Applying Machine Learning Techniques to the analysis of policy data of the Military Health Enterprise By Jaya Prasad Plmanabhan
M.S. Computer Science, IONA College, 2001
Submitted to the Department of Electrical Engineering and Computer Science in Partial Fulfillment of the Requirements for the Degree of
Master of Science in Electrical Engineering and Computer Science
at the
Massachusetts Institute of Technology
May 2015
o 153
Q 2015 Jaya Prasad Plmanabhan. All rights reserved.
The author hereby grants to MIT permission to reproduce and to distribute publicly paper and electronic copies of this thesis document in whole or in part in any medium now known
or hereafter created.
Author:
_Signature
redacted
Jaya Prasad Plmanabhan Electrical Engineering and Computer Science
Certified by:
Siauerdate_______
1'
Roy E. Welsch, Thesis SupervisorProfessor of Statistics and Management Science and Engineering Systems, MIT Sloan School of Management
Certified by:
Signature redacted
P,- S l C-u Thr) rrIAc
Accept
Accepi
eterI zooJIVILs, ess p~E
Professor of Computer Science and Electrical Engineering, head of the Clinical Decision-Making Group, CSAIL
ed
by:_Signature
redacted
-/ I
IProfessor Leslie A. Kolodziejski
Chair of the Committee on Gra te Students, Department of Electrical Engineering and Computer Science
by:
Signature redacted
Patrick Hale
MASSACHUSETTS INSTITUTE
OF TECHNOLOGY
JUN 2
3
2016
Applying Machine Learning Techniques to the analysis of policy data of the Military Health
Enterprise
By Jaya Prasad Plmanabhan
M.S. Computer Science, IONA College, 2001
Submitted to the Department of Electrical Engineering and Computer Science
in Partial Fulfillment of the Requirements for the Degree of
Master of Science in Electrical Engineering and Computer Science
Abstract:
It is common practice in organizational research to apply policy analysis to better
understand how an enterprise is approaching and addressing a particular topic of interest.
The approach to policy analysis commonly used is known as the Coding Approach. The
Coding Approach is a highly qualitative process that involves the manual identification of
relevant policy documents, the manual review of these documents to identify the key features of the topic, and the manual identification of the significance of these features as it relates to the policy documents. This process can generates rich insights into policies and how the topic of interest is being approached and viewed by the Stakeholder of the
enterprise. This process however is a manually intensive process and is subject to the bias of the expert/s reviewing and analyzing the documents.
My study proposes a new approach towards policy analysis that uses the Coding Approach
as its template, but applies Machine Learning Techniques, such as Natural Language
Processing and Data Mining Algorithms, together with a highly structured form of Case and Cross Case Analysis to identify documents that are related to the topic of interest, to
categorize these documents, to surface the key features of the topic, to calculate the significance of these features as reflected by the documents and to draw inferences about the key features and its significance as it relates to the policy documents. This new
approach provides a mixed methods approach that marries the best of both quantitative and qualitative techniques towards document analysis. This approach also reduces the amount bias that can be injected from the experts analyzing the documents, and thus guarantees an almost consistent result from document analysis regardless of the experts performing the analysis.
For my study I applied my mixed methods approach to analyzing the policy documents of the Military Health Enterprise MHS, to understand how well the MHS 's policies were addressing the delivery of psychological services to service members and their families. This study is important to the MHS for two reasons. With the reductions of the US Military presence in Afghanistan and Iraq there are large numbers of veterans returning who may have various forms of PTSD, who will requires varying types and levels of care. The other reason why this study is important to the MHS is due to the recent scandals (Walter Reed,
2007 & VA, 2014) it has faced specifically around to the health care services it was
supposed to provide to service members. Now its crucial for the MHS to understand the disconnect between its policies and what's actually being implemented. This study will provide the MHS with a non-bias review of what are the features of significance from a policy point of view in regards to the delivery of psychological services to service members and their families.
THIS PAGE INTENTIONALLY LEFT BLANK
;- , , -assw
mi-Acknowledgements
Its with immense gratitude I acknowledge the guidance and patience of my advisors
Professor Roy Welsch and Professor Peter Szolovits. It was an absolute honor and
privilege to have worked with both Roy and Peter.
I would like to extend my gratitude to each professor that contributed to my MIT
education while in the SM Program at EECS. The techniques, tools and approaches
applied in this thesis not only made this work possible but also will continue to be
part of my tool set as I take the next step in my engineering career.
I am extremely grateful to the staff at the graduate office of EECS, especially Miss
Janet Fischer and Miss Alicia Duarte for their kind help and patience.
I am also extremely grateful to the Director of the SDM program Pat Hale and the
staff at the SDM program, for their continued support and patience.
I owe my deepest thanks to my dear son Valentin and his mother Halyna for their
continued patience and support.
I must also thank my parents Padmanabhan and Leela for their constant support,
prayers and belief in me.
Finally I would like to express my deepest gratitude to my mentor and guide, Sangali
Karupan, without your constant guidance and presence none of this would have
been possible.
Table of Contents
Chapter 1: Introdu ction ...
... 4
1.1
Context ...
.
... ---...---
- -- - 4
1.2
M otivations...5
1.2.1 Em pirical M otivation... ... ---... .. 5
1.2.2 M ethodological M otivation...5
1.3
Identifying the K PIs ...
... ...
...
... 6
1.4 The data to be analyzed ...---..
--... -- 7
1.5 Sections of the M H S to be analyzed ...
8
1.6 Phases of conducting the analysis ...
8
1.7 Questions that the analysis helps us answers ...
10
1.8 Thesis Overview ...--
... ...---.- 11
Chapter 2: Foun dational T opics ...
12
2.1 Introduction ...-
...
... 12
2.2 M ilitary H ealth System ...
... 12
2.3 M ulti-level A nalysis ...
13
2.4 Enterprise A rchitecting...14
2.5 Q uantitative M ethods ...
. ..
-... 17
2.5.1 N atural Language Processing ... 17
2.5.2 Data M ining Techniques ... 19
2.6 Q ualitative M ethods ...
... -...
...
20
2.6.1 W ithin-Case Analysis...21
2.6.2 Cross-Case A nalysis ... 21
2.7 Com ing together ...
21
Chapter 3 R esearch M eth ods...
22
3. 1 Introduction ...----..
22
3.2 Collection and Preparation ...
22
3.2.1 Docum ent Search & Keyw ord Developm ent... 23
3.2.2 Classifying the relevant docum ents... 23
3.2.3 Developing the KPI (Eight Enterprise Views and Four MHS Goals) Characteristics...23
3.3 A nalysis... ... ---... 28
3.3.1 Cosine Sim ilarity ... 28
3.3.2 Rank or N orm alized Frequency... 29
3.3.3 Combined Relevancy & Normalized Frequency -The Rank and Relevancy Index...29
3.3.4 Range of Values... 29
3.3.5 The Rank and Relevancy M atrix... 30
3.4 Interpretation...
..
