Heterogeneous Resource Allocation under Degree Constraints
Texte intégral
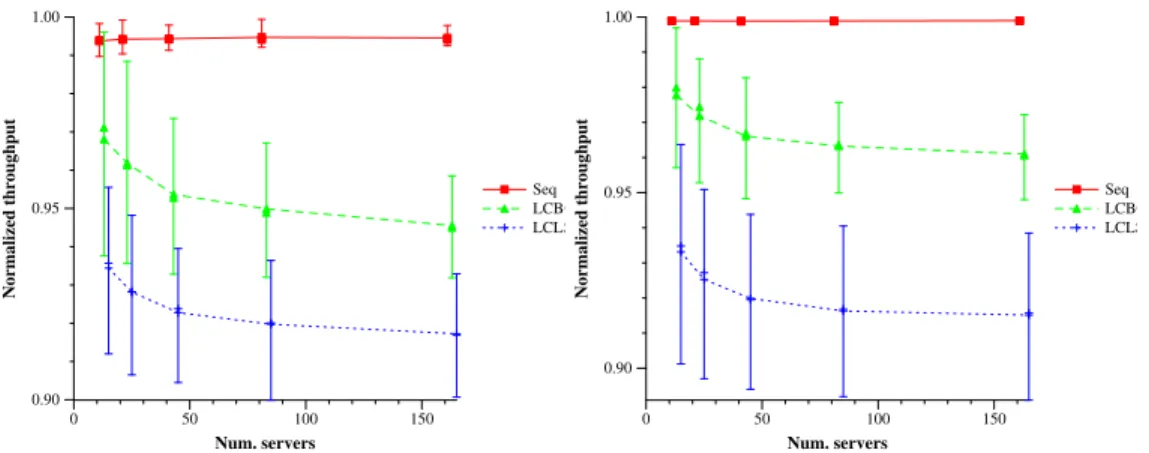
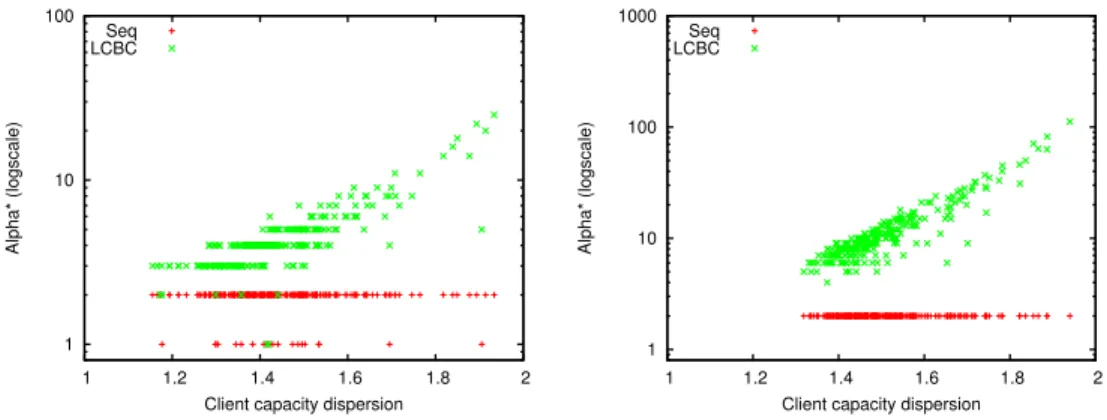
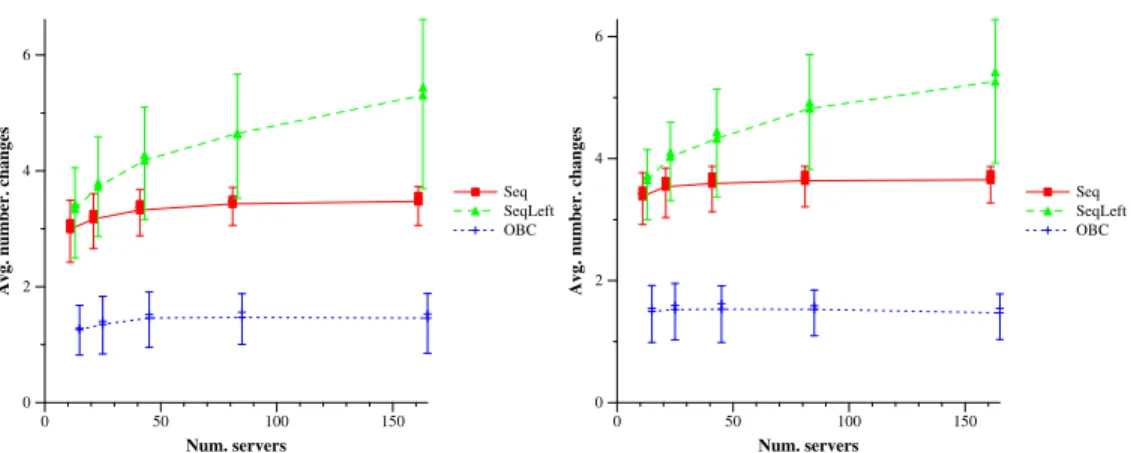
Figure
Documents relatifs
Decolonial economic projects like El Cambalache challenge coloniality on a day to day basis by reflecting on how we think about ourselves as women; our roles in creating
like to say good fences make good neighbours, but from outside this slanting wooden house that shrugs into itself, shouldering the icy harbour wind, it seems that maybe digging out
contemporary funeral rituals are shaped by the funeral industry on micro and macro levels. Consequently, future work would benefit from the perspective and insights of not..
(1995) that part of the reason why students report so many non-realistic responses to realistic items is due to the culture of the mathematics classroom. The use of
express a secretory phenotype largely dominated by proteases more so than inflammatory cytokines/chemokines, much like the granzyme (serine proteases) secretory profile of NK
The objectives of my research are: to explore the actual and potential education-related geographical movements of men and women of all ages participating in the (2014/2015)
Appendix B: Procedure for Torque Calibration of Lab Scale Drill Rig Motor Appendix C: Dynamic Analysis of a Deep Water Marine Riser Using Bond Graphs Appendix D: Cuttings Analysis
teacher community within days, if not minutes, of walking into the bricks and mortar of the DEECD. I feel it was a combination of what I was learning by being part of the
