Asynchronous Network Coded Multicast
Texte intégral
Figure

Documents relatifs
In Section 2, we start by recalling briefly some notions on HJ equations, and we present the maximization problem following [12] as well as related duality results in
Actually, for stacks we show an even stronger result, namely that they cannot be encoded into weakly (asyn- chronous) bisimilar processes in a π-calculus without mixed choice..
Comparing to three existing primal–dual algorithms for solving the same problem: Condat–Vu ([12,34]), AFBA ([25]), and PDFP ([8]), this new algorithm combines the advantages of
klimeschiella were received at Riverside from the ARS-USDA Biological Control of Weeds Laboratory, Albany, Calif., on 14 April 1977.. These specimens were collected from a culture
This paper presents for the first time a relatively generic framework for multiple reflection filtering with (i ) a noise prior, (ii ) sparsity constraints on signal frame
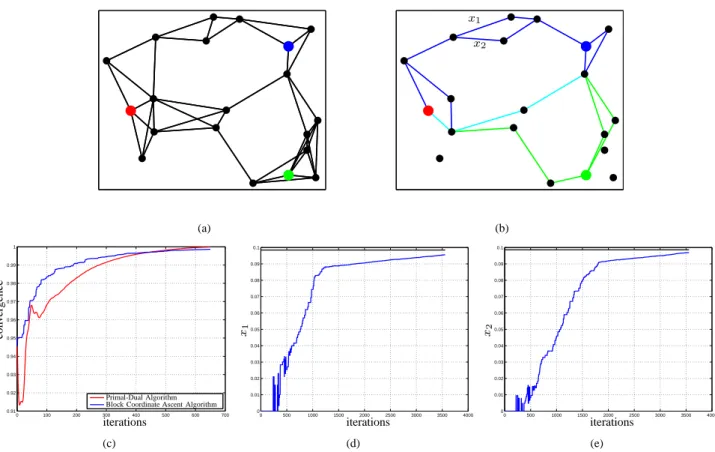
In order to incorporate asynchronous communications in the algorithm, the idea is to reformulate the second sum in (1) as an expectation over the (random) active edges and then to
« La sécurité alimentaire existe lorsque tous les êtres humains ont, à tout moment, un accès phy- sique et économique à une nourriture suffisante, saine et nutritive leur
The main contributions of this paper are the application to task scheduling in grids [6] of a parallel CGA [7], and a new local search operator suited to this problem is proposed..