---....----. 31
3.4.4.1 W ithin Case Analysis...
31
3.4.4.2 Cross-Case Analysis... 33
Chapter 4 Data Collection Preparation & Analysis ...
36
4.1 Introduction... 36
4.2 Ranking & Relevancy Fram ew ork:... ... 36
4.3 Routine One: ... ---...-... 37
4.3.1 Introduction: ... ... 37
4.3.2 Key Step -Docum ent Search:... 37
4.3.3 Key Step - Loading:...---... ... ... ---... 38
4.3.4 Key Step -Tokenizing: ... ...---.-... 39
4.3.5 Key Step - Segm entation:... ... 39
4.3.6 Key Step - Norm alization:... 40
4.3.7 Key Step -Categorization:... 40
4.3.8 Key Step -Saving to the database:... 41
4.3.9 Routine One Conclusion:... .. ---... 42
4.4 Routine Tw o:...---...42
4.4.1 Key Step -Docum ent W ide Token Frequency Distribution: ... 43
4.4.2 Key Step -Corpus W ide Token Frequency Distribution:... 43
4.4.3 Key Step -Bigram Corpus Wide Token Frequency Distribution:...45
4.4.4 Key Step -Docum ent Search with enhanced Keywords:... 46
4.4.5 Routine Tw o Conclusion:... ... 48
4.5 Routine Three: ... 48
4.5.1 Key Step -Tag Docum ents with Unigram Key code:... 49
4.5.2 Key Step - Create Corpus Dataset: ... ... 49
4.5.3 Key Step -Training and building classifier:... 50
4.5.4 Routine Three Conclusion:...50
4.6 Routine Four:... ... 50
4.6.1 Key Step -Tag Documents with Key code using Custom NGRAM TAGGER: ... 51
4.6.2 Key Step -Category W ide NGRAM Frequency distribution: ... 51
4.6.3 Key Step -Iterating the Key code refinem ent process: ... 53
4.6.4 Routine Four Conclusion:... 54
4.7 Routine Five:... 54
4.7.1 Key Step -Create a Relevancy Calculator:... 54
4.7.2 Key Step -Create the Rank or Norm alized Frequency Calculator:... 57
4.7.3 Routine Five Conclusion:... 58
4.8 Conclusion:...59
Chapter 5 Classification M odels & Analysis ... 60
5.1 Introduction:...--.. ... ... --... 60
5.2 The Problem Statem ent:... ... ... 60
5.3 Gathering and understanding the data:... 61
5.4 Preparing and cleansing the data: ... 64
5.5 Dim ension Reduction Process:... .. 66
5.5.1 Dom ain Experts Review :... 70
5.5.2 Sum m ary Statistics:... ...--... 71
5.5.3 Principal Com ponent Analysis:...84
5.5.4 Variance Inflation Factor:...84
5.6 Classification M odel Perform ance M easures ... 85
5.6.1 Benchm ark Values:...85
5.6.2 Logistic Regression to test benchm ark values:... 85
5.6.2 Classification/Confusion M atrix:...85
5.6.2 Perform ance M easures: ... 86
5.6.3 Perform ance Evaluation M atrix:... 87
5.7 Analysis:...87
5.7.1 Phase 1 - Multi label classifiers using binary relevance method...88
5.7.2 Phase 2 - M ulti Label classifiers using adapted algorithm s:... 98
5.9 Final Classifier Selection:...102
5.10 Conclusion...103
5.10.1 Further Applications:... 104
5.10.2 Future W ork On Classifier ... 104
5.10.3 N ext Steps ... 104
Chapter 6 Analysis: ...
105
6.1 Introduction ... 105
6.2 Macro (Central Military Health Service) Level Analysis ... 107
6.2.1 The General Enterprise View Analysis ... 108
6.2.2 The Dom inant Enterprise View Analysis... 109
6.2.4 Sum m ary... 111
6.3 Meso (Service-Army, Navy, Air Force) Level Analysis ... 112
6.3.1 The General Enterprise View Analysis ... 113
6.3.2 The Dom inant Enterprise View Analysis... 114
6.3.4 Sum m ary... 120
6.4 Enterprise (M acro vs. M eso) Level A nalysis...122
6.4.1 The Dom inant Enterprise View Analysis... 122
6.5 Sum m ary ... 134
Chapter 7 Conclusions and Future Research ...
137
7.1 Introduction ... 137
7.2 Current State of Policies...137
7.3 Future State Discussions...138
7.3.1 Stakeholder Roles Future State... 138
7.3.2 M acro Processes Future State ... 139
7.3.3 M icro Processes Future State ... 139
7.4 Future applications of the Mixed Methods Analysis Framework ... 140
7.4.1 Future Applications of the Mixed Methods Research Framework... 141
7.5 Conclusion:...142
Appendix A : ... 144
Chapter 1: Introduction
1.1 Context
"During the 1940s, as new and more powerful computing machines were developed, the term computer came to refer to the machines rather than their human predecessors." [11] "As it became
clear that computers could be used for more than just mathematical calculations, the field of computer science broadened to study computation in general. Computer science began to be established as a distinct academic discipline in the 1950s and early 1960s." [621
"Machine learning is a subfield of computer science stemming from research into artificial intelligence. It has strong ties to statistics and mathematical optimization, which deliver methods, theory and application domains to the field. Machine learning is employed in a range of computing tasks where designing and programming explicit, rule-based algorithms is infeasible. Example applications include spain filtering, optical character recognition (OCR), search engines and computer vision." [631
At the same time that the field of Computer Science was starting to establish credibility and acceptance in the industry and academia, a unique methodology started emerging known as
engineering systems [11. Engineering science is based on the physical sciences including physics,
mathematics, chemistry, etc., and it aims to build a stronger quantitative base for engineering versus the empirical base of years past. This approach, while extremely valuable, tends to be very
micro in focus and concentrates on the mechanics of the underlying discipline [11. "Engineering
systems" takes a holistic view of the results of the application of technology; it views how the
system in its entirety behaves [11. So engineering systems may be viewed as bringing a qualitative
lens to the quantitative results of the engineering sciences.
Nightingale and Rhodes defines Enterprise Architecting as a subfield of Engineering Systems, and it is defined as a field that emphasizes the application of holistic thinking to "design, valuate, and select" the future state of an enterprise [2]. This field utilizes an enterprise viewpoint to
approach a system, where there is a specific emphasis on the relationships and interactions among the elements of the enterprise. The enterprise views include: strategy, infrastructure, organization, process, knowledge, information, products, services, stakeholders, and ecosystem[2]. Enterprise Architecting may be used as a tool to enable an enterprise to improve its state by first
understanding its current state in terms of the above mentioned elements.
