Comparaison of Several Estimation Procedures for Long Term Behavior
Texte intégral
Figure
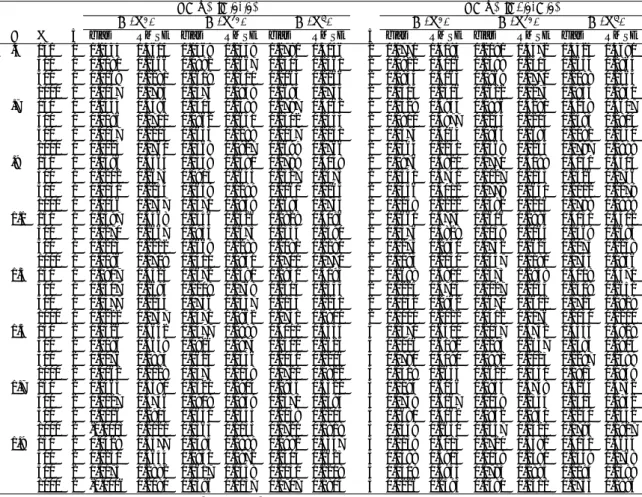
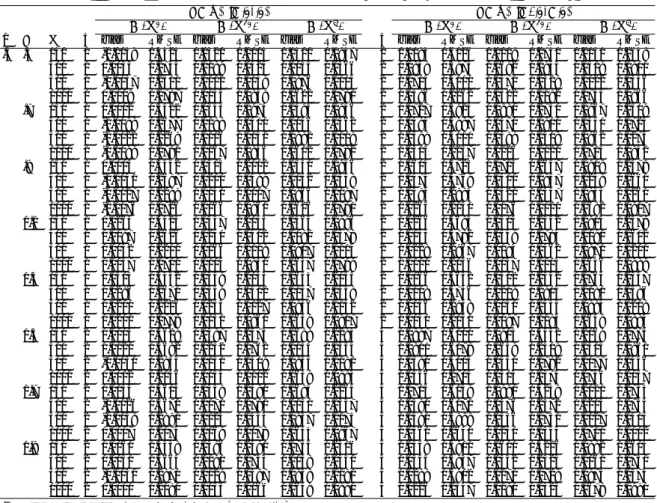
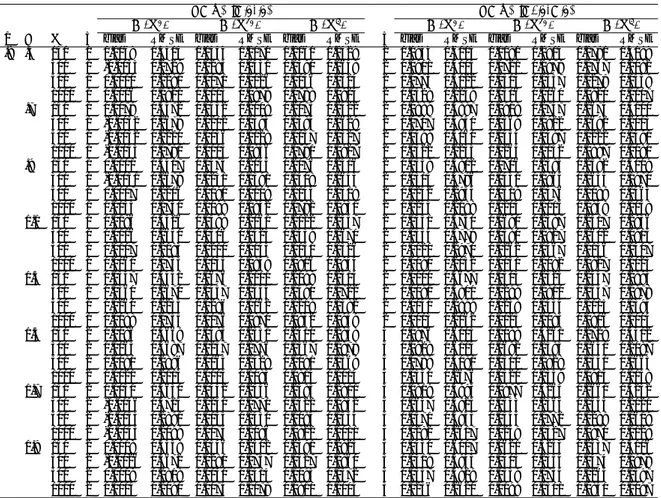
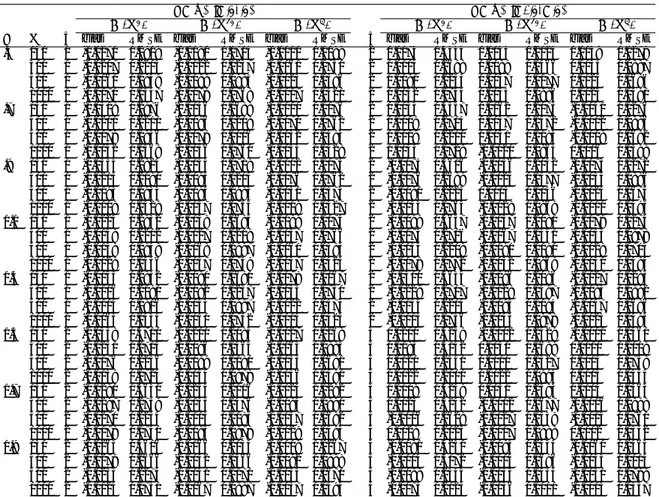
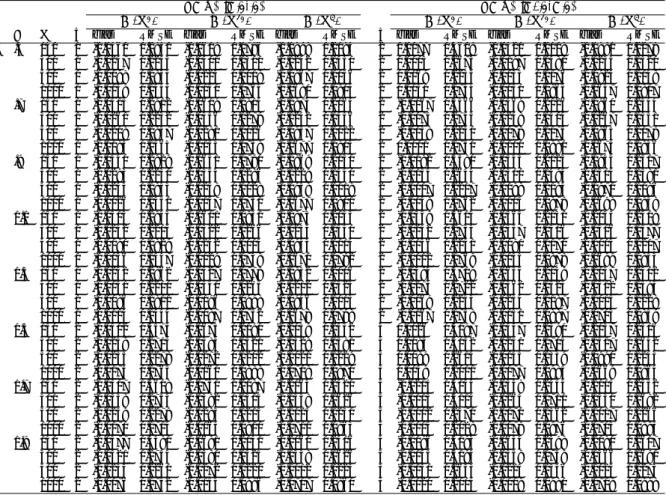


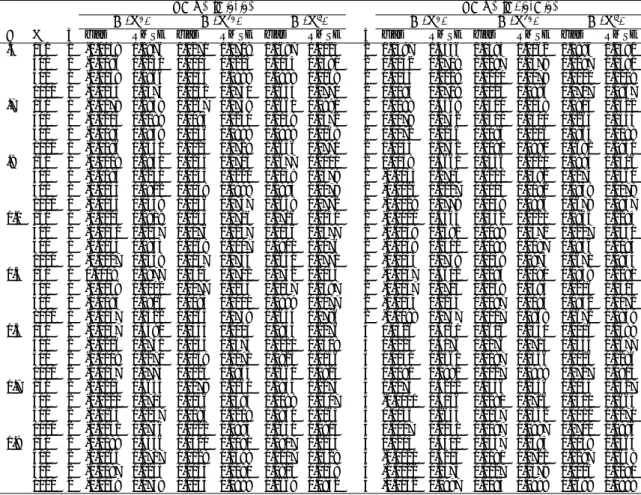
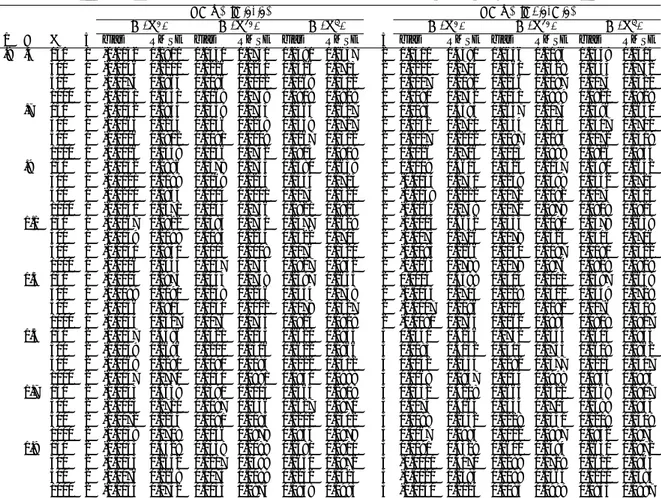
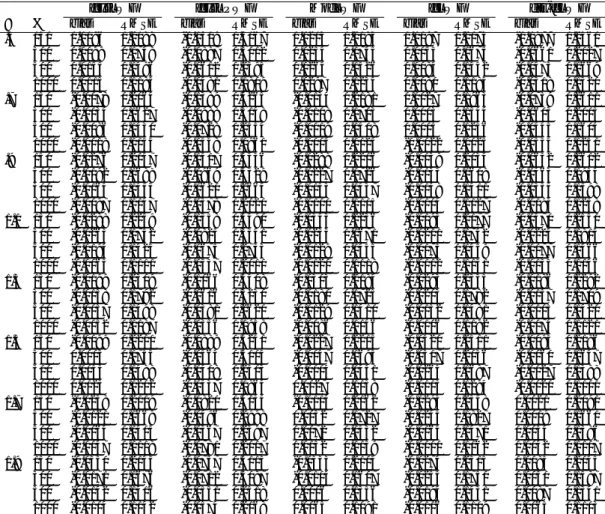
Documents relatifs
There has recently been a very important literature on methods to improve the rate of convergence and/or the bias of estimators of the long memory parameter, always under the
Estimation of limiting conditional distributions for the heavy tailed long memory stochastic volatility process.. Rafal Kulik,
- External estimation, in order to draw each latent variable towards strong correlation structures within the group, naturally uses single bivariate correlation between the
Keywords: Extreme value index, second order parameter, Hill estimator, semi-parametric estimation, asymptotic properties..
Parameter estimation for stochastic diffusion process with drift proportional to Weibull
We investigate the expected L 1 -error of the resulting estimates and derive optimal rates of convergence over classical nonparametric density classes provided the clustering method
This choice of k depends on the smoothness parameter β, and since it is not of the same order as the optimal values of k for the loss l(f, f ′ ) on the spectral densities, the
Hence, it seems natural to study our regression problem (1) in a semi-parametric framework: the shifts are the parameters of interest to be estimated, while the pattern stands for
