalyse par intervalles ; Applications en Elect-rochimie.
1.3.2 Collaborations scienti ques
Jai développé de nombreuses autres collaborations scienti ques avec, principalement, des collègues et doctorants de lUniversité dAngers.
² Avec J. Burger (LISA), jai utilisé le calcul par intervalles comme outil de démonst-ration automatique de linclusion de deux ensembles dé nis par des inégalités. Nous avons ensuite appliqué notre méthode à lanalyse de stabilité de modèles incertains [JB99].
² Avec L. Hardouin et J.L. Boimond (LISA), jai proposé une nouvelle approche pour lestimation de paramètres des modèles à événements discrets [JBH99].
² J.L. Godet, A. Elliasmine, Y. Ledu¤ (POMA), E. Walter (L2S) et moi-même, avons travaillé sur lestimation de constantes de la physique à partir de données expéri-mentales [JGW+97].
² Avec A. Godon (LISA), jai mis au point une méthode capable de trouver (lorsquil existe) un chemin reliant deux points dun même ensemble. Lapproche, qui combine analyse par intervalles et théorie des graphes a été appliquée à la plani cation de trajectoire. Ce travail a été présenté [JG99] lors dun congrès intitulé Applications of Interval Analysis to Systems and Control, à Girone en février 1999, où jétais membre du comité de programme.
² Avec S. Brahim-Belhouari, G. Fleury (service des mesures de Supélec), M. Kie¤er et E. Walter (L2S), jai travaillé sur la sélection de modèle, dans un contexte à erreurs bornées [BBKF+99].
² Avec D. Meizel, O. Lévêque (HEUDIASYC, UTC), M. Kie¤er et E. Walter (L2S), jai développé un logiciel pour la localisation statique et dynamique dun robot mobile par des techniques ensemblistes. Cette collaboration est associée aux thèses de O. Lévêque et M. Kie¤er [LJMW97] [JWLM99] [JKWM98] [KJW98] [KJWM99c] [KJWM99b].
1.3.3 Comité de lecture de revues internationales
Jai évalué des articles pour Automatica, IEEE Transactions on Automatic Control, In-ternational Journal of Control et Reliable Computing.
1.3.4 Activités administratives
Jai participé au comité de programme du Workshop on Applications of Interval Analysis to Systems and Control, Girone, 24-26 février 1999.
Depuis deux ans, jappartiens aux commissions de spécialistes suivantes :
² 60-63ième section de lUniversité dAngers, en tant que suppléant (titulaire : F.
Chapeau, MCF, LISA).
² 61ième section de lUniversité de Compiègne, en tant que membre extérieur titulaire
1.4 Activités denseignement
De septembre 1994 à juin 1998, jai enseigné au département de Physique de la Faculté des Sciences dAngers. A titre dexemple, pour lannée scolaire 97-98 (cest-à-dire la dernière année où jai enseigné), mes enseignements (en heures) sont récapitulés dans le tableau ci-dessous. Niveau Matière CM TD TP Maîtrise Automatique2 15 15 30 Maîtrise Electronique3 11 11 30 Licence Electronique4 18 DEUG SM2 Thermodynamique5 44 DEUG SV-ST Electrostatique6 28
Soit un total denviron 192 heures équivalent TD. Outre les encadrements de thèse et de DEA, jai comptabilisé une trentaine de projets en Licence et Maîtrise de Physique et Application.
En 1994-95, jai participé très activement à mise en place des travaux pratiques de la formation CAPES de Physique.
En 1996, jai participé à la création dune salle informatique mise à la disposition des étudiants de Licence et Maîtrise de Physique et Applications.
Jai mis en place un nouvel enseignement (cours, TD et TP) dAutomatique en Maîtrise de Physique et Applications.
1.5 Présentation dudocument de recherche
Ce mémoire a pour vocation de présenter en détails une grande partie de mes travaux de recherche e¤ectués depuis ma thèse. Le l conducteur de lapproche que jai choisie est la représentation de chaque variable incertaine dun problème par un ensemble censé la contenir. Cette approche, dite ensembliste, est encore relativement con dentielle, et
2Approche interne : représentation détat, commandabilité, observabilité, stabilisation par placement
de pôles, observateur, simulation. Avec de nombreux TD sous Matlab.
3Composants électroniques élémentaires, portes logiques, bascules, compteurs, microprocesseur puis
programmation assembleur sur le microcontrôleur MC68HC11.
4Diodes, transistors, ampli-opérationnels, montages élémentaires, ltres. 5Premier et second principes, machines thermiques.
soppose à lapproche probabiliste beaucoup plus classique. Jusquà présent, une formula-tion ensembliste dun problème ne permettait denvisager une résoluformula-tion able que dans le cadre dexemples très particuliers. Or, si nous nous plaçons sous lhypothèse idéale que lon sait manipuler les ensembles comme on sait manipuler les réels, il est très relativement aisé de concevoir un algorithme ensembliste simple apportant la solution au problème. Le principal obstacle qui se présente alors est que la mise en oeuvre du calcul ensembliste semble hors de portée. Pourtant, comme nous allons le montrer dans ce document, en combinant les sous-pavages pour représenter les ensembles et lanalyse par intervalles comme outil de calcul sur ces sous-pavages, il est possible de mettre en oeuvre le calcul ensembliste. Pour illustrer cette approche, nous traiterons un problème de localisation statique et dynamique dun robot. Sur ce problème, qui a pourtant fait couler beaucoup dencre, seule lapproche ensembliste que nous suivrons est capable de donner une solution garantie.
Le document est structuré de la façon suivante. Le chapitre 2 présente lapproche ensem-bliste, à la fois comme un outil de modélisation dune variable incertaine et comme un outil de résolution able de problèmes non-linéaires. Dans ce même chapitre, les sous-pavages seront introduits a n dapproximer convenablement les sous-ensembles qui nous intéressent et de les rendre facilement manipulables par un ordinateur. Au chapitre 3, les outils de base fournis par lanalyse par intervalles (fonction dinclusion, test dinclusion et opérateur de réduction) seront rappelés. Ils permettront une mise en oeuvre du calcul ensembliste, comme nous le montrerons au chapitre 4. Le chapitre 5 sintéressera à lappli-cation des techniques ensemblistes à lestimation et à lobservation. Plus particulièrement, nous traiterons lexemple de la localisation dun robot mobile sur lequel jai travaillé avec les trois doctorants que jai coencadrés. Les notations et sigles utilisés sont donnés après la conclusion et avant lannexe.
1.6 Liste des publications
Les publications dont les numéros apparaissent en gras sont données dans le document annexe.
Revues internationales avec comité de lecture
[1] L. Jaulin et E. Walter (1993). Guaranteed nonlinear parameter estimation from bounded-error data via interval analysis, Math. Comput. Simulation, 35, 123-127.
[2] L. Jaulin et E. Walter (1993). Set inversion via interval analysis, Automatica, 29(4), 1053-1064.
[3] L. Jaulin et E. Walter (1993). Guaranteed nonlinear parameter estimation via in-terval computations, Inin-terval computation, 3, 61-75.
[4] E. Walter et L. Jaulin (1994). Guaranteed characterization of stability domains via set inversion, IEEE Trans. on Autom. Control, 39(4), 886-889.
[5] L. Jaulin et E. Walter (1996). Guaranteed tuning, with application to robust control and motion planning. Automatica, 32(8), 1217-1221.
[6] O. Didrit, L. Jaulin et E. Walter (1995). Guaranteed analysis and optimization of parametric systems, European Journal of Control, 3, 66-80.
[7] L. Jaulin et E. Walter (1997). Global numerical approach to nonlinear discrete-time control, IEEE Trans. on Autom. Control, 42, 872-875.
[8] L. Jaulin, J.L Godet, E. Walter, A. Elliasmine et Y. Ledu¤ (1997). Light scattering data analysis via set inversion, Journal of Physics A: Mathematical and General, 30, 7733-7738.
[9] L. Jaulin et J. Burger (1999), Proving stability of uncertain parametric models, Automatica, 35(4).
[10] L. Jaulin, J.L. Boimond et L. Hardouin (1999), Estimation via set-inversion: ap-plication to discrete-event systems, Reliable Computing, 5(2), 165-173.
[11] L. Jaulin et E. Walter (1999), Guaranteed bounded-error parameter estimation for nonlinear models with uncertain experimental factors, Automatica, 35(5).
[12] M. Kie¤er, L. Jaulin, E. Walter et D. Meizel, Robust autonomous robot localization using interval analysis, accepté par Reliable Computing.