The goal of this thesis is to evaluate how well the policies of the Military Health Enterprise
(MHS) are addressing the delivery of psychological services to service members and their families.
We aim to do this by bringing together techniques from the fields of computer science, machine learning and enterprise architecting. A secondary goal of this thesis is to develop a mixed methods approach towards analyzing secondary data. In the sections that follow we discuss these
1.2 Motivations
The motivations for working on this research topic can be categorized into two groups, empirical and methodological. The two sections below discuss these motivations in detail.
1.2.1 Empirical Motivation
The Department of Defense (DoD) is facing a significant challenge in ensuring the physical
and psychological well being of service members and their families. For example, the prevalence of
post-traumatic stress disorder (PTSD) as a result of Operation Iraqi Freedom (OIF) and Operation
Enduring Freedom (OEF) is estimated to be between 5% and 20% [7], two times higher than the
rates of PTSD after Operation Desert Storm [81. Almost 20 percent of military service members who
have returned from Iraq and Afghanistan - 300,000 in all - report symptoms of post-traumatic
stress disorder or major depression, however only a little more than half have sought treatment [91.
Experts note that the MHS has difficulties dealing with the current needs and will be unable
to meet the projected demand for psychological health services [111. According to Tanielian [91, there
is a major health crisis facing the service members from OIF and OEF and unless they receive appropriate and effective care for these mental health conditions, there will be long-term consequences for them and for the nation. Unfortunately, there are many systems-wide barriers
preventing them from getting the high-quality treatment they need [91. There are also challenges
with the increasing rise of military healthcare costs. Researchers estimate that PTSD and
depression among returning service members will cost the nation as much as $6.2 billion in the two
years following deployment - an amount that comprises both direct medical care and costs for lost
productivity and suicide. Investing in high quality treatment could save close to $2 billion within two years by substantially reducing these indirect costs [91.
There is urgency from a human and financial perspective to ensure that the delivery of psychological services to service members and their families is streamlined and optimized.
1.2.2 Methodological Motivation
Beyond the empirical motivations, there were several methodological motivations for this thesis. Recent research projects in Organizational Research that utilized the Enterprise Architecting
(EA) approach to analyze the MHS used a pure qualitative methodology toward data collection and
analysis[2] (for example Ipollito's "architecting the future tele-behavioral health system of care in the US Army" [191). This qualitative approach enables practitioners to develop rich descriptions of
the structure, behaviors, measures, artifacts, and periodicity of the enterprise [2]. However, this
approach is largely dependent on the availability of well-structured and curated datasets, and on the domain experts to prepare, analyze, and interpret the data. This purely qualitative approach has
two key problems:
1) Depending on structured and curated data creates a dependency for the organization or
the experts to put systems in place to start collecting data in a structured manner. Introducing structure and organization to the data collection process from the beginning may result in the loss of useful data, especially when we have not fully understood the data that's available and how it relates to the problem statement.
and unstructured data, so limiting our data collection to a single or restricted number of sources may limit our ability to truly dig deep into the problem.
2) Dependence on individual domain experts to manually prepare, analyze, and interpret the data introduces biases and dependency. It is common practice in organizational
research that involves document analysis for the domain expert to manually and qualitatively conceptualize the data in relation to the topic being studied, identify the key codes (features and characteristics) of the topic in relation to the data that's
available, tag all instances of these key codes, calculate the frequency of these key codes,
and then to interpret and draw inferences based of these frequencies [66]. These
methods introduce a dependency to that particular expert's skills and point of view. Using this approach we are not always guaranteed to generate the same results if the analysis were re-run with another expert.
There is indeed a need in the world of organizational research to build less dependency on structured and highly un-curated data. There is also a need to build less dependency on the experts' skill and point of view to manually prepare and analyze the data.
This research aims to show how alternative sources of data, such as secondary data, can be
an effective replacement of rich primary sourced data. [20] Secondary data that may be used
includes: documentation on policy, concept of operations, and military health guidance.
The research also aims to show how quantitative techniques such the parsing, tokenizing, tagging, frequency and relevancy analysis, which are capabilities present in Natural Language Processing Tools, can be an effective replacement for the manual process of building a code list, tagging the code list and calculating the frequency for the code list.
1.3 Identifying the KPIs
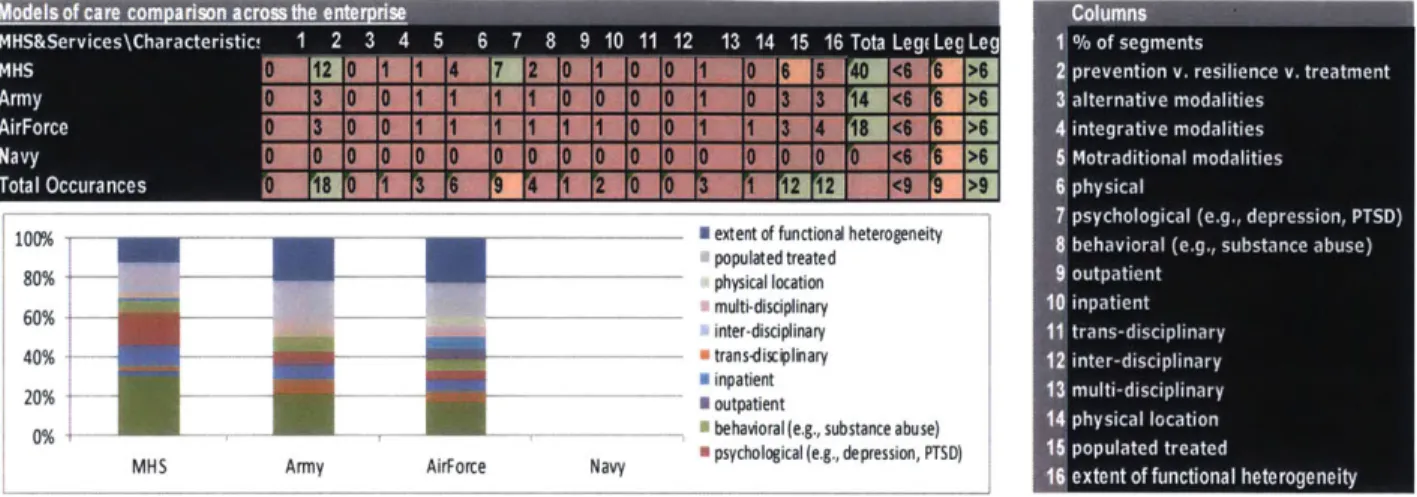
Having identified the primary goal of the thesis as "evaluating how well the policies of the MHS is addressing the delivery of psychological services to service members and their families", we had to next identify how we would evaluate the policies of the MHS. We needed Key Performance Indicators (KPIs) that would allow us to evaluate these policies. The MHS in 2012 defined four aims to strive for, to improve the care and services provided to the service members. These aims
included Population Health, Experience of Care, Per Capita Cost and Readiness (see Table 1.2)[15. These aims were closely aligned with the measures we were interested in collecting. So we decided to use these four aims (and their characteristics) as the KPIs to evaluate the Policies. As part of reviewing these four KPIs, we interviewed administrators at the MHS to understand the level of significance of the four KPIs to the MHS. We learnt that the MHS as a whole viewed the four aims as being equally important, however at the individual service levels the administrators may apply different levels of significance to the four aims. To avoid injecting any artificial weights on the KPIs we decided to weight each of the four KPIs as being equally important.
