Color Sparse Representations for Image Processing: Review, Models, and Prospects
Texte intégral
Figure

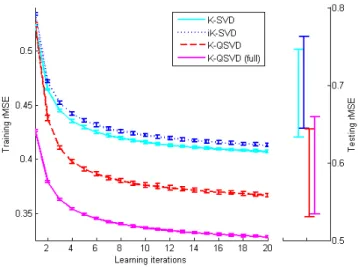

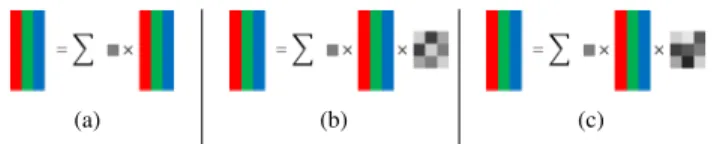
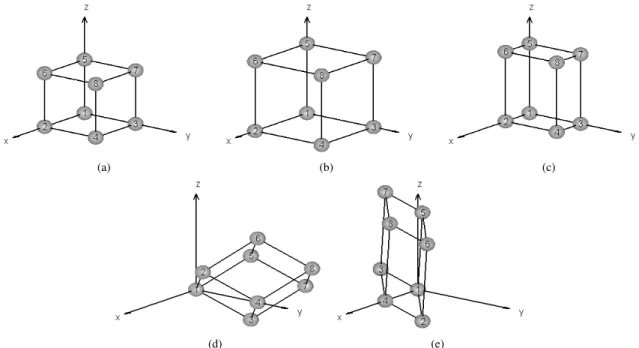
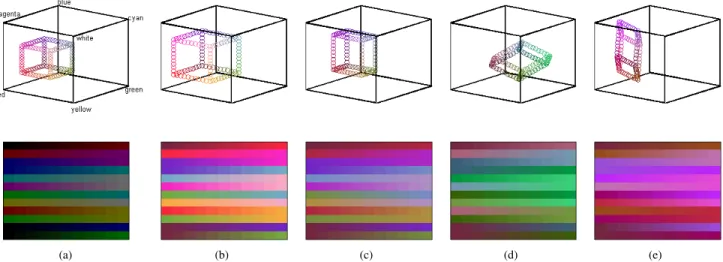

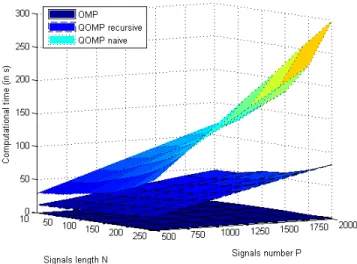
Documents relatifs
Based on a layer scanning algorithm, the color reordering generates gray level images and makes it possible to embed the color palette into the gray level images using a data
(Conserver les objets de la chasse aux trésors, écouter la vidéo, prendre et montrer l’objet de la même couleur dans
This paper presents a kinematical model of the knee joint that will be employed to specify the future Device kinematics and a preliminary control
So if you want to display another color space (or deconvoluted space or composite image) you have no other choice to put channel 1 in the R channel, channel2 in the G channel
Vaiter S, Deledalle C, Peyr´ e G, Fadili J, Dossal C (2012b) Local behavior of sparse analysis regularization: Applications to
In the special case of standard Lasso with a linearly independent design, (Zou et al., 2007) show that the number of nonzero coefficients is an unbiased esti- mate for the degrees
The documents may come from teaching and research institutions in France or abroad, or from public or private research centers.. L’archive ouverte pluridisciplinaire HAL, est
’variation ratio gain’, which is aimed to prove theoretically the significance of color effect on low-resolution faces within well- known subspace face recognition frameworks.