[13] L. Jaulin, E. Walter, O. Lévêque et D. Meizel, Set inversion for  algorithms, with application to guaranteed robot localization, soumis à Automatica.
[14] L. Jaulin, M. Kie¤er, E Walter et D. Meizel, Guaranteed robust nonlinear estima-tion, with application to robot localizaestima-tion, soumis à Automatica.
[15] M. Kie¤er, L. Jaulin et E. Walter, Guaranteed recursive nonlinear state estimation using interval analysis, soumis à IEEE TAC.
[16] L. Jaulin, Interval constraint propagation with application to bounded-error esti-mation, soumis à Automatica.
[17] L. Jaulin, Path planning using intervals and graphs, soumis à Reliable Computing. [18] L. Jaulin, Reliable Minimax Parameter Estimation, soumis à Reliable Computing. Congrès avec comité de lecture
[19] L. Jaulin. et E. Walter (1992). Set inversion, with application to guaranteed non-linear estimation and robust control, Proc. of the Workshop on Modeling Techniques for Uncertain Systems, Sopron.
[20] L. Jaulin et E. Walter (1993). Guaranteed nonlinear estimation and robust stability analysis via set inversion. Proc. 2nd European Control Conference, Groningen, 818- 821. [21] L. Jaulin et E. Walter (1993). Guaranteed nonlinear parameter estimation via inter-val computations, Conference on Numerical Analysis with Automatic Result Veri cation, Lafayette. (pas dactes).
[22] O. Didrit, L. Jaulin et E. Walter (1995). Guaranteed analysis and optimization of parametric systems, with application to their stability degree, Proc. 2nd European Control Conference, 1412-1417.
[23] L. Jaulin, E. Walter et O. Didrit (1996). Guaranteed robust nonlinear parame-ter bounding, CESA96 IMACS Multiconference (Symposium on Modelling, Analysis and Simulation), Lille, 2, 1156-1161.
[24] O. Lévêque, L. Jaulin, D. Meizel et E. Walter (1997). Vehicle localization from inaccurate telemetric data: a set inversion approach, Proc. 5th IFAC Symp. on Robot Control SY.RO.CO.97, Nantes, France, 1, 179-186.
[25] M. Kie¤er, L. Jaulin, E. Walter et D. Meizel, Guaranteed mobile robot tracking using interval analysis, MISC 99, Girona, Espagne, 347-360.
[26] L. Jaulin et A. Godon. Motion planning using interval analysis, MISC 99, Girona, Espagne, 335-346.
using interval analysis, CDC 98, Tampa, Floride, 3966-3971.
[28] S. Brahim-Belhouari, M. Kie¤er, G. Fleury, L. Jaulin et E. Walter. Model selection via worst-case criterion for nonlinear bounded-error estimation. Proceedings 16th {IEEE} Instrumentation and Measurement Tech. Conf., Venise, 24-26 mai 1999.
[29] M. Kie¤er, L. Jaulin, E. Walter et D. Meizel (1999). Localisation et suivi garantis dun robot par analyse par intervalles, JDA99.
Chapitre douvrages collectifs
[30] L. Jaulin et E. Walter (1994). Set inversion, with application to guaranteed non-linear estimation and robust control, Modeling Techniques for Uncertain Systems. A.B. Kurzhanski, V.M. Veliov (Eds), Birkhäuser, Boston. 3-20.
[31] L. Jaulin et E. Walter (1996). Guaranteed nonlinear set estimation via interval analysis, Bounding Approaches to System Identi cation, M. Milanese, J. Norton, H. Piet-Lahanier et E. Walter (Eds.), Plenum, New York. 363-382.
[32] M. Kie¤er, L. Jaulin, E. Walter et D. Meizel (1999). Nonlinear Identi cation Based on Unreliable Priors and Data, with Application to Robot Localization, In A. Garulli, A. Tesi and A. Vicino (eds.), Robustness in Identi cation and Control, Springer, Londres, 190-203
Lapproche ensembliste
2.1 Introduction
Dans ce chapitre, nous allons présenter les principes de lapproche ensembliste et montrer son intêret dans les sciences pour lingénieur. Une comparaison avec lapproche proba-biliste, plus classique, sera alors entreprise. Les bases théoriques du calcul ensembliste seront données, mais nous ferons momentanément limpasse sur sa mise en oeuvre car celle-ci nécessite lintroduction du calcul par intervalles, présenté au prochain chapitre. Pour approximer les ensembles et les représenter en machine, nous dé nirons la notion de sous-pavages en section 2.6.
2.2 Motivations
Les ensembles, qui vont nous intéresser, sont des sous-ensembles de Rn. Considérons un
sous-ensemble X de Rn.
² Dun côté, X peut représenter une variable vectorielle incertaine, que lon sait conte-nue dans X. Lensemble rentre ainsi en compétition avec la densité de probabilité, classiquement utilisée pour modéliser lincertitude.
² De lautre côté, X peut représenter tous les points quil contient. Ainsi, une propriété établie sur lensemble X sapplique à tous ses éléments. Lensemble o¤re ainsi la possibilité dobtenir la garantie des résultats tout comme le permet le calcul formel. Lapproche ensembliste o¤re donc une alternative à la fois à lapproche probabiliste et à lapproche formelle. Cette double nature de lensemble, développée dans cette section,
sera régulièrement exploitée dans ce document.
2.2.1 Représentation dune variable incertaine
Dans ce paragraphe, nous allons présenter et confronter deux approches statistiques (cest-à-dire capables de manipuler des variables incertaines reliées par des contraintes) : lap-proche probabiliste et laplap-proche ensembliste.
Lapproche probabiliste est la plus répandue en mathématiques comme dans les sciences pour lingénieur. Dans cette approche, une variable réelle ou vectorielle x de Rn, est
représentée (ou codée) par une densité de probabilité (appelée aussi loi), cest-à-dire, par une fonction ¼ : Rn ! R+ telle que R
Rn¼ (x) dx = 1. Ce codage nous donne à la fois
un ensemble, appelé support, X = fx 2 Rnj¼(x) 6= 0g qui contient à coup sûr la variable
incertaine x; mais il nous donne aussi une information sur la manière dont est distribuée cette variable aléatoire sur ce support.
Dans une approche ensembliste cette variable est représentée uniquement par un ensemble X, appelé ensemble de vraisemblance ou domaine , supposé contenir x: Notons quil est possible que ce domaine contienne des zones où lon sait que x ne se trouve pas, comme lillustre lexemple suivant.
Exemple 2.2.1 Supposons que pour une variable réelle x, le domaine soit X1= [0; 1] [
[2; 3]. On peut, par commodité dans nos calculs, vouloir avoir un domaine qui soit un intervalle. On prendra alors X2 = [0; 3] qui est aussi un domaine pour x puisquil le
contient et pourtant, X2 contient une zone ]1; 2[ où x ne peut se trouver. }
La représentation ensembliste est donc plus pauvre que la représentation probabiliste, mais elle permet une manipulation beaucoup plus aisée des variables aléatoires. De plus, elle demande moins de connaissances statistiques sur ces variables et permet ainsi de traiter une classe beaucoup plus grande de problèmes.
Tentons maintenant dexpliquer, en nous aidant dun exemple académique, pourquoi une représentation ensembliste permet une manipulation plus aisée des variables aléatoires, que lapproche probabiliste.