We also identified the need for KPIs that would evaluate the sections of the MHS that were
highly focused on the "delivery of psychological services to service members and their families".
In the study of Enterprise Architecting, the Enterprise can be broken up into specific views. According to the literature in Enterprise Architecting, there are eight main views in an enterprise (process, organization, knowledge, strategy, infrastructure, information, stakeholders, products)[2]. Within each view of an enterprise there are features (or characteristics) that determine the focus of
these views.[2] So we decided to use Enterprise Views (and its characteristics) as KPIs to indicate
sections of the MHS where the policies were focused on in terms of "delivery of psychological services to service members and their families".
Table 1.2: The Quadruple Aims of the Military Health System 11s
Number Description
1 Readiness: Ensuring that the total military force is medically ready to deploy and
that the medical force is ready to deliver healthcare anytime, anywhere in support of the full range of military operations, including humanitarian missions [3-19]
2 Population Health: Reducing the generators of ill health by encouraging healthy
behaviors and decreasing the likelihood of illness through focused prevention
and the development of increased resilience [3-19]
3 Experience of Care: Providing a care experience that is patient and family
centered, compassionate, convenient, equitable, safe, and always of the highest quality [3-19]
4 Per Capita Cost: Creating value by focusing on quality, eliminating waste and
reducing unwarranted variation; considering the total cost of care over time, not just the cost of an individual healthcare activity [3-191
1.4 The data to be analyzed
As discussed earlier this thesis is focused on analyzing how well the Policies of the MHS are addressing the delivery of psychological services to service members and their families. The decision to analyze the policy data was partially due to a desire to show the effectiveness and ease of using secondary data (as discussed in section 1.2.2). However it was mainly driven by the lack of easy access to primary sources of data. The primary sources of data we were looking for included medical claims data and direct survey data of service members (about the psychological services they have been receiving). Had these sources of data been available we would have been able to
focus our analysis on our original goal " Evaluating the performance of the MHS in delivering psychological services to service members and their families".
The policy data we will use is primarily policy documents from the MHS related to the delivery of psychological services to service member and their families. The reason why we choose this data was because from interviews with the administrators from the MHS we understood that the MHS
policies. Thus the descriptions of the policies could give us a relative real word view of the current state of the MHS in terms of delivery of psychological services to service members and their families.
Having chosen to analyze policy documents, we decided to use the coding approach towards
document analysis [661 (a widely used approach in organizational research) as the template for our
analysis. The coding approach involves the following steps:
1) Identify documents related to the topic of interest (In our case this would be the delivery of
psychological service members and their families).
2) Identifying the key codes (features and characteristics) of interest related to the topic interest (In our case this would be the KPIs)
3) Tag the presence of the codes in the documents.
4) Calculate the frequencies of these codes as they appear in the documents (since frequencies were used as indication of alignment between code and document).
5) Draw inferences and interpretations of these from the identified frequencies.
To add further rigor to our inferences and interpretations we will also be calculating the relevance of each KPI to the policy documents. In chapter three we discuss this in detail.
1.5 Sections of the MHS to be analyzed
Having identified the KPIs to be collected, the data to be analyzed, the template to be used for analysis. We can now investigate the sections of the MHS that we will be analyzing. It's important to note that the MHS is a multi level or hierarchical organization; it can be split up into three levels:
1) The Macro level, which is the topmost level where the main administrative entity resides.
2) The Meso level, which consist of the governing body of the uniformed services (Army, Air Force, and Navy)
3) The Micro level, which consists of the treatment facilities at the installations (camps).
Our plan is to analyze each level of the MHS using the methodology described in the sections 1.4 and 1.6 and then to compare the results of the analysis of each level to identify the dominant
enterprise views, the dominant characteristic within those views and the degree these views and characteristics addresses the four MHS goals; from the perspective of the policies that addresses the delivery of psychological services to service members and their families.
1.6 Phases of conducting the analysis
Having identified the KPIs to be collected, the data to be analyzed, the template to be used for analysis, we can now examine how the analysis will actually be conducted. As we mentioned in
section 1.4 we will be using the coding approach towards document analysis 1661 as our template.
Phase 1: Identify and build the collection of policy data - documents that are closely related to the research topic (the delivery of psychological services to service members and their families). This is done in three steps:
1) Identify and validate the repositories, database, and archives where most documents
related to the topic could be found.
2) Develop an initial set of search terms with the help of the domain experts.
3) Run a "wide" search on the document repositories with these search terms.
4) Manually review the documents to identify the documents that are most relevant to the research topic.
5) Develop a set of refined search terms, with the help of domain experts, by performing an
analysis on the terms that appears in the identified documents; using the tokenizing,
tagging, bigram identification, frequency count, and likelihood estimate features available in most NLP tools.
6) Search the repositories again using this newly identified set of search terms.
7) Repeat steps 3 to 6 until a sufficient set of documents has been identified. Then manually
review and filter down the list of final documents to those that are most relevant to the research topic.
Phase 2: Assign the documents to all classes (these classes are the KPIs). Identify what are the characteristics of these KPIs based on the documents that belong to the KPIs. The following steps do this:
1) Manually review each of the documents and assign them to the classes (the four MHS goals
and eight Enterprise Views).
2) Identify the key codes (characteristic) for the KPIs (the four MHS Goals and the eight Enterprise Views), with the help of domain experts, by analyzing the terms that appears in the documents associated with those KPIs. This is done by using the tokenizing, Ngram tagging, frequency count, and likelihood estimate features available in most NLP tools.
