Evaluation of Approximate Operators Case Study: Sobel Filter Application Executed on an Approximate RISC-V Platform
Texte intégral
Figure
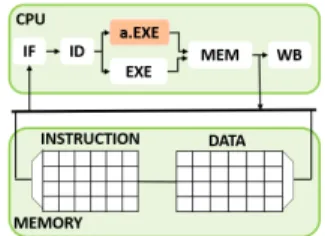
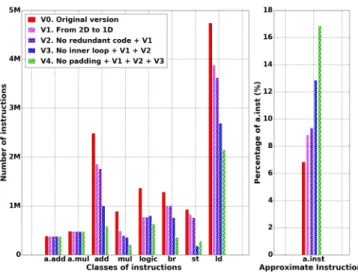
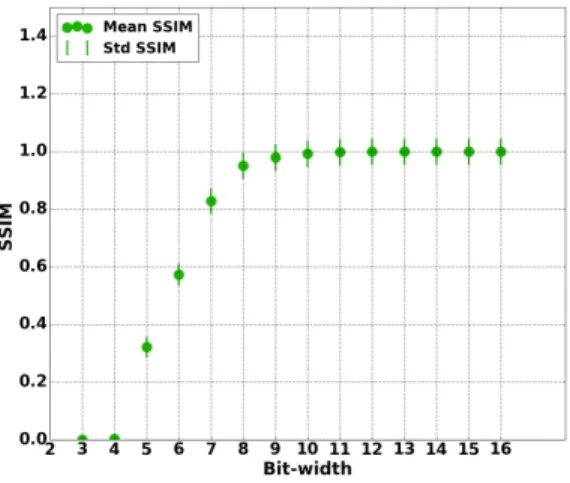
Documents relatifs
While the group H constructed by Hrushovski is naturally type- definable in the structure given, it only becomes so in Sanders’ Theorem (either in the ultraproduct or in a
Notre étude rétrospective descriptive, effectuée dans le Service de Médecine B au CHU IBN SINA de Rabat sur une période allant de Janvier 2010 à Décembre 2017, nous a permis
Abstract : In order to automate the quality control process of pipe’s welding joint, we present in this paper a new design of an embedded computer vision system, which is based on
In order to automate the quality control process of pipe’s welding joint, we present in this paper a new design of an embedded computer vision system, which is based on a
H1.3 – Last significant digit: despite the fact that this dimension is not taken into account in scale-based models, the way the human cognitive system represents
In [17], different approximations of the statistics of a nonlinear transformation of a random vector are used to investigate the filtering problem for a class of nonlinear
Adaptive execution of join will combine all the benefits of the existing standard algorithms, whether sorted inputs, the presence of permanent indexes for one or
On the one hand in traditional cost models the operation cost (amount of resources for its evaluation) can be estimated based on the size of arguments, order of objects in