Exemple 2.2.2 Considérons trois variables aléatoires réelles x; y et z reliées par la cont-rainte z = x + y. Cherchons à déduire les propriétés statistiques de z à partir de celles de x et y par les approches probabiliste puis ensembliste.
a) Approche probabiliste. Supposons que x et y ont des densités de probabilité uni-formes ¼ (x) = 1=5 sur [0; 5] et ¼ (y) = 1=2 sur [1; 3]. Pour calculer ¼ (z), il nous faut une
information sur le comportement conjoint de x et y. Nous allons donc supposer que x et y sont indépendantes. Ainsi, la densité du couple est uniforme avec ¼ (x; y) = 1=10 sur le pavé [0; 5] £ [1; 3]. Un calcul dintégrale élémentaire donne
¼ (z) = 0 si z · 1 (2.1) ¼ (z) = 101 (z ¡ 1) si z 2 [1; 3] (2.2) ¼ (z) = 1 5 si z 2 [3; 6] (2.3) ¼ (z) = 1 10 (¡z + 8) si z 2 [6; 8] (2.4) ¼ (z) = 0 si z ¸ 8 (2.5) Mais ce calcul dintégrale est généralement très di¢cile à e¤ectuer sauf dans des cas particuliers comme lorsque le couple (x; y) est gaussien ou uniforme.
b) Approche ensembliste. Lincertitude associée à x et y est donnée par un ensemble. Pour être cohérent avec a), nous allons prendre lintervalle [x] = [0; 5] pour x et lintervalle [y] = [1; 3], pour y. Il est alors clair que z est dans lintervalle [z] = [0 + 1; 5 + 3] = [1; 8]. Sur cet exemple, lapproche ensembliste engendre des calculs plus simples et demande moins dhypothèses sur le comportement conjoint que lapproche probabiliste. } Représenter un vecteur aléatoire x par un ensemble X, ne revient pas à supposer que la loi ¼ (x) est uniforme sur x. Cela revient juste à supposer que x est dans X et rien de plus. En terme probabiliste, cela signi e que le support de la loi ¼ (x) est inclus dans X. Dans lexemple 2.2.2, la variable aléatoire z est représentée par lintervalle [1; 8], et pourtant, ¼ (z) nest pas uniforme sur [1; 8].
Faisons maintenant une comparaison entre les approches probabiliste et ensembliste : ² Les manipulations non-linéaires sont plus simples avec lapproche ensembliste quavec
lapproche probabiliste. Le calcul de ¼ (z) ; de lexemple 2.2.2, est élémentaire parce que nous avons considéré le cas uniforme et une dépendance linéaire entre x; y et z. Mais en général, la moindre non-linéarité rend lapproche probabiliste di¢cilement exploitable. Si dans lexemple 2.2.2, z est donné par z = x2:y, le calcul de ¼ (z)
devient très di¢cile. Avec lapproche ensembliste, on obtient immédiatement, pour la variable z; lintervalle [z] = [0; 5]2: [1; 3] = [0; 25] : [1; 3] = [1; 75] (ce calcul utilise
lanalyse par intervalles qui sera donnée dans le chapitre suivant).
² Lapproche probabiliste réclame des connaissances sur les lois conjointes, qui sont souvent di¢ciles à obtenir en pratique. Dans notre exemple 2.2.2 où z = x+y, nous avons supposé que x et y étaient indépendantes. Si cette information navait pas
été disponible, nous naurions pas pu obtenir une représentation probabiliste pour z. En revanche, lapproche ensembliste ne réclame aucune information statistique sur le couple (x; y). Notons que par simplicité, il est souvent supposé que certaines variables sont indépendantes dans le but davoir les densités conjointes1. Or très
souvent, cette indépendance ne correspond pas à la situation réelle. Par exemple, lorsquun même capteur e¤ectue une série de mesures, le biais systématique du capteur engendre une dépendance entre toutes les erreurs de mesure. Le rajout de telles hypothèses produit alors des résultats di¢ciles à interpréter.
² Il arrive fréquemment que lerreur de mesure sur une donnée expérimentale soit donnée en terme de tolérance par lappareil de mesure et non en terme de densité de probabilité. Dans ce cas, lapproche ensembliste est une approche naturelle pour traiter les mesures fournies par le capteur. Par contre, lorsque les propriétés probabi-listes des variables aléatoires sont connues, il est clair quutiliser une approche ensem-bliste peut savérer inadapté. Dans les problèmes linéaires gaussiens, par exemple, les calculs probabilistes sont élémentaires et très e¢caces, si bien quune approche ensembliste ne présente aucun intérêt.
² Lincertitude due aux erreurs numériques peut être incorporée lors du calcul des domaines, ce qui semble être très di¢cile pour lapproche probabiliste. Si x2X, y2Y, et z = x + y, le domaine Z pour z, sera donné par
Z = X + Y + E , fx + y + ejx2X; y2Y; e2Eg (2.6) où E est lensemble représente le pessimisme introduit lors du calcul de Z.
² En n une représentation ensembliste permet lintroduction de formalismes et dou-tils nouveaux autorisant la résolution de problèmes non-linéaires dont le traitement semble impensable avec une approche probabiliste.
Malgré tous ses avantages, lapproche ensembliste reste encore con dentielle dans le mi-lieu des sciences pour lingénieur. On peut la trouver par exemple en estimation où elle est connue sous le nom dapproche à erreurs bornées (voir par exemple, [Wal90] et [MNPLW96]) et en commande robuste [Bar94].
1Considérons 3 variables aléatoires x; y et z ayant pour lois ¼ (x) ; ¼ (y) et ¼ (z). La loi conjointe
¼ (x; y; z) ; qui représente le comportement statistique collectif de ces trois variables, ne peut se déduire des lois ¼ (x) ; ¼ (y) et ¼ (z) que dans certains cas particuliers. Par exemple lorsque x; y et z sont indépendantes, on a ¼ (x; y; z) = ¼ (x) :¼ (y) :¼ (z).
2.2.2 Recouvrement dun espace de recherche
Beaucoup dalgorithmes, utilisés dans les sciences pour lingénieur, consistent à balayer un espace de recherche (contenant une in nité non dénombrable de points) dans le but de trouver des solutions à un problème ou bien de montrer quune propriété est valide pour tout cet espace. Une approche ponctuelle ne permet danalyser quune in me portion de cet espace de recherche. Rien ne permet alors de conclure avec certitude, sauf pour des cas particuliers (problèmes convexes ou linéaires), que la ou les solutions du problème ont été trouvées.
Or, lespace de recherche peut fréquemment être recouvert par un nombre ni de sous-ensembles simples, sur lesquels on sait calculer, et qui eux, contiennent une in nité de points. On peut ainsi résoudre avec garantie des problèmes de démonstration automatique ou de recherche de solutions de problèmes non-linéaires, en saidant des principes suivants :
² Si une même propriété est établie pour chacun des sous-ensembles dune partition de lespace de recherche, alors cette propriété est valide pour lespace de recherche tout entier.
² Si lon arrive à prouver quun sous-ensemble ne contient aucune solution du pro-blème, on peut léliminer de lespace de recherche.
² Si lon narrive pas à prouver quun sous-ensemble ne contient aucune solution, on peut toujours le décomposer en plusieurs sous-ensembles sur lesquels on recommence une analyse.
Parmi la classe des problèmes qui véri ent ces principes, on trouve les algorithmes de type branch and bound ainsi que tous les algorithmes qui seront présentés dans ce manuscrit. Notons que les méthodes formelles permettent, elles aussi, dobtenir des résultats garantis. Mais la classe des problèmes quelles peuvent traiter en un temps convenable est très réduite. Nous verrons que pour les applications qui vont nous intéresser au chapitre 5, il est impensable despérer obtenir des résultats avec des méthodes formelles.
2.3 Opérations sur les ensembles
Les opérations que lon peut e¤ectuer sur les ensembles sont de deux types :
² Les opérations étendues : Ce sont des opérations qui sont déjà dé nies pour les élements des ensembles considérés et dont la dé nition est étendue aux ensembles (addition, produit scalaire, ...).
² Les opérations ensemblistes pures : ces opérations ont peu de sens si lon considère les éléments des ensembles (union, intersection, produit cartésien : : :).
2.3.1 Les opérations étendues
Soient X un ensemble de Rn, Y un ensemble de Rm et f : Rn ! Rm; une fonction
vectorielle. On dé nit
limage directe de X par f f (X) , fy 2 Rmj9x 2X; f(x) = yg;
limage inverse de Y par f f¡1(Y) , fx 2 Rnj9y2Y; f(x) = yg: (2.7)
Parmi les propriétés importantes de ces ensembles rappelons
f (X1\ X2) ½ f (X1) \ f (X2) ; (2.8) f (X1[ X2) = f (X1) [ f (X2) ; (2.9) f¡1(Y 1\ Y2) = f¡1(Y1) \ f¡1(Y2) ; (2.10) f¡1(Y 1[ Y2) = f¡1(Y1) [ f¡1(Y2) ; (2.11) f¡f¡1(Y)¢ ½ Y; (2.12) f¡1(f (X)) ¾ X: (2.13)
De même, les opérateurs classiques peuvent être aussi dé nis pour les ensembles. Ainsi, si X et Y sont deux sous-ensembles de Rn;
X + Y , fx + y; x 2 X; y 2 Yg: (2.14) Notons que ce type dextension peut entraîner certaines confusions. Par exemple X ¡ X doit être compris comme lensemble fx ¡ y; x 2 X; y 2 Xg et non pas comme lensemble fx ¡ x; x 2 Xg = f0g. Pourtant, si f(x) = x ¡ x; f (X) = f0g.