Phase 3: Using data mining techniques to build a multi label classifier that will be able to categorize new or incoming documents into the eight possible enterprise views. The steps involved in this process are:
1) Use dimension reduction techniques such as:
a. VIF or Variance Inflation Factor to identify target variables that have a high correlation with all other predictors.
b. Pairwise collinearity analysis, to remove redundant variables, and logistic
regression to measure the sensitivity and false negative rates.
c. Using Principal Component Analysis to coalesce the remaining independent
variables to cover the desired variance and achieve the desired sensitivity and false negative rates.
2) Build the multi label classifier using:
a. Binary Relevance Method to build up a group of independent classifiers.
9
b. Adapted Algorithm Methods that is able to classify multiple dependent variables
simultaneously.
Phase 4: Calculate the Rank and Relevancy of each KPI characteristic in relation to the documents that are associated with it. Generate a matrix for each KPI that displays the rank and relevancy for each of its characteristics. This can be done in the following steps:
1) Calculate the relevancy of each KPI's Characteristic to the related documents using a
cosine similarity matrix.
2) Calculate the rank or normalized frequency of each KPI's Characteristic within the documents.
3) Add up the relevancy and rank of individual Characteristic to calculate the Rank and
Relevancy Index of the KPI as a whole.
Phase 5: After the quantitative data preparation and analysis, the results can be interpreted and inferred by using the following techniques:
1) A within-case analysis, which analyses the data at each level of the MHS to identify:
a. The dominant Enterprise Views at a given level (in terms of the total Rank and Relevancy Index as identified in the policies).
b. The dominant characteristics at each view at a given level (in terms of the total
Rank and Relevancy Index as identified in the policies).
c. How well the four goals of the MHS are being addressed by the dominant views
and dominant characteristics at a given level (in terms of the total Rank and Relevancy Index as identified in the policies).
2) A cross-case analysis, which analyses the data between level of the MHS to identify:
a. The dominant views between levels.
b. The dominant characteristics between levels.
c. How well the four MRS goals are being addressed by the dominant views and
characteristics between levels.
1.7 Questions that the analysis helps us answers
As a result of the five-phase analysis we are now able to answer the following questions:
1) What are the most dominant Enterprise Views across the MHS as identified in the policies
[addressing the delivery of psychological services to service members and their families]? (e.g., Stakeholder and Process)
2) What are the most dominant Enterprise View characteristics across the MHS as identified in the policies? (For example, Primary Care Provider, and Easy Access to Mental Health
Services.)
3) How well are the Enterprise Views and characteristics addressing the four goals of the MHS
as identified in the policies?
4) What areas should the Enterprise views and characteristics (as identified in the policies) focus on to allow its future state to better address the four goals of the Military Health System?
5) If an actual data collection campaign is to be started, than what are the data points we want
to focus on to avoid data glut?
1.8 Thesis Overview
To conclude this chapter, a summary of the remaining chapters of this thesis is discussed below:
1) Chapter 2 -Foundation Topics: This chapter provides an account of previously published
material by experts and researchers particularly in the areas of: a) Military Health Systems.
b) Multi-level Analysis.
c) Enterprise Architecting. d) NLP.
e) Data Mining Techniques.
The subject matter listed above forms the foundation of which the thesis is built off.
2) Chapter 3 - Research Methods and Approaches: This chapter describes the approaches that
were taken to locate, prepare, analyze and interpret the documents associated with the delivery of psychological services to services members and their families by the MHS.
3) Chapter 4 - NLP Framework: This chapter discusses the details of the preparation and
analysis that was done on the data using Python's NLTK. In this chapter we discuss about: a) How parsing, tokenizing, filtering, and tagging of the body of text in the document
collection, can be done with Python's NLTK.
b) How to calculate the normalized frequency and likelihood estimates of key codes,
Non Key codes, Bigrams and Ngrams with Python's NLTK. c) How to develop a custom Ngrams tagger, with Python's NLTK.
d) How to calculate Rank using normalized frequencies, with Python's NLTK.
e) How to calculate Relevancy using cosine similarity, with Python's NLTK.
4) Chapter 5 - Multi Label Classifier: This chapter discusses the steps that were taken to build
the multi label classifier. This classifier will be built using the policy documents, the frequency count of the Key Characteristics (of the KPIs) within these documents, and the classes (KPIs) that these documents belong to.
5) Chapter 6 - Analysis: This chapter provides the analysis of the various levels (macro and
meso) of the enterprise by utilizing both within-case and cross-case analysis.
6) Chapter 7 - Summary and Future Steps: This chapter discusses the future steps that may be
taken to improve the state of the enterprise. It also discusses the future applications of the mixed methods approach that was employed.
Chapter 2: Foundational Topics
2.1 Introduction
The primary goal of this research is to analyze how well the policies of the MHS is addressing the delivery of psychological services to service members and their families. We plan to do this by bring together techniques from the fields of computer science, machine learning and enterprise architecting, to create a mixed methods approach that analyzes secondary data. To successfully implement this approach, a broad body of knowledge from various fields had to be investigated including:
1) The military health system
2) Multi-level analysis
3) Enterprise architecting
4) Quantitative methods - including:
a) Natural Language Processing (NLP)
b) Data Mining Techniques
5) Qualitative methods - including:
a) Case and Cross Case Analysis
In the sections that follow we discuss in detail about the MHS (and its components), Multi-level analysis, and Enterprise Architecting, Natural Language Processing, and Data Mining
Techniques. These are the foundational topics on which the research is based, and a good understanding is necessary to completely understand the project.
2.2
Military Health SystemThe Military Health System is the enterprise within the United States Department of Defense that provides healthcare to active duty and retired U.S. Military personnel and their
dependents [13]. Its mission is to provide health support for the full range of military operations and
sustain the health of all who are entrusted to the Military Health System [14].
121
SIEC SIEC SIEC 14-Vy ^,'.
Figure 2.1 Current Structure of Military Health System Governance [14]
The Military Health System is a multi-level enterprise with multiple sublevels within each level; the organization and governance structure is depicted in Figure 2.1. This research will focus on the governing body of the Military Health System and the uniformed services including: Army, Navy,
and Air Force. Figure 2.2 below shows the Military Health System broken into its levels; as shown the macro level consists of the governing body of the Military Health System, the meso level
consists of the governing body of the uniformed services (Army, Air Force, and Navy), and finally the micro level consists of the medical treatment facilities at the installations (camps) itself.
Being a multi-leveled and layered organization, there are complex relationships within and between the levels that determine how the enterprise functions; understanding these relationships will be essential in accurately determining how well the policies of the MHS is addressing the delivery of psychological services to service members and their families.
l
i,',,,q MoctoMH
Levt'I '
Iu
vct III~
Figure 2.2 Military Health System's Multiple Levels [12]
As discussed above, the MHS is a multi-level organization. Part of analyzing the policies of the MHS is to understand the relationships and interactions between and within the various levels
of the MHS. This is best achieved with a good understanding of what really constitutes a multi-level organization and how multi-level analysis is conducted.