2.3.2 Les opérations ensemblistes pures
Elles regroupent, par exemple, la projection canonique, lunion, lintersection et le produit cartésien. Dé nissons ces opérations dans le cas où X et Y sont deux sous-ensembles de Rn et Rm.
proji(X) , fxi 2 Rj9x = (x1; : : : ; xi; : : : ; xn)T 2 Rn; x 2 Xg; (2.15)
X \ Y , fx 2 Rnjx 2 X et x 2 Yg, avec n = m; (2.16)
X [ Y , fx 2 Rnjx 2 X ou x 2 Yg, avec n = m; (2.17)
De plus, nous utiliserons les relations binaires ensemblistes classiques
X ½ Y , 8x 2 X; x 2 Y; (2.19) X = Y , X ½ Y et Y ½ X: (2.20)
2.3.3 Pessimisme dû aux occurrences multiples
Une expression ensembliste du type
Z = X ¡ X (2.21) peut a priori sinterpréter de la façon suivante
Z = fx ¡ x; x 2 Xg : (2.22) Ainsi Z se réduit à un singleton qui contient pour seul élément le vecteur nul. Nous lavons vu, cette interprétation est fausse et la confusion vient du fait que, dans lexpression ensembliste, des variables sont associées à ces ensembles. Lambiguïté disparaît si les ensembles sont manipulés sans les nommer par lintermédiaire dune variable. Par exemple, il nous semble naturel décrire Z = [1; 2] ¡ [1; 2] , Z = [¡1; 1] car lintervalle [1; 2] na pas été nommé par une variable X. Lexpression (2.21) doit donc se comprendre ainsi
Z = ff (x; y) ; x 2 X; y 2Xg avec f(x; y) = x ¡ y: (2.23) Lécriture dune expression ensembliste oublie les relations de dépendance qui peuvent exister entre les variables représentées par les ensembles. Ce problème est connu sous le nom du problème de dépendance et a été abondamment étudié dans la littérature (voir par exemple [Moo79]). Il faudra donc résister à la tentation décrire des équivalences2 du
type
Z = (X + Y) ¡ X , Z + X = (X + Y): Par contre, il est correct décrire
X + X ¡ X ¡ X =2 (X ¡ X) : (2.24) Lorigine mathématique de ces ambiguïtés vient du fait que beaucoup de propriétés de calcul dans Rn ne se généralisent pas aux parties P (Rn) de Rn: Par exemple (Rn; +) est
un groupe, alors que (P (Rn) ; +) est seulement un monoïde car, pour tout X di¤érent
du singleton f0g (élément neutre pour laddition), il nexiste pas densemble Y tel que
2Cette équivalence est bien évidemment fausse. Pour sen convaincre, on peut construire un
contre-exemple en prenant Y =f0g; X =[0; 1] et Z = [¡1; 1]: La proposition de gauche de trouve satisfaite, contrairement à la proposition de droite.
X + Y =f0g. Puisque la plupart des propriétés algébriques du calcul dans Rn; ne
séten-dent pas aux ensembles de Rn; nous nous e¤orcerons, dans ce manuscrit, déviter toute
manipulation algébrique sur les ensembles. Soit f une fonction Rn! R; (x
1; : : : ; xn) ! y dont on connaît une expression permettant
de lévaluer. Si F(X1; : : : ; Xn) est le résultat dun calcul ensembliste sur X, utilisant cette
expression pour f. Alors, on a linclusion
f(X1; : : : ; Xn) ½ F(X1; : : : ; Xn); (2.25)
où
f(X1; : : : ; Xn) = ff (x1; : : : ; xn) ; x1 2 X1; : : : ; xn2 Xng :
On dit que lévaluation ensembliste est pessimiste. Cette inclusion peut être une égalité dans certains cas particuliers, mais en général, elle ne lest pas. Cela provient du problème de dépendance que nous rappelons : Si, dans lexpression de f; certains xi apparaîssent
plusieurs fois, alors f(X) ½ F (X), sinon, f(X) = F (X). Exemple 2.3.1 Si f (x1; x2) = x1+ x2¡ x1;
f(X1; X2) = fx1+ x2 ¡ x1jx1 2 X1; x2 2 X2g = fx2jx2 2 X2g = X2: (2.26)
Alors que
F(X1; X2) = X1+ X2¡ X1 = fx1+ x2 ¡ x3jx1 2 X1; x2 2 X2; x3 2 X1g (2.27)
contient f(X1; X2). La dépendance entre x1 et x3 (qui est x1 = x3) napparaît pas dans cette
expression rajoutant ainsi un degré de liberté dans la fabrication de lensemble F(X1; X2).
2.4 Représentation des ensembles
2.4.1 Di¤érents types de représentation
La représentation exacte ou approchée de sous-ensembles de Rn est fondamentale dans
notre approche. Elle doit être su¢samment simple pour permettre des manipulations e¢caces des sous-ensembles. Elle doit également être su¢samment riche pour représenter tous les sous-ensembles qui nous intéressent et qui sont parfois non connexes et avec tout type de formes. Parmi les approches classiques pour représenter les sous-ensembles de Rn,
² La représentation par équations et inéquations : Cette représentation permet une manipulation exacte des ensembles. Malheureusement, les algorithmes qui en décou-lent utilisent le calcul formel et ne sappliquent quà une classe réduite déquations ou dinéquations. Ils sont souvent incapables de réaliser certaines opérations élémen-taires sur les ensembles (essayez par exemple de mettre sous forme dinéquations la somme de deux ellipses de R2). De plus, la complexité de ces algorithmes (en
temps de calcul et en place mémoire) les rend souvent inexploitables, même pour des prob lèmes académiques.
² La représentation par nuage de points : Un ensemble X est représenté par un nuage de points contenus dans X. Ces points peuvent avoir été obtenus par un tirage aléa-toire (approche Monte-Carlo), ou par un balayage déterministe. Cette représentation est très approximative et linterprétation du résultat est très souvent arbitraire. Que penser par exemple lorsque le nuage est vide? Dans ce cas, la seule propriété de X que lon peut garantir est quil existe des points qui ne sont pas dans X. En revanche, la manipulation des nuages de points est très facile.
² La représentation par recouvrement : Il convient tout dabord de dé nir une classe de sous-ensembles de Rn que lon sait représenter et manipuler aisément. Les éléments
de cette classe sont appelés des récipients (car ils sont souvent intéressants de par ce quils sont censés contenir). Cette classe peut être lensemble des ellipsoïdes, des pavés ou des polytopes, zonotopes (voir gure 2.1) : : : Pour une classe de récipients donnée, un ensemble X peut généralement être représenté par une union de récipients qui recouvre complètement X. Beaucoup de caractéristiques intéressantes de X se trouvent contenues dans cette union. Par exemple, nous avons la garantie que si le recouvrement est vide, lensemble X est lui aussi vide. Dans ce document, les récipients considérés seront les pavés de Rn:
Figure 2.1: Un zonotope de R3:
² La représentation par encadrement : Dans cette approche présentée dans ma thèse [Jau94], on considère une classe de récipients telle que tout compact X de Rn peut
être encadré par deux unions de récipients X¡ et X+ dans le sens où
X¡ ½ X ½ X+: (2.28)
Une connaissance du couple [X¡; X+] nous donne de précieuses informations sur X.
Par exemple, vol(X¡) · vol(X) · vol(X+), ou encore, si X+est vide, alors X est aussi
vide. On peut même en déduire des informations sur les propriétés de connexité de X. Par exemple, si X¡ et X+ sont constitués chacun de deux composantes connexes
disjointes : X¡ = X¡
1[X¡2 et X+ = X+1 [X+2, et si, de plus, X¡1 ½ X+1, X¡2 ½ X+2 alors,
X est non connexe. Notons que de telles informations sur la connexité ne seraient pas disponibles avec les représentations par nuage de points ou par recouvrement. Dans ce manuscrit, nous allons principalement utiliser une représentation par recouvre-ment où les récipients sont des pavés.