A multi-level organization is an organizational structure where every entity in the
organization, except the one at the top, is a subordinate to at least a single other entity [321.
Enterprises may be organized into hierarchies, or levels, which correspond to different capabilities
[331. Capabilities of the "lower" levels of organization are in a sense inherited from the levels above,
providing both a means of modularizing individual capabilities and the ability to reuse methods in different branches of the hierarchy [33].
Rousseau in her 1985 paper, on "Issues of Level in Organization Research", advocates for a multi-level approach when studying organizations, based on the increasing bureaucratization and
advancement in technology [34]. Rousseau recommends building models to describe the relations
and state at each level of an enterprise. These findings can then be contrasted with the other levels
[341.
There has been considerable progress in multi-level analysis; one of the reasons for this progress, according to Rousseau, is the development and acceptance of models and statistical
procedures to conduct multi-level research [351. Rousseau's insights have been the subject of further
research by many other scholars (it is also one of the motivations for the use of quantitative techniques in this research).
Nicol[38
] in his 2010 PhD thesis presented a Multi-Domain Process Matrix (MDPM) to provide a
mechanism that synthesizes the physical, organizational, and information flow control for
processes performed at many levels of an enterprise [381. The idea of using a matrix to generate the
physical, informational, and organizational flow of the process at each level acted as the motivation for developing a matrix to collect measurements (and calculations) of the characteristics of the KPIs at various levels and to compare and contrast them to better understand the relationships within and between the levels.
Nicol's MDPM reflects how a matrix with measurements of the KPIs can surface interactions between levels of an enterprise that may otherwise be hidden[12].
2.4 Enterprise Architecting
There are various definitions for enterprise architecting: Nightingale and Rhodes[2] describe enterprise architecture generally as the structure and behavior of an enterprise within a complex socio-technical environment, and define enterprise architecting as "applying holistic thinking to design, evaluate, and select a preferred structure for a future state enterprise to realize its value proposition and desired behaviors[2]."
Enterprises have been studied by management, social, and information scientists; however, it has been mainly through a single view of the enterprise, like studying the organizational structure
or the information technology architecture [16]. The inadequacy of single or even pairwise analysis
of enterprises is well recognized [181. Nightingale and Rhodes propose that a greater perspective of
an enterprise can be gained by using ten "elements" to assess the enterprise. By realizing how the components of an enterprise contribute to these elements, the complexity of the enterprise as a
whole can be reduced [2]. The ten elements and a high level representation of their interactions are
illustrated in Figure 2.3 and are defined in Table 2.1.
Table 2.1: Enterprise Architecture Elements Descriptions [21
The exogenous element is the ecosystem. This is the part of the world that is relevant to the enterprise, and is characterized by the external regulatory,
Ecosystem political, economic, market, and societal environment in which the enterprise
operates and competes/cooperates with other related enterprises.
Enterprise stakeholders are individuals and groups who contribute to, benefit
Stakeholders from, and/or are affected by the enterprise. Stakeholders may be either
exogenous or endogenous to our enterprise, depending on the perspective we take.
Strategy The vision, strategic goals, business model, and enterprise level metrics.
Process Core, leadership, lifecycle, and enabling processes by which the enterprise
creates value for its stakeholders.
Figure 2.3 Enterprise Architecting Views and Elements (2]
According to Rhodes and Nightingale, the 10 elements of the enterprise consist of the eight enterprise.
The competencies, explicit and tacit knowledge, and intellectual property resident in the enterprise.
Information The available information required by the enterprise to perform its mission and
operate effectively.
Systems and information technology, communications technology, and physical facilities that enable the enterprise's performance.
The products that the enterprise acquires, markets, develops, manufactures, and/or distributes to stakeholders.
The offerings derived from the enterprise's knowledge, skills, and competences that deliver value to stakeholders, including support of products.
the part of the external world that is relevant to the enterprise[2]". Stakeholders are described as "individuals and groups who contribute to, benefit from the enterprise [2]".
Rhodes, Ross, and Nightingale express that a descriptive architectural construct is needed to effectively represent the current state and to plan the future states of complex enterprises, or
systems of systems [391. They present a framework that was developed through descriptive studies
of real-world enterprises. An example of the possible state of relations in an enterprise is shown in Figure 2.4. This example provides a generic representation of how the enterprise elements
interconnect and influence each other. The solid lines show the primary relationships and
influences between elements, and the dotted lines are secondary ones. The elements in the shaded box represent the dominant elements of the enterprise. A dominant element could be one that has the most focus (investment of time, money, energy and etc.) by the stakeholders of the enterprise, or it could be the one that is most crucial in delivering the desired goals (increasing revenue, delivering better services, producing quality products and etc.) of the enterprise. In this example the enterprise elements stakeholder and ecosystem is absent, indicating that further investigations of the exact relationships and flows in an enterprise is needed.
-~fJ~J U * Umuuuuamuugmuul a U IlIt:~ - ~tI U
Figure 2.4 Enterprise Architectine Framework [21
Enterprise Architecting is an effective method for analyzing complex socio-technical
systems because the elements of enterprises do not permit traditional investigative methods [29].
The eight view elements can be utilized to identify the current state of an enterprise, which in return can support the development of enhanced future states. Enterprise Architecting is used in this research to evaluate the views of the MHS that the policies are focused on.
I
As mentioned in section 1.8 the data preparation and analysis sections will utilize Python's Natural Language Tool Kit (NLTK) [681, and various types of classifiers. The subsections that follow
will provide an introduction to the topics of Natural Language Processing and Data Mining. In chapter three we discuss at high level how the features of NLTK and the classifiers are applied.
i
Natural Language Processing"Natural language processing is the technology for dealing with our most ubiquitous product: human language, as it appears in e-mails, web pages, tweets, product descriptions, newspaper stories, social media, and scientific articles, in thousands of languages and varieties. In the past decade, successful natural language processing applications have become part of our everyday experience, from spelling and grammar correction in word processors to machine translation on the web, from e-mail spam detection to automatic question answering, from detecting people's opinions about products or services to extracting appointments from your
e-mail. [69]"
The tool and resources available for NLP can be divided into two categories:
1) 2)
General frameworks
Components, pipelines, and tools
Below is a list of some of the NLP tools and resources that are available. A more detailed list can be viewed in the Wikipedia article "Outline of Natural Language Processing"[70].