2.4.2 Distances entre compacts
Pour évaluer la qualité dune représentation, il convient de dé nir di¤érentes distances entre deux compacts de Rn. Munissons Rn de la distance
L1(x; y) , max
i2f1;:::;ngjyi¡ xij (2.29)
La proximité de A à B est dé nie par h0
1(A; B) , inf
©
r 2 R+jA ½ B + rUª (2.30)
où U est la sphère unité de (Rn; L
1). La distance de Hausdor¤ (voir [Ber79]) entre deux
sous-ensembles A à B de Rn est donnée par
h1(A; B) , max©h01(A; B) ; h01(B; A)
ª
(2.31) La distance de Hausdor¤ est une distance dans lensemble des compacts de Rnpuisquelle
véri e
(i) séparabilité h1(A; B) = 0 ) A = B
(ii) symétrie h1(A; B) = h1(B; A)
(iii) inégalité triangulaire h1(A; C) · h1(A; B) + h1(B; C)
(2.32)
2.5 Approximation ducalcul ensembliste
Considérons une classe R de sous-ensembles de Rn dont les éléments sont appelés
ensembliste, génère un sous-ensemble de Rn qui nest, en général, plus un récipient. Par
exemple, si les récipients considérés sont les ellipses de R2, la somme de deux ellipses nest
généralement plus une ellipse. Pour rendre les opérations internes dans R, on peut utiliser le calcul extérieur :
fR(X1; : : : ; Xn) = ¤ (f (X1; : : : ; Xn)) (2.33)
où X1; : : : ; Xn sont des récipients et ¤ (A) désigne le plus petit récipient (au sens de
linclusion) qui contient A. Lensemble ainsi obtenu donne des informations sur le calcul ensembliste idéal associé. Lopérateur ¤ peut être mis en oeuvre pour des opérations relativement élémentaires. Lorsquon a a¤aire à la composition de fonctions élémentaires, un pessimisme est introduit :
goh (X1; : : : ; Xn) ½ ¤ (goh (X1; : : : ; Xn)) ½ ¤ (g (¤h (X1; : : : ; Xn))) (2.34)
De ce fait, comme beaucoup de fonctions intervenant dans des problèmes concrets sont des compositions de fonctions élémentaires, il est souvent aisé de trouver un récipient qui contienne lensemble Y résultant dun calcul ensemb liste. Par contre, il est rare quon puisse avoir le plus petit.
2.6 Les sous-pavages
Les sous-pavages forment une classe densembles de Rn faciles à manipuler à laide dun
ordinateur et qui permettent dapproximer avec une précision arbitraire une grande classe de sous-ensembles compacts3de Rntout en conservant certaines de leurs propriétés comme
la forme, la connexité : : : Comme un sous-pavage est formé de pavés, il convient, tout dabord, de xer les notations et les dé nitions pour les pavés. Ensuite, nous introduirons mathématiquement les notions de sous-pavage et de pavage et décrirons leur représentation en machine ainsi que quelques algorithmes élémentaires qui serviront à les manipuler.
2.6.1 Pavés
Un pavé ou vecteur intervalle [x] de Rn est le produit cartésien de n intervalles :
[x] = [x1; ¹x1] £ ¢ ¢ ¢ £ [xn; ¹xn] = [x]1£ ¢ ¢ ¢ £ [x]n: (2.35)
Lensemble des pavés est dénoté IRn. La longueur w([x] ) (en anglais : width) dun pavé
[x] est la longueur du plus grand de ses côtés. Posons
j , minfij¹xi¡ xi = w([x] )g (2.36)
Dé nissons les deux pavés L [x] et R [x] comme suit : L [x] , [x1; ¹x1] £ ¢ ¢ ¢ £ h xj;xj+¹xj 2 i £ ¢ ¢ ¢ £ [xn; ¹xn] R [x] , [x1; ¹x1] £ ¢ ¢ ¢ £ hx j+¹xj 2 ; ¹xj i £ ¢ ¢ ¢ £ [xn; ¹xn] (2.37) L [x] est appelé ls gauche de [x] et R [x], ls droit de [x]. Ici L et R peuvent être vus comme des opérateurs de IRn vers IRn. Lopération qui consiste à générer ces deux ls
à partir de [x] est appelée bissection de [x]. Les deux sous-pavés L [x] et R [x] sont dits frères. Par exemple, frère(RRRL [x]) = LRRL [x]. La réuni cation est lopération qui consiste à réunir deux pavés frères L [x] et R [x] pour nen former quun seul, le père [x]. On notera [x] := (L [x] jR [x]).
Soit X un ensemble compact de Rn. On appelle pavé enveloppe de X le plus petit pavé
qui contient X. On le notera [X]. Soient X et Y deux compacts de Rn, le pavé enveloppe
de leur union est dé ni par
A t B = [A [ B] : (2.38)
2.6.2 Pavages et sous-pavages
Un sous-pavage dun pavé [x] ½ Rn est une union de sous-pavés de [x] qui ne se
chevau-chent pas. Néanmoins, deux pavés dun même sous-pavage peuvent avoir une intersection non-vide (cest le cas sils ont une frontière commune), mais, leurs intérieurs sont tous deux à deux disjoints. Lorsquun sous-pavage bP recouvre tout le pavé [x], bP est appelé pavage de [x]: Un sous-pavage de [x] est dit régulier si chacun de ses pavés peut être obtenu par bissections successives de [x]. Lensemble de tous les sous-pavages réguliers de [x] est dénoté SPR([x]). Les sous-pavages réguliers permettent dapproximer une très grande classe densembles compacts de Rn et, comme nous allons le montrer, ils
peu-vent être manipulés par un ordinateur très facilement. Nous allons aussi manipuler des sous-pavages non réguliers, mais les opérations ensemblistes associées comme lintersec-tion ou le test dappartenance dun pavé seront beaucoup plus lourdes. Un pavage régulier
b
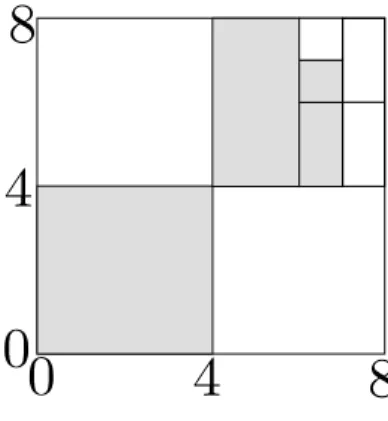
P = f[x]1; : : : ; [x]9g du pavé [x] = [0; 8] £ [0; 8] est représenté sur la gure 2.2.
Les boîtes grises forment un sous-pavage régulier bQ de [x] = [0; 8] £ [0; 8]: Remarquons que bQ a un double statut : il peut être vu comme une liste nie de pavés
b
Q = fLL[x]; LRR[x]; LLRRR[x]; LLRRRR[x]g
= f[0; 4] £ [0; 4]; [4; 6] £ [4; 8]; [6; 7] £ [4; 6]; [6; 7] £ [6; 7]g; (2.39) et dans ce cas, on notera [0; 4]2 2 bQ et [0; 1]2 =2 bQ. Mais bQ peut aussi être vu comme un
sous-ensemble de R2. Ainsi, on notera [0; 1]2 ½ bQ ½ R2. Ce double statut peut parfois
Figure 2.2: Sous-pavage et pavage réguliers dun pavé
lorsque bP = f[0; 3] ; [4; 5]g et bQ = f[0; 9]g? Elle est vraie si bP et bQ sont vus comme des sous-ensembles de R, mais fausse sils sont vus comme des listes dintervalles. Dans ce manuscrit, nous ferons en sorte que de telles ambiguïtés ne se présentent pas et puissent être levées en saidant du contexte.
A partir dun sous-pavage régulier bQ de SPR([x]), on peut engendrer deux sous-pavages L bQ = f[y] 2 bQj [y] ½ L[x]g; (2.40) R bQ = f[y] 2 bQj [y] ½ R[x]g: (2.41) Ces deux sous-pavages sont appelés ls gauche et droit respectivement. Par exemple, dans le sous-pavage de la gure 2.2, on a
L bQ = fLL[x]g = f[0; 4] £ [0; 4]g
R bQ = fLRR[x]; LLRRR[x]; LLRRRR[x]g
= = f[4; 6] £ [4; 8]; [6; 7] £ [4; 6]; [6; 7] £ [6; 7]g:
(2.42) Les sous-pavages seront utilisés pour approximer les sous-ensembles de Rn. La gure 2.3
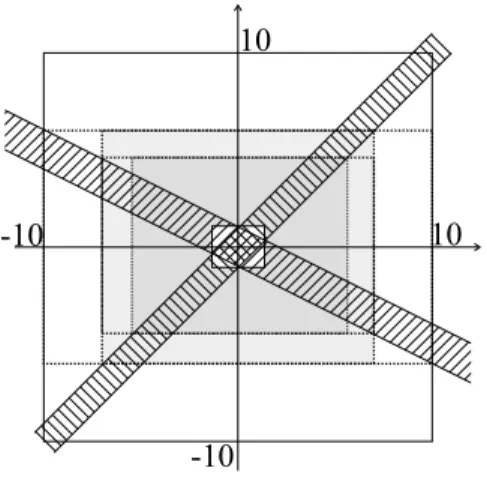
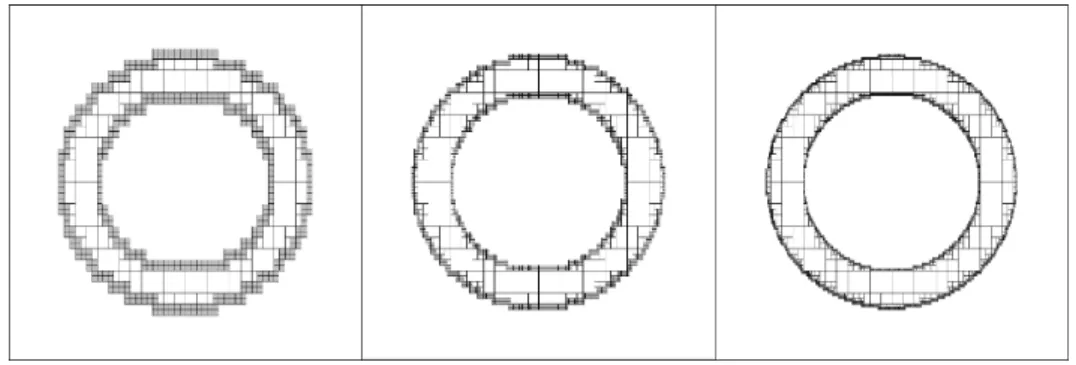
donne une illustration de lencadrement par sous-pavages de lanneau
S = f(x; y)jx2+ y2 2 [1; 2]g, (2.43)
avec des précisions di¤érentes. Le cadre correspond au pavé [¡2; 2] £ [¡2; 2]. Le sous-pavage ¢bS formé des pavés en gris contient la frontière de S alors que le sous-sous-pavage bS¡
formé des pavés blancs dans lanneau est inclus dans S: On a donc lencadrement
bS¡ ½ S ½ bS+ avec bS+, bS¡[ ¢ bS: (2.44)
Les sous-pavages ne peuvent généralement approximer avec une précision raisonnable que des compacts X de Rn, où n est faible (typiquement inférieur à 5). Toutefois, lorsque X
est minuscule, quelques pavés peuvent su¢re pour son approximation, même lorsque la dimension de X est grande.
Figure 2.3: Encadrement dun ensemble entre deux sous-pavages, pour di¤érentes préci-sions
2.6.3 Représentation binaire dun sous-pavage régulier
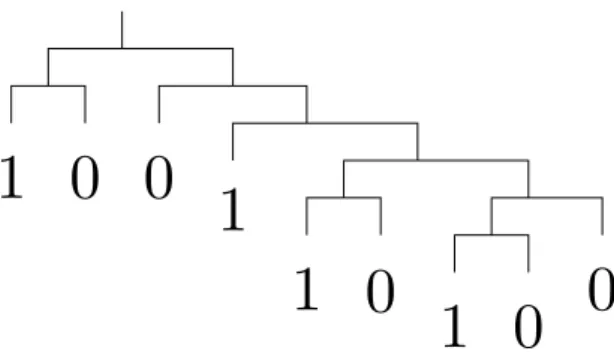
En machine, un sous-pavage régulier peut être représenté par un arbre binaire. La gure 2.4 contient larbre associé au sous-pavage de la gure 2.2, où 1, signi e appartient au sous-pavage. Un arbre binaire T peut aussi être codé par une chaîne en notation polo-naise inversée4 p(T ), ob tenue comme suit : Si T est une feuille, cest-à-dire que T na
quun noeud qui est sa racine, alors p(T ) = T , sinon p(T ) = p(LT )jp(RT )jfcg; où j est lopérateur de concaténation et c est un code signi ant couper. Par exemple si T est larbre de la gure 2.4, p(T ) = f10c0110c10c0cccccg5: Cette séquence peut être codée en
binaire en remplaçant c par 1; 0 par 00 et 1 par 01. Les c de n de séquence ne sont bien sûr pas nécessaires pour retrouver larbre. T est alors représenté par la séquence binaire suivante p2(T ) = f010010001010010100100g: Remarquons que ce codage prend moins
de 3 octets. Ce type de codage par séquences binaires a été abondamment étudié dans la littérature. Des manipulations comme les intersections ou les unions de sous-pavages peuvent être faites beaucoup plus rapidement si on travaille directement sur les séquences binaires avec un codage adapté (voir par exemple [Pru90]).
2.6.4 Opérations sur les sous-pavages réguliers
Nous allons maintenant présenter quelques opérations de base sur les sous-pavages ré-guliers, à savoir la réuni cation, lunion et lintersection. Nous allons aussi donner un
4Cette notation est classique pour représenter une chaîne de calcul. Par exemple lexpression
paren-thésée (1 + 2) ¤ ((3 + 4) ¡ 5) peut être représentée par un arbre à 9 noeuds où les feuilles sont les chi¤res et les autres noeuds sont les opérateurs (¤ est la racine). Cette expression en notation polonaise inversée est 1 2 + 3 4 + 5 ¡ ¤. Remarquons que lordre dapparition des chi¤res est la même dans les deux expressions.
5Pour une meilleure compréhension, nous donnons lexpression parenthésée :
Figure 2.4: Représentation dun sous-pavage régulier par un arbre binaire.
algorithme capable de tester si un pavé est inclus dans un sous-pavage. Notons que ces opérations sont très rapides grâce à lutilisation darbres binaires. Pour les sous-pavages non réguliers, ces opérations ne peuvent plus être e¤ectuées aussi simplement.
Réuni cation de deux sous-pavages : Considérons un pavé [x] et deux sous-pavages réguliers bX 2 SPR(L[x]) et bY 2 SPR(R[x]). Le sous-pavage réuni é bZ , ( bX j bY) élément de SPR([x]) est dé ni et calculé comme suit :
Si bX = fL[x]g et bY = fR[x]g, bZ = [x] ; Si bX = ; et bY = ;, alors bZ = ;;
Sinon, L bZ = bX et R bZ = bY
(2.45) Notons que le nombre de pavés # bZ du sous-pavage bZ nest pas forcément égal à # bX +# bY. Si par exemple [x] = [0; 2]2; bX = f[0; 1] £ [0; 2]g et bY = f[1; 2] £ [0; 2]g; alors on a
b
X = fL[x]g et bY = fR[x]g. Et donc # bZ = 1 alors que # bX + # bY = 2: Si on travaille avec des arbres binaires, toutes ces opérations sont élémentaires. Par exemple linstruction L bZ = bX et R bZ = bY revient à raccrocher les deux arbres bX et bY à un noeud pour former larbre bZ. Notons en n que la réuni cation peut être vue comme lopération inverse des opérateurs L et R dans le sens où
b
Z = ( bX j bY) , bX = L bZ et bY = R bZ (2.46) Intersection : Lintersection bX \ bY de deux sous-pavages bX 2 SPR([x]) et bY 2 SPR([x]), est un sous-pavage de SPR([x]). Il est obtenu par lalgorithme récursif sui-vant :
Intersection³X ; bb Y; [x]´ (2.47) Si bX = f[x]g, renvoyer bY;
Si bY = f[x]g, renvoyer bX ;
Si bX = ; ou si bY = ;, renvoyer ;;
Renvoyer (³Intersection³L bX ; L bY; L[x]´jIntersection³R bX ; R bY; R[x]´´; (2.48)
Union : Si bX et bY sont deux sous-pavages de SPR( [x] ), lunion bX [ bY est un sous-pavage régulier de SPR( [x] ) qui peut être obtenu par lalgorithme récursif :
Union³X ; bb Y; [x]´ (2.49) Si bX = ; ou si bY = f[x]g, renvoyer bY,
Si bY = ; ou si bX = f[x]g, renvoyer bX ,
Renvoyer (Union³L bX ; L bY; L[x]´; Union³R bX ; R bY; R[x]´):
(2.50) Tester si un pavé est inclus dans un sous-pavage : Si [z] est un pavé contenu dans [x] et bX 2 SPR([x]), lalgorithme récursif qui suit permet de tester si [z] ½ bX ou si [z]\
b
X = ;: Si lalgorithme renvoie 1, alors, [z] ½ bX . Sil renvoie 0, alors, [z] \ bX = ;. Sinon, lalgorithme renvoie lintervalle [0; 1] qui signale6 que [z] est à cheval sur la frontière de
b X . Inside³[z]; bX ; [x]´ Si [z] = ; ou si bX = f[x]g, renvoyer 1; Si bX = ;; renvoyer 0; a = Inside³[z] \ L[x]; L bX ; L[x]´; Si a = [0; 1] ; renvoyer [0; 1] ; b = Inside³[z] \ R[x]; R bX ; R[x]´; Si a 6= b, renvoyer [0; 1] ; Si a = b, renvoyer a;
2.7 Algorithmes ensemblistes
Le calcul ensembliste est une notion un peu idéale car on ne sait pas vraiment calculer avec les ensembles. Dans nos applications, nous développerons des algorithmes ensemblistes qui utiliseront le calcul ensembliste et qui donc, eux aussi, seront idéaux. Voici un exemple dalgorithme ensembliste type.