NLP Toolkits: [70] Name Apertium Language C++, Java GPL LISP, C++ LGPL, MIT, C++ Commercial C++ Affero GPL
Deep Linguistic Processing with HPSG Initiative Ultralingua Inc. TALP Research
License
Creators
(various) DELPH-IN Distinguo FreeLing,lr
Name Language
t
General Architecture for Text Engineering(GATE) Gensim LinguaStream Java Python Java
License
-r LGPL LG PL Free for researchCreators
University of Catalonia)GATE open source
community
Radim Rehu'rek
University of Caen, France
Common Public License
University of Massachusetts Amherst
Modular Audio
Recognition Framework Java BSD
The MARF Research and
Development
Group, Concordia University
MontyLingua Natural Language Toolkit (NLTK) Python, Java Apache OpienNLP UIMA Java Apache License 2.0 Java / C++ Apache 2.0 Online community Apache 18
/I
Mallet F Javat
-1 Free for research 1~ MIT Python Apache 2.0 4. 1For the purposes of our research we needed the ability to tokenize, parse, filter, tag,
collocate, permute, calculate frequencies, likelihood estimates, cosine similarities, generate bigrams and Ngrams for large bodies of text.
The Natural Language Toolkit managed and maintained by the NLTK Project, provides a rich library of tools built in Python, and provides the functionalities mentioned above. In addition
Python allows easy interfacing with our chosen data repository (MongoDB).
"NLTK is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning" [681.
For the reasons mentioned above we decided to use Python's NLTK as the toolkit to parse, tokenize, tag and calculate the desired frequencies and relevancy.
2.5.2 Data Mining Techniques
Data Mining resides at the convergence of the union of the fields of statistics and machine learning (AI). There are a variety of techniques for investigating data and building models in the world of statistics: linear regression, logistic regression, discriminant analysis, and principal
component analysis for example. The core tenant of classical statistics, that data is scarce and computing is expensive, does not apply to data mining. Unlike classical statistics, in data mining due
to the high availability of data, the model is fitted with one sample and evaluated with another. [47]
"Computer science has brought us "machine learning" techniques, such as trees and neural networks, that rely on computational intensity and are less structured than classical statistical models. In addition, the growing field of database management is also part of the picture. The emphasis that classical statistics places on inference (determining whether a pattern or interesting result might have happened by chance) is missing in data mining. In comparison to statistics, data mining deals with large datasets in open-ended fashion, making it impossible to put the strict limits around the question being addressed that inference would require."[471
"As a result, the general approach to data mining is vulnerable to the danger of "over fitting," where a model is fit so closely to the available sample of data that it describes not merely structural characteristics of the data, but random peculiarities as well. In engineering terms, the model is fitting the noise, not just the signal."[4 7]
In data mining there are two types of algorithm that may be used to develop models. The algorithms are either classification algorithms or prediction algorithms. The models developed are either:
e Classification models:
* Prediction models:
o Predicts continuous valued functions.
o An example of a prediction model is one that can predict the likely tax refund for an
individual based on his/her income, occupation and history of tax refunds.
Below we highlight some of the commonly used algorithms for building predictors and classifiers. Our goal was to build models that would classify incoming documents into any of the eight enterprise views; so we focused on the classifier algorithms. Chapter five discusses about the algorithms we used and approach we took to identify the ideal set of algorithms.
- Classification Algorithms:
o Naive Bayes
o K-Nearest Neighbors
o Classification and Regression Trees
o Logistic Regression
o Neural Nets
o Discriminant Analysis
o Support Vector Machines
- Predictive Algorithms:
o Multiple Linear Regressions
o Moving Average
o Weighted Moving Average
o Autoregressive Moving Average
o Autoregressive Integrated Moving Average
o Exponential Smoothing
o Trend Estimation
2.6 Qualitative Methods
In section 1.6 we discussed about within-case and cross-case analysis. We will be using both approaches to identify:
1) The dominant enterprise views.
3) The degree of coverage of the four MHS goals by the dominant views and characteristics.
The within-case approach will be used to analyze the enterprise views at the levels of an enterprise. The cross-case approach will be used to analyze the enterprise views between levels. Below is a summary of within-case and cross-case analysis:
2.6.1 Within-Case Analysis
A within-case analysis is essentially an empirical inquiry that investigates a contemporary
phenomenon within a real-life context, especially when the boundaries between phenomenon and context are not clearly evident. [It] copes with the technically distinctive situation in which there will be many more characteristics of interest than data points, and as one result relies on multiple sources of evidence, with data needing to converge in a triangulating fashion. Another result benefits from the prior development of theoretical propositions to guide data collection and
analysis [31]
2.6.2 Cross-Case Analysis
Cross-case analysis analyses data across all of the cases in order to identify similarities and differences; the desired goal is to identify the causal links in real-life situations that are too complex
for a single survey or experiment [31]. Undertaking multiple case studies can generate explanations,
which can be tested systematically. Also the use of multi-case sampling adds to the validity and generalizability of these findings through replication logic.
2.7 Coming together
By integrating multi-level analysis (building models at each level and contrasting models
between and within levels) with the enterprise views of Enterprise Architecting, and the tools from Machine Learning, and Computer Science (NLTK and the various classifier algorithms), the levels that make up an enterprise may be studied in a detailed and quantifiable manner; and the current state of the levels and the inter and intra-level relationships may be determined. Multi-level analysis combined with the techniques mentioned above provides a Mixed Methods Approach (an approach that marries quantitative techniques with qualitative techniques) for collecting,
preparing, analyzing and interpreting the policy data related to the research topic.
The chapters that follows will examine the details and validity of the components of the Mixed Methods Approach and how when brought together provides us with an accurate picture of how well the policies of the MHS are addressing the delivery of psychological services to service members and their families.
Chapter 3 Research Methods
3. 1 Introduction
In section 1.4 we introduced the idea that we will be using the coding approach towards
document analysis [661 as our template for data analysis. Building off this template we defined five
phases in section 1.6 to collect, prepare, analyze and interpret the data. In this chapter we will examine some of the steps in the five phases and basis for performing these steps.
3.2 Collection and Preparation
This section provides a high level introduction to the process of searching and identifying documents, identifying and enhancing the key search terms, and identifying and enhancing the KPI characteristics. Chapter four will provide the technical details as to how the above steps are actually implemented.
Prior to starting the data preparation and analysis, the documents that were most related to the topic of interest had to be identified. A document content extraction algorithm was utilized for the purposes of identifying each document's applicability.
There are many methods that may be used for automatically extracting and analyzing the content of documents. The method determined to be most applicable for this research was a document content extraction model using keyword correlation analysis, as suggested by Jiang-Liang Hou and Chuan-An Chan[40]. "This method proposes a model for document content extraction on the basis of a keyword correlation thesaurus. An algorithm for keyword correlation
determination is developed via the keyword frequency and location in the specified documents. By application of this method, the document keyword correlation can be automatically determined based on the existing documents in the repository. Since the proposed approach is not
domain-oriented, it can be applied in various enterprises to efficiently establish a thesaurus of their own. This method provides an applicable and efficient document extraction mechanism for organizations to construct a knowledge center that fits the enterprise's operation features [401."