AlgEns
Entrées A, B, sous-ensemb les de Rn
Initialisation C = f0g;
Début for i = 1 to 10, C = A + B+ [C] D =f(C)+f¡1(A)
Sortie D, sous-ensemb le de Rn
6Lexplication du codage du chevauchement par un intervalle [0; 1] résulte de la notion de booléen
où f0g est le singleton contenant le vecteur nul, [C] est le pavé enveloppe de lensemble C et f une fonction de Rn dans Rn. Il est clair que AlgEns nest pas implémentable en
létat. Toutefois, il peut être approximé par le même algorithme, où les sous-pavages se substituent aux ensembles (de même quun algorithme sur les réels est approximé par le même algorithme sur les ottants). Si le calcul sur les sous-pavages est implémenté, ce qui fera lobjet du prochain chapitre, une mise en oeuvre de AlgEns sera :
AlgExt
Entrées bA, bB, sous-pavages de Rn;
Initialisation bC = f0g ;
Début for i = 1 to 10, bC = bA + bB + [bC] ; bD =f(bC)+f¡1(bA) ;
Sortie bD, sous-pavage de Rn.
(2.51) Cet algorithme sera appelé algorithme extérieur car, à tout instant, les ensembles de AlgEns sont contenus dans les sous-pavages correspondant dans AlgExt. Chaque opé-ration sur les sous-pavages de AlgExt doit donc être telle que le sous-pavage résul-tant contienne le résultat ensembliste associé. Ainsi, f(bC); dans AlgExt, représente un sous-pavage qui contient lensemble ff (x) jx 2bCg qui lui même contient lensemble f(C) de AlgEns. De la même façon, bA + bB de AlgExt est un sous-pavage qui enferme fa + bja 2bA; b 2cBg qui enferme A + B de AlgEns.
Nous dirons que AlgExt est une mise en oeuvre de AlgEns. Lexpression mise en oeuvre peut paraître un peu forte puisquil sagit seulement dune approximation. Pourtant un algorithme sur les nombres réels est souvent mis en oeuvre par le même algorithme mais sur les ottants. Par mise en oeuvre dun algorithme, il faut donc comprendre que les variables de lalgorithme implémenté sont très proches de celles de lalgorithme idéal. Par exemple, si on utilise des ellipsoïdes pour représenter les ensembles de AlgEns, on ne peut pas réellement parler de mise en oeuvre car les ensembles manipulés par AlgEns ne sont pas des ellipsoïdes. Par contre, en représentant les ensembles par des sous-pavages, on peut vraiment parler dune mise en oeuvre de AlgEns car les sous-pavages de AlgExt sont arbitrairement proches des ensembles de AlgEns.
2.8 Conclusion
Dans ce chapitre, nous avons présenté lapproche ensembliste comme outil de résolution de problèmes non-linéaires et de représentation de lincertitude. Après quelques brefs rappels sur la théorie des ensembles, nous avons introduit la notion de sous-pavage. Ces sous-pavages nous permettront par la suite dapproximer et de manipuler les ensembles impliqués dans nos problèmes. Nous navons pas directement parlé de la mise en oeuvre
du calcul ensembliste, car elle requiert dune part, lintroduction du calcul par intervalles, qui sera faite au chapitre suivant, et dautre part, quelques algorithmes spéci ques, dont certains seront décrits au chapitre 4.
Analyse par intervalles
3.1 Introduction
Lanalyse par intervalles (voir [Moo79]) repose sur une idée très simple qui consiste à représenter les nombres réels ou entiers par des intervalles qui les contiennent. Cette idée a permis dapporter de la rigueur aux algorithmes numériques classiques. Mais elle a aussi permis le développement dalgorithmes spéci ques aux intervalles, pouvant concurren-cer sérieusement lapproche formelle, dans le sens où les résultats obtenus sont garantis. Lanalyse par intervalles permet par exemple de trouver toutes les solutions dun en-semble déquations non-linéaires, ou doptimiser de façon garantie un critère non convexe [Han92b], ou même de démontrer des propositions. Sur ces terrains, il est raisonnable da¢rmer que lanalyse par intervalles nadmet, à ce jour, aucun concurrent sérieux. Lanalyse par intervalles apparaît donc de façon inespérée au moment où on commençait à a¢rmer quil nexisterait jamais aucune méthode numérique capable de minimiser de façon garantie une fonction coût non convexe. Et pourtant elle reste con dentielle, prin-cipalement parce que limplémentation des algorithmes qui en découlent est di¢cile. On peut légitimement se demander où est le miracle ? Quest ce qui fait que soudainement on arrive à résoudre autant de problèmes réputés impossibles ? En bref, on peut dire que la vision ensembliste de lanalyse par intervalles permet une analyse par blocs dun espace de recherche alors que classiquement, nous ne pouvions le parcourir que par un nuage de points. Or comme cet espace est en général constitué dune in nité de points, il nous était impossible de balayer lespace tout entier en un temps ni. Une autre question naturelle est Quest-ce-qui permet à lanalyse par intervalles un travail par blocs que dautres types dapproches ensemblistes ne permettent pas ? . Nous allons maintenant tenter dapporter une réponse à cette question. Considérons un pavé [x] de Rn, une fonction f : Rn! R et
un ensemble S de Rn dé ni par un ensemble de contraintes (égalités, inégalités : : :) reliées
par des opérateurs logiques (et, ou, non : : :). Lanalyse par intervalles possède trois clefs qui permettent de réaliser les trois opérations suivantes
² encadrer limage de [x] par f, cest-à-dire trouver un intervalle qui contienne len-semble image ff(x)jx 2 [x]g: Cette clef est une conséquence directe du calcul par intervalles et utilise la notion de fonction dinclusion qui sera présentée en section 3.3.
² tester lappartenance de [x] à un ensemble S, cest-à-dire montrer que [x] ½ S ou que [x] \ S = ;. Pour cela, nous développerons le concept de test dinclusion en section 3.4.
² réduire [x] par rapport à S, cest-à-dire trouver un pavé [q] contenu dans [x] tel que [x] \ S = [q] \ S. La réduction est principalement fondée sur les trois approches suivantes : (i) la propagation de contraintes sur les intervalles présentée en section 3.6, (ii) la méthode de Newton par intervalles brièvement rappelée en section 3.7 et (iii) la linéarisation extérieure que nous introduirons en section 3.7. Les opérateurs NS qui permettent cette opération seront appelés opérateur de réduction (en anglais
narrowing operators). Ainsi, on notera [q] = NS([x]) si [q] ½ [x] et si [x]\S = [q]\S.
Comme nous le verrons, les deux dernières clefs sont des conséquences directes de la première. Ces trois clefs forment la base de tous les algorithmes auxquels nous allons nous intéresser. Toute autre théorie mathématique qui permettrait dimplémenter ces trois opérations pourrait se substituer à lanalyse par intervalles, mais il nen existe pas à ma connaissance. Lanalyse par intervalles permet la réalisation de ces trois opérations
² pour une classe énorme de fonctions f,
² pour une classe énorme de contraintes dé nissant S;
² de façon garantie par rapport aux erreurs darrondi de la machine.
Lanalyse par intervalles a été développée dans les années 70, (voir Moore [Moo79]) pour quanti er lerreur sur le résultat dun calcul numérique due à la précision nie du calcul ottant de lordinateur. De nos jours, elle est aussi très utilisée pour la résolution déqua-tions ou dinéquadéqua-tions non-linéaires ainsi que pour la minimisation dune fonction coût non convexe. Pour cela, elle est généralement appelée par des algorithmes de type branch-and-bound, qui découpent lespace (branch) tout en a¢nant les domaines de certaines variables (bound).
3.2 Calcul par intervalles
Etendre aux intervalles les opérations arithmétiques de base f+; ¡; :; =g est une idée natu-relle pour évaluer lensemble que décrit la somme, le produit, etc. de deux réels incertains inclus dans des intervalles. On dé nit ainsi pour ± 2 f+; ¡; :; =g,
[x] ± [y] = fx ± yjx 2 [x] et y 2 [y]g . (3.1) La caractérisation de [x] ± [y] se fait à laide du formulaire
8 > > > < > > > : [x] + [y] =£x + y; x + y¤; [x] ¡ [y] =£x ¡ y; x ¡ y¤;
[x] : [y] =£min¡x:y; x:y; x:y; x:y¢; max¡x:y; x:y; x:y; x:y¢¤; [x] = [y] = [x] ££1=y; 1=y¤, si 0 =2 [y] et indé ni sinon:
(3.2) Les propriétés algébriques des opérations sur les intervalles ont été largement étudiées. Parmi les plus souvent rappelées, citons la sous-distributivité de la multiplication par rapport à laddition
[a] : ([b] + [c]) µ [a] : [b] + [a] : [c] : (3.3) De même, les fonctions élémentaires comme exp, tan, sin, cos : : : peuvent être étendues aux intervalles. Si f : R ! R est une fonction élementaire, on dé nit son extension intervalle comme suit :
[f] : IR ! IR
[x] ! [f] ([x]) = [ff(x)jx 2 [x]g] : (3.4) où [A] désigne lintervalle enveloppe de lensemble A ½ Rn, cest-à-dire le plus petit
inter-valle qui contient A et, rappelons le, IR désigne lensemble de tous les interinter-valles. Ainsi, en prenant en compte la monotonie de lexponentielle, on a [exp] ([x]) = [exp (x) ; exp (x)] = exp ([x]). Dans le cas de lexponentielle, comme cest le cas pour toutes les fonctions élé-mentaires continues, lextension intervalle [f] ([x]) est égale à limage par f de [x], ce qui se traduit par [f] ([x]) = f ([x]). Pour les fonctions non monotones comme le sinus, il faut développer un algorithme spéci que. Pour bien assimiler le calcul par intervalles, je vous conseille daller jouer avec la calculatrice par intervalles sur le site
http: //www.mscs.mu.edu/~globsol/JavaIntervalCalc/I_C.html
3.3 Fonction dinclusion
Soit f une fonction de Rn dans Rm. Une fonction ensembliste [f] dé nie de IRndans IRm,
est une fonction dinclusion de f si
Notons que quelque soit la fonction f, nous savons trouver une fonction dinclusion. Par exemple la fonction [f] ([x] ) =Rn; pour tout [x] de IRn; est une fonction dinclusion pour
toute fonction f de Rndans Rm. Lanalyse par intervalles sévertue à proposer un ensemble
doutils permettant de trouver des fonctions dinclusion e¢caces (cest-à-dire précises et rapide à évaluer) pour tout type de fonctions f (polynomiales [MMTG92], possédant ex-pression analytique [Moo79], dé nie par un algorithme [JWLM99], solution dune équation di¤érentielle [Loh87], [Kuh98], : : :). Une fonction dinclusion [f] pour f est convergente; si pour toute suite [x] (k),
lim
k!1w([x] (k)) = 0 ) limk!1w([f]( [x] (k)) = 0: (3.6)
Rappelons que w([x] (k)) dénote la longueur de [x] (k). Cette propriété est demandée pour la convergence de la plupart des algorithmes utilisant lanalyse par intervalles.
Soient [fj] :IRn ! IR; m fonctions dinclusion associées aux fonctions coordonnées fj
dune fonction vectorielle f :Rn! Rm. Une fonction dinclusion pour f sera donnée par
[f]( [x]) = [f1]( [x]) £ : : : £ [fm]( [x]): (3.7)
Lélaboration de fonctions dinclusion e¢caces dune fonction vectorielle f se ramène donc à lélaboration de fonctions dinclusion e¢caces pour ses fonctions coordonnées. Foca-lisons nous donc sur le calcul de fonctions dinclusion de fonctions à valeurs dans R et plus particulièrement sur les fonctions termes, qui représentent une vaste classe de fonctions non-linéaires. Nous renvoyons à la littérature [MMTG92], [Moo66], [Loh87], [JWLM99] pour le traitement dautres classes de fonctions. Brièvement, une fonction terme (voir [Gra98] page 10 pour une dé nition précise) est une fonction qui peut être construite par compositions des fonctions élémentaires usuelles, sin, cos, exp, sqrt, sqr, abs, max, : : : et des opérateurs +; ¡; ¤; =. Un exemple de fonction terme est donnée par f(x1; x2; x3) =
p
x1+ exp(x2) ¤ log (x33+ sin (x1)). Il existe plusieurs méthodes pour ob
-tenir une fonction dinclusion dune fonction terme f. La méthode la plus simple consiste à remplacer les occurrences des variables scalaires (x; y; : : :) dans lexpression de f par les variables intervalles correspondantes ([x] ; [y] ; : : :) ; et toutes les fonctions élémentaires (exp, sin, : : :) par leur extension intervalle. Nous obtenons ainsi la fonction dinclusion naturelle de f. Cependant, bien souvent, cette fonction dinclusion nest pas minimale au sens de linclusion. Elle ne lest que lorsque chacune des variables nintervient quune seule fois dans lexpression de f. En outre, la longueur des intervalles obtenus dépend assez fortement de lexpression initiale de la fonction comme lillustre lexemple suivant tiré de la thèse de M. Kie¤er [Kie99].
Exemple 3.3.1 Comparons les performances des fonctions dinclusion établies à partir de quatre formulations dune même fonction terme :
f2(x) = x:x + x; (3.9) f3(x) = x2+ x; (3.10) f4(x) = (x + 12)2¡ 14: (3.11) Pour [x] = [¡1; 1], on obtient [f1] ([x]) = [x] ([x] + 1) = [¡2; 2] ; (3.12) [f2] ([x]) = [x] : [x] + [x] = [¡2; 2] ; (3.13) [f3] ([x]) = [x]2+ [x] = [¡1; 2] ; (3.14) [f4] ([x]) = ¡[x] + 12¢2¡ 14 =£¡14; 2¤: (3.15)
Selon lexpression de la fonction, lencadrement obtenu sera donc plus ou moins grossier (voir la gure 3.1). Les deux expressions [x] : [x] et [x]2 ne sont pas équivalentes, car dans le premier cas, chacune des occurrences de x peut varier indépendamment. Précisons que lensemble image de la fonction initiale est £¡1
4; 2
¤
. [f4] est donc minimale. }
Figure 3.1: Comparaison de fonctions dinclusion dune même fonction
Une fonction dinclusion qui fournit un intervalle image qui nest pas égal à lévaluation intervalle de la fonction réelle sur lintervalle considéré est dite pessimiste. Il nexiste pas de méthode systématique permettant, pour une fonction terme donnée, dobtenir une fonction dinclusion minimale. Cependant, on peut constater empiriquement que plus une variable apparaît fréquemment dans lexpression de f, plus le pessimisme a des chances de devenir important. Cela peut sinterpréter par le fait que deux occurrences dune même variable sont considérées comme variant indépendamment lune de lautre. Ainsi, les in-certitudes se combinent, pour donner un résultat plus mauvais que si lon avait considéré les occurrences comme variant de façon identique.
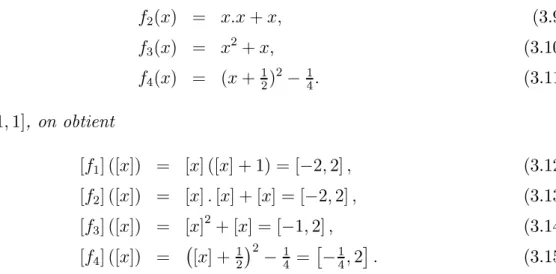
![Figure 3.2: Réduction dun pavé [x] en un pavé [q] relativement à une seule contrainte C 1](https://thumb-eu.123doks.com/thumbv2/123doknet/14464899.713312/43.892.267.580.127.409/figure-réduction-pavé-pavé-relativement-seule-contrainte.webp)