Using the above keyword extraction algorithm as a motivation, a document content extraction step was developed that involved:
1) Identifying and validating the repositories, databases, and archives where most documents
related to the topic could be found.
2) Developing the keyword list that would best relate to the topic (with the help of domain experts from the SSRC), and utilizing this keyword list to search for associated documents.
3) Reviewing the documents to refine the keyword list, and then searching the repositories
4) Repeating step three until no more documents are located from the repositories or until the keyword list becomes sufficiently specific (to be determined by a domain experts from the SSRC).
5) Using the refined keyword and final document list to now identify the characteristics of the
KPIs (with the help of the domain experts from the SSRC).
The sub-sections below discuss these steps in detail.
3.2.1 Document Search & Keyword Development
With the help of domain experts from the SSRC we developed an initial set of generic keywords that were related to the topic of delivery of psychological services to service members and their families. These keywords cast a wide net search of documents related to the topic. The documents returned from this wide search were then manually review (with the help of domain experts) for relevancy. From this manually intensive process a total of 15 related documents were identified.
Using this initial set of keywords and documents an enhanced Keyword (and Phrase) list is then developed by tagging the keywords and calculating the normalized frequency count of
keywords and non-keywords in the corpus. Following which the bigrams were identified, and those with the top 100 frequencies and likelihood of occurrences are surfaced. These findings are
surfaced to the domain experts to identify the most significant keywords (and phrases) to the topic.
The newly identified keywords (and phrases) will then be used to search and identify newer more related documents. The newer more related documents would then be put through the same process to further enhance the keyword/code list. The final keyword (phrase) list will be applied against the combined list of relevant documents from the two passes to identify a final set of relevant documents.
Table 3.1 shows the final set of 32 highly relevant documents that were identified from the above detailed process. In section 4.1 and 4.2 we dig deep into the actual steps of document search and keyword refinement.
3.2.2 Classifying the relevant documents
Once the final set of 32 highly relevant documents have been identified, we now had to classify them into their related classes. These classes were the eight Enterprise Views. We manually classify them with the aid of domain experts; in chapter five we will build a multi label classification model that will classify new incoming documents into one of the eight Enterprise Views. Its
necessary to classify the documents so that we can build relevant document cohorts for each class/view. The document cohorts will then be used to identify the characteristics, rank and relevancy of each class.
3.2.3 Developing the KPI (Eight Enterprise Views and Four MHS Goals) Characteristics
Once the final cohort of relevant documents for each class has been identified and final keyword (phrase) list has been developed, we can now focus on identifying the characteristics of
We implemented a custom version of the NgramTagger which takes in as a parameter a training model. This training model is made up of a tagged corpus consisting of a list of tagged Ngrams, where each Ngram is a list of (array of terms, tag) tuples.
Using the training model the NgramTagger will consume each document and parse through it looking for the existence of Ngrams to tag. Once the entire document has been scanned and the desired Ngrams have been tagged, we will surface the normalized frequencies of the tagged Ngrams and the untagged unigrams in the document. The domain experts can then review these
calculations and identify if there are more relevant or significant Ngrams that should be included in the tagged Ngram list. This process of identifying new Ngrams is a highly manual process, but it is made easier by the features in the tool that allows the surfacing of normalized frequency and likelihood estimates of Ngrams that contains selected unigrams. These features make it easier and faster to understand the context in which unigrams of interest exist.
This process is repeated until we have identified all possible relevant Ngrams. This final list will represent the characteristics of the KPIs. Section 4.4 discusses about the steps involved in the
Ngram Tagging, we will look at a specific example of how this is done.
Table 3.1 Final list of Documents identified for analysis
Org Title Description
Level
attps://wwwVAifg?()rg/?doc Lmlatii
U12 MiS Stakelsu' ders Repoit 1A) t'0gy is tht
littps://www.google.comri/ir [Isa= t&r ctj & &Csi dsuun:
(Jdi'ja&uaCt=8&vedf=O(CCAQjAA&rr http%43A%12F%2Fwwwrx.health.u %i'FRefereiu.2
)-dakeholdei
to
torw Id on I' cI 14, li1unChig
1111ification testing to allow mlrenibers of
th-rmy, Air Force, Navy, and Def-ense Centers s
celience for Psychological Hlealith to evalu at
Web-ai(se(I tool prior to its (i INIS: rovide i ho iii ii
>1>2 a111d decision
I >ofport capali IlIi tT
jscssinig risks,
nitigating operational vulnerah ilfocaLing scarce
imbat resorm e. durini, the p1 hilt aW
Ilidlcting
Org Title Description Level
peaim alize." ouw u nanis aei - iperatives to t'
ff1 m\h:\ I
ideline Update builds on tie VA/ Do
hI hlical Practice Guidelinte for the Managet:
I POst-Traumliiatic Stiess pIu)blished in '0 1
hie goal of this update is to integrate thi
t-sults of recent research and update th
tcommendations of the orwiinal guiid ehik
flect the current kiiowli
it if 11 1 Ii n
eAI s W e ) i liit r -I a lu
p://o iants ni
hgv/grants/goide/pa-files/PAR--01
014.htmil1
inconsiste I'\Pf'i ' oisitoo th iIAd' MXlf. Wtal Heal th IiitiiiifiiOrliihiI LStablis tlu ffice of tw Assist ut SCcietfarv of Defense (iealth
(UASD(lIA)) policy for the Military lhI fl't
-!,'flIthi.n i 1 n Tl 'l itmII to-tlf- Systeni (MIIS regarding the new SAIL
uIiiization review (UR) criteria is tl
,oi-mental health UR tool for both direct
c;
providers as well as managed cair sop
k1mll[!fWtors iI All future contiact.
u p I 1 f hflfl iiil iutiipisif'
'ffp/ \flhthiimi
ish
001) (poIIii Il' 1!)Lhk ili I 1ff1if d ic 'I f,1f IX pillWt iits overall Iiefi eiis' I if 1Cu llphsh inw mnission is reiatest t" I
.1~~ 11Lf % 11 11: 1 it f1(k I <1 f . .1 'Kffjfl t of f oimii ci iii f '-Ol/( 'r jecives
.'Lidro1 n _0 0 P lc n or dep oymA ent lm in psyFOVIrCIP()vd S "'uiddanC 0) (0 IIfditimis and imedicatiOis) 01ftilUed service 1
pf I 5) nfl.f